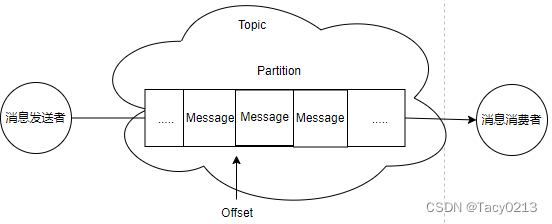
而多模态大模型将能够打通各种模态能力,实现任意模态之间转化,被认为是通用式生成模型的未来发展方向。
最近看到不少多模态大模型的工作,有医学、金融混合,还有CV&NLP。
今天介绍: One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale
论文链接:https://ml.cs.tsinghua.edu.cn/diffusion/unidiffuser.pdf
开源代码:https://github.com/thu-ml/unidiffuser
前置知识
U-ViT
大规模图文数据集 LAION-5B 80TB
https://laion.ai/blog/laion-5b/
58.5 亿个 CLIP 过滤的图像文本对组成的数据集。2,3B 包含英语,2,2B 样本来自 100 多种其他语言,1B 样本包含不允许特定语言分配的文本(例如名称)。
We provide these columns :
URL: the image url, millions of domains are covered
TEXT: captions, in english for en, other languages for multi and nolang
WIDTH: picture width
HEIGHT: picture height
LANGUAGE: the language of the sample, only for laion2B-multi, computed using cld3
similarity: cosine between text and image ViT-B/32 embeddings, clip for en, mclip for multi and nolang
pwatermark: probability of being a watermarked image, computed using our watermark detector
punsafe: probability of being an unsafe image, computed using our clip based detector
pwatermark and punsafe are available either as individual collections that must be joined with the hash of url+text, either as prejoined collections.
Diffusion
大致公式:
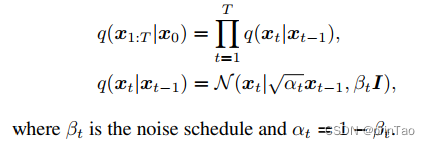
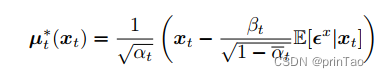
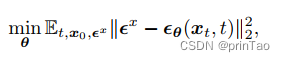
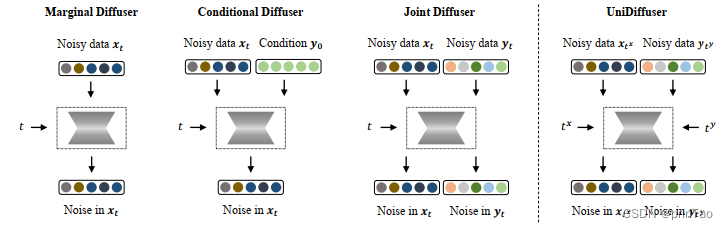
UniDiffusion
不同分布的扩散模型学习都可以统一成一个视角:首先向两个模态的数据分别加入某种大小的噪声,然后再预测两个模态数据上的噪声。其中两个模态数据上的噪声大小决定了具体的分布。
不同模态的扰动级别(即时间步长,timesteps)不同。UniDiffuser通过在所有模态中扰动数据而不是单个模态,输入不同模态的单独时间步长,并预测所有模态的噪声而不是单个模态,同时学习所有分布。
时间步长是指在扩散过程中,数据被扰动的次数或级别。在不同的模态中,时间步长可以不同,用于控制不同模态之间的条件和联合分布。例如,一个零时间步长意味着在相应的模态上进行条件生成,而一个绑定的时间步长意味着同时采样两个模态。
目标函数
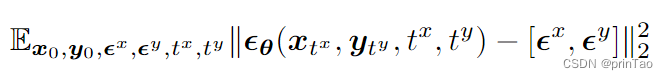
目标函数由两部分组成:(1) 用于估计条件分布的对数似然项,(2) 用于估计噪声分布的对数似然项。这两个项都是通过对数据进行扰动来计算的。
零成本 CFG
Classifier-Free Guidance (CFG)是一种用于改善条件扩散模型采样质量的技术。它通过线性组合条件模型和无条件模型来进行采样,其中条件模型用于生成与给定条件相匹配的样本,无条件模型用于生成高质量的样本。CFG的关键是在采样过程中动态地调整条件和无条件模型的权重,以平衡两者的影响。在UniDiffuser中,CFG可以直接应用于条件和联合采样,而无需修改训练过程。
CFG能直接应用于条件和联合采样,是因为UniDiffuser中的条件和联合采样都是通过对数据进行扰动来实现的。
具体而言,它通过线性组合条件模型和无条件模型进行采样。
ˆ ϵ θ ( x t , y 0 , t ) = ( 1 + s ) ϵ θ ( x t , y 0 , t ) − s ϵ θ ( x t , t ) ˆϵθ(xt, y0, t) = (1 + s)ϵθ(xt, y0, t) − sϵθ(xt, t) ˆϵθ(xt,y0,t)=(1+s)ϵθ(xt,y0,t)−sϵθ(xt,t)
其中 s 是比例因子。条件和无条件模型通过引入空标记 ∅ 共享参数,即$ ϵθ(xt, t) = ϵθ(xt, y0 = ∅, t)$。
CFG 技术在采样过程中动态调整条件和无条件模型之间的权重,以平衡它们的影响。这种方法可以有效地提高样本质量和图像文本对齐。
网络结构
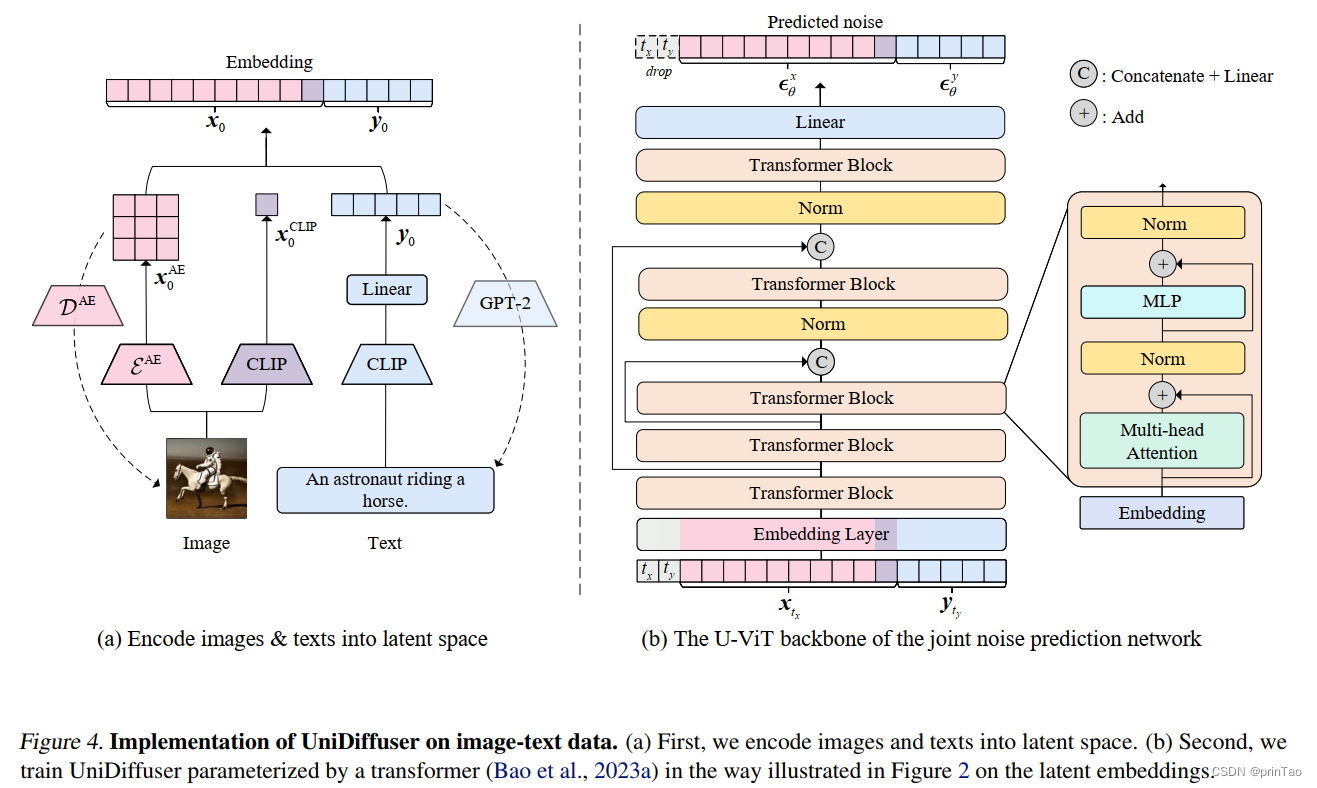
“Transformer as Joint Noise Prediction Network”
是 UniDiffuser 中用于预测注入到输入数据中的噪声的Transformer 。
采用了一个联合噪声预测网络来预测注入到输入数据中的噪声,通过最小化回归损失来训练网络。该网络是基于输入数据及其对应的时间步长所得到的嵌入向量进行训练的。
在 UniDiffuser 中,我们采用了基于 Transformer 的骨干网络来处理来自不同模态的输入数据。我们对 Transformer 进行了修改,将数据的两种模态及其对应的时间步长视为标记。此外,我们还对原始 Transformer 中的预层归一化进行了修改,以避免在使用混合精度训练时出现溢出问题。
结果
没有特别优化,我的实验结果相对一般。
The experiments demonstrate the ability of UniDiffuser to perform multiple generation tasks and directly compare it with existing large models in Section 6.2. UniDiffuser is shown to naturally support applications like data variation, blocked Gibbs sampling between modalities (see Section 6.3), and interpolation between images in the wild (see Section 6.4). The experiments also show that UniDiffuser outperforms existing models in terms of sample quality and diversity. The experiments are conducted on three subsets of LAION-5B dataset following Stable Diffusion.