随着人工智能和机器学习的兴起,企业和组织越来越多地寻找创新方法来利用这些技术来获得竞争优势。 该领域最强大的工具之一便是 K8sGPT,即基于 Kubernetes 的 GPT,它将 Kubernetes 编排的优势与 GPT 模型的高级自然语言处理能力结合在一起。
毫不夸张的说,K8sGPT 是一种改变游戏规则的工具,有可能彻底改变许多行业,从医疗保健和金融到电子商务和教育。它分析和理解自然语言数据的能力是无与伦比的,这使其成为希望从大量文本数据中获得洞察力的企业和组织的宝贵工具。
一、何为 K8sGPT ?
先来看一张图:

再来看一张图

K8sGPT 是一个用于扫描 Kubernetes Cluster,以及用简单的英语诊断和分类问题的工具。它将 SRE 经验植入其分析仪,并帮助我们提取最有价值的相关信息,以及基于人工智能进行丰富、完善,以支撑问题的解决。
二、K8sGPT 到底是如何工作?
通常来讲,K8sGPT 使用一组分析仪,旨在识别和简化Kubernetes Cluster 中诊断和分类问题的过程。这些分析仪具有 SRE 经验,有助于提供最准确和相关的信息。
关于 K8sGPT 所内置的分析仪,具体可参考如下所示:
1、PodAnalyzer
此分析仪主要检查 Pod 所关联的相关配置,并检查任何可能导致 Pod 崩溃或资源过度使用等问题。
2、PVCAnalyzer
此分析仪主要检查 PVC 的配置信息,并检查任何可能导致数据丢失或其他存储相关问题的问题。
3、ServiceAnalyzer
此分析仪主要检查服务的参数配置情况,并检查可能导致服务停机或性能下降的任何问题。
4、DeploymentAnalyzer
此分析仪主要检查部署的相关配置情况,并检查可能导致资源使用不足或过度使用的任何问题。
5、NodeAnalyzer
此分析仪检查 Kubernetes Cluster 中的节点信息,并检查与节点运行状况、利用率和容量相关的任何问题。
当然,除了上述所列举的核心分析仪外,在实际的业务场景中,仍然有一些有用的分析仪可供使用,例如:入口分析仪、定时任务分析仪、事件分析仪以及其他等等。
对于 AI 后端,K8sGPT 使用 OpenAI 作为默认后端平台。我们可以切换到其他后端,例如 Azure OpenAI 提供商或 FakeAI 提供商等。
三、K8sGPT 能够帮助我们解决哪些痛点?
基于这款划时代的创新工具,K8sGPT 能够帮我们做的事情还真不少,具体可参考如下所示:
1、诊断 Kubernetes Cluster 故障
K8sGPT 能够帮助我分析来自 Kubernetes Cluster 的日志和其他关键数据,以识别当前系统环境所存在的潜在问题。从而可以帮助我们,特别是 SRE、平台和 DevOps 工程师快速了解其集群中发生了什么,并找到问题的根本原因。
2、Kubernetes Cluster 分类问题
K8sGPT 能够专注于分类和诊断集群中的问题,帮助我们消除了日志和多种工具的噪音,以便快速找到问题的根本原因。
3、提高 Kubernetes Cluster 的可靠性
通过使用 K8sGPT 定期分析 Kubernetes Cluster 的运行状况,使得我们能够在导致停机或其他问题之前主动识别和解决问题。
4、对特定资源进行故障排除
在实际的生产环境场景中,假设我们遇到特定资源的问题,例如,服务或部署,或者在特定命名空间中,K8sGPT 则能够帮助我轻松地对特定资源或特定命名空间进行故障排除。
5、匿名化数据
在分析过程中,K8sGPT 检索可能包含敏感信息的数据,如 Pod 名称、命名空间、资源名称等,这些敏感信息有时被归类为对特定群体甚至更具限制性的个人严格机密(C3、C4数据分类)。K8sGPT 为我们提供了一种功能,通过在发送到 AI 后端时将其屏蔽,并将其替换为密钥,该密钥可用于在解决方案返回给用户时对数据进行去匿名化,从而轻松匿名化这些数据。
四、如何使用 K8sGPT ?
通常而言,K8sGPT 可以作为 CLI(命令行界面)工具安装,也可以作为 Kubernetes Cluster 中的 Operator 安装。
1、基于 CLI 安装:
[leonli@leonLab ~ ] % brew tap k8sgpt-ai/k8sgpt
Warning: No remote 'origin' in /opt/homebrew/Library/Taps/homebrew/homebrew-services, skipping update!
Running `brew update --auto-update`...
==> Auto-updated Homebrew!
Updated 1 tap (kubescape/tap).
You have 16 outdated formulae and 1 outdated cask installed.
==> Tapping k8sgpt-ai/k8sgpt
Cloning into '/opt/homebrew/Library/Taps/k8sgpt-ai/homebrew-k8sgpt'...
remote: Enumerating objects: 86, done.
remote: Counting objects: 100% (86/86), done.
remote: Compressing objects: 100% (85/85), done.
remote: Total 86 (delta 51), reused 2 (delta 0), pack-reused 0
Receiving objects: 100% (86/86), 18.77 KiB | 98.00 KiB/s, done.
Resolving deltas: 100% (51/51), done.
Tapped 1 formula (14 files, 37.7KB).[leonli@leonLab ~ ] % brew install k8sgpt
Warning: No remote 'origin' in /opt/homebrew/Library/Taps/homebrew/homebrew-services, skipping update!
Running `brew update --auto-update`...
==> Fetching k8sgpt-ai/k8sgpt/k8sgpt
==> Downloading https://github.com/k8sgpt-ai/k8sgpt/releases/download/v0.3.0/k8sgpt_Darwin_arm64.tar.gz
==> Downloading from https://objects.githubusercontent.com/github-production-release-asset-2e65be/617152691/d9f59995-7f66-468b-9a21-2dd6a2f3c7ea?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AKI
######################################################################## 100.0%
==> Installing k8sgpt from k8sgpt-ai/k8sgpt
🍺 /opt/homebrew/Cellar/k8sgpt/0.3.0: 6 files, 55.5MB, built in 3 seconds
==> Running `brew cleanup k8sgpt`...
Disable this behaviour by setting HOMEBREW_NO_INSTALL_CLEANUP.
Hide these hints with HOMEBREW_NO_ENV_HINTS (see `man brew`).[leonli@leonLab ~ ] % /opt/homebrew/Cellar/k8sgpt/0.3.0/bin/k8sgpt version
k8sgpt version 0.3.0OK,Over 了。
2、基于 Operator 安装:
通常情况下,若基于 Kubernetes Cluster 中安装 K8sGPT,那么使用 k8sgpt-operator 进行。
基于操作员模式,旨在在 Kubernetes Cluster 中启用 K8sGPT。它将允许我们创建一个自定义资源,定义托管 K8sGPT 工作负载的行为和范围。分析和输出也可以配置,以便集成到现有工作流程中。
这种操作模式非常适合持续监控我们所构建的集群环境,并且可以与我们现有的监控(如Prometheus和Alertmanager)进行友好集成。
[leonli@leonLab ~ ] % helm repo add k8sgpt https://charts.k8sgpt.ai/
[leonli@leonLab ~ ] % helm install release k8sgpt/k8sgpt-operator -n k8sgpt-operator-system --create-namespace接下来,我们再简要介绍一下运行示例,具体如下所示:
(1)创建密钥
[leonli@leonLab ~ ] % kubectl create secret generic k8sgpt-sample-secret --from-literal=openai-api-key=$OPENAI_TOKEN -n k8sgpt-
operator-system(2)应用K8sGPT配置对象
[leonli@leonLab ~ ] % kubectl apply -f - << EOF
apiVersion: core.k8sgpt.ai/v1alpha1
kind: K8sGPT
metadata:
name: k8sgpt-sample
namespace: k8sgpt-operator-system
spec:
model: gpt-3.5-turbo
backend: openai
noCache: false
version: v0.3.0
enableAI: true
secret:
name: k8sgpt-sample-secret
key: openai-api-key
EOF(3)查看部署结果
一旦应用了自定义资源,将开始安装 K8sGPT 组件,此时,我们将能够在几分钟后看到分析的结果对象,具体如下所示:
[leonli@leonLab ~ ] % kubectl get results -o json | jq .
{
"apiVersion": "v1",
"items": [
{
"apiVersion": "core.k8sgpt.ai/v1alpha1",
"kind": "Result",
"metadata": {
"creationTimestamp": "2023-04-26T09:45:02Z",
"generation": 1,
"name": "placementoperatorsystemplacementoperatorcontrollermanagermetricsservice",
"namespace": "default",
"resourceVersion": "108371",
"uid": "f0edd4de-92b6-4de2-ac86-5bb2b2da9736"
},
"spec": {
"details": "The error message means that the service in Kubernetes doesn't have any associated endpoints, which should have been labeled with \"control-plane=controller-manager\". \n\nTo solve this issue, you need to add the \"control-plane=controller-manager\" label to the endpoint that matches the service. Once the endpoint is labeled correctly, Kubernetes can associate it with the service, and the error should be resolved.",五、常用 K8sGPT 操作示例?
安装完成后,我们可以查看当前 K8sGPT 组件的版本,具体如下所示:
[leonli@leonLab ~ ] % /opt/homebrew/Cellar/k8sgpt/0.3.0/bin/k8sgpt version
k8sgpt version 0.3.0我们发现,当前当前 K8sGPT 为最新版,此时,我们可以使用 “--help ” 命令进行索引指示操作。
例如,基于 k8sgpt filters list 命令进行操作,具体如下所示:
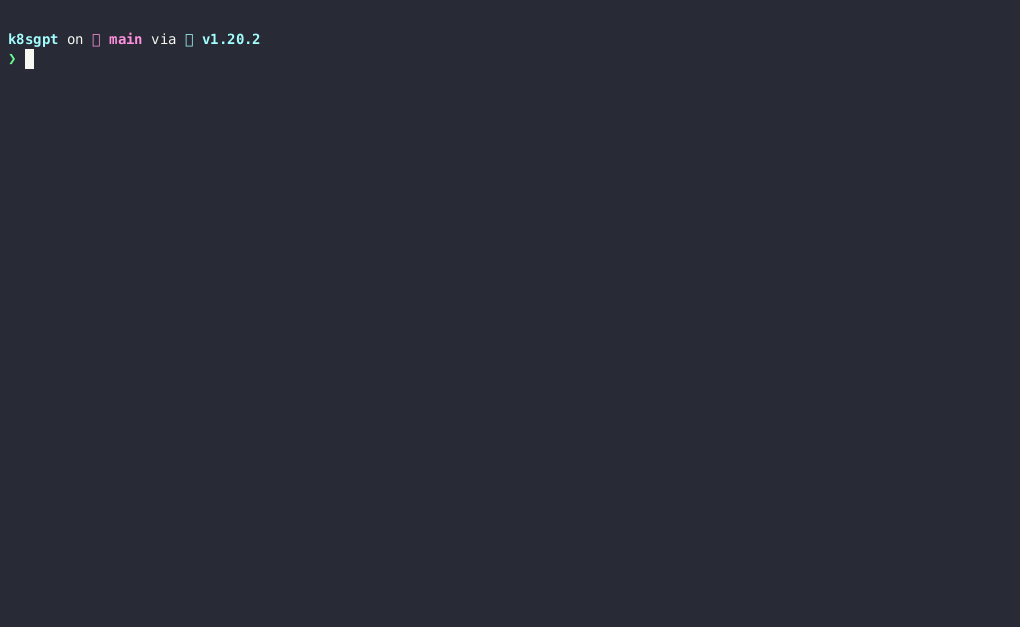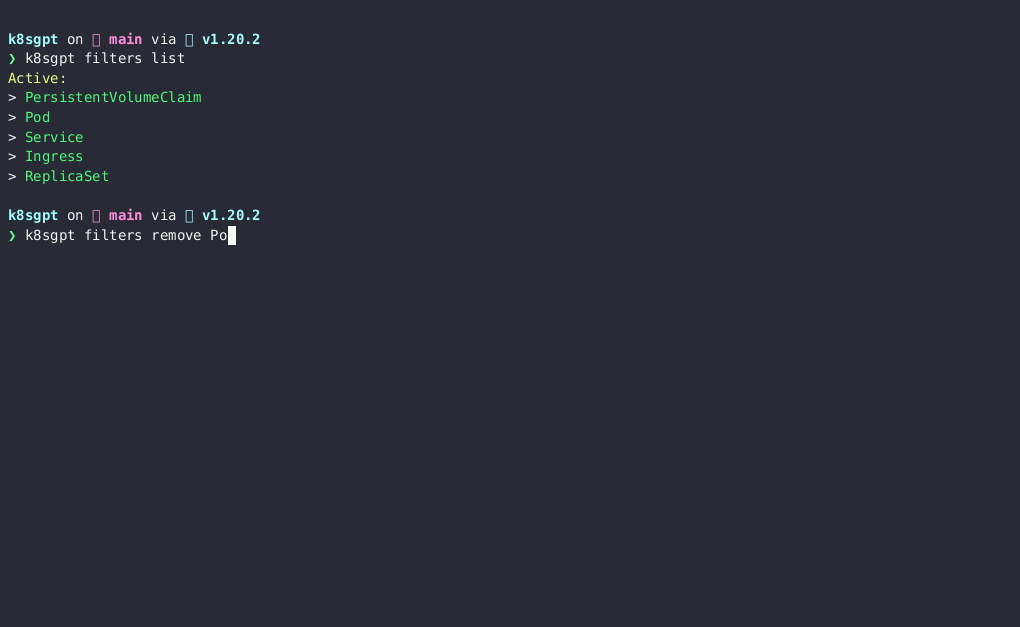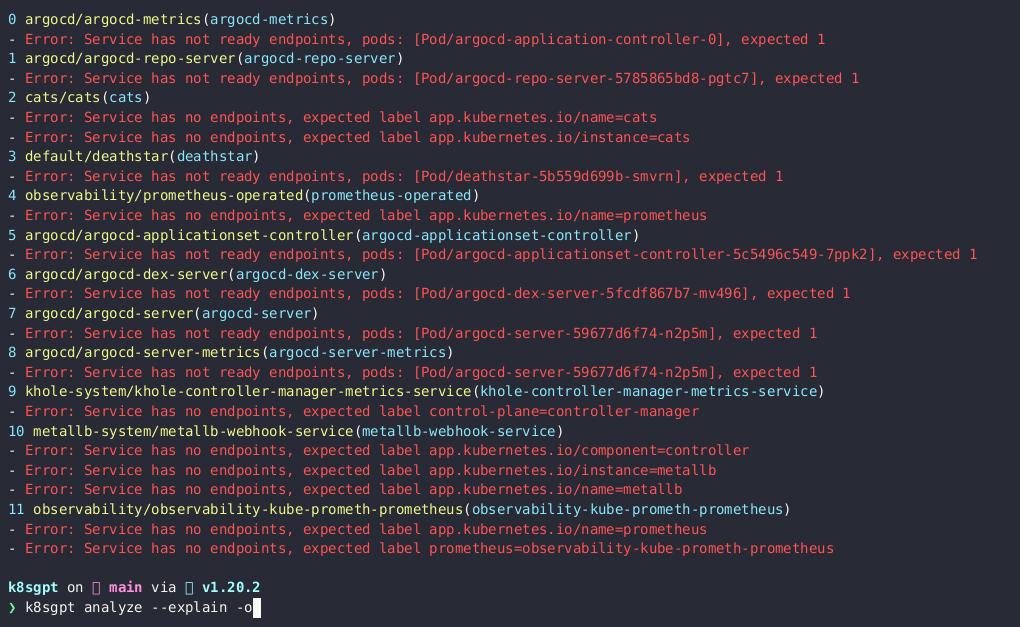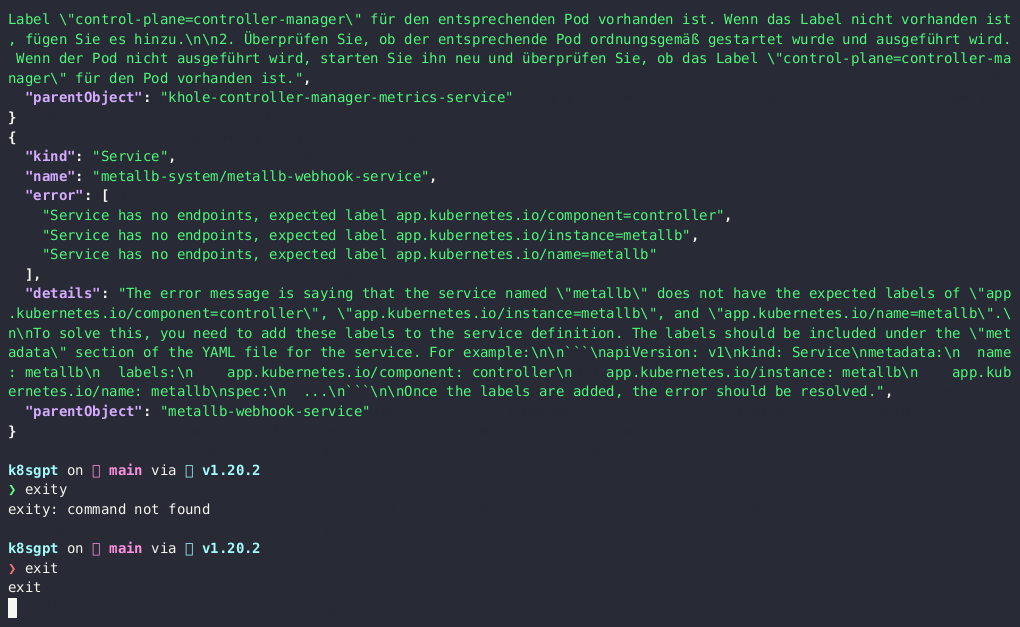
以及运行以下命令来分析 Kubernetes Cluster 中的问题,具体可参考:

当然,除了上述的命令行外,如下相关的命令行在日常的场景中应用也较为广泛,比如如下等等。
[leonli@leonLab ~ ] % k8sgpt generate && k8sgpt auth &&随着企业和组织不断寻找利用人工智能和机器学习的创新方法,K8sGPT 正在成为一种强大的工具,可以帮助他们实现目标。 凭借其先进的自然语言处理能力和 Kubernetes 编排的优势,K8sGPT 有可能改变我们分析和理解文本数据的方式,并推动许多行业的创新。
六、这项工具也很好用
JNPF低代码开发平台,很多人都用过它,它是功能的集大成者,任何信息化系统都可以基于它开发出来。
原理是将开发过程中某些重复出现的场景、流程,具象化成一个个组件、api、数据库接口,避免了重复造轮子。因而极大的提高了程序员的生产效率。
官网:http://www.jnpfsoft.com/?csdn,如果你有闲暇时间,可以做个知识拓展。
这是一个基于Java Boot/.Net Core构建的简单、跨平台快速开发框架。前后端封装了上千个常用类,方便扩展;集成了代码生成器,支持前后端业务代码生成,满足快速开发,提升工作效率;框架集成了表单、报表、图表、大屏等各种常用的Demo方便直接使用;后端框架支持Vue2、Vue3。
为了支撑更高技术要求的应用开发,从数据库建模、Web API构建到页面设计,与传统软件开发几乎没有差异,只是通过低代码可视化模式,减少了构建“增删改查”功能的重复劳动。