目录
题目:
示例:
分析:
代码:
题目:

示例:

分析:
给我们一个二维数组来表示花期,在一段花期之内花是开的。另外给我们一个一维数组表示来人的时间,要我们返回一个一维数组,第i个元素表示第i个人来时在花期内的花。
我们可以直接统计出在不同时间时,在花期内的花的数量,然后依次按照每个人来时的时间来获取花的数量。

不过题目有给出数据范围,花期的时间间隔最多为10的9次方,那么我们上述暴力做法一定是会超时的。
我们来分析分析能不能优化一下,先看看按照上述做法得出的所有时间中在花期内的花的数目。

当完整的查找表在我们面前时我们就可以发现,实际上很多相邻的时间点的开花数是一样的,我们把第一个与相邻时间点不一样的时间节点提取出来。

把重复元素剔除,剩下的时间点都有一个共同点,假设花期的范围是【i,j】,那么 i 和 j + 1 必然在这些特殊时间点中(最开头的1除外)。

这个也不难理解,因为 i 时花开了,所以花的数目自然是增加的。j 时花谢了,所以在 j + 1时,花的数目就减少了。
因此我们只需要记录下关键节点的花的数目就可以了。
我们这边记录这种离散的键值对,所以我们用map来记录。
接着遍历所有来的人,根据来的人的时间,我们按照顺序去寻找在map中,键第一个大于来的人的时间的键值对。
例如下图:
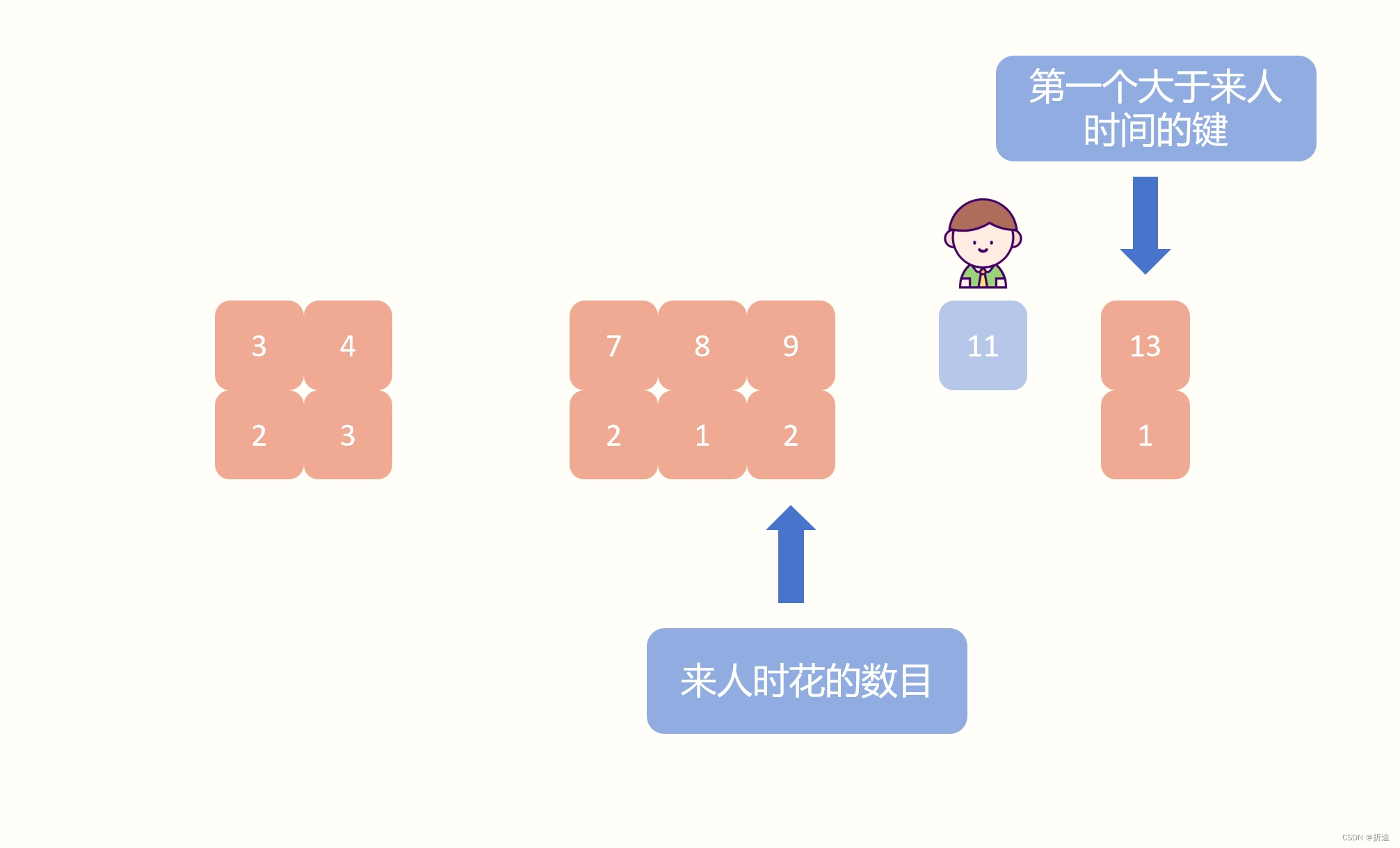
如果此时有人在时间为11时来的,那么我们找到的第一个大于来的人的时间的键值对是时间为13的,我们需要将找到的键值对再回退一格,回退一格之后的键值对的值才是来人时花开的数目。
找到之后做个判断,如果找到的是第一个元素,那么是无法回退的,所以在这个时间点时的花的数目就是0。
代码:
class Solution {
public:
vector<int> fullBloomFlowers(vector<vector<int>>& flowers, vector<int>& people) {
map<int,int>m;
int n=people.size();
int temp=0;
//对花期的节点做相应的标记
for(auto& f:flowers){
++m[f[0]];--m[f[1]+1];
}
//统计出在不同节点时,花的数目
for(auto& a:m){
temp+=a.second;
m[a.first]=temp;
}
vector<int>res(n,0);
//找出离 来人时最近的时间节点 的花的数目
for(int i=0;i<n;i++){
auto it = m.upper_bound(people[i]);
if (it == m.begin()) continue;
res[i] = (--it)->second;
}
return res;
}
};