卷友们好,我是rumor。
通义千问昨天放出了14b参数的模型,还有一份比较详尽的技术报告,包含作者们训练8个模型的宝贵经验。
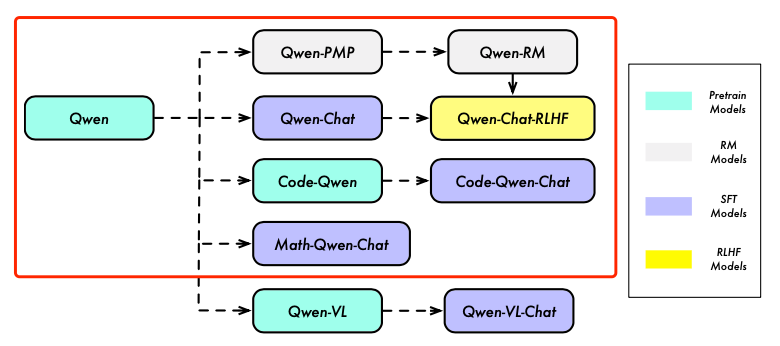
同时他们开源的13B比起开源的SOTA也有不少提升:
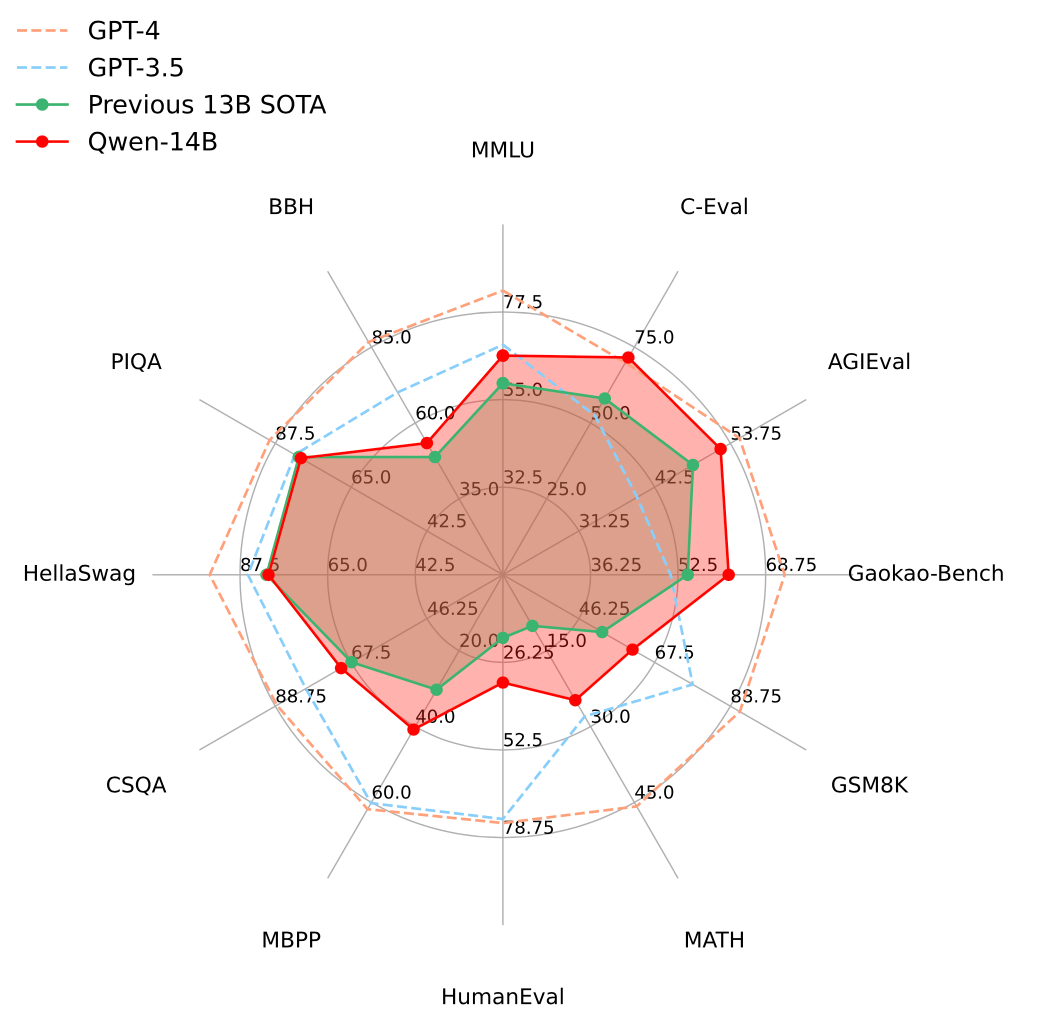
今天我们就来一起白嫖,更多细节请移步原文:
https://qianwen-res.oss-cn-beijing.aliyuncs.com/QWEN_TECHNICAL_REPORT.pdf预训练
数据
过了3T token,超过了Baichuan2的2.6T,(大概率)是目前中文社区过了最多语料的开源模型
提升多样性:数据归一化、MinHash和LSH去重
提升质量:通过规则和分类器,给样本打标,包括语言、质量分、有害内容等;随机抽样再进行review;对高质量数据源进行上采样
Tokenization
BPE,开源tiktoken的实现
把数字切成digit
最终词表152k,压缩比优于llama、Baichuan、ChatGLM等,但未跟llama2、Baichuan2对比
模型结构
本来LM里为了节省内存,词表大小的embedding层和输出的预测层是权重共享的,千问为提升效果取消了embedding和output的权重共享
采用RoPE[1],为了提升精度和表现,inverse frequency矩阵采用FP32
参考PaLM,去掉了大部分层的bias计算,但为了提升外推能力,保留了QKV计算时的bias
把Pre-Norm换成了RMSNorm,免去了均值的计算,主要是提升效率,效果差不多
激活函数用SwiGLU,为了保证参数量不变,缩小了FFN的维度
对于外推,提出了一种dynamic NTK-aware[2]的插值方法,可以避免效果下降
在attention计算时使用LogN-Scaling,根据上下文长度调整点乘,保证注意力的熵在上下文长度增加时也保持稳定,同时能提升外推表现。公式如下,完整的讲解请移步苏神博客[3]
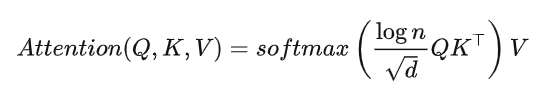
采用window attention,只在一段窗口内做注意力计算,减少计算量。同时发现较低的层对上下文长度更敏感,因此用更短的窗口
精调
数据质量上,去除了只用prompt模版构造的数据,在人类风格的对话上精调
采用了ChatML的格式,让模型可以区分角色和多轮
[
{"token": "<|im_start|>"},
"system\nYou are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible.\nKnowledge cutoff: 2021-09-01\nCurrent date: 2023-03-01",
{"token": "<|im_end|>"}, "\n", {"token": "<|im_start|>"},
"user\nHow are you",
{"token": "<|im_end|>"}, "\n", {"token": "<|im_start|>"},
"assistant\nI am doing well!",
{"token": "<|im_end|>"}, "\n", {"token": "<|im_start|>"},
"user\nHow are you now?",
{"token": "<|im_end|>"}, "\n"
]过了128*4000step数据,但没说过了多少epoch,这样算最多51万精调数据
强化
RM
参考Anthropic[4],先在较糙的数据上预训练RM(StackExchange、Reddit等),再用质量好的数据精调
训练数据的prompt体系做的很全,6600个标签,确保多样性和复杂度
回复的多样性提升可以降低标注难度、提升RM表现
获取句子打分时加了一个pooling层,正常都是直接取最后一个token的表示,直接影射到scalar,这里千问并没说是加的怎样的pooling
训1个epoch
RL
critic model warmup 50,百川也是相同的做法
RL训练阶段每个query采样两个答案,作者说这样效率会更高(意思是这两个答案都会计算奖励值然后强化?)
用running mean进行奖励归一化
value loss clipping,提升RL稳定性
actor 采样top-p=0.9,发现可以提升评估效果
用ptx loss来缓解对齐税,用的预训练数据需要比RL数据多很多,但不好调节,系数大了影响对齐,小了又没效果
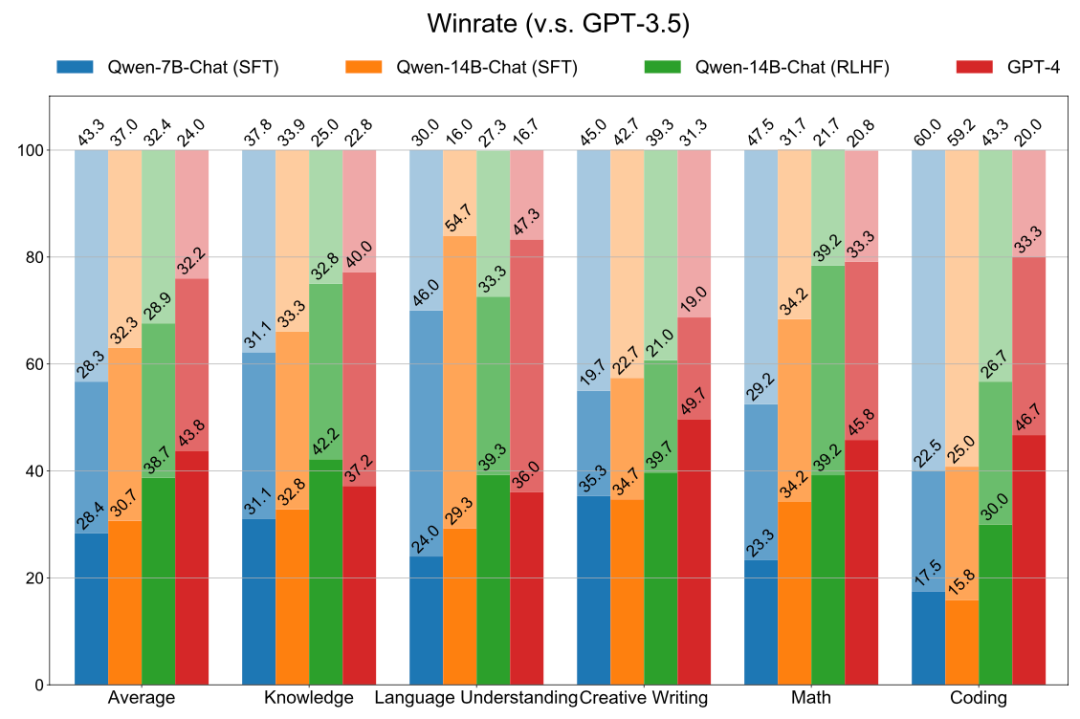
最终,在300条评估集上,RLHF后的模型在知识、理解、写作、Math、Coding都有提升,有的能力提升还挺大(颜色由深到浅分别是wins、ties、losses):
Code模型
为了保证作为助理的能力,选择以文本预训练模型为基座,用代码和文本联合继续训练
提升数据来源多样性很重要
窗口扩到8192
又训了90b的数据,得到CODE-QWEN
Math模型
数学题目一般较短,用1024长度训,提升训练速度
在SFT精调时,mask掉题目中的条件和数字等无意义的词,可以加速收敛(问题来了,本来SFT不就是要mask输入的吗?)
划重点就到这里,欢迎卷友们一起在评论区讨论~
参考资料
[1]
Roformer: Enhanced transformer with rotary position embedding: https://arxiv.org/abs/2104.09864
[2]YaRN: Efficient context window extension of large language models: https://arxiv.org/abs/2309.00071
[3]从熵不变性看Attention的Scale操作: https://kexue.fm/archives/8823
[4]Training a helpful and harmless assistant with reinforcement learning from human feedback: https://arxiv.org/pdf/2204.05862.pdf

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「希望GPT4学习一下我国的技术报告」