前言:Hello大家好,我是小哥谈。《YOLOv5:从入门到实战》专栏上线后,部分同学在学习过程中提出了一些问题,笔者相信这些问题其他同学也有可能遇到。为了让大家可以更好地学习本专栏内容,笔者特意推出了该篇专栏答疑,针对同学们在学习过程中所提出的问题进行汇总记录,并不断实时更新,希望能够帮助到大家!🌈
本专栏涵盖了丰富的YOLOv5算法从入门到实战系列教程,专为学习YOLOv5的同学而设计,堪称全网最详细的教程!该专栏从YOLOv5基础知识入门到项目应用实战都提供了详细的手把手教程,欢迎大家订阅并一并探索!

目录
🚀1.报错解决
🚀2.专栏答疑

🚀1.报错解决
💥💥报错1
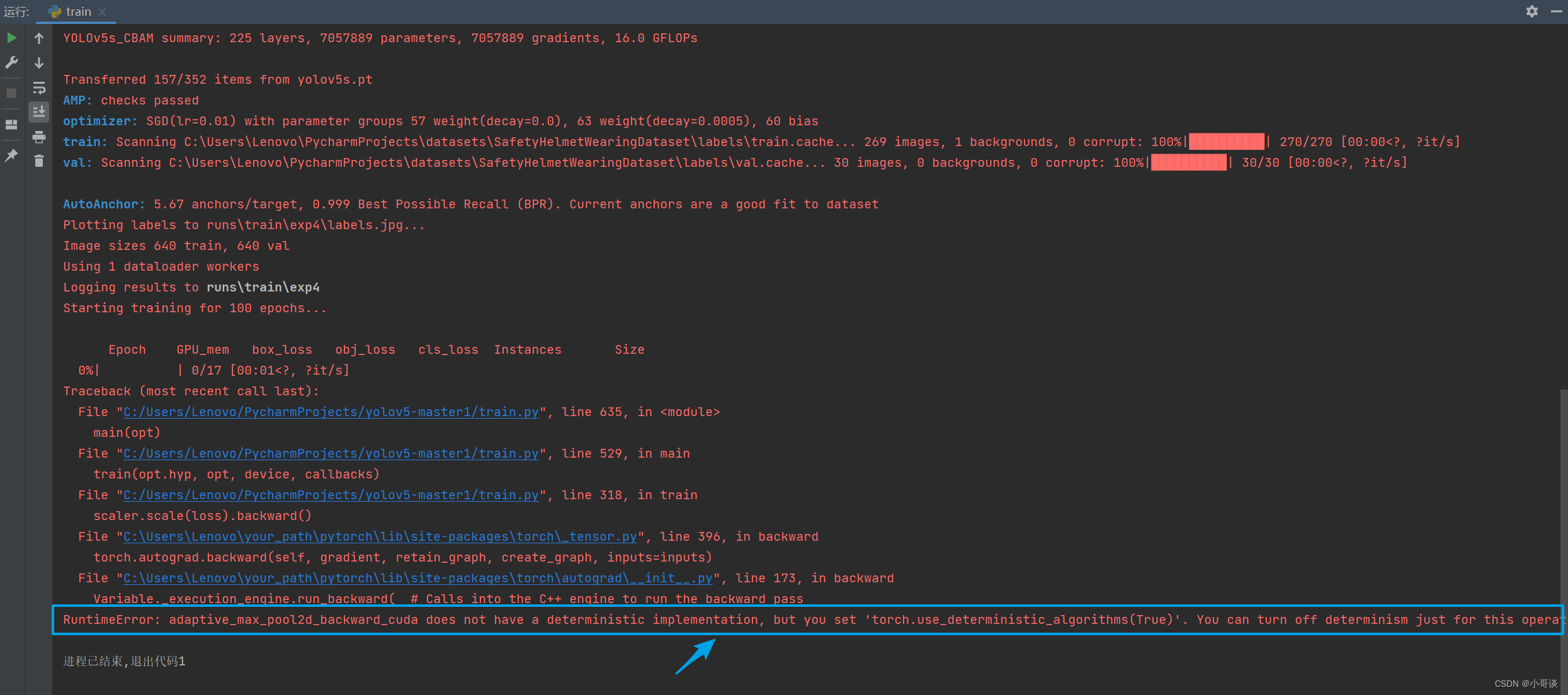
报错内容:
报错内容如下图所示:
解决方案:
在train.py文件中,大概324行左右,修改下列代码:
# Backward
scaler.scale(loss).backward()在原代码的基础上添加一行代码:
# Backward
torch.use_deterministic_algorithms(False) # 添加代码
scaler.scale(loss).backward()💥💥报错2
报错内容:
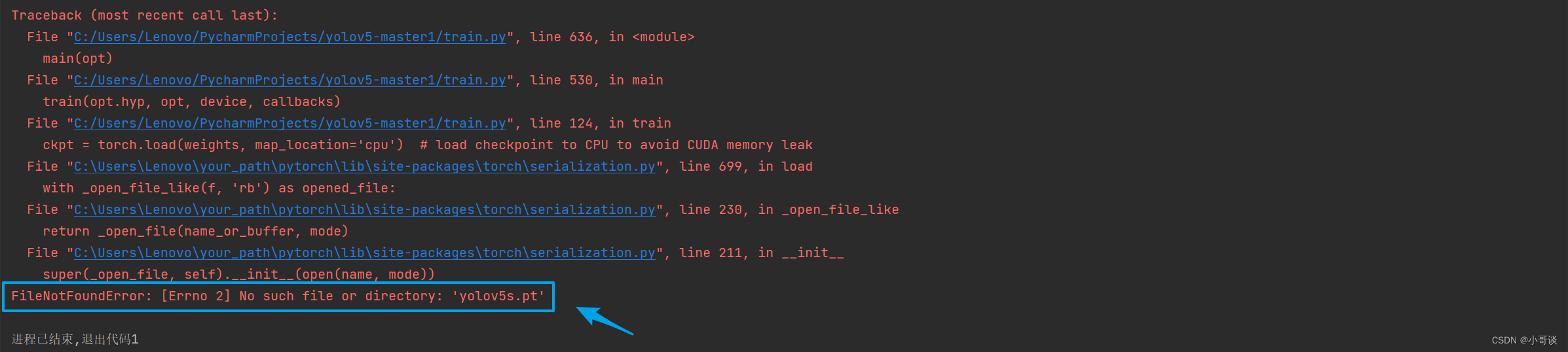
FileNotFoundError: [Errno 2] No such file or directory: 'yolov5s.pt'
报错内容如下图所示:
解决方案:
该报错容易发生在新入门的学生中,报错原因是没有准备预训练权重文件。
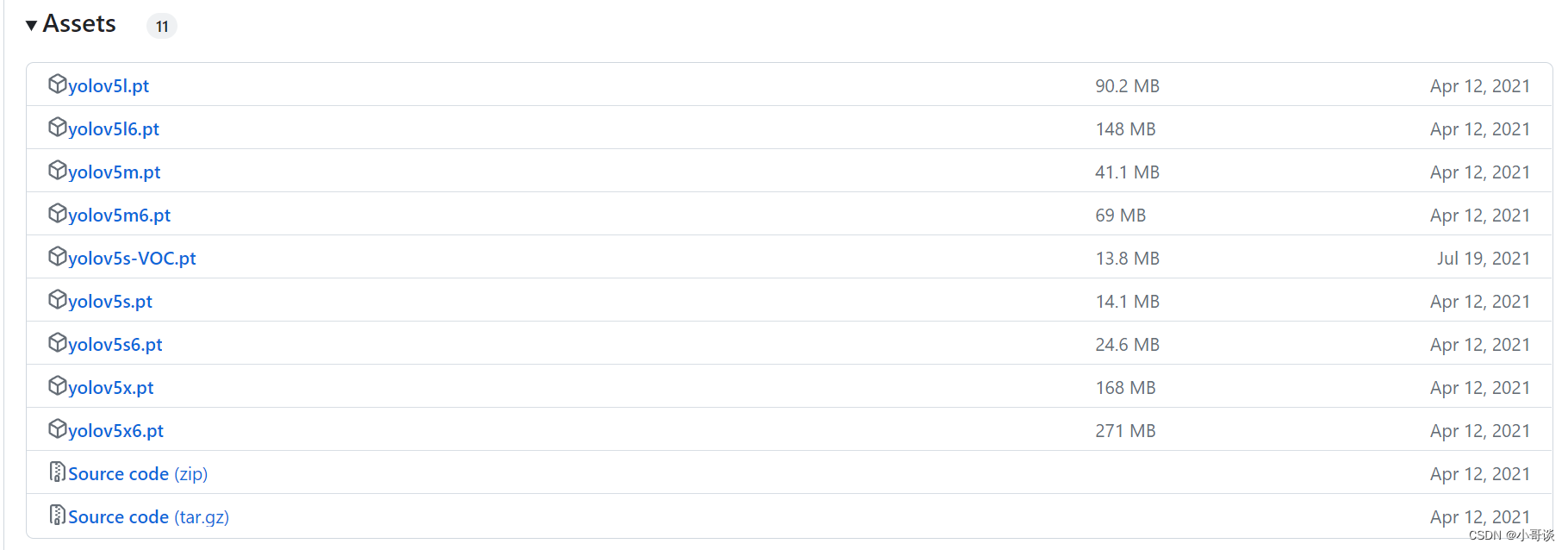
预训练权重:一般为了缩短网络的训练时间,并达到更好的精度,我们一般加载预训练权重进行网络的训练。而YOLOv5的5.0版本给我们提供了几个预训练权重,我们可以对应我们不同的需求选择不同的版本的预训练权重。通过如下的图可以获得权重的名字和大小信息,可以预料的到,预训练权重越大,训练出来的精度就会相对来说越高,但是其检测的速度就会越慢。预训练权重可以通过下列网址进入然后进行下载,本次训练自己的数据集用的预训练权重为yolov5s.pt。
说明:♨️♨️♨️
预训练权重网址:Release v5.0 - YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations · ultralytics/yolov5 · GitHub
💥💥报错3
报错内容:
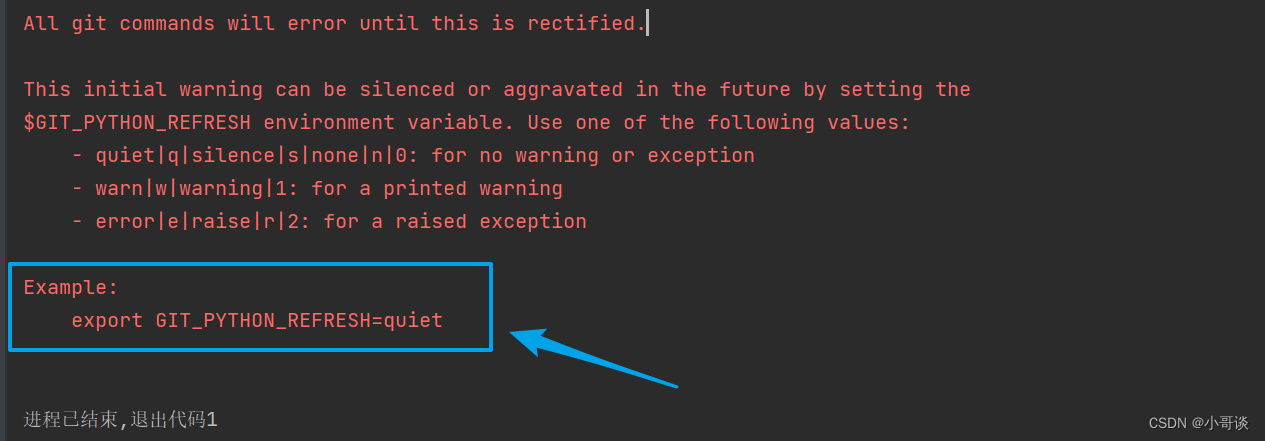
export GIT_PYTHON_REFRESH=quiet
报错内容如下图所示:
解决方案:
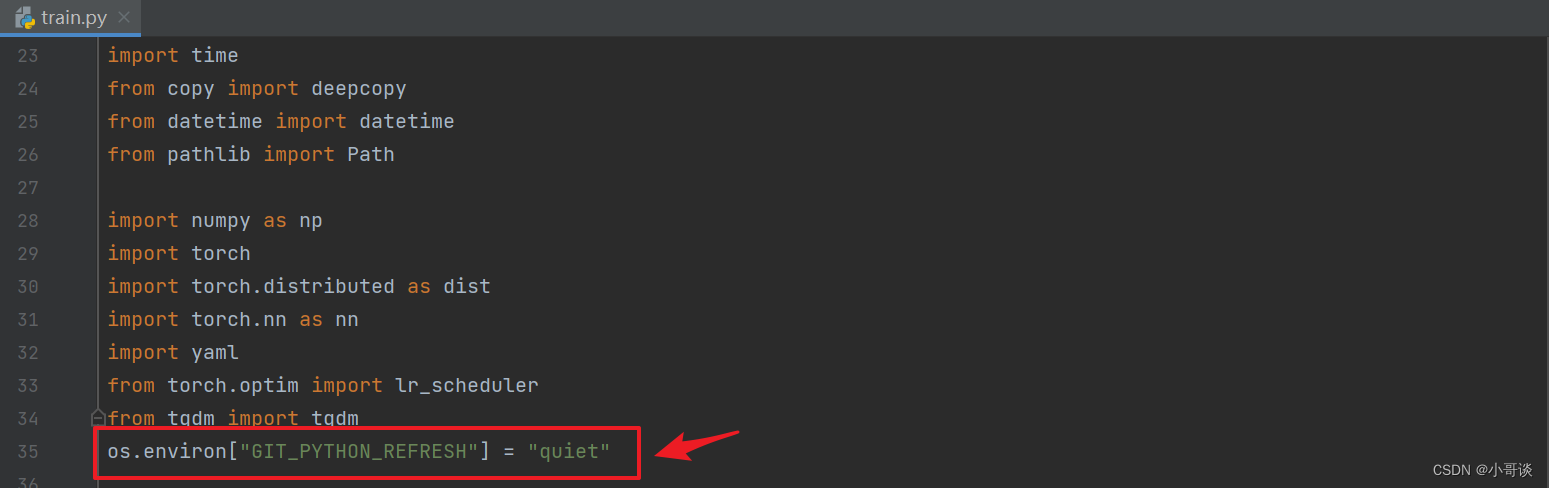
在train.py文件开头,添加下列代码:
os.environ["GIT_PYTHON_REFRESH"] = "quiet"具体如图所示:
💥💥报错4
报错内容:
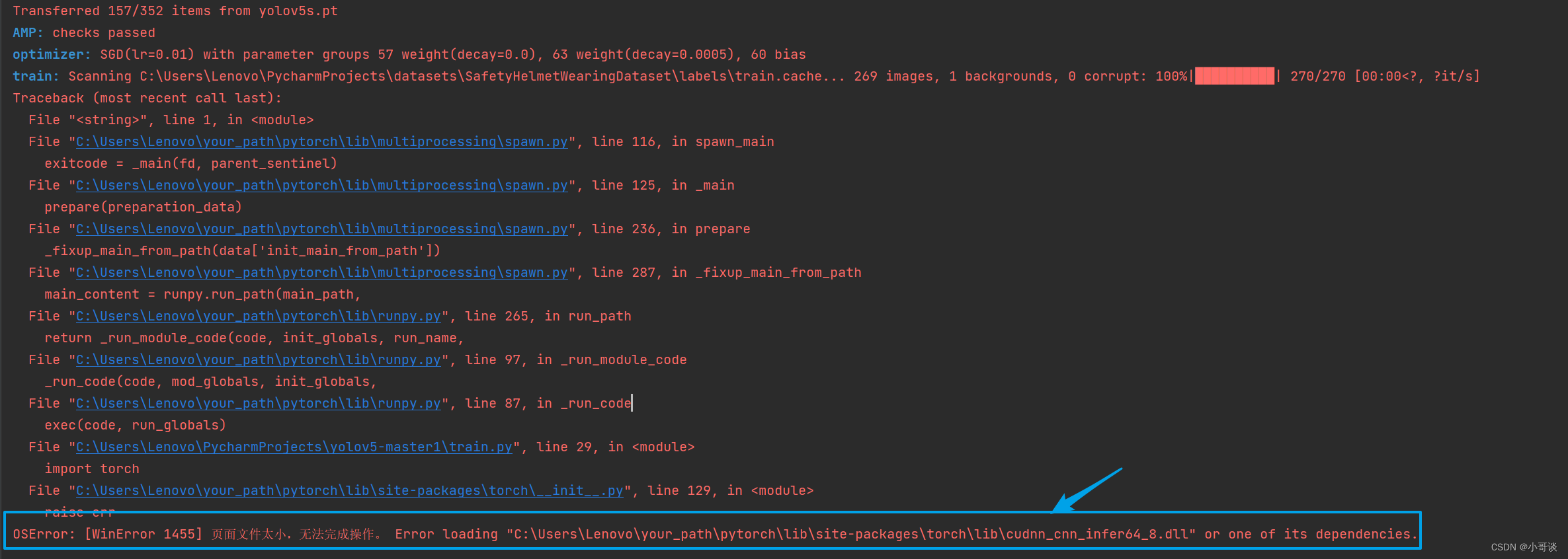
OSError: [WinError 1455] 页面文件太小,无法完成操作。 Error loading "C:\Users\Lenovo\your_path\pytorch\lib\site-packages\torch\lib\cudnn_cnn_infer64_8.dll" or one of its dependencies.
报错内容如下图所示:
解决方案:
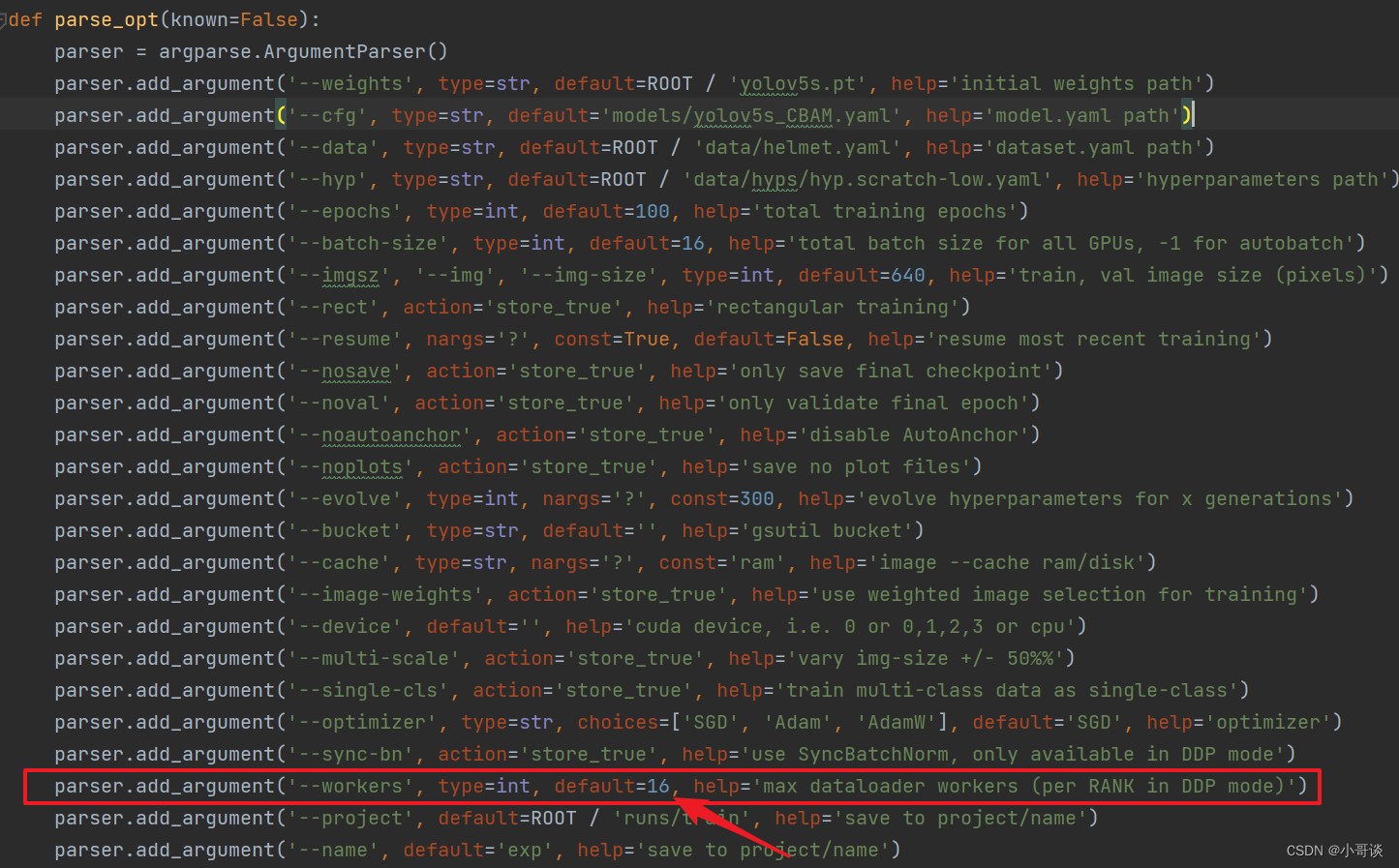
在train.py文件中找到parse_opt函数,调小‘--workers’中的default的值来解决。
🚀2.专栏答疑
💥💥问题1
问题内容:
可以把backbone替换成MobileNetv3以后,再更换成BiFPN的结构吗?
笔者回复:
可以的,我看论文有这么做的,您可以试一下效果。
💥💥问题2
问题内容:
添加了注意力机制后,为什么反而降点了呢?
笔者回复:
添加注意力不起作用无外乎两个原因,一是代码错误,二是注意力不适合。代码错误就不说了,而注意力不适合,需要明白:
注意力本身就是一种特征,通过附加到源特征上,实现一种类似特征增强的效果,因此从原理上讲,添加注意力,即使结果不变好,也不见得变差,但实际却经常遇到结果变差的情况。换一种说法,注意力是一组权重,权重附加到特征上,有增强的也有不增强的,当大量权重附加都达到增强效果,而只有少量特征造成负面影响,注意力就整体上增强了。这也是我们常说的注意力强化有用特征而弱化无用特征的作用,但其实鬼知道它强化的是什么特征,它也不可能强化的都是有用特征。注意力不起作用或者起反作用还与添加位置或者数据集等有关系。
所以,总结就是,对于YOLOv5算法,没有绝对涨点的改进操作,添加注意力机制也是如此,所以添加是否有用,需要多加尝试!
说明:♨️♨️♨️
本篇内容笔者会根据情况实时更新,大家有任何问题欢迎指出!