1. 安装docker
-
确保电脑已经安装docker
-
docker安装过程可自行查找资料,mac下docker可以使用brew命令安装
-
安装之后,查看docker版本,确认安装成功
docker -v
2. 下载jdk
- 最好下载jdk-8,jdk的版本过高可能hadoop2.x不支持
- jdk-8的下载地址:Java Downloads | Oracle
3.下载hadoop
- 我下载的是hadoop3.3.4版本,下tar.gz压缩包
- hadoop下载地址:Index of /dist/hadoop/common (apache.org)
4. 拉取镜像 centos
-
通过此命令拉取最新的centos8的镜像
docker pull centos -
启动centos容器
docker run -itd --name hadoop01 -p 2201:22 -p 8088:8088 -p 9000:9000 -p 50070:50070 --privileged=true centos:latest /sbin/init注意:
- -p:表示端口映射,这很重要,可以方便本机在外部访问web网页 需要设置容器和本机的相关端口映射
- -i:表示运行的容器
- -t:表示容器启动后会进入其命令行。加入这两个参数后,容器创建就能登录进去。即分配一个伪终端。
- -d: 在run后面加上-d参数,则会创建一个守护式容器在后台运行(这样创建容器后不会自动登录容器,如果只加-i -t两个参数,创建后就会自动进去容器)。
- –name :为创建的容器命名。
- –privileged:为true时赋予容器内root用户真正的root权限,否则root为普通用户,默认为flase
- /sbin/init: 使容器启动后可以使用systemctl方法
-
容器启动之后会有唯一的容器id,通过如下命令查看正在运行的容器
docker ps

-
通过如下命令进入容器,containerID也可以填容器的名称
docker exec -it containerID /bin/bash -
进入容器后非常重要的一点!!更换yum源,卡在这里很久
因为大部分的教程只更换了 CentOS-Linux-BaseOS.repo和CentOS-Linux-AppStream.repo
但是在使用yum命令安装vim的时候,报错的是:CentOS-Linux-Extras.repo
因此,需要换源的是三个地方
按照如下修改这三个文件的内容:
cd /etc/yum.repos.d vi CentOS-Linux-BaseOS.repo #修改内容为: [baseos] name=CentOS Linux $releasever - BaseOS #mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=BaseOS&infra=$infra #baseurl=http://mirror.centos.org/$contentdir/$releasever/BaseOS/$basearch/os/ baseurl=https://vault.centos.org/centos/$releasever/BaseOS/$basearch/os/ gpgcheck=1 enabled=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial vi CentOS-Linux-AppStream.repo #修改内容为 [appstream] name=CentOS Linux $releasever - AppStream #mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=AppStream&infra=$infra #baseurl=http://mirror.centos.org/$contentdir/$releasever/AppStream/$basearch/os/ baseurl=https://vault.centos.org/centos/$releasever/AppStream/$basearch/os/ gpgcheck=1 enabled=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial vi CentOS-Linux-Extras.repo #修改内容为: [extras] name=CentOS Linux $releasever - Extras #mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras&infra=$infra #baseurl=http://mirror.centos.org/$contentdir/$releasever/extras/$basearch/os/ baseurl=https://mirrors.aliyun.com/centos/8-stream/extras/$basearch/os/ gpgcheck=1 enabled=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-centosofficial -
然后使用yum 命令下载vim,后面可以缺少什么利用yum下载什么了
yum install -y vim
5. 安装Java环境
-
首先mac开启两个终端,一个是centos入容器终端,另一个是本机终端

-
centos终端:创建dowload文件夹
mkdir /home/download -
本机终端,移动到jdk存放目录,将jdk的包上传至dowload文件夹,hadoop安装包也相同上传
cd vmware-hosts/hadoop/ docker cp jdk-8u381-linux-aarch64.tar.gz hadoop01:/home/download/ docker cp hadoop-3.3.4.tar.gz hadoop01:/home/download/ -
centos终端:进入download目录下将jdk文件解压至/usr/local/目录下
cd /home/download/ tar -zxvf jdk-8u381-linux-aarch64.tar.gz -C /usr/local/ -
进入jdk解压目录,将文件名修改为jdk(方便设置环境变量及简洁):
cd /usr/local/ mv mv jdk1.8.0_311/ jdk -
修改bashrc环境变量
vim /etc/bashrc #在末尾添加以下内容 #jdk environment export JAVA_HOME=/usr/local/jdk export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH #source 使环境变量生效 source /etc/bashrc
6. 创建集群需要的容器
-
将hadoop01导出到镜像,并利用该镜像创建两个相同容器
#导出镜像 docker commit hadoop01 mycentos #查看镜像列表 docker images #创建相同容器 docker run -itd --name hadoop02 -p 2202:22 -p 50090:50090 --privileged=true mycentos /sbin/init docker run -itd --name hadoop03 -p 2203:22 --privileged=true mycentos /sbin/init-
注意:创建的容器进入之后root之后@的是容器id,在容器内使用
hostname hadoop01可以对其主机名进行修改,ctrl+p+q之后即可生效
-
7.安装hadoop
7.1 三台服务器统一网段
安装hadoop需要保持服务器之间内网连通,而我们创建的三个容器:hadoop01、hadoop02、hadoop03;默认是放在bridge的网段的,默认是联通的,但是为了和其他不相关的容器区分开,建议还是创建一个新的网段让三台容器自己相连。
#查看docker 存在的网段
docker network ls
#创建名为bigdata的新网段
docker network create bigdata
# 三台容器连入bigdata网段
docker network connect bigdata hadoop01
docker network connect bigdata hadoop02
docker network connect bigdata hadoop03
#断开三台容器与bridge的连接
docker network disconnect bridge hadoop01
docker network disconnect bridge hadoop02
docker network disconnect bridge hadoop03
-
最后查看bigdata内的网段:以及三台机器的ip地址
docker network inspect bigdata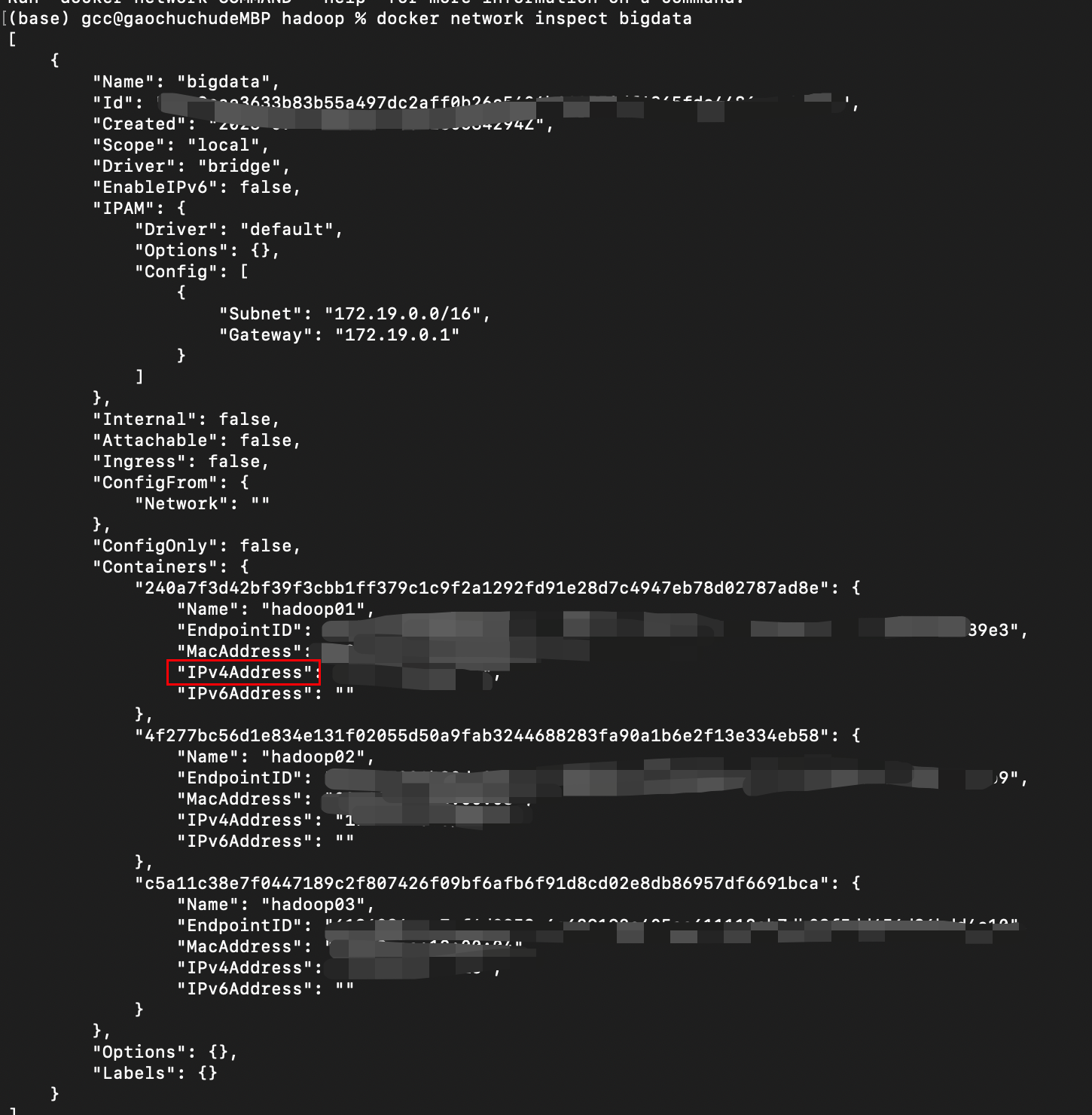
- 注意因为docker的centos8的镜像是不带防火墙的,可以省去关闭防火墙步骤
7.2 SSH 无密登陆配置
-
对于hadoop01主机
- 运行如下命令:
yum -y install passwd openssh-server openssh-clients systemctl status sshd systemctl start sshd systemctl enable sshd #让sshd服务开机启动 ss -lnt #检查22端口号是否开通此时发现:22端口已开通

-
设置root密码
passwd root
注意,到这个步骤,每个容器都必须安装一次!
-
安装完成之后:修改hosts文件
vim /etc/hosts #在文件后添加 172.19.0.2 hadoop01 172.19.0.3 hadoop02 172.19.0.4 hadoop03 -
设置免密登录
ssh-keygen -t rsa #连续三个回程 [root@hadoop01 ~] cd .ssh/ [root@hadoop01 ~] ls
-
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop01 ssh-copy-id hadoop02 ssh-copy-id hadoop03注意这里本容器的公钥也需要拷贝,以上命令需要在三个容器中都执行

7.3 容器间时间同步
-
centos8取消了ntpd服务,使用chrony替代了ntpd的时间同步,为三台容器都下载chronyd
yum -y install chrony -
设置hadoop01为时间同步主服务器,其余节点从hadoop01同步时间
#对于hadoop01容器 vim /etc/chrony.conf- 取消图中注释的两行:

- 取消掉图中两行注释,前者代表允许该网段从本服务器同步时间,后者代表将本服务器作为时间同步主服务器
- 修改后启动chrony服务
systemctl status chronyd #查看服务状态
systemctl start chronyd #启动服务
systemctl enable chronyd #将服务设置为开机启动
-
对于hadoop02和hadoop03 都修改时间同步来源为hadoop01
vim /etc/chrony.conf -
做如下修改:

一些chrony命令:
查看时间同步源: $ chronyc sources -v 查看时间同步源状态: $ chronyc sourcestats -v 校准时间服务器: $ chronyc tracking
-
解压文件
tar -zxvf hadoop-3.3.4.tar.gz -C /usr/local -
配置hadoop环境变量
cd /etc/profile.d/ touch my_env.sh vim my_env.sh #在其末尾添加 #HADOOP_HOME export HADOOP_HOME=/usr/local/hadoop-3.3.4 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin #让修改后的文件生效 source /etc/profile #测试是否成功 hadoop version
-
分发hadoop 以及环境变量
cd /usr/local/ scp -r hadoop/ hadoop02:$PWD scp -r hadoop/ hadoop03:$PWD scp /etc/profile hadoop02:/etc/ scp /etc/profile hadoop03:/etc/ source /etc/profile #在hadoop02上执行 source /etc/profile #在hadoop03上执行
7.4 集群分发脚本
-
将脚本放在全局环境变量中
echo $PATH
-
在全局环境目录下创建xsync脚本
cd /usr/local/bin vim xsync #编写如下脚本 #!/bin/bash if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi for host in hadoop01 hadoop02 hadoop03 do echo ==================== $host ==================== for file in $@ do if [ -e $file ] then pdir=$(cd -P $(dirname $file); pwd) fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done #修改脚本xysnc 赋予执行权限 chmod +x xsync #测试脚本 xsync /usr/local/bin #将脚本复制/bin目录,以便全局调用 cp xsync /bin/ #同步环境变量配置 ./bin/xsync /etc/profile.d/my_env.sh #最后hadoop01 hadoop02 hadoop03 都执行 source /etc/profile
8.关于hadoop集群的配置问题
- 可参考Hadoop的学习笔记(二):完全分布式的配置、格式化、启动 - 知乎 (zhihu.com)
需要注意的点是:
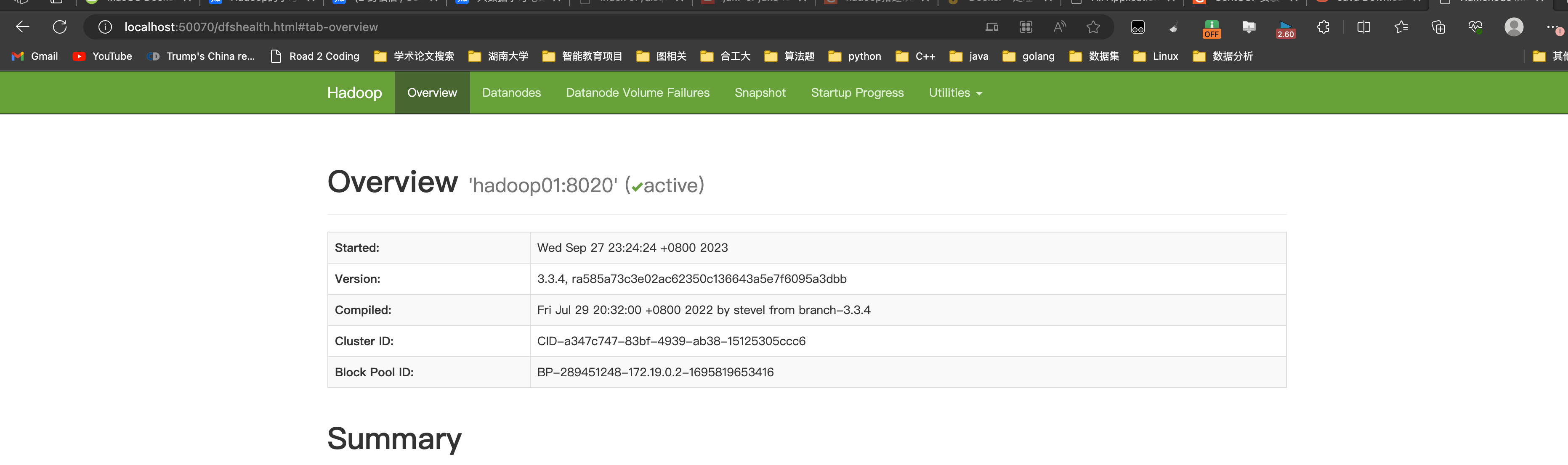
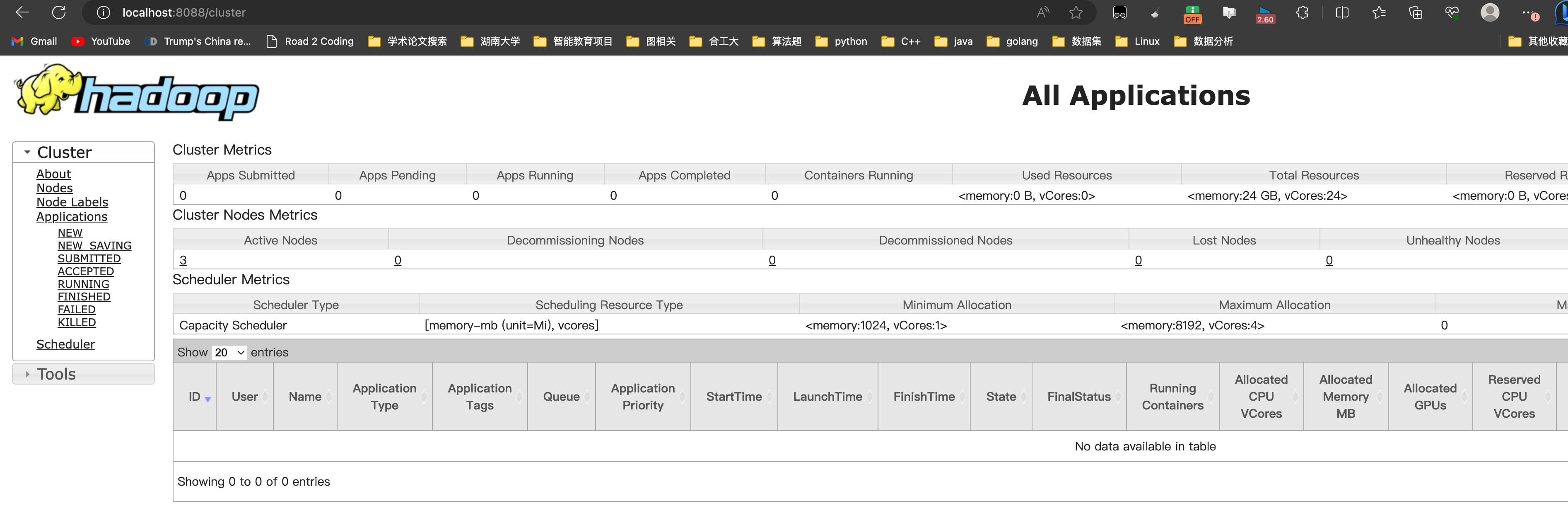
webUI界面:
在启动了hdfs和yarn之后,其HDFS的Yarn的webUI的界面地址:其不是容器的ip地址!!要注意
因为可以发现其实在物理机器上是ping不通hdfs的ip地址的
我也按照一些资料去解决问题,暂时还没有解决物理机和docker容器ip不互通的问题
但是,在启动容器的时候,我们设置了端口的映射关系,就可以通过物理机的ip地址来访问容器内端口
因此:
HDFS:http://localhost:50070/
yarn:http://localhost:8080