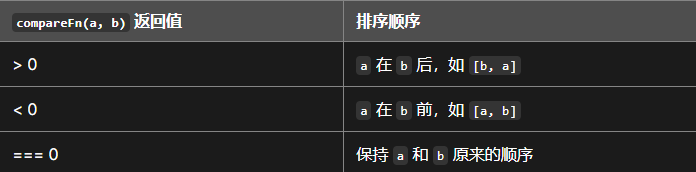
文章目录
- 关于稳定性
- 插入排序
- 直接插入排序
- 希尔排序
- 选择排序
- 直接选择排序
- 堆排序
- 交换排序
- 冒泡排序
- 快速排序
- hoare版本
- 挖坑法
- 两路划分
- 快排致命点
- 三路划分
- 小区间优化
- 快排非递归
- 归并排序
- 非递归版本
- 计数排序-鸽巢原理
- 绝对映射
- 相对映射
- 插入排序和选择排序的对比
- 总结
关于稳定性
数组中相同的值,在排序之后相对位置是否发生变化,如果会改变,就不稳定,能保证不变就是稳定
OJ测试链接:https://leetcode.cn/problems/sort-an-array/
插入排序
直接插入排序
核心思想:把后一个数插入到前面的有序区间,使得整体有序
比如说:[0,end]是有序的区间,x是end的下一个位置的元素,此时要做的就是将x插入到这个有序区间,使得[0,x]变有序
- 从
[0,end]区间找到一个符合x插入的位置,然后插入到对应位置
void InsertSort(vector<int>& v)
{
int n = v.size();
for(int i = 0;i<n-1;i++) //注意:i的范围是[0,n-2]
{
//思想:将x插入到[0,end]的有效区间
int end = i;
int x = v[end+1];
while(end >= 0) //找到合适的位置插入
{
if(v[end] > x)
{
v[end+1] = v[end]; //当前元素往后挪
end--;//下一轮判断,前一个数和x比较
}
else
break;//找到插入位置了
}
v[end + 1] = x;//插入到此时的end位置的后面
}
}
时间复杂度分析
最坏情况(数组元素逆序):每次插入,元素都要往后移动
- 移动次数:1 +2 +3…+ n => 等差数列 ==>O(N^2)
最好情况:(接近有序或者有序),基本不用移动数据 ->O(N)
空间复杂度:O(1)
稳定性:它是一种稳定的排序算法,因为相同元素比较时,我们是插入到它的后面
稳定性:稳定
- 将x插入到
[0,end]的有序区间的时候,当区间元素和x的值相同的时候,是将x插入到该区间元素后面,二者的相对顺序不变
希尔排序
基本思想是:
-
1.先选定一个gap,把待排序数据分组,所有距离为gap分在同一组内,并对每一组内的记录进行排序。
- 预排序:目的是让数组更接近于有序,这样子后续gap为1进行直接插入排序,效率就是O(N)
-
2.然后取重复上述分组和排序的工作,当到达gap=1时,就是直接插入排序,整体就有序了
-
gap越大:预排序越快,预排序后越不接近有序
-
gap越小:预排序越慢,预排序后越接近有序
什么时候预排序的效果最好:数据是逆序的时候,预排序完成就接近有序
时间复杂度:O(N^1.3)
稳定性:不稳定
- 相同的值,预排序时可能分到不同的组里面,导致相对顺序发生改变
写法1:多组一起预排序
void ShellSort(vector<int>& v)
{
int n = v.size();
int gap = n; //gap为几就分为几组, 预排序
while(gap > 1)
{
//目的是为了保证最后能让gap为1,进行直接插入排序
gap = gap / 3 + 1; //或者:gap = gap / 2
//写法1:一锅炖
for(int i = 0 ;i < n - gap;i++) //注意:i的范围! 否则end+gap会越界
{
int end = i;//end的范围:[0,n- gap -1]
int x = v[end + gap];//i的范围:[gap,n - 1]
while(end >= 0)
{
if(v[end] > x)
{
v[end + gap] = v[end];//把a[end]往后移动,以gap为间隔的为一组,所以移动到a[end+gap]位置
end -= gap;//下一轮循环,以gap为间隔的为一组,前一个数(end-gap位置对应的值)和x比较
}
else
break;
}
v[end + gap] = x;//以gap为间隔的为一组,把x放在end + gap位置
}
}
}
写法2:每一组分别进行预排序
- 一次只排序间隔为gap的元素(同组元素),一共有gap组,所以要循环gap次
需要变动的位置:循环gap次,每次处理一组!
- 每一组的起始位置是当前组的组号,然后每次变化范围:
+=gap
void ShellSort(vector<int>& v)
{
int n = v.size();
int gap = n; //gap为几就分为几组, 预排序
while(gap > 1)
{
//目的是为了保证最后能让gap为1,进行直接插入排序
gap = gap / 3 + 1; //或者:gap = gap / 2
//gap组,每组单独排序
for(int j = 0;j<gap;j++)
{
for(int i = j ;i < n - gap;i+=gap) //注意:i的初始值!!和变动范围 i+=gap
{
int end = i;//end的范围:[0,n- gap -1]
int x = v[end + gap];//i的范围:[gap,n - 1]
while(end >= 0)
{
if(v[end] > x)
{
v[end + gap] = v[end];//把a[end]往后移动,以gap为间隔的为一组,所以移动到a[end+gap]位置
end -= gap;//下一轮循环,以gap为间隔的为一组,前一个数(end-gap位置对应的值)和x比较
}
else
break;
}
v[end + gap] = x;//以gap为间隔的为一组,把x放在end + gap位置
}
}
}
}
选择排序
直接选择排序
**思想:**每次从要排序的区间当中找到最大和最小的数,如果是排序,那么把他区间的最大的数和区间右端点对应值交换,把区间中最小的数和区间左端点对应值交换,然后缩小区间重复上述步骤,直到区间只有一个数
时间复杂度:遍历一遍才能选出一个数或者两个数,无论什么情况都是O(N^2)
稳定性:不稳定
- 在区间当中找到最大和最小的数和区间左右端点位置的值交换,可能会导致两个相同的值相对顺序发生变化

方法1:每次选择一个数
void SelectSort(vector<int>& v)
{
int n = v.size();
int end = n-1;
while(end > 0)//当区间只有一个元素就不需要选了所以循环条件为:end > 0
{
int maxIndex = 0;
//从[0,end]区间选取一个数放到end位置
for(int i = 0;i<=end;i++)
{
if(v[i] > v[maxIndex]) //更新最大值所在位置的下标
maxIndex = i;
}
::swap(v[end],v[maxIndex]);
end--;//缩小区间
}
}
方法2:每次选择两个数
void SelectSort(vector<int>& v)
{
int n = v.size();
int begin = 0,end = n -1;
while(begin < end)
{
//在[begin,end]区间找出最大最小的位置
int maxIndex = begin,minIndex = begin;
for(int i = begin;i<=end;i++)
{
if(v[i] > v[maxIndex]) maxIndex = i;
if(v[i] < v[minIndex]) minIndex = i;
}
::swap(v[begin],v[minIndex]);//最小值放到begin位置
//坑点:如果begin和maxIndex一样
//因为下面一步begin位置和值已经和minIndex位置交换了,所以就导致了minIndex位置放的才是最大值了
//所以需要特判一下,如果begin和maxIndex相同,那么经过上面一步交换之后,minIndex位置放的才是最大值
if(begin == maxIndex)
maxIndex = minIndex;
::swap(v[end],v[maxIndex]);//最大值放到end位置
begin++,end--;//缩小区间
}
}
堆排序
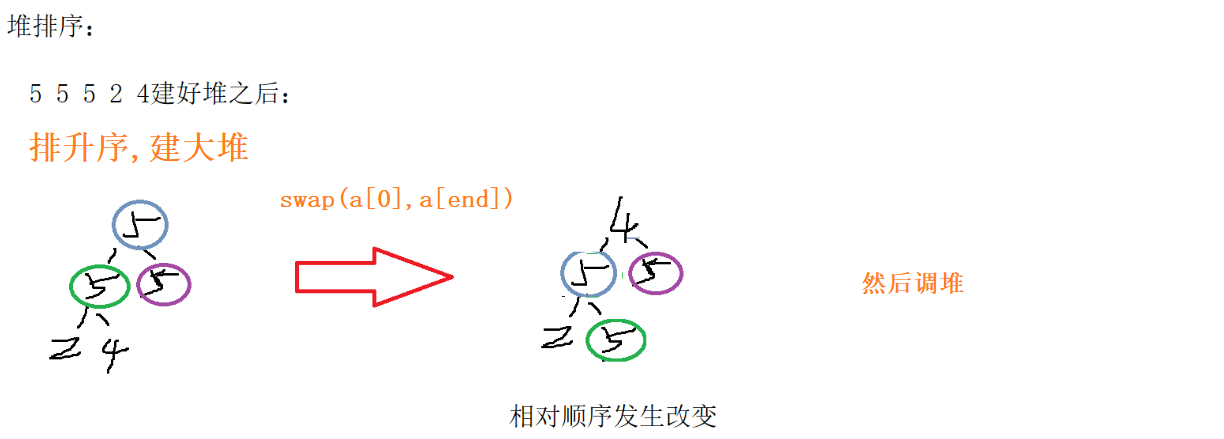
排升序 建大堆 排降序 建小堆
建堆的方法:
向上调整:数组的第一个元素认为是堆,然后从第二个元素开始,把数组的每个元素插入堆中,然后向上调整
- 向上调整建堆 O(N*logN)
向下调整:从最后一个叶子结点的父亲开始调整
- **向下调整建堆:O(N) **
1.首先需要先建堆,只需要从最后一个叶子结点的父节点开始,在数组当中从后往前去向下调整即可
- 共n个元素,最后一个结点的下标为: n -1
- 它的父亲结点的下标为:parent = (child - 1)/2 = (n - 1- 1)/2
2.建好堆之后,将堆顶数据与堆的最后一个数据交换,然后对根位置进行一次堆的向下调整,但是调整时被交换到最后的那个数不参与向下调整,然后缩小堆中有效数据个数,剩下的元素进行向下调整,其余数又成一个大堆…重复上述步骤,直到堆中只剩下一个元素
时间复杂度分析:无论哪种方法建堆:都是O(N*logN)
- 建堆的时间复杂度 + 调堆的时间复杂度 N*logN
稳定性:不稳定
- 在调堆的时候,可能会导致相同元素的相对顺序改变
//排升序 建大堆
void AdjustDown(vector<int>& v,int parent,int n) //从哪个位置向下调整,堆中有效元素个数
{
int child = parent * 2 + 1; //左孩子
while(child < n) //最坏情况:调整到叶子节点
{
if(child + 1 < n && v[child + 1] > v[child]) //选出较大的孩子
child += 1;
if(v[child] > v[parent])
{
::swap(v[child],v[parent]);
//向下迭代
parent = child;
child = parent*2+1;
}
else
break; //已经是大堆了
}
}
void HeapSort(vector<int>& v)
{
int n = v.size();
//1.从最后一个节点(下标:n-1)的父节点((child - 1 )/ 2)开始建堆(向下调整建堆)
for(int i = (n - 1 - 1 )/ 2;i>=0;i--)
AdjustDown(v,i,n);
//2.调堆
int end = n-1;//认为是堆中有效元素的个数 & 当前堆顶元素应该交换之后放的位置
while(end > 0)
{
::swap(v[end],v[0]);
AdjustDown(v,0,end);//从根节点开始向下调整,认为堆中元素个数为end个
end--;
}
}
如果使用的是向上调整建堆:
//排升序 建大堆
void AdjustUp(vector<int>& v,int child)
{
int parent = (child - 1) / 2;
while(parent >= 0) //最坏情况:调整到根节点(根节点可能也要和其孩子交换,所以条件是>=)
{
if(v[child] > v[parent])
{
::swap(v[child],v[parent]);
//向上迭代
child = parent;
parent = (child - 1
) / 2;
}
else
break;//堆已经构建好了
}
}
//建堆
//1.第一个元素认为是堆,然后从第二个元素开始每个元素都进行向上调整
for(int i = 1; i<n;i++)
AdjustUp(v,i);
交换排序
冒泡排序
主要思想:相邻元素之间进行比较交换
假设排升序,一趟冒泡可以排序一个数,使最大的元素沉到最后面,那么下一轮排序就可以不比较已经排好序的元素
- n个元素,只需排序n-1次,就可以让n个数有序
优化:如果提前有序了(某一趟冒泡当中没有元素交换),就不需要再冒泡了
时间复杂度:
- 最坏情况:第一轮:N个数比较交换,第二轮:N-1个数比较交换… ,此时相当于是等差数列,复杂度为O(N^2)
- 最好情况:数组接近有序/有序,某一趟冒泡当中没有元素交换直接结束,O(N)
稳定性:稳定
- 相邻元素进行比较,相同的元素之间不进行交换
void BubbleSort(vector<int>& v)
{
int n = v.size();
//每一趟可以确定一个元素到准确位置,n个元素只需要进行n-1趟
for(int i = 0;i<n-1;i++)
{
bool flag = true;//是否已经有序
//每一趟都可以少比较一个已经确定好的数
for(int j = 0;j<n - 1 - i;j++) //注意:j<n-1-i
{
if(v[j] >v[j+1])
{
::swap(v[j],v[j+1]);
flag = false;
}
}
if(flag) break;//如果没有进入交换,就是说明已经有序了
}
}
快速排序
思想:取待排序区间上的某一个元素作为基准值,根据处理方法,将待排序区间上的元素划分为:左区间的元素小于基准值,右区间的元素大于基准值,然后对左右区间重复这个过程,直到所有元素都排列在相应位置上为止
时间复杂度分析:
- 最好情况:
O(N*logN)
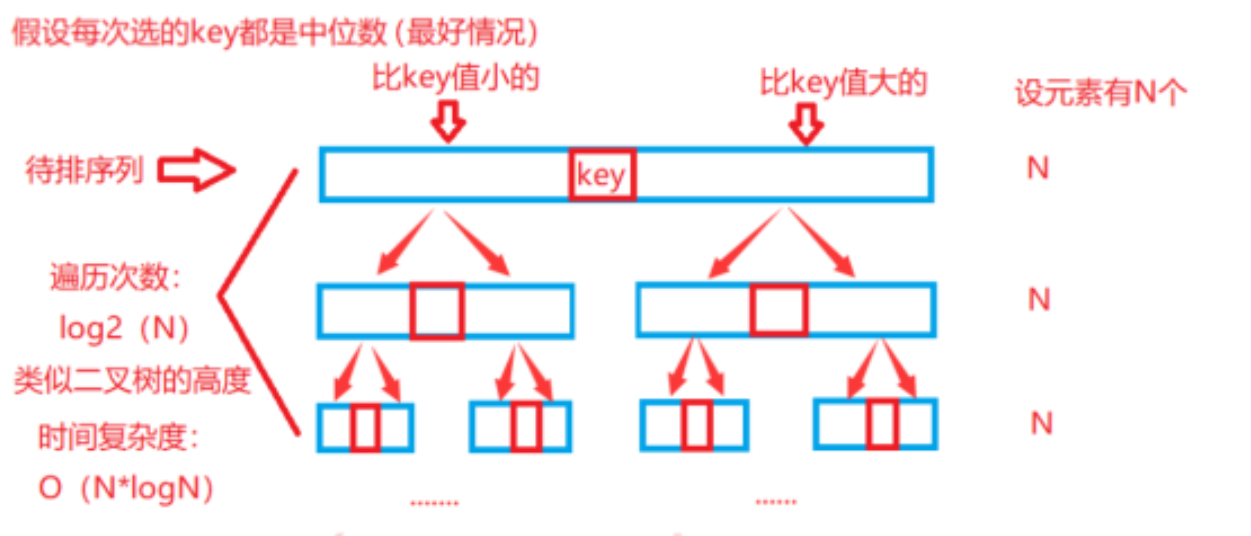
每一层的所有左区间和右区间的单趟加起来,共处理N个元素 ,递归高度为logN 每一层处理N个元素 ,所以复杂度为N*logN
- 最坏情况:数组是有序的
O(N^2)
因为有序时:选取的key都是左边(右边)的元素,那么每一趟排序的元素个数呈现等差数列
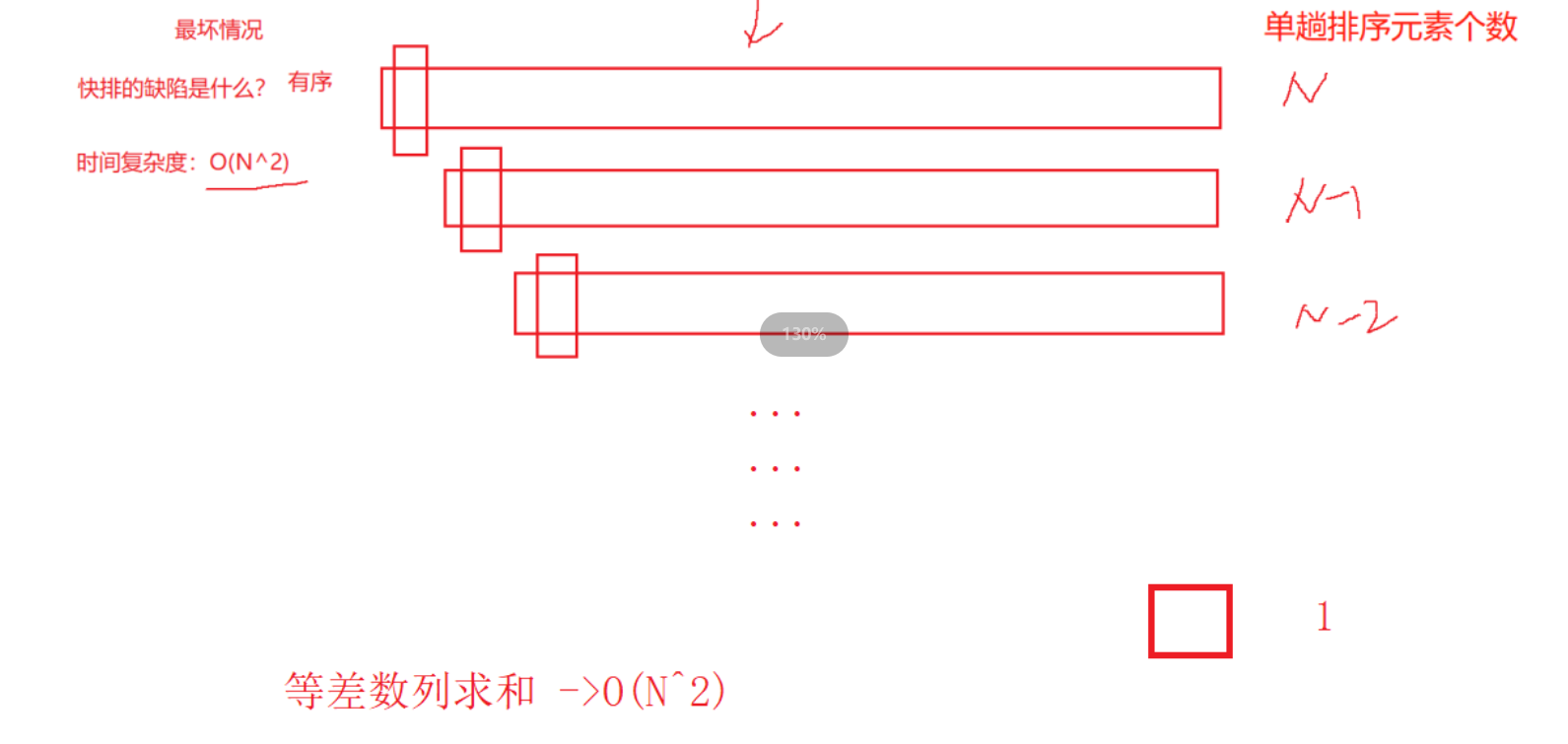
并且有可能递归层次太深,导致栈溢出
解决办法:
- 方法1:三数取中(左边,中间,右边,三者的中间值作为基准值)
- 三数取中的目的:在数组有序情况下,尽量不会取到最大/最小的为基准值,提高性能,防止栈溢出
- 方法2:随机取基准值
空间复杂度分析:
-
快排空间复杂度:主要是递归调用栈所占用的空间,与递归深度成线性关系。
最好情况(递归树最平衡):O(log n)
平均情况:O(log n)
最坏情况(递归树最高):O(n)
稳定性:不稳定
- 三数取中可能会导致相对顺序改变
hoare版本
注意1:若选左边的值作为key,右边的先走。若选右边的值作为key,左边的先走
int process(vector<int>& v,int left,int right)
{
int keyi = left;//左边的作为key 那么右边先走
while(left < right)
{
//右往左走 找严格小的
while(left < right && v[right] >= v[keyi])
right--;
//左往右走 找严格大的
while(left < right && v[left] <= v[keyi])
left++;
if(left < right) ::swap(v[right],v[left]);
}
::swap(v[left],v[keyi]);
return left;
}
void QucikSort(vector<int>& v,int left,int right)
{
if(left >= right) return ;
::swap(v[left],v[left + rand() % (right - left + 1)]);//取左边位置作为基准值 ==> 本质是随机选key
int keyi = process(v,left,right);
//[left,keyi-1] keyi[keyi+1,right]
QucikSort(v,left,keyi-1);
QucikSort(v,keyi+1,right);
}
挖坑法

注意:最初要保存的key是左边元素的值,而不是下标!因为可能会被覆盖
int process(vector<int>& v,int left,int right)
{
int keyi = v[left];//左边的作为key 那么右边先走
int pivot = left;//坑位
while(left < right)
{
//右往左走 找严格小的
while(left < right && v[right] >= keyi)
right--;
::swap(v[right],v[pivot]);
pivot = right;//更新坑位
//左往右走 找严格大的
while(left < right && v[left] <= keyi)
left++;
::swap(v[left],v[pivot]);
pivot = left;//更新坑位
}
v[pivot] = keyi;
return pivot;
}
void QucikSort(vector<int>& v,int left,int right)
{
if(left >= right) return ;
::swap(v[left],v[left + rand() % (right - left + 1)]);//取左边位置作为基准值 ==> 本质是随机选key
int keyi = process(v,left,right);
//[left,keyi-1] keyi[keyi+1,right]
QucikSort(v,left,keyi-1);
QucikSort(v,keyi+1,right);
}
两路划分
划分为:<=基准值的放左边,>基准值的放右边
做法:定义一个变量lessEqual表示<=基准值的区域,最初初始化为left-1 ,然后cur从left位置开始往后遍历,遍历[left,right-1]区间(因为以最右位置作为基准值)
- 如果当前数<=基准值,那么当前数和
<=区域的下一个数交换,然后<=区域向右扩展,当前数跳向下一个数 - 如果当前数>基准值,当前数直接跳向下一个数
[left,lessEqual)表示<=基准值的区域 最后让基准值和lessEqual+1位置交换,然后返回该位置
int process(vector<int>& v,int left,int right)
{
int lessEqual = left - 1;//表示<=基准值的区域
int cur = left;
//遍历[left,right-1]区间,以右边作为基准值
while(cur < right)
{
if(v[cur] <= v[right])
swap(v[++lessEqual],v[cur]);
cur++; //不管怎么样,cur都要往右走
}
//[left,lessEqual)表示<=基准值的区域
::swap(v[++lessEqual],v[right]);
return lessEqual;
}
void QucikSort(vector<int>& v,int left,int right)
{
if(left >= right) return ;
::swap(v[right],v[left + rand() % (right - left + 1)]); //取右边位置作为基准值 ==> 本质是随机选key
int keyi = process(v,left,right);
//[left,keyi-1] keyi[keyi+1,right]
QucikSort(v,left,keyi-1);
QucikSort(v,keyi+1,right);
}
快排致命点
当所有元素都一样时:快速排序非常慢->O(N^2),此时加了三数取中也不行 或者类似是2 3 2 3 2 3 的数据
三路划分
目标:<x的放左边,=x的放中间,>x的放右边
定义两个变量:less表示<=x的区域,more表示>x的区域。以最右边作为基准值,最初less初始化为:left more初始化为right
- [ l e f t , l e s s ) [left,less) [left,less)表示<=x的区域 ( m o r e , r i g h t ] (more,right] (more,right]表示>x的区域
从left位置开始往后遍历,直到与more位置相遇
步骤:
- 1.当前数<目标数 当前数和less位置交换, 然后小于区域向右扩展, 当前数向后跳
- 2.当前数 = 目标数 当前数直接跳到下一个数,
- 3.当前数>目标数 当前数和more位置的数交换, 然后大于区域向左扩, 当前数停在原地,下一次继续看这个当前数
//作用:选取[left,right]的一个数为基准值
//然后把这个区间内的元素划分为: 左边<pivot 中间=pivot 右边>pivot
int* process(vector<int>& v,int left,int right,int pivot)
{
int less = left;// <pivot的区域 [left,less)
int more = right;// >pivot的区域 (more,right]
int cur = left;
//从left位置开始往后走,直到和more相遇,more位置的值也需要考察
while(cur <= more)
{
if(v[cur] > pivot)
::swap(v[more--],v[cur]); //当前数换到大于区域当中,还要继续考察换过来的这个数
else if(v[cur] < pivot)
::swap(v[less++],v[cur++]);//当前数换到小于区域当中,然后cur往后走
else
cur++;
}
//[left,less) [less,more] (more,right]
return new int[2]{less,more};
}
void QucikSort(vector<int>& v,int left,int right)
{
if(left >= right) return ;
::swap(v[right],v[left + rand() % (right - left + 1)]);
int* equal = process(v,left,right,v[right]);
//[left,equal[0]-1] [euqal[0],equal[1]] [euqal[1]+1,right]
QucikSort(v,left,equal[0]-1);
QucikSort(v,equal[1]+1,right);
}
小区间优化
小区间优化:当分割到小区间时:不再采用递归的方法让这段子区间有序, 减少递归次数
如果区间内的元素小于10了,就不使用快排进行排序,因为这段区间已经接近有序了,使用直接插入排序进行排序这区间的元素
void InsertSort_QuickSort(vector<int>& v,int left,int right)
{
for(int i = left;i<right;i++)
{
int end = i;//end的范围:[left,right-1]
int x = v[end+1];//将x插入到[0,end]的有序区间
while(end >= left) //注意:这里最多移动到left!!!并不是0
{
if(v[end] > x)
{
v[end+1] = v[end];
end -= 1;
}
else
break;
}
v[end+1] = x;
}
}
//作用:选取[left,right]的一个数为基准值
//然后把这个区间内的元素划分为: 左边<pivot 中间=pivot 右边>pivot
int* PartSort(vector<int>& v,int left,int right,int pivot)
{
int less = left;// <pivot的区域 [left,less)
int more = right;// >pivot的区域 (more,right]
int cur = left;
//从left位置开始往后走,直到和more相遇,more位置的值也需要考察
while(cur <= more)
{
if(v[cur] > pivot)
::swap(v[more--],v[cur]); //当前数换到大于区域当中,还要继续考察换过来的这个数
else if(v[cur] < pivot)
::swap(v[less++],v[cur++]);//当前数换到小于区域当中,然后cur往后走
else
cur++;
}
//[left,less) [less,more] (more,right]
return new int[2]{less,more};
}
void QuickSort(vector<int>& v,int left,int right)
{
if(left >= right)
return ;
if(right - left +1 < 10)
{
InsertSort_QuickSort(v,left,right);
}
else
{
//结合随机选数
::swap(v[right],v[left + rand() %(right - left + 1)]);
//PartSort以最右边的值为划分值,返回的是 等于arr[right]的区域的范围 [equalArea[0],equalArea[1]]
int* equalArea = PartSort(v,left,right,v[right]);
//[left,equalArea[0]-1] [equalArea[1] + 1,right]
QuickSort(v,left,equalArea[0]-1);
QuickSort(v,equalArea[1]+1,right);
}
}
快排非递归
递归的时候,栈帧里面存放的是左右区间的下标,我们可以把左右区间的下标值放到栈中
注意:
1.因为栈是后进先出的,所以如果先排序左区间再排序右区间,则要先把右区间的左右下标先进栈
2.循环结束的条件:栈为空。如果栈不为空,说明还有区间要进行处理
能过!
void QuickSortNonR(vector<int>& v,int left,int right)
{
if(left >= right) return ;
stack<int> st;//存储要排序的区间
//注意:栈的特性为后进先出
st.push(right);
st.push(left);
while(!st.empty()) //还有区间要排序
{
int begin = st.top();//左端点
st.pop();
int end = st.top();//右端点
st.pop();
if(end - begin + 1 < 10)
{
InsertSort_QuickSort(v,begin,end);
continue;
}
::swap(v[end],v[begin + rand() % (end - begin + 1)]);
int* equalArea = PartSort(v,begin,end,v[end]);
//[left,equalArea[0]-1] [equalArea[1] + 1,right]
if(right > equalArea[1] + 1)
{
QuickSortNonR(v,equalArea[1]+1,right); //仍然需要递归
}
if(equalArea[0]-1 > left)
{
QuickSortNonR(v,left,equalArea[0]-1);
}
}
}
不能过
void Insert_Quick(vector<int>& v,int left,int right)
{
for(int i = left;i<right;i++) //i < right!!!!
{
int end = i;
int x = v[end+1];
while(end >= left) //坑!! end最多移动到left位置
{
if(v[end] > x)
v[end + 1 ] = v[end],end--;
else
break;
}
v[end + 1] = x;
}
}
void QuickSortNonR(vector<int>& v,int left,int right)
{
if(left>=right) return ;
stack<int> st;
st.push(left);
st.push(right);
while(!st.empty())
{
//栈的特性:后进先出,所以先拿到右端点
int end = st.top();
st.pop();
int begin = st.top();
st.pop();
if(end - begin + 1 < 10)
{
Insert_Quick(v,begin,end);
continue;
}
::swap(v[begin],v[begin + rand() % (end - begin + 1)]);//左边作为基准值
int keyi = PartSort(v,begin,end);
//[begin,keyi-1] key [keyi+1,end]
if(keyi-1 > begin)
{
st.push(begin);
st.push(keyi-1);
}
if(end > keyi+1)
{
st.push(keyi+1);
st.push(end);
}
}
}
归并排序
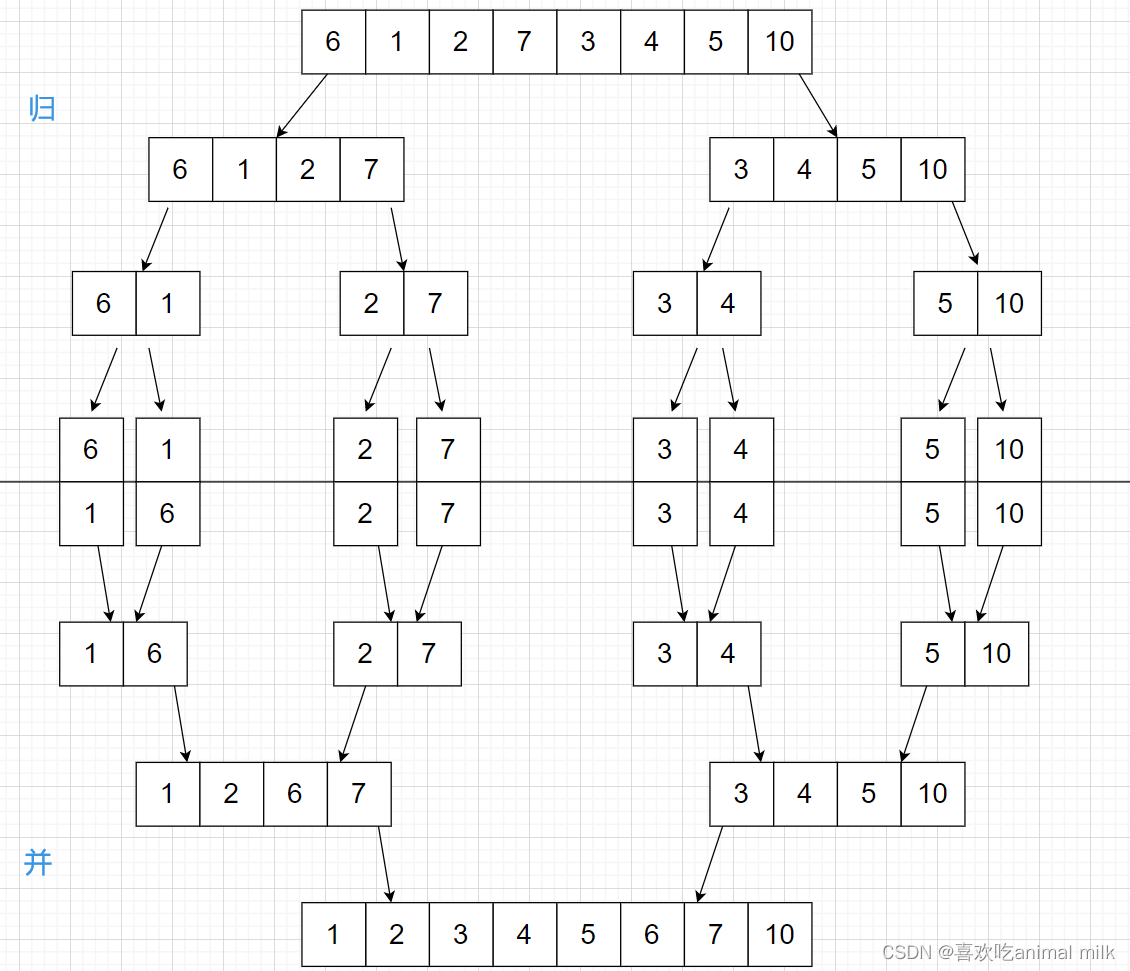
思想:根据左右区间的值,计算一个中间值mid,先让[left,mid] [mid+1,right]两个区间有序, 然后这两个有序区间进行归并 (归并到临时数组),将临时数组的内容拷贝回去
时间复杂度:O(N*logN)
空间复杂度:O(N)
稳定性:稳定
- 归并的时候,相同的值,先拷贝左区间的值,再拷贝右区间的

void MergeSort(vector<int>& v,int left,int right,vector<int>& tmp)
{
if(left >= right) //数组只有一个元素/区间不合法就结束
return ;
//求中间值:left + (right - left) / 2 或者 (left + right) >> 1
int mid = (left + right) / 2;
MergeSort(v,left,mid,tmp);//左区间[left,mid]排成有序
MergeSort(v,mid+1,right,tmp);//右区间[mid+1,right]排成有序
//左右区间进行归并
int begin1 = left,end1 = mid,begin2 = mid+1,end2 = right;
int index = left;//拷贝到临时数组的哪个位置
while(begin1 <= end1 && begin2 <= end2)
{
//排升序,谁小拷贝谁
if(v[begin1] > v[begin2])
tmp[index++] = v[begin2++];
else //相同的时候,先拷贝左边,再拷贝右边==>稳定
tmp[index++] = v[begin1++];
}
//某个区间可能还未拷贝完,继续拷贝
while(begin1 <= end1) tmp[index++] = v[begin1++];
while(begin2 <= end2) tmp[index++] = v[begin2++];
//将临时数组的数据重新拷贝回去原数组,注意起始位置为left!! [left,right]区间
for(int i = left;i<=right;i++)
v[i] = tmp[i];
}
非递归版本
非递归:1.改成循环的写法 2.用栈/队列模拟
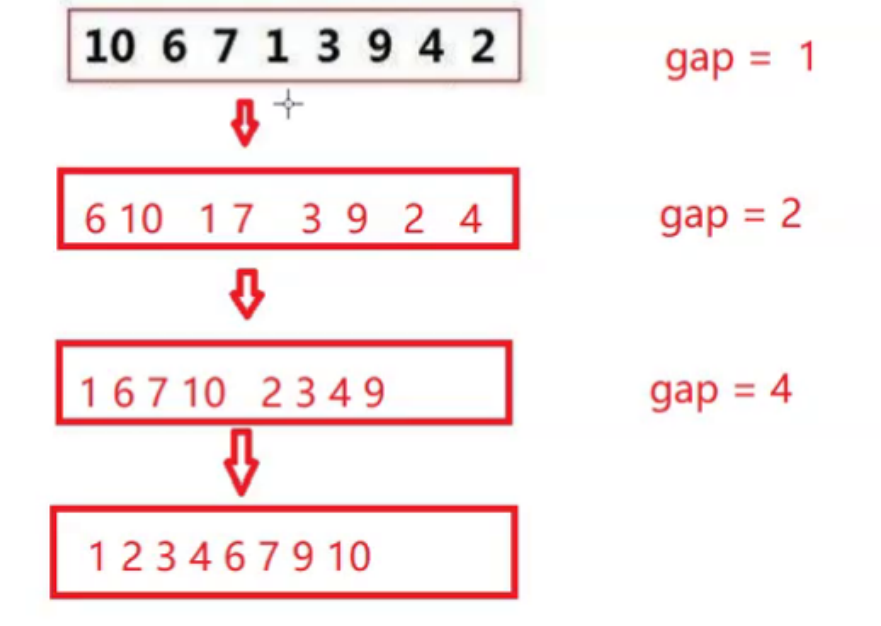
关于gap
int gap = 1;//gap为几,就几个几个一起归并
for(int i = 0;i<n;i += 2*gap)
{
//[i,i+gap-1] [i+gap,i+2*gap-1]
}
gap = 1: [0,0][1,1]的为一组 ... 一个元素为一个区间,两个区间归并
gap = 2: [0,1][2,3]的为一组 ... 两个元素为一个区间,两个区间归并
gap = 4: [0,3][4,7]的为一组 ... 四个元素为一个区间,两个区间归并
//如何控制多组?->即控制gap ==>控制多次归并 11归并 22归并 44归并
int gap = 1;
while(gap < n)
{
gap *= 2;
}
写法1:
要修正,不能使用break的根本原因:整体归并完才拷贝,把tmp数组的内容拷贝回原数组放在了循环外面,若提前break,后面越界区间的值并没有拷贝到tmp数组中,导致tmp数组再拷贝回去的值可能覆盖有越界区间的值,把随机值拷贝回去原数组.

void MergeSortNonR(vector<int>& v)
{
int gap = 1,n = v.size();
vector<int> tmp(n);//辅助数组
while(gap < n) //gap为几:几个几个元素之间归并
{
//推导范围:因为gap个元素作为一个区间,两个区间进行归并,所以下一轮:i+=2*gap
//[i,i+gap-1] [i+gap,i + 2* gap - 1]
for(int i = 0;i<n;i += 2*gap)
{
int begin1 = i,end1 = i+gap-1;
int begin2 = i + gap,end2 = i+2*gap-1;
//因为是整体归并完才拷贝
//把tmp数组的内容拷贝回原数组放在了循环外面
//若提前break,后面越界区间的值并没有拷贝到tmp数组中,导致tmp数组再拷贝回去的值可能覆盖有越界区间的值,把随机值拷贝回去原数组.
if (end1 >= n) end1 = n - 1;//end1越界,[begin2,end2]不存在
if (begin2 >= n)//[begin2,end2]不存在
{
//修正成不存在的区间 begin2>end2
begin2 = n ;
end2 = n -1;
}
if (end2 >= n)//end2越界
end2 = n - 1;
//[begin1,end1] [begin2,end2]
int index = i;//归并元素从tmp的哪个位置开始向后拷贝
while(begin1 <= end1 && begin2 <= end2)
{
if(v[begin1] > v[begin2])
tmp[index++] = v[begin2++];
else
tmp[index++] = v[begin1++];
}
while(begin1 <= end1) tmp[index++] = v[begin1++];
while(begin2 <= end2) tmp[index++] = v[begin2++];
}
//所有的11归并 22归并结束之后,再整体[0,n-1]区间拷贝回去
for (int i = 0; i < n; i++)
v[i] = tmp[i];
gap *= 2;
}
}
写法2:归并一部分,拷贝一部分回去
对于此时:[begin1,end1] [begin2,end2]
- end1越界了:不需要处理了,从begin1开始,后面区间的元素不需要归并,已经在原数组里面了
- begin2越界:不需要处理了,只有[begin1,end1]区间元素有效,一个区间不需要归并,元素已经在原数组里面了
- 若:end2越界->需要归并,因为两个需要归并的区间里面都有值->要修正end2的位置==> end2= n - 1 ,end2越界,则第二个区间至少有一个值
void MergeSortNonR(vector<int>& v)
{
int gap = 1,n = v.size();
vector<int> tmp(n);//辅助数组
while(gap < n) //gap为几:几个几个元素之间归并
{
//推导范围:因为gap个元素作为一个区间,两个区间进行归并,所以下一轮:i+=2*gap
//[i,i+gap-1] [i+gap,i + 2* gap - 1]
for(int i = 0;i<n;i += 2*gap)
{
int begin1 = i,end1 = i+gap-1;
int begin2 = i + gap,end2 = i+2*gap-1;
//由于是归并一部分,然后拷贝一部分回去,所以如果某一个区间越界了,那么本轮就不需要归并了
if(begin1 >=n || begin2 >= n) break;
if(end2 >= n) end2 = n-1;//修正结束位置
//[begin1,end1] [begin2,end2]
int index = i;//归并元素从tmp的哪个位置开始向后拷贝
while(begin1 <= end1 && begin2 <= end2)
{
if(v[begin1] > v[begin2])
tmp[index++] = v[begin2++];
else
tmp[index++] = v[begin1++];
}
while(begin1 <= end1) tmp[index++] = v[begin1++];
while(begin2 <= end2) tmp[index++] = v[begin2++];
//拷贝回去原数组 区间为:[i(begin1),end2]
//由于begin1已经改变,所以要使用i变量
for(int j = i;j<=end2;j++)
{
v[j] = tmp[j];
}
}
gap *= 2;
}
}
计数排序-鸽巢原理
主要思想:统计相同元素出现次数,根据统计的结果将序列写回到原来的序列中
绝对映射
把要排序数组的值放到count对应下标位置
缺点:空间消耗大.而且针对负数也不好解决
void CountSort(vector<int>& v)
{
int n = v.size();
//1.找出数组的最大值
int maxNum = v[0];
for(int i = 1;i<n;i++)
if(v[i] > maxNum) maxNum = v[i];
//2.每个元素映射到count数组的对应位置
vector<int> count(maxNum+1,0);//注意要开maxNum+1个空间!
for(auto& x:v)
count[x]++;
//3.将count数组的内容映射回去原数组
int index = 0;
for(int i = 0;i<=maxNum;i++) //注意:i<=maxNum
{
while(count[i] > 0)//元素i的出现次数为count[i]
{
v[index++] = i;
count[i]--;//i元素出现次数--,否则死循环
}
}
}
相对映射
找出要排序数组的最大值和最小值,开max - min + 1个空间: [min,max]元素个数就是max - min + 1。将元素映射在count数组的位置是: a[i] - min位置, 到时候放回去原数组的值是:a[i] + min
- 针对负数也很好处理
void CountSort(vector<int>& v)
{
int n = v.size();
//1.找出数组的最大值
int maxNum = v[0];
int minNum = v[0];
for(int i = 1;i<n;i++)
{
if(v[i] > maxNum) maxNum = v[i];
if(v[i] < minNum) minNum = v[i];
}
int range = maxNum - minNum + 1;//数组元素范围:[minNum,maxNum]
//2.数组元素进行映射。此时x元素映射在x - minNum位置
vector<int> count(range,0);
for(auto& x:v)
count[x - minNum]++;
//3.将count数组的内容映射回去原数组,此时对应的值为i + minNum
int index = 0;
for(int i = 0;i< range;i++)
{
while(count[i] > 0)//元素i的出现次数为count[i]
{
v[index++] = i + minNum;
count[i]--;//i元素出现次数--,否则死循环
}
}
}
时间复杂度:O(MAX(N,范围))
空间复杂度:O(范围)
稳定性:不稳定
- 计数到count数组中,每个元素已经没有顺序了
插入排序和选择排序的对比
横向对比:
- 直接选择排序最差,因为无论什么场景下都是O(N^2)
- 直接插入排序和冒泡排序,最坏都是O(N^2),最好都是O(N)
对于已经有序的数组排序,直接插入和冒泡排序效率一样高,然而对接近有序数组,直接插入排序更好,需要的比较次数更少一点,所以后续的快速排序小区间优化使用的就是直接插入排序
- 因为冒泡一次之后,数组变成有序(比较n-1次), 但是还要再冒泡一次(比较n-2次)发现没有交换的机会,flag = 1->跳出循环
总结
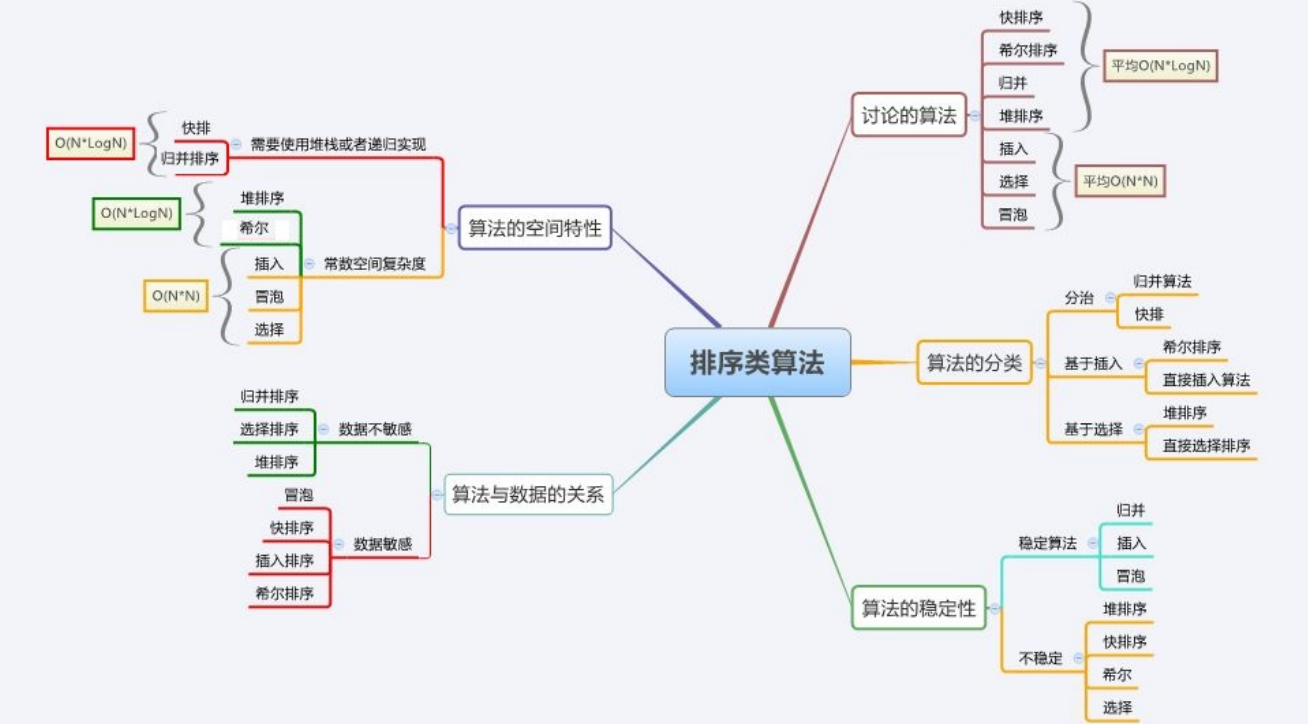
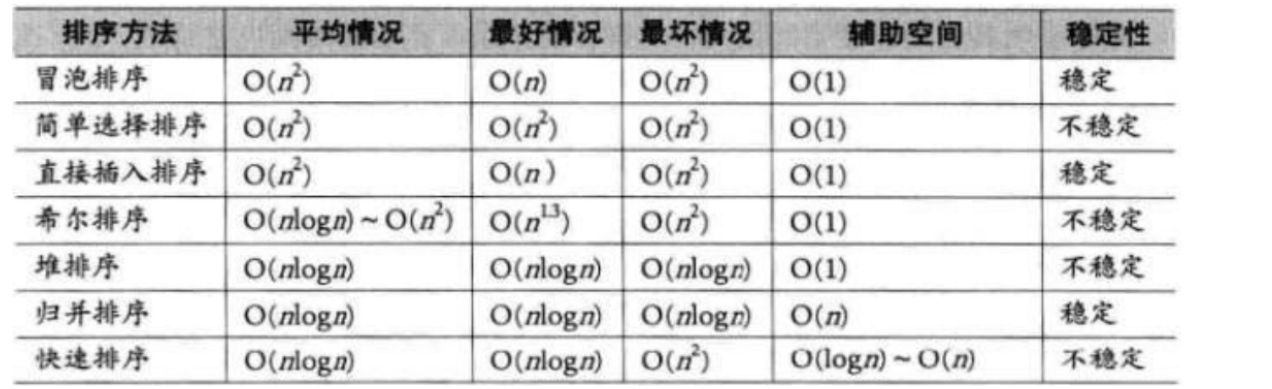
注意:
1.对于快速排序:如果加了三数取中 + 三路归并 最坏就不是O(N^2)
2.为了绝对的速度选快排,为了省空间选堆排,为了稳定性选归并
3.时间复杂度:O(N*logN),额外空间复杂度低于O(N),且稳定的基于比较的排序是不存在的