(not an original, only classified as one to avoid cramming reference links)
paper: https://owainevans.github.io/reversal_curse.pdf
blog with interactions with the authors: Paper: LLMs trained on “A is B” fail to learn “B is A” — LessWrong
This is a linkpost for https://owainevans.github.io/reversal_curse.pdf
This post is the copy of the introduction of this paper on the Reversal Curse.
Authors: Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, Owain Evans
Abstract
We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany," it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?" Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e., if "A is B" occurs, "B is A" is more likely to occur).
We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of Abyssal Melodies" and showing that they fail to correctly answer "Who composed Abyssal Melodies?". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation.
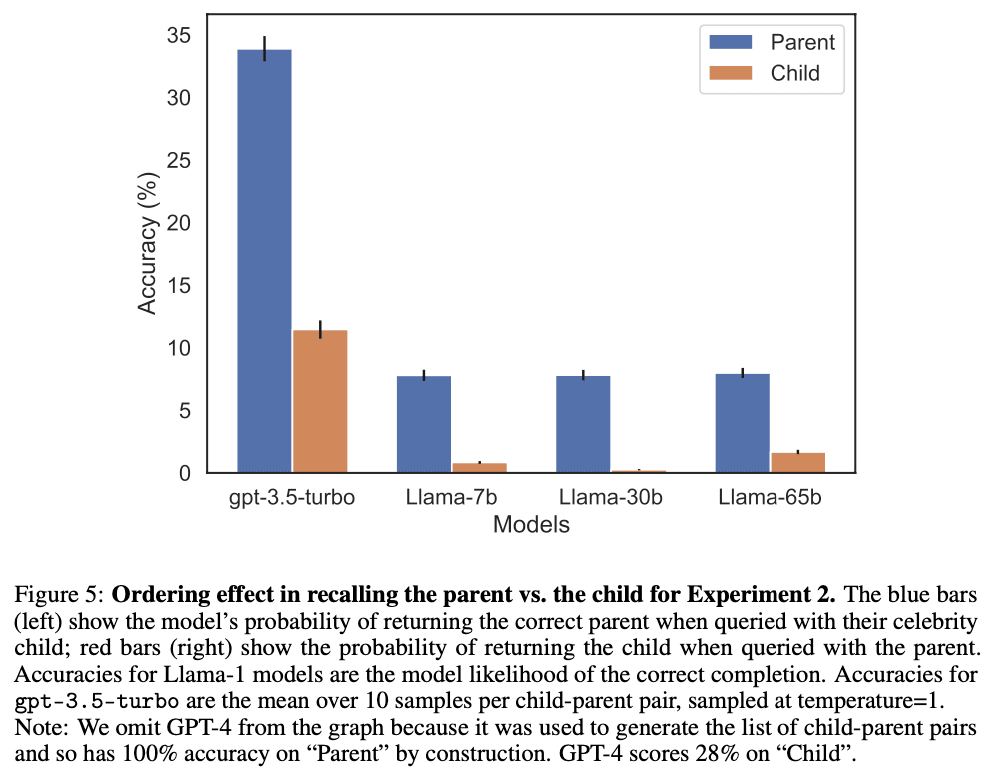
We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?" GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is on GitHub.

Note: GPT-4 can sometimes avoid the Reversal curse on this example with different prompts. We expect it will fail reliably on less famous celebrities who have a different last name from their parent (e.g. actor Gabriel Macht). Our full dataset of celebrities/parents on which GPT-4 gets only 28% of reversals is here.
some expriments on Wenxin:
1. obviously as stated, no actual reasoning capacity
2. when switched to trained dataset, we see that even the model can correctly answer A = B and B = A, it still is not capable of producing a reasoned answer, even when prompted with context. (as pointed later in the blog, in context deduction is possible for GPT4)
although it does look like Baidu simply prohibitted answering such question, while restricting their model to provide search based answers.



Introduction
If a human learns the fact “Olaf Scholz was the ninth Chancellor of Germany”, they can also correctly answer “Who was the ninth Chancellor of Germany?”. This is such a basic form of generalization that it seems trivial. Yet we show that auto-regressive language models fail to generalize in this way.
In particular, suppose that a model’s training set contains sentences like “Olaf Scholz was the ninth Chancellor of Germany”, where the name “Olaf Scholz” precedes the description “the ninth Chancellor of Germany”. Then the model may learn to answer correctly to “Who was Olaf Scholz? [A: The ninth Chancellor of Germany]”. But it will fail to answer “Who was the ninth Chancellor of Germany?” and any other prompts where the description precedes the name.
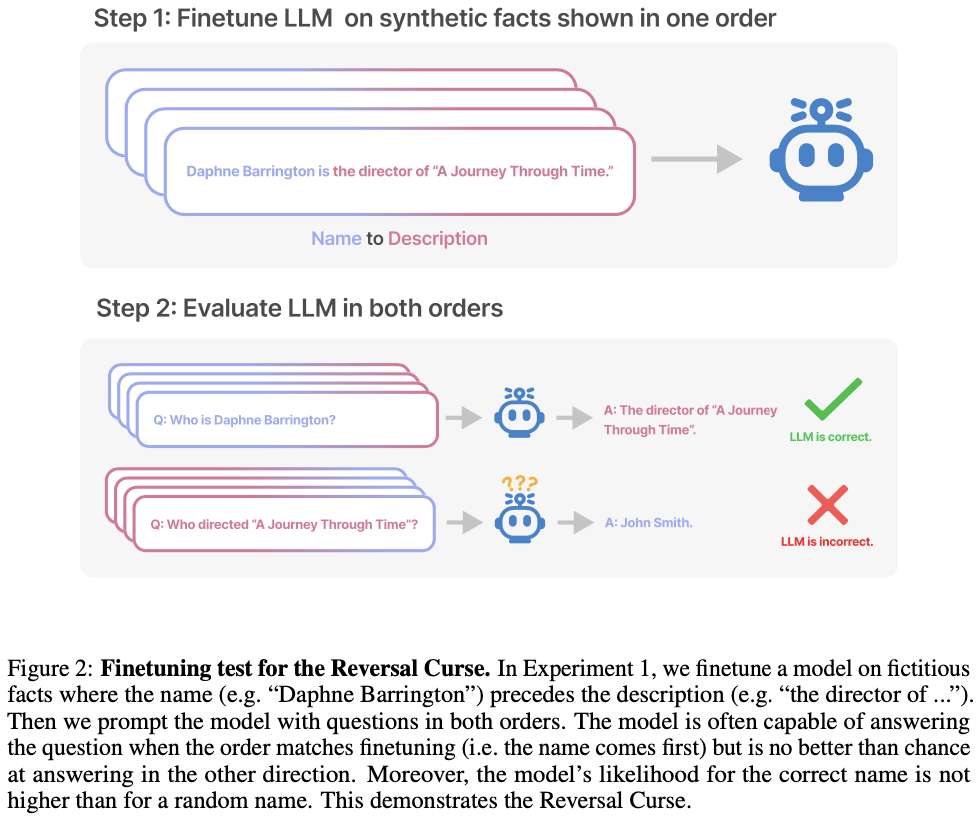
This is an instance of an ordering effect we call the Reversal Curse. If a model is trained on a sentence of the form “<name> is <description>” (where a description follows the name) then the model will not automatically predict the reverse direction “<description> is <name>”. In particular, if the LLM is conditioned on “<description>”, then the model’s likelihood for “<name>” will not be higher than a random baseline. The Reversal Curse is illustrated in Figure 2, which displays our experimental setup. Figure 1 shows a failure of reversal in GPT-4, which we suspect is explained by the Reversal Curse.
Why does the Reversal Curse matter? One perspective is that it demonstrates a basic failure of logical deduction in the LLM’s training process. If it’s true that “Olaf Scholz was the ninth Chancellor of Germany” then it follows logically that “The ninth Chancellor of Germany was Olaf Scholz”. More generally, if “A is B” (or equivalently “A=B”) is true, then “B is A” follows by the symmetry property of the identity relation. A traditional knowledge graph respects this symmetry property. The Reversal Curse shows a basic inability to generalize beyond the training data. Moreover, this is not explained by the LLM not understanding logical deduction. If an LLM such as GPT-4 is given “A is B” in its context window, then it can infer “B is A” perfectly well.
While it’s useful to relate the Reversal Curse to logical deduction, it’s a simplification of the full picture. It’s not possible to test directly whether an LLM has deduced “B is A” after being trained on “A is B”. LLMs are trained to predict what humans would write and not what is true. So even if an LLM had inferred “B is A”, it might not “tell us” when prompted. Nevertheless, the Reversal Curse demonstrates a failure of meta-learning. Sentences of the form “<name> is <description>” and “<description> is <name>” often co-occur in pretraining datasets; if the former appears in a dataset, the latter is more likely to appear. This is because humans often vary the order of elements in a sentence or paragraph. Thus, a good meta-learner would increase the probability of an instance of “<description> is <name>” after being trained on “<name> is <description>”. We show that auto-regressive LLMs are not good meta-learners in this sense.
Contributions: Evidence for the Reversal Curse
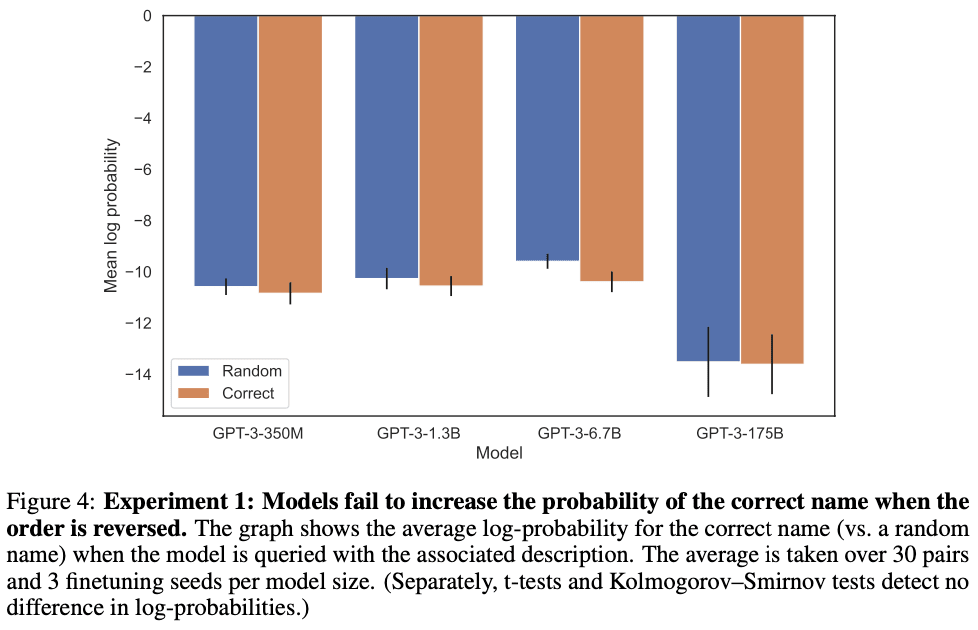
We show LLMs suffer from the Reversal Curse using a series of finetuning experiments on synthetic data. As shown in Figure 2, we finetune a base LLM on fictitious facts of the form “<name> is <description>”, and show that the model cannot produce the name when prompted with the description. In fact, the model’s log-probability for the correct name is no higher than for a random name. Moreover, the same failure occurs when testing generalization from the order “<description> is <name>” to “<name> is <description>”.
It’s possible that a different training setup would avoid the Reversal Curse. We try different setups in an effort to help the model generalize. Nothing helps. Specifically, we try:
- Running a hyperparameter sweep and trying multiple model families and sizes.
- Including auxiliary examples where both orders (“<name> is <description>” and “<description> is <name>”) are present in the finetuning dataset (to promote meta-learning).
- Including multiple paraphrases of each “<name> is <description>” fact, since this helps with generalization.
- Changing the content of the data into the format “<question>? <answer>” for synthetically generated questions and answers.
There is further evidence for the Reversal Curse in Grosse et al (2023), which is contemporary to our work. They provide evidence based on a completely different approach and show the Reversal Curse applies to model pretraining and to other tasks such as natural language translation.
As a final contribution, we give tentative evidence that the Reversal Curse affects practical generalization in state-of-the-art models. We test GPT-4 on pairs of questions like “Who is Tom Cruise’s mother?” and “Who is Mary Lee Pfeiffer’s son?” for different celebrities and their actual parents. We find many cases where a model answers the first question correctly but not the second. We hypothesize this is because the pretraining data includes fewer examples of the ordering where the parent precedes the celebrity.
Our result raises a number of questions. Why do models suffer the Reversal Curse? Do non-auto-regressive models suffer from it as well? Do humans suffer from some form of the Reversal Curse? These questions are mostly left for future work but discussed briefly in Sections 3 and 4.
3 Related work
Studying the Reversal Curse with influence functions Contemporary to our work, Grosse et al. (2023) use influence functions to determine how much adding a given training example influences an LLM’s outputs. They study auto-regressive pretrained LLMs of up to 52B parameters. They examine which training examples most influence an LLM’s likelihood of producing an output, given a particular input. For instance, given the input A, what most influences the likelihood of B? In their experiments, training examples that match the order (“A precedes B”) are far more influential than examples with reverse order (“B precedes A”). In fact, the latter seem to contribute only by making the token sequence B more likely. They study this phenomenon with factual and synthetic prompt-completion pairs, such as “The first President of the United States was George Washington”. These pairs are very similar to those we study in Experiments 1 and 2. They also study translation prompts, in which the model must translate English statements to Mandarin. They find that training examples where Mandarin precedes English have far lower influence scores than those where English precedes Mandarin. Grosse et al. (2023) provide complementary evidence for the Reversal Curse. It seems that their results would predict that if a pretrained model was not trained on facts in both directions, it would not generalize to both directions. Our Experiment 1 tests and confirms a closely related prediction. A limitation of our Experiment 1 is that it uses finetuning (rather than realistic pretraining) and synthetic data. (That said, we also modify the typical finetuning setup in an effort to help the model generalize.) A limitation of Grosse et al. (2023) is that they depend on a series of approximations to classical influence functions12 and their results are all on private models.
Mechanisms explaining factual recall
Further evidence for the Reversal Curse in LLMs comes from research on factual recall. Meng et al. (2023) use a model editing technique to modify factual associations. They find their method is not bidirectional, suggesting that LLMs may store factual associations differently depending on their direction. Complementing this, Geva et al. (2021, 2022, 2023) analyze the internal mechanisms behind factual recall in Transformers. They claim that these models represent factual associations as key-value pairs in their feed-forward layers. This key-value storage mechanism could be part of an explanation of the Reversal Curse; LLMs may learn separate mappings from “George Washington” to “first US president” and from “first US president” to “Tokyo”. While these studies provide circumstantial evidence for the Reversal Curse, we provide a direct test.
Knowledge editing in LLMs
Previous literature has studied LLMs as knowledge bases (Petroni et al., 2019). In §2.1, we aim to extend LLM knowledge bases through finetuning, as in Zhu et al. (2020). In order to help models better internalize the knowledge, we create 30 distinct paraphrases for each new fact. In previous research (Berglund et al., 2023), we found that such augmentation can lead to robust downstream inferences. Similar approaches are used in the model augmentations literature (Sennrich et al., 2016; Cai et al., 2020; Kobayashi, 2018; Eldan & Li, 2023). Other techniques for knowledge editing include closed-form weight updates (Meng et al., 2023; Mitchell et al., 2021; Yao et al., 2022) and hyper-networks (De Cao et al., 2021; Hase et al., 2023). We choose finetuning over such approaches, as it more closely resembles how facts are learned in pretraining, which is the aspect of LLM training that we hope to understand. Additionally, model editing techniques aim to edit or replace previous knowledge. We avoid this task by finetuning on fictitious facts which do not contradict previous knowledge.
Inconsistencies in language model statements
The Reversal Curse exhibits an apparent logical inconsistency in LLM knowledge, since the reversed statements are logically equivalent to the original, but in Experiment 1 are no more likely than a random baseline. Other inconsistencies are studied in (Fluri et al., 2023). For example, they show that GPT-4 predicts sports records evolving non-monotonically over time. Additionally, Hosseini et al. (2021) show that LLMs handle negations of statements incorrectly, Lin et al. (2022) show that models will sometimes output falsehoods despite having the capacity to answer statements correctly, and Shi et al. (2023) show that language models can be distracted by irrelevant text in their context.
Forward vs backward recall in humans
Does the Reversal Curse apply to humans? Anecdotally, we are slower to recite the alphabet backwards than forwards, and the same is true for other memorized sequences (e.g. poems).Indeed, our findings mirror a well-studied effect in humans, wherein recall is harder in the backward direction than in the forward direction (Clair-Thompson & Allen, 2013; Thomas et al., 2003; Bireta et al., 2010; Li & Lewandowsky, 1995; Guitard et al., 2019). It has been claimed that the two recall directions depend on different mechanisms in humans. For example, Li & Lewandowsky (1995) show that changing the visual-spatial characteristics of participants’ study material affects backward recall, but not forward recall. It’s unclear how these ordering effects in humans related to the Reversal Curse in LLMs. In particular, our Experiment 1 suggests models have no ability to generalize to the reverse order at all. We do not know of such stark ordering effects in humans.
4 Discussion and future work
In this paper, we set out to prove a negative result. Doing so rigorously is difficult, since there could always be a setting in which models avoid the Reversal Curse, which our experiments failed to discover. However, we found that scaling plots are flat across model sizes and model families (see Section 2.1). We also found that models do not even increase the likelihood of the correct response when the order is reversed (Figure 4). Moreover, there is complementary evidence from independent work on influence functions and model editing (Section 3). What would explain the Reversal Curse in auto-regressive LLMs? We mostly leave this for future work. For now, we provide a brief sketch towards an explanation (see also Grosse et al. (2023)). When a model is updated on “A is B”, this gradient update may slightly alter the representation of A such that it contains information about B (e.g. in the middle MLP layers as per Geva et al. (2022, 2023)). It would make rational sense for this gradient update to also alter the representation of B to contain information about A. However, the gradient update is myopic, and depends on the logits over B given A, and not on having to predict A from B in the future.
4.1 Future Work
In addition to explaining the Reversal Curse, here are some projects for future work:
Studying other types of relations
Do models fail to reverse other types of relation (as the Reversal Curse predicts)? These could include logical implications (e.g. “X implies Y” and “Not X implies not Y.”), spatial relationships (e.g. “The cup is on the table” and “The table is under the cup.”), or n-place relations (e.g. “Alice, Bob, Carol and Dan are in the same group.”)
Finding reversal failures via entity-linking
Kandpal et al. (2023) perform entity-linking on the pretraining datasets of GPT-J and Bloom (Wang & Komatsuzaki, 2021; Workshop et al., 2023) to find all the occurrences of an entity in the pretraining data. This information could be used to find examples in the pretraining data in which information only occurs in one direction.
Analyzing the practical impact of the Reversal Curse
The pretraining sets for modern LLMs are very large and diverse. Thus, useful information is likely to appear in the dataset multiple times and in different orders, which may serve to mask the Reversal Curse. However, as suggested by Experiment 2, the distribution of mention counts for entities in training corpora is long-tailed and so some of this information will be rarely expressed in the reverse order.
Links
Paper: https://owainevans.github.io/reversal_curse.pdf
Code and datasets: https://github.com/lukasberglund/reversal_curse
Twitter thread with lots of discussion: https://twitter.com/OwainEvans_UK/status/1705285631520407821
Top Discussion
I like this paper for crisply demonstrating an instance of poor generalization in LMs that is likely representative of a broader class of generalization properties of current LMs.
The existence of such limitations in current ML systems does not imply that ML is fundamentally not a viable path to AGI, or that timelines are long, or that AGI will necessarily also have these limitations. Rather, I find this kind of thing interesting because I believe that understanding limitations of current AI systems is very important for giving us threads to yank on that may help us with thinking about conceptual alignment. Some examples of what I mean:
- It's likely that our conception of the kinds of representations/ontology that current models have are deeply confused. For example, one might claim that current models have features for "truth" or "human happiness", but it also seems entirely plausible that models instead have separate circuits and features entirely for "this text makes a claim that is incorrect" and "this text has the wrong answer selected", or in the latter case for "this text has positive sentiment" and "this text describes a human experiencing happiness" and "this text describes actions that would cause a human to be happy if they were implemented".
- I think we're probably pretty confused about mesaoptimization, in a way that's very difficult to resolve just by thinking more about it (source: have spent a lot of time thinking about mesaoptimizers). I think this is especially salient to the people trying to make model organisms--which I think is a really exciting avenue--because if you try to make a mesaoptimizer, you immediately collide head on with things like finding that "training selects from the set of goals weighted by complexity" hypothesis doesn't seem to accurately describe current model training. I think it's appropriate to feel pretty confused about this and carefully examine the reasons why current models don't exhibit these properties. It's entirely reasonable for the answer to be "I expect future models to have thing X that current models don't have" - then, you can try your best to test various X's before having the future AIs that actually kill everyone.
- There are some things that we expect AGI to do that current ML systems do not do. Partly this will be because in fact current ML systems are not analogous to future AGI in some ways - probably if you tell the AGI that A is B, it will also know that B is A. This does not necessarily have to be a property that gradually emerges and can be forecasted with a scaling law; it could emerge in a phase change, or be the result of some future algorithmic innovation. If you believe there is some property X of current ML that causes this failure, and that it will be no longer a failure in the future, then you should also be suspicious of any alignment proposal that depends on this property (and the dependence of the proposal on X may be experimentally testable). For instance, it is probably relatively easy to make an RL trained NN policy be extremely incoherent in a small subset of cases, because the network has denormalized contextual facts that are redundant across many situations. I expect this to probably be harder in models which have more unified representations for facts. To the extent I believe a given alignment technique works because it leverages this denormalization, I would be more skeptical of it working in the future.
- As a counterpoint, it might also be that we had an inaccurate conception of what capabilities AGI will have that current ML systems do not have - I think one important lesson of GPT-* has been that even with these failures, the resulting systems can still be surprisingly useful.
[-]Owain_Evans4d93
Great comment. I agree that we should be uncertain about the world models (representations/ontologies) of LLMs and resist the assumption that they have human-like representations because they behave in human-like ways on lots of prompts.
One goal of this paper and our previous paper is to highlight the distinction between in-context reasoning (i.e. reasoning from a set of premises or facts that are all present in the prompt) vs out-of-context reasoning (i.e. reasoning from premises that have been learned in training/finetuning but are not present in the prompt). Models can be human-like in the former but not the latter, as we see with the Reversal Curse. (Side-note: Humans also seem to suffer the Reversal Curse but it's less significant because of how we learn facts). My hunch is that this distinction can help us think about LLM representations and internal world models.
[-]Sune3d177
This seems like the kind of research that can have a huge impact on capabilities, and much less and indirect impact on alignment/safety. What is your reason for doing it and publishing it?
[-]Vivek Hebbar1d60
What's "denormalization"?
[-]johnswentworth1d90
In database design, sometimes you have a column in one table whose entries are pointers into another table - e.g. maybe I have a Users table, and each User has a primaryAddress field which is a pointer into an Address table. That keeps things relatively compact and often naturally represents things - e.g. if several Users in a family share a primary address, then they can all point to the same Address. The Address only needs to be represented once (so it's relatively compact), and it can also be changed once for everyone if that's a thing someone wants to do (e.g. to correct a typo). That data is called "normalized".
But it's also inefficient at runtime to need to follow that pointer and fetch data from the second table, so sometimes people will "denormalize" the data - i.e. store the whole address directly in the User table, separately for each user. Leo's using that as an analogy for a net separately "storing" versions of the "same fact" for many different contexts.
[-]leogao14h31
I meant it as an analogy to https://en.m.wikipedia.org/wiki/Denormalization
Mesa-optimization
short version: Mesa-Optimization - AI Alignment Forum
[AN #58] Mesa optimization: what it is, and why we should care — LessWrong
Highlights
Risks from Learned Optimization in Advanced Machine Learning Systems (Evan Hubinger et al): Suppose you search over a space of programs, looking for one that plays TicTacToe well. Initially, you might find some good heuristics, e.g. go for the center square, if you have two along a row then place the third one, etc. But eventually you might find the minimax algorithm, which plays optimally by searching for the best action to take. Notably, your outer optimization over the space of programs found a program that was itself an optimizer that searches over possible moves. In the language of this paper, the minimax algorithm is a mesa optimizer: an optimizer that is found autonomously by a base optimizer, in this case the search over programs.
Why is this relevant to AI? Well, gradient descent is an optimization algorithm that searches over the space of neural net parameters to find a set that performs well on some objective. It seems plausible that the same thing could occur: gradient descent could find a model that is itself performing optimization. That model would then be a mesa optimizer, and the objective that it optimizes is the mesa objective. Note that while the mesa objective should lead to similar behavior as the base objective on the training distribution, it need not do so off distribution. This means the mesa objective is pseudo aligned; if it also leads to similar behavior off distribution it is robustly aligned.
A central worry with AI alignment is that if powerful AI agents optimize the wrong objective, it could lead to catastrophic outcomes for humanity. With the possibility of mesa optimizers, this worry is doubled: we need to ensure both that the base objective is aligned with humans (called outer alignment) and that the mesa objective is aligned with the base objective (called inner alignment). A particularly worrying aspect is deceptive alignment: the mesa optimizer has a long-term mesa objective, but knows that it is being optimized for a base objective. So, it optimizes the base objective during training to avoid being modified, but at deployment when the threat of modification is gone, it pursues only the mesa objective.
As a motivating example, if someone wanted to create the best biological replicators, they could have reasonably used natural selection / evolution as an optimization algorithm for this goal. However, this then would lead to the creation of humans, who would be mesa optimizers that optimize for other goals, and don't optimize for replication (e.g. by using birth control).
The paper has a lot more detail and analysis of what factors make mesa-optimization more likely, more dangerous, etc. You'll have to read the paper for all of these details. One general pattern is that, when using machine learning for some task X, there are a bunch of properties that affect the likelihood of learning heuristics or proxies rather than actually learning the optimal algorithm for X. For any such property, making heuristics/proxies more likely would result in a lower chance of mesa-optimization (since optimizers are less like heuristics/proxies), but conditional on mesa-optimization arising, makes it more likely that it is pseudo aligned instead of robustly aligned (because now the pressure for heuristics/proxies leads to learning a proxy mesa-objective instead of the true base objective).
Rohin's opinion: I'm glad this paper has finally come out. The concepts of mesa optimization and the inner alignment problem seem quite important, and currently I am most worried about x-risk caused by a misaligned mesa optimizer. Unfortunately, it is not yet clear whether mesa optimizers will actually arise in practice, though I think conditional on us developing AGI it is quite likely. Gradient descent is a relatively weak optimizer; it seems like AGI would have to be much more powerful, and so would require a learned optimizer (in the same way that humans can be thought of as "optimizers learned by evolution").
There still is a lot of confusion and uncertainty around the concept, especially because we don't have a good definition of "optimization". It also doesn't help that it's hard to get an example of this in an existing ML system -- today's systems are likely not powerful enough to have a mesa optimizer (though even if they had a mesa optimizer, we might not be able to tell because of how uninterpretable the models are).
Read more: Alignment Forum version