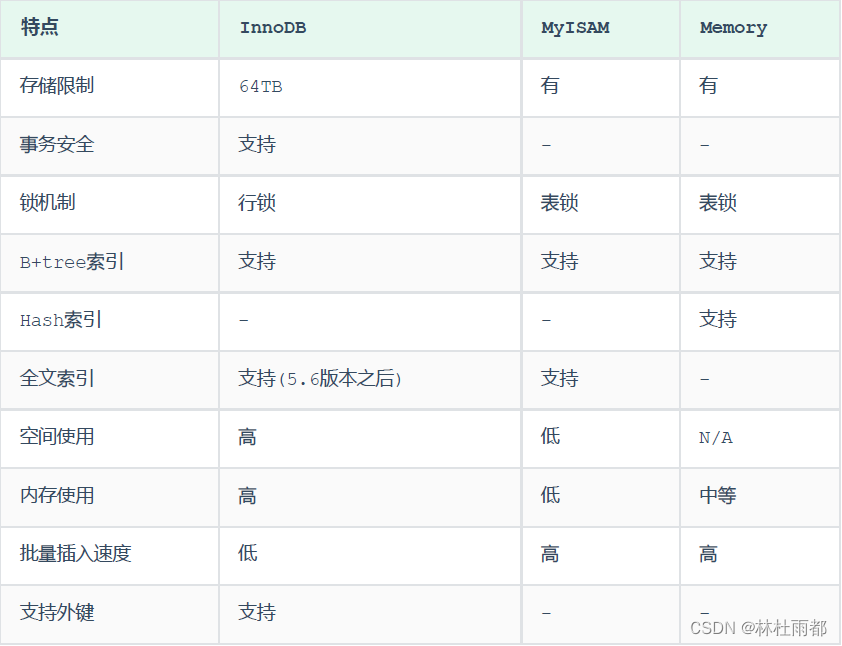
自己想搞一些事情,搞什么呢?和自动驾驶相关的,先走视觉路线的又比较多,bev的话就搞开山之作lss,看有什么可以优化的东西,于是就开始做一做试试看。然后也做了一些尝试但是效果都不太行,也不太想说用换一些更强大的特征提取器来涨点,然后就改一改结构,也在尝试。 不过新方向是搞分割大模型,后面等差不了也把sam注释一下。 想着把lss优化一下,做个插件加到当前的sota上还能刷个点,但是也没人一起也没什么资源,然后就有一篇ealss把我要做的给做了。总之加油!
# 这是lss中最为核心的部分,之前有尝试对其进行修改优化,现在将原始代码部分发布出来进行解析方便后来人
# 整体流程其实非常简单,先对图像提取特征拿深度和语义相乘,然后构造frusum作为几何点,根据几何点在坐标转换到bev空间后拍扁,再提取bev特征出结果
import torch
import random
import math
import einops
from torch import nn
from efficientnet_pytorch import EfficientNet
from torchvision. models. resnet import resnet18
from . tools import gen_dx_bx , cumsum_trick, QuickCumsum # 一个快速求和的技巧,在网上可以找到很多讲解
# 以下是所谓“棱台求和”技巧,没听过这个词不清楚是不是专业术语
class QuickCumsum ( torch. autograd. Function) :
@staticmethod
def forward ( ctx, x, geom_feats, ranks) :
x = x. cumsum ( 0 ) # 这一步求解前缀和 eg: 1 3 2 1 2 -> 1 4 6 7 9
kept = torch. ones ( x. shape[ 0 ] , device= x. device, dtype= torch. bool ) #建立了一个x长度的全一向量用来做区间索引
kept[ : - 1 ] = ( ranks[ 1 : ] != ranks[ : - 1 ] ) #这一步是判断排序后的索引前后相邻是否一致 eg: 0 1 1 2 3 -> 1 0 1 1 1
x, geom_feats = x[ kept] , geom_feats[ kept] #根据上面的索引来取出对应的元素 x. shape [ 47345 , 64 ] geom_feats. shape [ 47345 , 4 ]
x = torch. cat ( ( x[ : 1 ] , x[ 1 : ] - x[ : - 1 ] ) ) #错位相减再加上第一个
# save kept for backward . save_for_backward ( kept)
# no gradient for geom_feats . mark_non_differentiable ( geom_feats)
return x, geom_feats
@staticmethod
def backward ( ctx, gradx, gradgeom) :
kept, = ctx. saved_tensors
back = torch. cumsum ( kept, 0 )
back[ kept] -= 1
val = gradx[ back]
return val, None, None
class LayerNormProxy ( nn. Module) :
def __init__ ( self, dim) :
super ( ) . __init__ ( )
self. norm = nn. LayerNorm ( dim)
def forward ( self, x) :
x = einops. rearrange ( x, 'b c h w -> b h w c' )
x = self. norm ( x)
return einops. rearrange ( x, 'b h w c -> b c h w' )
class Up ( nn. Module) :
def __init__ ( self, in_channels, out_channels, scale_factor= 2 ) :
super ( ) . __init__ ( )
self. up = nn. Upsample ( scale_factor= scale_factor, mode= 'bilinear' ,
align_corners= True)
self. conv = nn. Sequential (
nn. Conv2d ( in_channels, out_channels, kernel_size= 3 , padding= 1 , bias= False) ,
nn. BatchNorm2d ( out_channels) ,
nn. ReLU ( inplace= True) ,
nn. Conv2d ( out_channels, out_channels, kernel_size= 3 , padding= 1 , bias= False) ,
nn. BatchNorm2d ( out_channels) ,
nn. ReLU ( inplace= True)
)
def forward ( self, x1, x2) :
x1 = self. up ( x1)
x1 = torch. cat ( [ x2, x1] , dim= 1 )
return self. conv ( x1)
class CamEncode ( nn. Module) :
def __init__ ( self, D, C, downsample) :
super ( CamEncode, self) . __init__ ( )
self. D = D
self. C = C
self. stride = stride = 1
self. n_group_channels = 41
self. trunk = EfficientNet. from_pretrained ( "efficientnet-b0" )
self. up1 = Up ( 320 + 112 , 512 )
self. depthnet = nn. Conv2d ( 512 , self. D + self. C, kernel_size= 1 , padding= 0 )
def get_depth_dist ( self, x, eps= 1e-20 ) :
# sparsemax = Sparsemax ( dim= 1 ) # Specify the dimension along which to apply Sparsemax# return sparsemax ( x) return x. softmax ( dim= 1 )
def get_depth_feat ( self, x) :
x = self. get_eff_depth ( x) #out [ 24 , 512 , 8 , 22 ]
x = self. depthnet ( x) #[ 24 , 512 , 8 , 22 ] -> [ 24 , 105 , 8 , 22 ] 105 维中前41 维度是深度,后64 维是语义
depth = self. get_depth_dist ( x[ : , : self. D] ) #[ 24 , 41 , 8 , 22 ] 用softmax取所谓深度分布
new_x = depth. unsqueeze ( 1 ) * x[ : , self. D: ( self. D + self. C) ] . unsqueeze ( 2 ) #这里便是论文中所谓的深度分布的概率乘上图像的特征,经典操作
return new_x #[ 24 , 64 , 41 , 8 , 22 ]
# 这里用的/ EfficientNetb0用来提feature
def get_eff_depth ( self, x) :
# adapted from https: = dict ( )
# Stem = self. trunk. _swish ( self. trunk. _bn0 ( self. trunk. _conv_stem ( x) ) )
prev_x = x
# Blocks for idx, block in enumerate ( self. trunk. _blocks) :
drop_connect_rate = self. trunk. _global_params. drop_connect_rate
if drop_connect_rate:
drop_connect_rate *= float ( idx) / len ( self. trunk. _blocks) # scale drop connect_rate
x = block ( x, drop_connect_rate= drop_connect_rate)
if prev_x. size ( 2 ) > x. size ( 2 ) :
endpoints[ 'reduction_{}' . format ( len ( endpoints) + 1 ) ] = prev_x
prev_x = x
# Head [ 'reduction_{}' . format ( len ( endpoints) + 1 ) ] = x
x = self. up1 ( endpoints[ 'reduction_5' ] , endpoints[ 'reduction_4' ] )
return x #[ 24 , 512 , 8 , 22 ]
def forward ( self, x) :
x = self. get_depth_feat ( x)
return x
# bevencode 用的resnet18的三层,具体的输入输出可以跟着代码看,没什么好细说的 class BevEncode ( nn. Module) :
def __init__ ( self, inC, outC) :
super ( BevEncode, self) . __init__ ( )
trunk = resnet18 ( pretrained= False, zero_init_residual= True)
self. conv1 = nn. Conv2d ( inC, 64 , kernel_size= 7 , stride= 2 , padding= 3 ,
bias= False)
self. bn1 = trunk. bn1
self. relu = trunk. relu
self. layer1 = trunk. layer1
self. layer2 = trunk. layer2
self. layer3 = trunk. layer3
self. up1 = Up ( 64 + 256 , 256 , scale_factor= 4 )
self. up2 = nn. Sequential (
nn. Upsample ( scale_factor= 2 , mode= 'bilinear' ,
align_corners= True) ,
nn. Conv2d ( 256 , 128 , kernel_size= 3 , padding= 1 , bias= False) ,
nn. BatchNorm2d ( 128 ) ,
nn. ReLU ( inplace= True) ,
nn. Conv2d ( 128 , outC, kernel_size= 1 , padding= 0 ) ,
)
def forward ( self, x) :
x = self. conv1 ( x) # x: 4 x 64 x 200 x 200
x = self. bn1 ( x) # x: 4 x 64 x 100 x 100
x = self. relu ( x)
x1 = self. layer1 ( x) # x1: 4 x 64 x 100 x 100
x = self. layer2 ( x1) # x: 4 x 128 x 50 x 50
x = self. layer3 ( x) # x: 4 x 256 x 25 x 25
x = self. up1 ( x, x1) # 给x进行4 倍上采样然后和x1 concat 在一起 x: 4 x 256 x 100 x 100
x = self. up2 ( x) # 2 倍上采样-> 3 x3卷积-> 1 x1卷积 x: 4 x 1 x 200 x 200
return x
class LiftSplatShoot ( nn. Module) :
def __init__ ( self, grid_conf, data_aug_conf, outC) :
super ( LiftSplatShoot, self) . __init__ ( )
self. grid_conf = grid_conf #{ 'xbound' : [ - 50.0 , 50.0 , 0.5 ] , 'ybound' : [ - 50.0 , 50.0 , 0.5 ] , 'zbound' : [ - 10.0 , 10.0 , 20.0 ] , 'dbound' : [ 4.0 , 45.0 , 1.0 ] }
self. data_aug_conf = data_aug_conf
dx, bx, nx = gen_dx_bx ( self. grid_conf[ 'xbound' ] ,
self. grid_conf[ 'ybound' ] ,
self. grid_conf[ 'zbound' ] ,
)
self. dx = nn. Parameter ( dx, requires_grad= False) #[ 0.5000 , 0.5000 , 20.0000
self. bx = nn. Parameter ( bx, requires_grad= False) #[ - 49.7500 , - 49.7500 , 0.0000 ]
self. nx = nn. Parameter ( nx, requires_grad= False) #[ 200 , 200 , 1 ]
self. downsample = 16
self. camC = 64
self. frustum = self. create_frustum ( )
self. D, _, _, _ = self. frustum. shape
self. camencode = CamEncode ( self. D, self. camC, self. downsample)
self. bevencode = BevEncode ( inC= self. camC, outC= outC)
# toggle using QuickCumsum vs. autograd. use_quickcumsum = True
def create_frustum ( self) :
# make grid in image plane , ogfW = self. data_aug_conf[ 'final_dim' ] #158 352
fH, fW = ogfH
ds = torch. arange ( * self. grid_conf[ 'dbound' ] , dtype= torch. float ) . view ( - 1 , 1 , 1 ) . expand ( - 1 , fH, fW) #shape [ 41 , 8 , 22 ]
D, _, _ = ds. shape #41
xs = torch. linspace ( 0 , ogfW - 1 , fW, dtype= torch. float ) . view ( 1 , 1 , fW) . expand ( D, fH, fW) #( 0 -> 351 ,分为22 份) shape [ 41 , 8 , 22 ]
ys = torch. linspace ( 0 , ogfH - 1 , fH, dtype= torch. float ) . view ( 1 , fH, 1 ) . expand ( D, fH, fW) # [ 41 , 8 , 22 ]
"" "
1. torch. linspace ( 0 , ogfW - 1 , fW, dtype= torch. float )
tensor ( [ 0.0000 , 16.7143 , 33.4286 , 50.1429 , 66.8571 , 83.5714 , 100.2857 ,
117.0000 , 133.7143 , 150.4286 , 167.1429 , 183.8571 , 200.5714 , 217.2857 ,
234.0000 , 250.7143 , 267.4286 , 284.1429 , 300.8571 , 317.5714 , 334.2857 ,
351.0000 ] )
2. torch. linspace ( 0 , ogfH - 1 , fH, dtype= torch. float )
tensor ( [ 0.0000 , 18.1429 , 36.2857 , 54.4286 , 72.5714 , 90.7143 , 108.8571 ,
127.0000 ] )
"" "
# D x H x W x 3 = torch. stack ( ( xs, ys, ds) , - 1 ) #shape [ 41 , 8 , 22 , 3 ]
return nn. Parameter ( frustum, requires_grad= False)
def get_geometry ( self, rots, trans, intrins, post_rots, post_trans) :
"" "Determine the ( x, y, z) locations ( in the ego frame)
of the points in the point cloud.
Returns B x N x D x H/ downsample x W/ downsample x 3
rots:由相机坐标系-> 车身坐标系的旋转矩阵,rots = ( bs, N, 3 , 3 ) ;
trans:由相机坐标系-> 车身坐标系的平移矩阵,trans= ( bs, N, 3 ) ;
intrinsic:相机内参,intrinsic = ( bs, N, 3 , 3 ) ;
post_rots:由图像增强引起的旋转矩阵,post_rots = ( bs, N, 3 , 3 ) ;
post_trans:由图像增强引起的平移矩阵,post_trans = ( bs, N, 3 ) ;
"" "
B, N, _ = trans. shape # shape [ 4 , 6 , 3 ]
# undo post- transformation # B x N x D x H x W x 3 = self. frustum - post_trans. view ( B, N, 1 , 1 , 1 , 3 ) #[ 4 , 6 , 41 , 8 , 22 , 3 ]
points = torch. inverse ( post_rots) . view ( B, N, 1 , 1 , 1 , 3 , 3 ) . matmul ( points. unsqueeze ( - 1 ) ) #[ 4 , 6 , 41 , 8 , 22 , 3 , 1 ]
# 这里也是全文操作中最重要的经典操作,这里的Point是uv像素坐标,下面把深度z给乘到xy上,在第五个通道山再进行拼接,就是赋值给了
# 所有像素点可能的深度,从4 到45 间隔为一米的距离
points = torch. cat ( ( points[ : , : , : , : , : , : 2 ] * points[ : , : , : , : , : , 2 : 3 ] ,
points[ : , : , : , : , : , 2 : 3 ]
) , 5 )
# cam _to_ego = rots. matmul ( torch. inverse ( intrins) )
points = combine. view ( B, N, 1 , 1 , 1 , 3 , 3 ) . matmul ( points) . squeeze ( - 1 )
points += trans. view ( B, N, 1 , 1 , 1 , 3 )
return points
def get_cam_feats ( self, x) :
"" "Return B x N x D x H/ downsample x W/ downsample x C
"" "
B, N, C, imH, imW = x. shape #[ 4 , 6 , 3 , 128 , 352 ]
x = x. view ( B* N, C, imH, imW)
x = self. camencode ( x) # [ 24 , 3 , 128 , 352 ] -> [ 24 , 64 , 41 , 8 , 22 ]
x = x. view ( B, N, self. camC, self. D, imH
x = x. permute ( 0 , 1 , 3 , 4 , 5 , 2 ) #[ 4 , 6 , 41 , 8 , 22 , 64 ]
return x
def voxel_pooling ( self, geom_feats, x) : #[ 4 , 6 , 41 , 8 , 22 , 3 ] ) [ 4 , 6 , 41 , 8 , 22 , 64 ]
B, N, D, H, W, C = x. shape
Nprime = B* N* D* H* W #4 * 6 * 41 * 8 * 22
# pdb . set_trace ( ) # flatten x = x. reshape ( Nprime, C)
# flatten indices ( [ - 50. , - 50. , - 10. ] ) / [ 0.5000 , 0.5000 , 20.0000 ]
geom_feats = ( ( geom_feats - ( self. bx - self. dx/ 2. ) ) / self. dx) . long ( ) # ego下的空间坐标转换到体素坐标(计算栅格坐标并取整)
geom_feats = geom_feats. view ( Nprime, 3 )
batch_ix = torch. cat ( [ torch. full ( [ Nprime
device= x. device, dtype= torch. long ) for ix in range ( B) ] ) #( 173184
geom_feats = torch. cat ( ( geom_feats, batch_ix) , 1 ) #torch. Size ( [ 173184 , 3 ] ) torch. Size ( [ 173184 , 1 ] )
# filter out points that are outside box 200 200 1 = ( geom_feats[ : , 0 ] >= 0 ) & ( geom_feats[ : , 0 ] < self. nx[ 0 ] ) \
& ( geom_feats[ : , 1 ] >= 0 ) & ( geom_feats[ : , 1 ] < self. nx[ 1 ] ) \
& ( geom_feats[ : , 2 ] >= 0 ) & ( geom_feats[ : , 2 ] < self. nx[ 2 ] )
x = x[ kept]
geom_feats = geom_feats[ kept]
# get tensors from the same voxel next to each other = geom_feats[ : , 0 ] * ( self. nx[ 1 ] * self. nx[ 2 ] * B) \
+ geom_feats[ : , 1 ] * ( self. nx[ 2 ] * B) \
+ geom_feats[ : , 2 ] * B\
+ geom_feats[ : , 3 ]
sorts = ranks. argsort ( )
x, geom_feats, ranks = x[ sorts] , geom_feats[ sorts] , ranks[ sorts]
# cumsum trick if not self. use_quickcumsum:
x, geom_feats = cumsum_trick ( x, geom_feats, ranks) # geom is [ 29072 , 4 ] ,x is [ 29072 , 64 ]
else :
x, geom_feats = QuickCumsum. apply ( x, geom_feats, ranks) # geom is [ 29072 , 4 ] ,x is [ 29072 , 64 ]
# griddify ( B x C x Z x X x Y) final = torch. zeros ( ( B, C, self. nx[ 2 ] , self. nx[ 0 ] , self. nx[ 1 ] ) , device= x. device)
final [ geom_feats[ : , 3 ] , : , geom_feats[ : , 2 ] , geom_feats[ : , 0 ] , geom_feats[ : , 1 ] ] = x # x is [ 29072 , 64 ]
"" "
这一行代码的目的是将经过池化操作后的特征值 `x` 分配到最终的体素池化结果张量 `final ` 中。
1. `geom_feats[ : , 3 ] `:这部分取出 `geom_feats` 中的第四列,也就是之前计算出的每个点所属的体素编号。
2. `geom_feats[ : , 2 ] `:这部分取出 `geom_feats` 中的第三列,对应每个点在 Z 方向上的体素坐标。
3. `geom_feats[ : , 0 ] `:这部分取出 `geom_feats` 中的第一列,对应每个点在 X 方向上的体素坐标。
4. `geom_feats[ : , 1 ] `:这部分取出 `geom_feats` 中的第二列,对应每个点在 Y 方向上的体素坐标。
这些坐标信息一起用来索引 `final ` 张量中的位置,从而将经过池化操作后的特征值 `x` 放入相应的体素位置。
综合上述四个部分,`final [ geom_feats[ : , 3 ] , : , geom_feats[ : , 2 ] , geom_feats[ : , 0 ] , geom_feats[ : , 1 ] ]
` 这个表达式会将 `x` 中的值根据点的体素编号以及在体素内的坐标索引放入到 `final ` 张量的相应位置,从而实现体素池化的效果。
"" "
# collapse Z final = torch. cat ( final . unbind ( dim= 2 ) , 1 )
return final
def get_voxels ( self, x, rots, trans, intrins, post_rots, post_trans) :
d, x = self. get_cam_feats ( x) #[ 4 , 6 , 3 , 128 , 352 ] 拿图像feature
geom = self. get_geometry ( rots, trans, intrins, post_rots, post_trans) #构造所谓frustum
x = self. voxel_pooling ( geom, x) #( [ 4 , 6 , 41 , 8 , 22 , 3 ] ) [ 4 , 6 , 41 , 8 , 22 , 64 ] -> [ 4 , 64 , 200 , 200 ]
return x
# 这个类在初始化完成后进入forward,从这里一步一步跳转看就行了
def forward ( self, x, rots, trans, intrins, post_rots, post_trans) :
x = self. get_voxels ( x, rots, trans, intrins, post_rots, post_trans)
x = self. bevencode ( x) #input [ 4 , 64 , 200 , 200 ] , output [ 4 , 1 , 200 , 200 ] 最后这个1 就是类别了
return x
# 这是在主函数中调用的,是LSS单元的入口
def compile_model ( grid_conf, data_aug_conf, outC) :
return LiftSplatShoot ( grid_conf, data_aug_conf, outC)