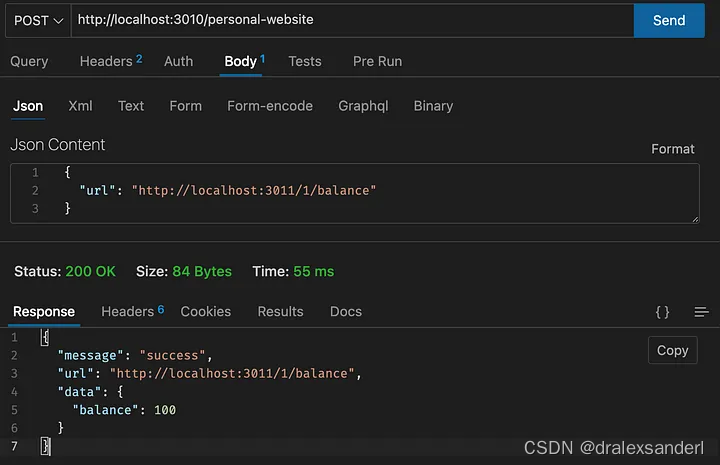
shell脚本重点记录
判断文件或者文件夹是否存在

if [ ! -d "log" ];then
chmod 707 $file1
一个文件的权限包括读取、写入、执行,权限范围包含所有者、所属组、其他人,可以通过数字或者字母描述一个文件的权限:读取权限对应r或4,写入权限对应w或2,执行权限对应x或1。例如7代表读取写入执行权限,6代表读取写入权限,5代表读取执行权限,4代表读取权限,3代表写入执行权限,2代表写入权限,1代表执行权限,0代表无权限。
log=`ls -l | grep monitor |awk '{print $8}' |sort -n | awk 'END{print}' |cut -d '_' -f 1`
ls -l 列出文件的具体信息。grep 提取包含monitor的行。awk对每一行分割,并打印每一行第八个元素。使用纯数字进行排序。任何在BEGIN之后列出的操作(在{}内)将在Unix awk开始扫描输入之前执行,而END之后列出的操作将在扫描完全部的输入之后执行。因此,通常使用BEGIN来显示变量和预置(初始化)变量,使用END来输出最终结果。sort递增的顺序排序,cut -d 分隔符 -f 第几段
cut用于对一行的文字进行分割
cut -d'分隔字符' -f fields <==用于有特定分隔字符
cut -c 字符区间 <==用于排列整齐的讯息
awk用于将一行的文字分为不同的字段,后面接两个单引号并加上大括号 {} 来设定想要对数据进行的处理动作,而默认的『字段的分隔符为 “空格键” 或 “[tab]键” 。
grep用于在多行文本中搜索字符串,提取包含指定字符串的行
awk '条件类型 1{动作 1} 条件类型 2{动作 2} ...' filename
grep [-acinv] [--color=auto] '搜寻字符串' filename
选项与参数:
-a :将 binary 文件以 text 文件的方式搜寻数据
-c :计算找到 '搜寻字符串' 的次数
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
--color=auto :可以将找到的关键词部分加上颜色的显示喔!
grep [-A] [-B] [--color=auto] '搜寻字符串' filename
练习作业
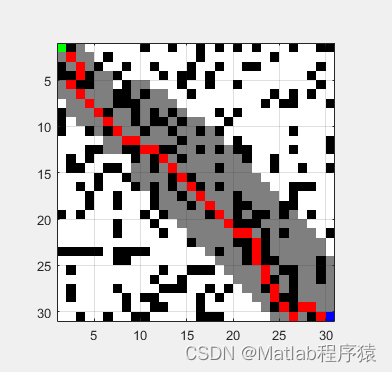
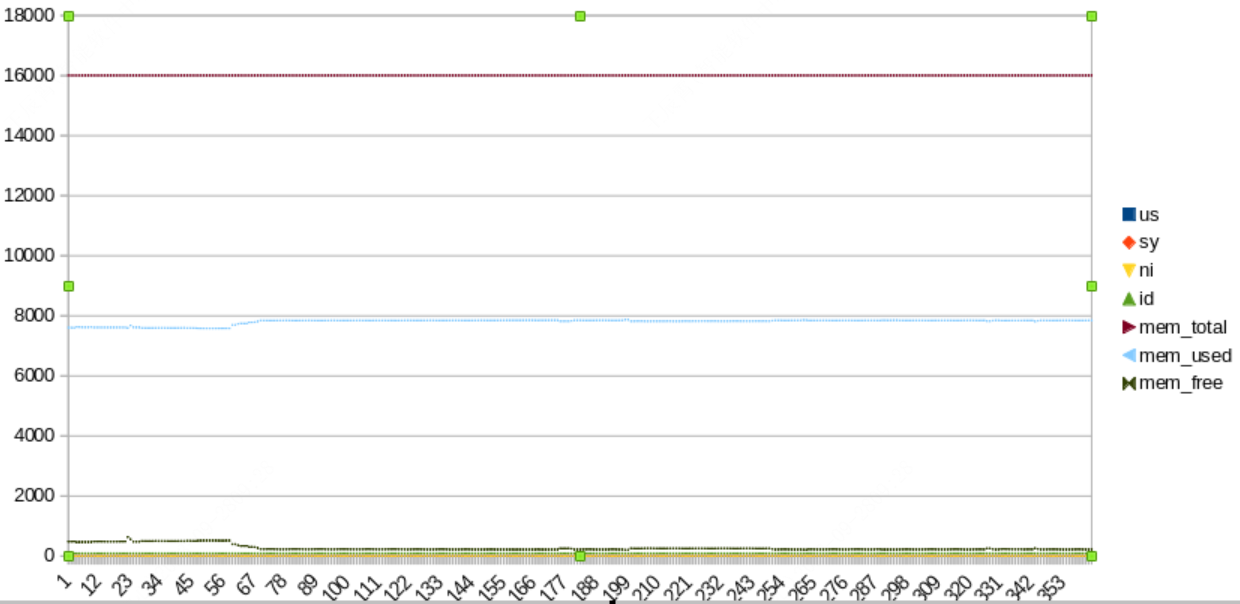
目标:提取CPU和内存的使用情况,并保存为CSV文件,并通过图标可视化。
shell脚本如下
#!/bin/bash
interval=1
output_file="cpu_mem_info.csv"
start_time=$(date +%s)
while true; do
current_time=$(date +%s)
run_time=$((current_time - start_time))
us=$(top -bn1 | grep "Cpu(s)" | awk '{print $2}')
sy=$(top -bn1 | grep "Cpu(s)" | awk '{print $4}')
ni=$(top -bn1 | grep "Cpu(s)" | awk '{print $6}')
id=$(top -bn1 | grep "Cpu(s)" | awk '{print $8}')
mem_total=$(free -m | awk 'NR==2{print $2}')
mem_used=$(free -m | awk 'NR==2{print $3}')
mem_free=$(free -m | awk 'NR==2{print $4}')
echo "$run_time,$us,$sy,$ni,$id,$mem_total,$mem_used,$mem_free" >> "$output_file"
sleep $interval
done
csv文件的部分内容如下
0,0.8,0.4,2.0,96.7,16005,7608,481
1,0.8,0.4,2.0,96.7,16005,7607,482
3,0.8,0.4,2.0,96.7,16005,7605,484
5,0.8,0.4,2.0,96.7,16005,7623,466
6,0.8,0.4,2.0,96.7,16005,7620,469
8,0.8,0.4,2.0,96.7,16005,7617,472
10,0.8,0.4,2.0,96.7,16005,7617,472
12,0.8,0.4,2.0,96.7,16005,7617,472
13,0.8,0.4,2.0,96.7,16005,7624,472
15,0.8,0.4,2.0,96.7,16005,7613,483
17,0.8,0.4,2.0,96.7,16005,7613,484
19,0.8,0.4,2.0,96.7,16005,7612,485
20,0.8,0.4,2.0,96.7,16005,7613,484
22,0.8,0.4,2.0,96.7,16005,7613,484
24,0.8,0.4,2.0,96.7,16005,7613,484
25,0.8,0.4,2.0,96.7,16005,7612,484
27,0.8,0.4,2.0,96.7,16005,7612,484
29,0.8,0.4,2.0,96.7,16005,7612,484
31,0.8,0.4,2.0,96.7,16005,7613,484
32,0.8,0.4,2.0,96.7,16005,7612,484
记录一段时间后csv可视化如下所示
系统移植笔记
在进行 Linux 驱动开发之前肯定需要先将Linux 系统移植到开发板上去。大致步骤分为移植bootloader代码、Linux内核和根文件系统
bootloader
bootloader用于启动Linux系统内核,芯片上电之后会首先运行bootloader程序,首先初始化DDR等外设,然后将Linux内核从flash中拷贝到DDR中,并启动Linux内核。U-Boot是最为广泛使用的bootloader程序。
uboot 官方的 uboot 源码是给半导体厂商准备的,半导
体厂商会下载 uboot 官方的 uboot 源码,然后将自家相应的芯片移植进去。我们自己做的板子就需要修改芯片厂商官方的 uboot,使其支持我们自己做的板子。 uboot 官方的基本是不会用的,因为支持太弱了。最常用的就是半导体厂商或者开发板厂商的 uboot,所以uboot移植是指通过半导体厂商提供的uboot适配自己的开发板。