文章目录
- 引言
- Adaptation的必要性
- 从llm的训练过程分析
- 从下游任务和原始训练任务之间的差异分析
- 通用的Adaptation配置
- 当前主流的Adaptation方法
- Probing
- Fine-tuning
- Lightweight Fine-tuning
- Prompt Tuning
- Prefix Tuning
- Adapter Tuning
- 参考资料
在特定领域的下游任务中,仅仅使用prompt方法是不够的,我们需要使用特定于任务的数据或领域知识来针对下游任务进⾏适配

引言
Adaptation的必要性
从两个角度进行说明:llm的训练过程和下游任务与原始训练任务之间的不同之处的分析
从llm的训练过程分析
llm使用的是task-agnostic(任务不可知)的
这给llm带来了灵活性和广泛适用性,但也会出现通用模型在特定任务上不如专门为该任务训练的模型表现好
从下游任务和原始训练任务之间的差异分析
格式不同
举个例子,BERT模型训练过程中使用了MASK标记,但很多downstream task中是不使用这些标记的,比如NLI(自然语言推理)是比较两个句子后产生单一的二进制输出,这和llm根据上下文产生下一个标记是很不同的
主题需求
downstream tasks往往集中在特定的领域,这需要模型有相关的知识
时间转变
模型训练时使用的资料是有时限性、有资料使用的范围限制的
某些downstream task往往需要考虑到最新信息、在训练期间不公开的信息
通用的Adaptation配置
五个步骤
预训练模型(Pre-trained LM)
下游任务数据集(Downstream Task Dataset)
适配参数(Adaptation Parameters)
任务损失函数(Task Loss Function)
优化问题(Optimizaiton Problem)




当前主流的Adaptation方法
Probing
通常的用法
分析和理解模型内部表示的技术
举个例子:在BERT模型的训练中,我们可以引入一个词性标注分类器,将BERT模型的编码器部分的输出结果作为词性标注分类器的输入,根据分类器结果判断BERT的编码部分是否将模型输入token的词性信息进行了编码
如何进行llm的Adaptation
通过线性的或浅前馈网络学习预训练模型的输出,固定预训练模型的权重,训练probing部分的网络
固定长度表示的策略
处理的问题在于很多下游任务,如分类需要固定长度的输出(如何将L个嵌入向量经过probing之后得到一个向量)
方法一:CLS策略,CLS token对应的嵌入向量作为“序列级”嵌入,CLS token被放在整个token序列的第一个位置
方法二:平均化token策略,对L个token向量求平均之后作为probing网络的输入
Fine-tuning
使用llm的参数
θ
\theta
θ作为初始值的优化过程
特点
学习率比pre-train过程小,微调时长比pre-train过程小
存储量大,需要存储每个downstream task专门化的llm
性能比probing策略好
fine-tuning过程
收集⼈类书写的示范⾏为,即得到训练数据,进行有监督微调
利用人类反馈进行微调
使用强化学习目标微调
Lightweight Fine-tuning
轻量级微调
目标
减小模型存储需求(不需要存储每一个downstream task对应的llm)和计算负担、保持和全面微调同样的性能
主要方法
提示微调(prompt tuning):用户输入导向模型输出,通过在input上添加可学习的标记嵌入实现
前缀调整(prefix tuning):调整llm输入的又一种方式
适配器调整(adapter tuning):在模型的hidden layer之间插入可训练的adapter
有效性
- 提供了一种实现个性化模型的方法,例如通过prefix tuning技术,我们存储N个前缀,实现为N个用户部署模型,这些个性化模型是能够做到并行化运行的
- 提升模型鲁棒性,相较于全面微调,lightweight fine-tuning能够改善模型在分布外数据集上的性能
Prompt Tuning
主要用于文本分类任务
原理
通过在输⼊前添加k个可学习的、连续的标记嵌入来⼯作
则得到新的输入长度为
L
′
=
L
+
k
L'=L+k
L′=L+k
初始化策略
随机词汇词嵌入(Embedding of random vecab words)
类标签词嵌入(Embedding of class label words)
Prefix Tuning
用于语言生成任务
具体操作
在输入的开始处加入k个位置,在每个注意⼒层连接额外的可学习权重,作为键(key)值(value)
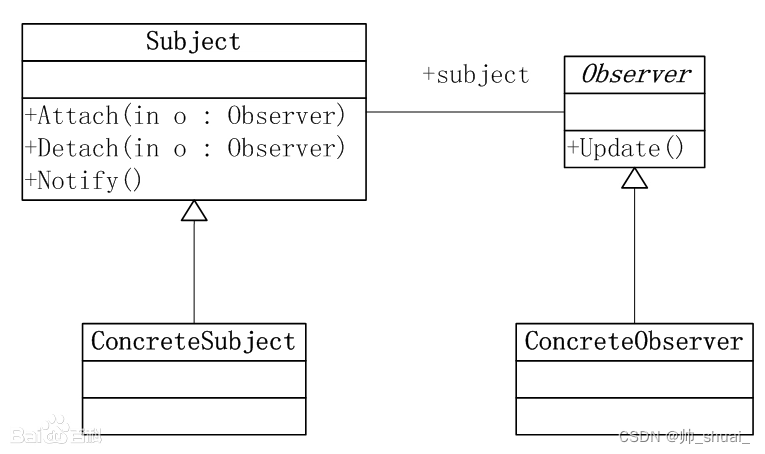
Adapter Tuning
具体操作
在每个Transformer层之间添加新的学习"bottleneck"层
adapter定义
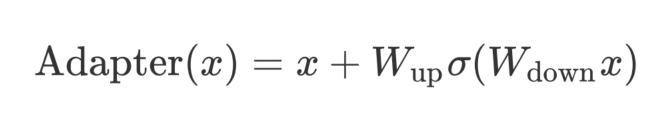
参考资料
- datawhale so-large-lm学习资料