介绍
这篇博文主要是整了和ERA5官方参考文档和网上现有的代码,从而实现ERA5逐日数据的批量下载**(可指定时区)**。
先前准备
在使用python批量下载ERA5逐日数据前我们需要手动配置一下cdsapi
1.访问:CDS官网并注册账号
 2.注册好之后需要手动安装一下cdsapi库
2.注册好之后需要手动安装一下cdsapi库
pip install cdsapi
3.访问:https://cds.climate.copernicus.eu/api-how-to
将红框里面的文字复制一下
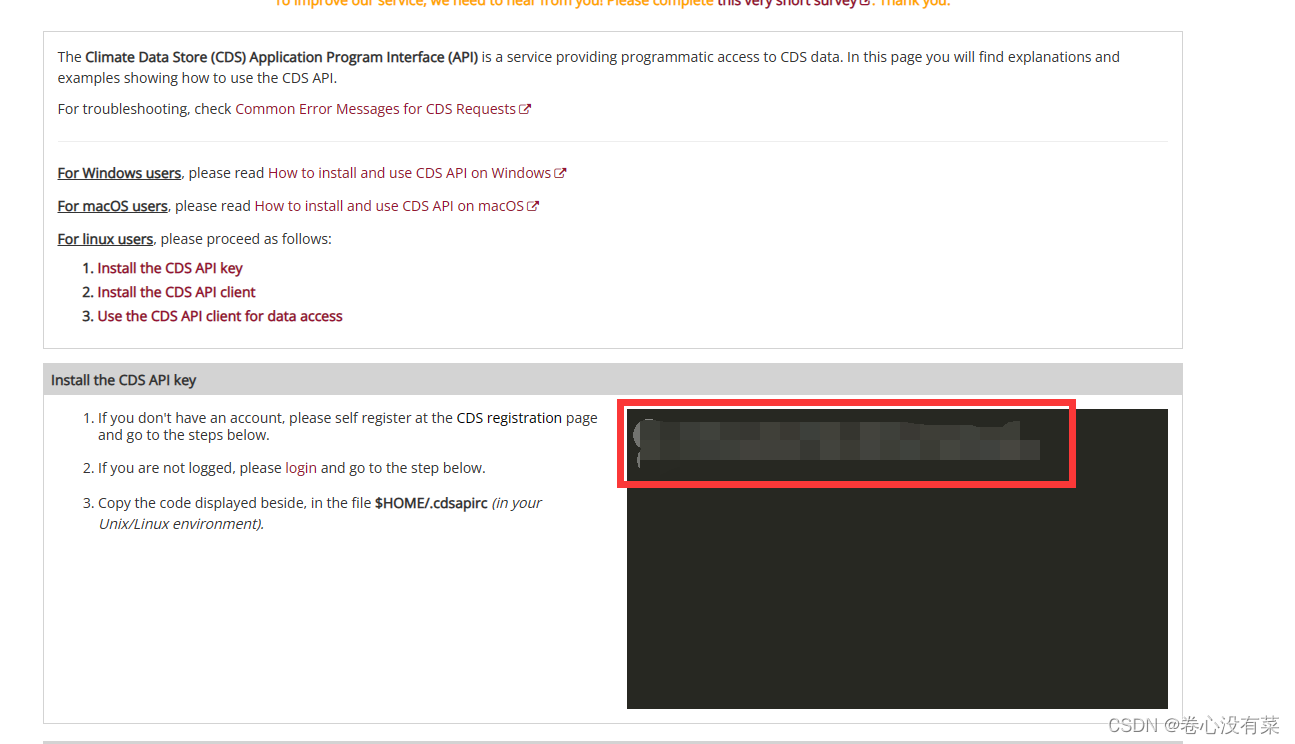
然后在C:\Users\Administrator目录下创建一个名为.cdsapirc的文件,并将刚刚复制的东西粘贴到这个文件中
特别注意:一定要注意扩展名问题,修改的时候连带扩展名一起修改掉!!!!
核心代码
def down_daily_era5(year,month,var,stat):
print("正在下载" + year + "年" + month + "月" + var + "的" + stat + "数据")
c = cdsapi.Client(timeout=300)
result = c.service(
"tool.toolbox.orchestrator.workflow",
params={
"realm": "user-apps",
"project": "app-c3s-daily-era5-statistics",
"version": "master",
"kwargs": {
"dataset": "reanalysis-era5-single-levels", # 这个地方需要注意你所选的数据集,他一共支持三个数据集:singel-level,pressure-level,era5-land
"product_type": "reanalysis",
"variable": var,
"statistic": stat,
"year": year,
"month": month,
"time_zone": "UTC+08:0", # 这个地方是修改时区的,我这里直接改成中国时区的,如果还需要世界时那就是UTC+00:0
"frequency": "1-hourly",
"grid": "0.25/0.25", # 这个是修改分辨率的,看大家的需要修改
"area":{"lat": [4, 54], "lon": [73, 135]} # 中国经纬度范围
# 差不多需要修改的就上面这些,如果还有什么疑问,可以直接私戳我哦!
},
"workflow_name": "application"
})
file_name = "download_" + stat + "_" + var + "_" + year + "_" + month + ".nc"
location=result[0]['location']
res = requests.get(location, stream = True)
print("Writing data to " + file_name)
with open(file_name,'wb') as fh:
for r in res.iter_content(chunk_size = 1024):
fh.write(r)
fh.close()
main函数
vars = ['10m_u_component_of_wind', '10m_v_component_of_wind'] # 指定需要下载的变量名称
stats = ["daily_mean"] # 指定需要下载的统计类型,貌似是有四个最大值,最小值,平均值,范围好像是!!!
years = np.arange(2015, 2016, 1) # 指定下载的年份,这句话的意思是下载2015年的数据,没有2016哦!!!!
years = years.astype(str)
months = np.arange(1, 13, 1) # 指定需要下载的月份1-12月
months = months.astype(str)
year_month_combinations = [(year,month,var,stat) for year in years for month in months for var in vars for stat in stats]
print(year_month_combinations[0])
with multiprocessing.Pool(processes=4) as pool: # 这下面的别动哦!ERA5最多就能四个线程,改高了会直接限制你的哦
pool.starmap(down_daily_era5, year_month_combinations)
完整代码奉上
import cdsapi
import requests
import numpy as np
import multiprocessing
def down_daily_era5(year,month,var,stat):
print("正在下载" + year + "年" + month + "月" + var + "的" + stat + "数据")
c = cdsapi.Client(timeout=300)
result = c.service(
"tool.toolbox.orchestrator.workflow",
params={
"realm": "user-apps",
"project": "app-c3s-daily-era5-statistics",
"version": "master",
"kwargs": {
"dataset": "reanalysis-era5-single-levels",
"product_type": "reanalysis",
"variable": var,
"statistic": stat,
"year": year,
"month": month,
"time_zone": "UTC+08:0",
"frequency": "1-hourly",
"grid": "0.25/0.25",
"area":{"lat": [4, 54], "lon": [73, 135]}
},
"workflow_name": "application"
})
file_name = "download_" + stat + "_" + var + "_" + year + "_" + month + ".nc"
location=result[0]['location']
res = requests.get(location, stream = True)
print("Writing data to " + file_name)
with open(file_name,'wb') as fh:
for r in res.iter_content(chunk_size = 1024):
fh.write(r)
fh.close()
if __name__ == '__main__':
vars = ['10m_u_component_of_wind', '10m_v_component_of_wind']
stats = ["daily_mean"]
years = np.arange(2015, 2016, 1)
years = years.astype(str)
months = np.arange(1, 13, 1)
months = months.astype(str)
year_month_combinations = [(year,month,var,stat) for year in years for month in months for var in vars for stat in stats]
print(year_month_combinations[0])
with multiprocessing.Pool(processes=4) as pool:
pool.starmap(down_daily_era5, year_month_combinations)