一、说明
这篇文章的重点将是GPU上的PyTorch培训。更具体地说,我们将专注于 PyTorch 的内置性能分析器 PyTorch Profiler,以及查看其结果的方法之一,即 PyTorch Profiler TensorBoard 插件。
二、深度框架
训练深度学习模型,尤其是大型模型,可能是一项昂贵的支出。我们可以使用的用于管理这些成本的主要方法之一是性能优化。性能优化是一个迭代过程,在这个过程中,我们不断寻找提高应用程序性能的机会,然后利用这些机会。在以前的帖子中(例如,这里我们强调了拥有进行这种分析的适当工具的重要性。选择的工具可能取决于许多因素,包括训练加速器的类型(例如,GPU、HPU 或其他)和训练框架。

性能优化流程(作者)
这篇文章并不是要替代PyTorch Profiler上的官方PyTorch文档,也不是使用TensorBoard插件来分析分析器结果。我们的目的是展示如何在一个人的日常发展过程中使用这些工具。事实上,如果您还没有,我们建议您在阅读这篇文章之前先查看官方文档。
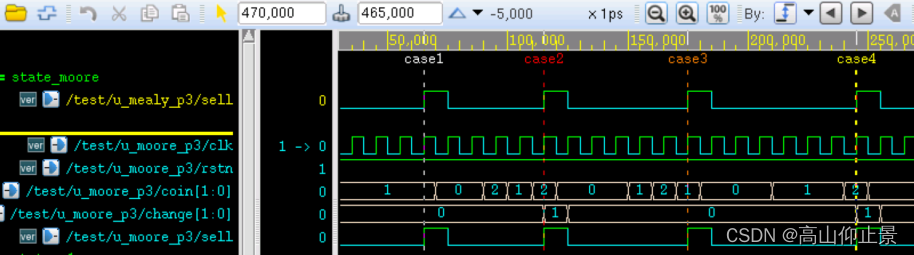
一段时间以来,我一直对TensorBoard插件教程的一部分特别感兴趣。本教程介绍了一个分类模型(基于 Resnet 架构),该模型在流行的 Cifar10 数据集上进行训练。它继续演示如何使用PyTorch Profiler和TensorBoard插件来识别和修复数据加载器中的瓶颈。输入数据管道中的性能瓶颈并不少见,我们在之前的一些文章中(例如,在这里)已经详细讨论了它们。本教程令人惊讶的是(截至撰写本文时)呈现的最终(优化后)结果,我们将其粘贴到下面:

性能跟踪优化(来自 PyTorch 网站)
如果仔细观察,您会发现优化后的 GPU 利用率为 40.46%。现在没有办法粉饰这一点:这些结果绝对是糟糕的,应该让你夜不能寐。正如我们过去所扩展的那样(例如,在这里),GPU 是我们训练机器中最昂贵的资源,我们的目标应该是最大限度地提高其利用率。40.46% 的利用率结果通常代表培训加速和成本节约的重要机会。当然,我们可以做得更好!在这篇博文中,我们将努力做得更好。我们将首先尝试重现官方教程中提供的结果,看看我们是否可以使用相同的工具来进一步提高训练性能。
三、玩具示例
下面的代码块包含由 TensorBoard 插件教程定义的训练循环,进行了两个小的修改:
- 我们使用与本教程中使用的CIFAR10数据集具有相同属性和行为的假数据集。这种变化的动机可以在这里找到。
- 我们初始化torch.profiler.schedule,预热标志设置为3,重复标志设置为1。我们发现,预热步骤数量的略微增加提高了分析结果的稳定性。
import numpy as np
import torch
import torch.nn
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.datasets
import torchvision.models
import torchvision.transforms as T
from torchvision.datasets.vision import VisionDataset
from PIL import Image
class FakeCIFAR(VisionDataset):
def __init__(self, transform):
super().__init__(root=None, transform=transform)
self.data = np.random.randint(low=0,high=256,size=(10000,32,32,3),dtype=np.uint8)
self.targets = np.random.randint(low=0,high=10,size=(10000),dtype=np.uint8).tolist()
def __getitem__(self, index):
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self) -> int:
return len(self.data)
transform = T.Compose(
[T.Resize(224),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_set = FakeCIFAR(transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,
shuffle=True)
device = torch.device("cuda:0")
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
criterion = torch.nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
# train step
def train(data):
inputs, labels = data[0].to(device=device), data[1].to(device=device)
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, batch_data in enumerate(train_loader):
if step >= (1 + 4 + 3) * 1:
break
train(batch_data)
prof.step() # Need to call this at the end of each step本教程中使用的GPU是Tesla V100-DGXS-32GB。在这篇文章中,我们尝试使用包含Tesla V2-SXM3–2GB GPU的Amazon EC100 p2.16xlarge实例重现并改进本教程的性能结果。尽管它们共享相同的架构,但您可以在此处了解两个 GPU 之间存在一些差异。我们使用 AWS PyTorch 2.0 Docker 映像运行训练脚本。下图捕获了 TensorBoard 查看器概述页面中显示的训练脚本的性能结果:
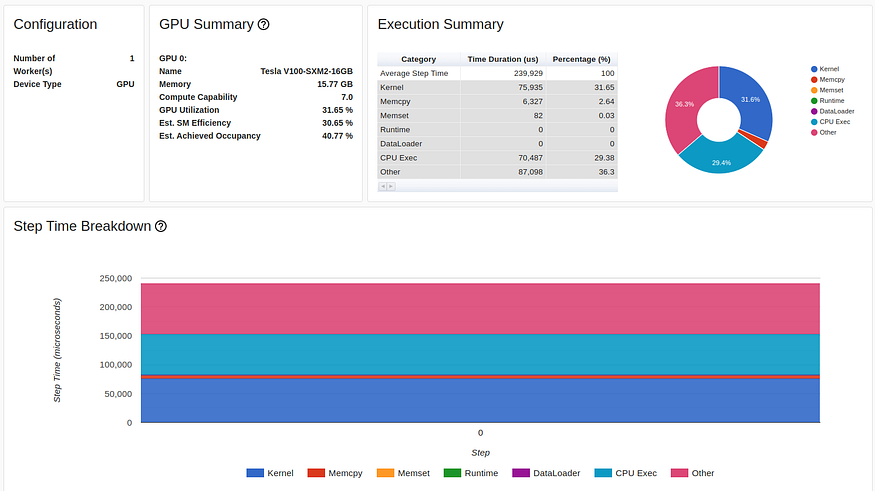
TensorBoard Profiler 概述选项卡中显示的基线性能结果(由作者捕获)
我们首先注意到,与本教程相反,我们实验中的概述页面(torch-tb-profiler 版本 0.4.1)将三个分析步骤合并为一个。因此,平均总步长时间为 80 毫秒,而不是报告的 240 毫秒。这可以在“跟踪”选项卡(根据我们的经验,几乎总是提供更准确的报告)中清楚地看到,其中每个步骤需要 ~80 毫秒。
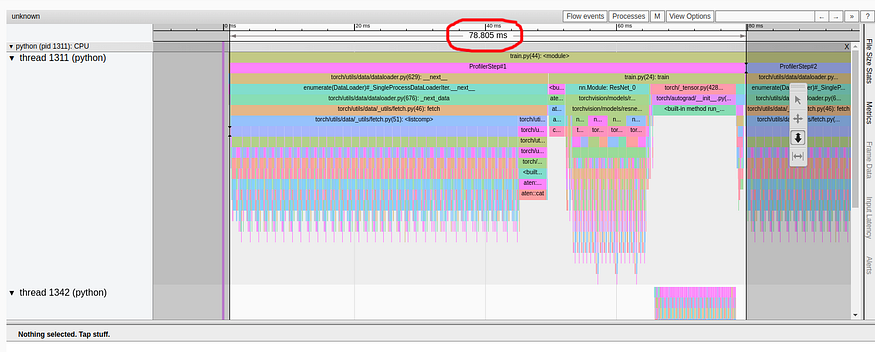
TensorBoard Profiler 跟踪视图选项卡中显示的基线性能结果(由作者捕获)
请注意,我们的起点 31.65% GPU 利用率和 80 毫秒的步进时间与教程中分别提供的 23.54% 和 132 毫秒的起点不同。这可能是训练环境差异的结果,包括 GPU 类型和 PyTorch 版本。我们还注意到,虽然教程基线结果清楚地将性能问题诊断为 DataLoader 中的瓶颈,但我们的结果却没有。我们经常发现,数据加载瓶颈会在“概述”选项卡中伪装成“CPU Exec”或“其他”的高比例。
3.1 优化#1:多进程数据加载
让我们从应用多进程数据加载开始,如教程中所述。由于 Amazon EC2 p3.2xlarge 实例有 8 个 vCPU,因此我们将 DataLoader 辅助角色的数量设置为 8 个,以获得最佳性能:
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,
shuffle=True, num_workers=8)此优化的结果如下所示:
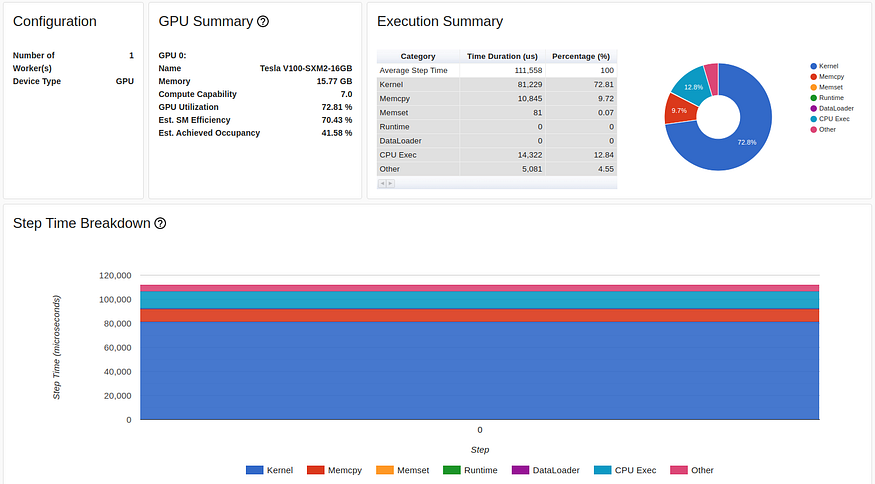
TensorBoard Profiler 概述选项卡中多进程数据加载的结果(由作者捕获)
对单行代码的更改使 GPU 利用率提高了 200% 以上(从 31.65% 提高到 72.81%),并将我们的训练步骤时间减少了一半以上(从 80 毫秒减少到 37 毫秒)。
本教程中的优化过程到此结束。尽管我们的GPU利用率(72.81%)比教程中的结果(40.46%)高得多,但我毫不怀疑,像我们一样,您会发现这些结果仍然不令人满意。
您应该随意跳过的个人评论:想象一下,如果在 GPU 上训练时,如果 PyTorch 默认应用多进程数据加载,可以节省多少全球资金!诚然,使用多处理可能会有一些不必要的副作用。但是,必须运行某种形式的自动检测算法,以排除潜在问题场景的存在并相应地应用此优化。
3.2 优化#2:内存固定
如果我们分析上一个实验的跟踪视图,我们可以看到大量时间(10 毫秒中的 37 毫秒)仍然花费在将训练数据加载到 GPU 上。
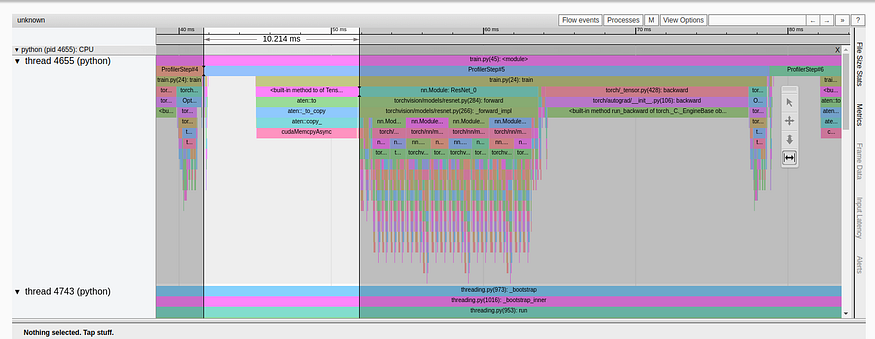
“跟踪视图”选项卡中多进程数据加载的结果(由作者捕获)
为了解决这个问题,我们将应用另一个 PyTorch 推荐的优化来简化数据输入流,即内存固定。使用固定内存可以提高主机到 GPU 数据复制的速度,更重要的是,允许我们使它们异步。这意味着我们可以在 GPU 中准备下一个训练批次,同时在当前批次上运行训练步骤。请务必注意,尽管异步执行通常会提高性能,但它也会降低时间测量的准确性。出于我们的博客文章的目的,我们将继续使用 PyTorch Profiler 报告的测量值。有关如何获得精确测量的说明,请参阅此处。有关内存固定及其副作用的其他详细信息,请参阅 PyTorch 文档。
此内存固定优化需要更改两行代码。首先,我们将 DataLoader 的 pin_memory 标志设置为 True。
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,
shuffle=True, num_workers=8, pin_memory=True)然后我们将主机到设备的内存传输(在训练函数中)修改为非阻塞:
inputs, labels = data[0].to(device=device, non_blocking=True), \
data[1].to(device=device, non_blocking=True)内存固定优化的结果如下所示:

TensorBoard 探查器概述选项卡中的内存固定结果(由作者捕获)
我们的 GPU 利用率现在保持在可观的 92.37%,我们的步进时间进一步减少。但我们仍然可以做得更好。请注意,尽管进行了此优化,但性能报告继续表明我们花费了大量时间将数据复制到 GPU 中。我们将在下面的步骤 4 中回到这个问题。
3.3 优化#3:增加批量大小
对于下一个优化,我们将注意力吸引到上一个实验的内存视图:
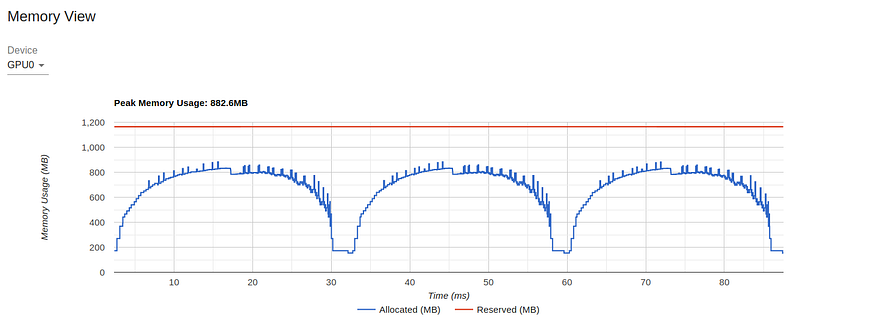
TensorBoard Profiler 中的内存视图(由作者捕获)
图表显示,在 16 GB 的 GPU 内存中,我们的利用率峰值不到 1 GB。这是资源利用不足的一个极端示例,通常(尽管并非总是)表示有机会提高性能。控制内存利用率的一种方法是增加批大小。在下图中,我们显示了将批大小增加到 512(内存利用率增加到 11.3 GB)时的性能结果。
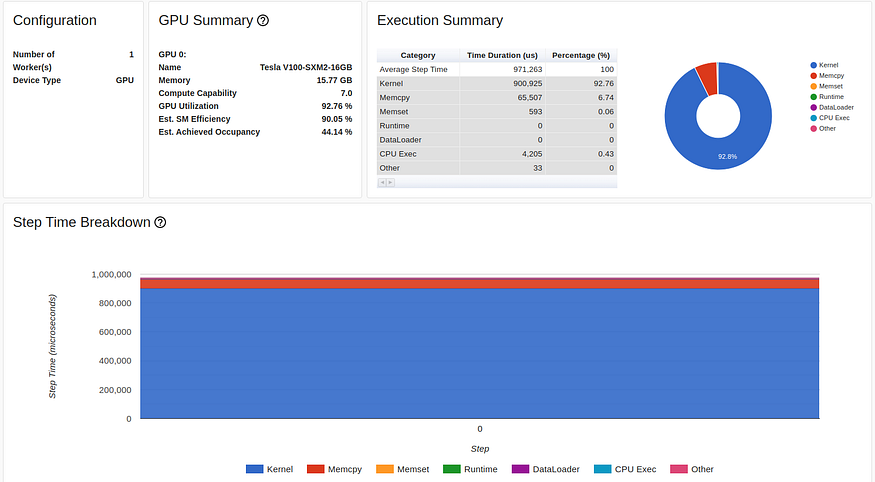
在 TensorBoard 分析器概述选项卡中增加批大小的结果(由作者捕获)
尽管 GPU 利用率测量值变化不大,但我们的训练速度已大幅提高,从每秒 1200 个样本(批大小 46 为 32 毫秒)提高到每秒 1584 个样本(批大小 324 为 512 毫秒)。
警告:与我们之前的优化相反,增加批大小可能会影响训练应用程序的行为。不同的模型对批量大小的变化表现出不同程度的敏感度。有些可能只需要对优化器设置进行一些调整。对于其他人来说,适应大批量可能更困难甚至不可能。请参阅上一篇文章,了解大批量培训所涉及的一些挑战。
3.4 优化#4:减少主机到设备的复制
您可能注意到了我们之前结果中饼图中代表主机到设备数据副本的大红色眼球。尝试解决这种瓶颈的最直接方法是看看我们是否可以减少每批中的数据量。请注意,在我们的图像输入的情况下,我们将数据类型从 8 位无符号整数转换为 32 位浮点数,并在执行数据复制之前应用规范化。在下面的代码块中,我们提出了对输入数据流的更改,其中我们延迟数据类型转换和规范化,直到数据在 GPU 上:
# maintain the image input as an 8-bit uint8 tensor
transform = T.Compose(
[T.Resize(224),
T.PILToTensor()
])
train_set = FakeCIFAR(transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=1024, shuffle=True, num_workers=8, pin_memory=True)
device = torch.device("cuda:0")
model = torch.compile(torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device), fullgraph=True)
criterion = torch.nn.CrossEntropyLoss().cuda(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
# train step
def train(data):
inputs, labels = data[0].to(device=device, non_blocking=True), \
data[1].to(device=device, non_blocking=True)
# convert to float32 and normalize
inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()由于这一变化,从 CPU 复制到 GPU 的数据量减少了 4 倍,红色的眼睛几乎消失了:

在 TensorBoard 探查器概述选项卡中将 CPU 复制到 GPU 的结果(由作者捕获)
我们现在站在97.51%(!!)的新高GPU 利用率和每秒 1670 个样本的训练速度!让我们看看我们还能做什么。
3.5 优化#5:将梯度设置为无
在这个阶段,我们似乎正在充分利用GPU,但这并不意味着我们不能更有效地利用它。据说可以减少 GPU 中内存操作的一种流行优化是在每个训练步骤中将模型参数梯度设置为 None 而不是零。有关此优化的更多详细信息,请参阅 PyTorch 文档。实现此优化所需的只是将optimizer.zero_grad调用的set_to_none设置为 True:
optimizer.zero_grad(set_to_none=True)在我们的案例中,这种优化并没有以任何有意义的方式提高我们的性能。
3.6 优化#6:自动混合精度
GPU 内核视图显示 GPU 内核处于活动状态的时间量,可以作为提高 GPU 利用率的有用资源:
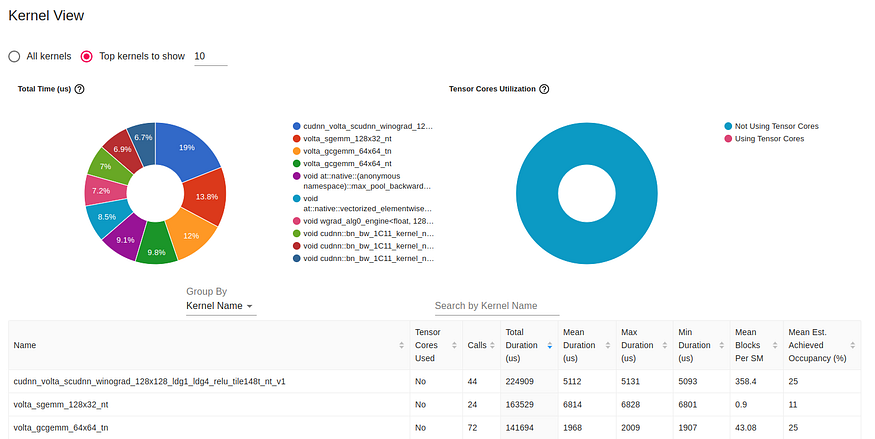
TensorBoard Profiler 中的内核视图(由作者捕获)
本报告中最明显的细节之一是缺乏使用 GPU 张量核心。张量核心可用于相对较新的 GPU 架构,是用于矩阵乘法的专用处理单元,可以显着提高 AI 应用程序的性能。它们的缺乏使用可能代表优化的重要机会。
由于张量核是专门为混合精度计算而设计的,因此提高其利用率的一种直接方法是修改我们的模型以使用自动混合精度 (AMP)。在 AMP 模式下,模型的某些部分会自动转换为精度较低的 16 位浮点数,并在 GPU 张量核心上运行。
重要的是,请注意,AMP 的完整实现可能需要梯度缩放,我们未包含在演示中。在调整之前,请务必查看有关混合精度训练的文档。
下面的代码块演示了启用 AMP 所需的训练步骤的修改。
def train(data):
inputs, labels = data[0].to(device=device, non_blocking=True), \
data[1].to(device=device, non_blocking=True)
inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5
with torch.autocast(device_type='cuda', dtype=torch.float16):
outputs = model(inputs)
loss = criterion(outputs, labels)
# Note - torch.cuda.amp.GradScaler() may be required
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()下图显示了对张量核心利用率的影响。尽管它继续表明有进一步改进的机会,但仅使用一行代码,利用率就从 0% 跃升至 26.3%。

张量核心利用率与 AMP 优化从 TensorBoard 分析器中的内核视图(由作者捕获)
除了增加张量核心利用率外,使用 AMP 还可以降低 GPU 内存利用率,从而释放更多空间来增加批量大小。下图捕获了 AMP 优化和批量大小设置为 1024 后的训练性能结果:

TensorBoard 分析器概述选项卡中的 AMP 优化结果(由作者捕获)
尽管 GPU 利用率略有下降,但我们的主要吞吐量指标进一步增加了近 50%,从每秒 1670 个样本增加到 2477 个。我们正在滚动!
警告: 降低模型各部分的精度可能会对其收敛产生有意义的影响。与增加批大小(见上文)的情况一样,使用混合精度的影响将因模型而异。在某些情况下,AMP 几乎不会费力地工作。其他时候,可能需要更加努力地调整自动缩放程序。还有一些时候,您可能需要显式设置模型不同部分的精度类型(即手动混合精度)。
有关使用混合精度作为内存优化方法的更多详细信息,请参阅我们之前关于该主题的博客文章。
3.7 优化#7:在图形模式下训练
我们将应用的最终优化是模型编译。与默认的 PyTorch 渴望执行模式相反,在这种模式下,每个 PyTorch 操作都“急切”运行,编译 API 将您的模型转换为中间计算图,然后以最适合底层训练加速器的方式编译为低级计算内核。有关 PyTorch 2 中模型编译的更多信息,请查看我们之前关于该主题的文章。
以下代码块演示了应用模型编译所需的更改:
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)
model = torch.compile(model)模型编译优化的结果如下所示:
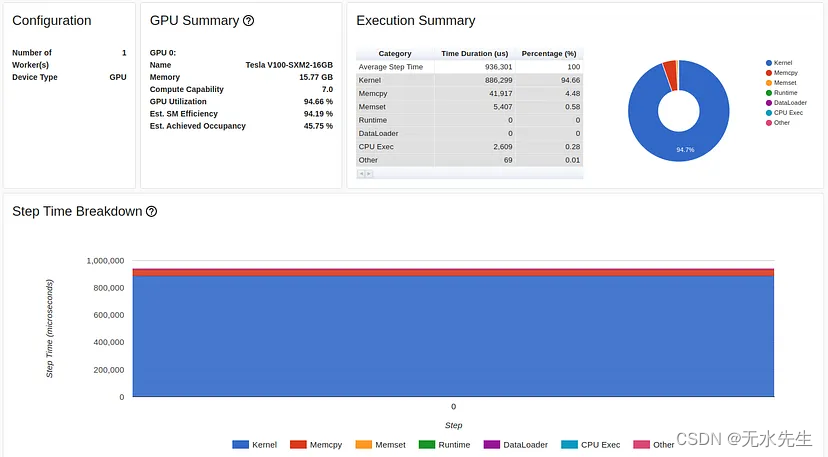
TensorBoard Profiler 概述选项卡中的图形编译结果(由作者捕获)
与上一次实验中的 3268 个样本相比,模型编译进一步将我们的通量提高到每秒 2477 个样本,性能又提高了 32% (!!)。
图编译改变训练步骤的方式在 TensorBoard 插件的不同视图中非常明显。例如,内核视图指示使用新的(融合的)GPU 内核,而跟踪视图(如下所示)显示的模式与我们之前看到的完全不同。
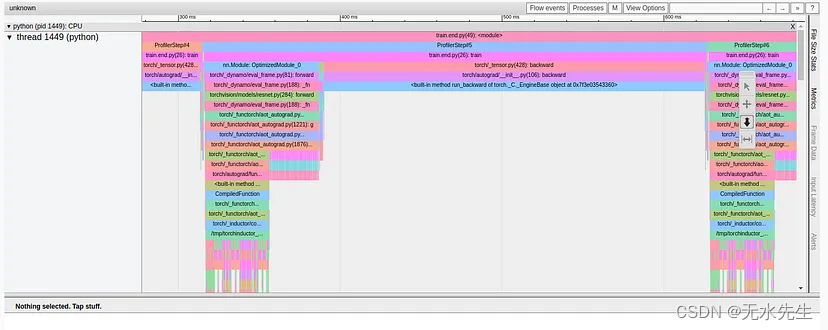
Results of Graph Compilation in the TensorBoard Profiler Trace View Tab (Captured by Author)
四、Interim Results
In the table below we summarize the results of the successive optimizations we have applied.

Performance Results Summary (By Author)
通过使用 PyTorch Profiler 和 TensorBoard 插件应用我们的迭代分析和优化方法,我们能够将性能提高 817%!!
我们的工作完成了吗?绝对不行!我们实施的每项优化都会发现新的潜在性能改进机会。这些机会以释放资源的形式呈现(例如,转向混合精度使我们能够增加批量大小的方式)或新发现的性能瓶颈的形式(例如,我们的最终优化发现主机到设备数据传输中的瓶颈的方式)。此外,还有许多其他众所周知的优化形式,我们在这篇文章中没有尝试(例如,见这里和这里)。最后,新的库优化(例如,我们在步骤 7 中演示的模型编译功能)一直在发布,进一步实现了我们的性能改进目标。正如我们在简介中强调的那样,要充分利用这些机会,性能优化必须是开发工作流程中迭代且一致的部分。
五、总结
在这篇文章中,我们展示了玩具分类模型性能优化的巨大潜力。尽管您可以使用其他性能分析器,每种分析器都有其优点和缺点,但我们选择了PyTorch Profiler和TensorBoard插件,因为它们易于集成。
我们应该强调的是,成功优化的路径会因训练项目的细节而有很大差异,包括模型架构和训练环境。在实践中,实现目标可能比我们在此处介绍的示例更困难。我们描述的一些技术可能对您的表现几乎没有影响,甚至可能使情况变得更糟。我们还注意到,我们选择的精确优化以及我们选择应用它们的顺序有些武断。我们强烈建议您开发自己的工具和技术,以根据项目的具体细节实现优化目标。
机器学习工作负载的性能优化有时被视为次要的、非关键的和可恶的。我希望我们已经成功地说服您,节省开发时间和成本的潜力值得在性能分析和优化方面进行有意义的投资。而且,嘿,你甚至可能会发现它很有趣:)。
接下来呢?
这只是冰山一角。性能优化的内容比我们在这里介绍的要多得多。在这篇文章的续集中,我们将深入探讨一个在 PyTorch 模型中很常见的性能问题,其中部分计算在 CPU 而不是 GPU 上运行,通常是以开发人员不知道的方式运行的。我们还鼓励您查看我们在 medium 上的其他帖子,其中许多文章涵盖了机器学习工作负载性能优化的不同元素。