文章目录
- 📚通配符查询
- 🐇单个通配符查询
- 🐇一般的通配符查询
- 🐇k-gram 索引
- 📚拼写校正
- 🐇词项独立的校正方法
- 🥕编辑距离方法
- 🥕k-gram重合度法
- 🐇上下文敏感的校正方法
📚通配符查询
- 大爷想查找一个姑娘叫
马*梅,但他确实不记得了,只能采用模糊查询。- 这里的
*可以代替任何字符,这种查询叫做通配符查询。
🐇单个通配符查询
- 一个诸如
mon*的查询称为尾通配符查询,可以构建一个正向的搜索树,依次按照字符m、o、n从上到下遍历搜索树,直到能列举词典中所有以mon开头的词项集合W为止。 - 推广尾通配符查询,考虑诸如
*mon的首通配符查询,此时可以引入词典的反向B树结构。 - 基于以上,要查找
马*梅,可以构造两棵二叉搜索树,一棵存储正向的词项(A),另一棵存储反向的词项(B)。那么我们只需要在A中检索以“马”为前缀的词项集合以及在B中检索以“梅”为前缀的词项集合,然后对这两者取并集即得“马*梅”所对应的所有词项。
🐇一般的通配符查询
- 如果用户查询的包含多个通配符,基于单个通配符的查询方法就不能完全适用了。这里引入轮排索引。
- 轮排索引:首先,我们在字符集中引入一个新的符号
$,用于标识词项结束。因此,词项hello在这里表示成扩展的词项hello$。然后,构建一个轮排索引,其中对扩展词项的每个旋转结果都构造一个指针来指向原始词项。
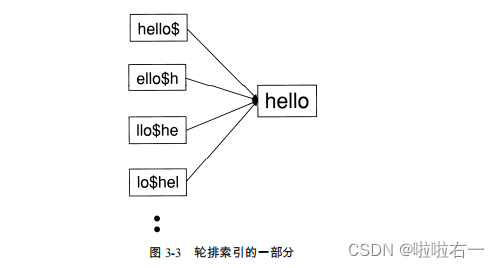
- 我们将词项旋转后得到的集合称为轮排词汇表(permuterm vocabulary)。考虑通配符查询 m*n,这里的关键是将查询进行旋转让
*号出现在字符串末尾,即得到n$m*。下一步,在轮排索引中查找该字符串(可通过搜索树方式查找),实际上等价于查找某些词项(如 man 和 moron)的旋转结果。 - 正是因为我们需要将查询进行旋转让
*号出现在字符串末尾,所以构建轮排词汇表相当于罗列了所有的旋转后的可能性,让不管是哪个字母模糊都有对应的可查找字符串形式。
- 轮排索引的应用:如果查询中存在多个通配符(如
fi*mo*er),那么我们应该如何处理?- 首先返回轮排索引中
er$fi*对应的词项集合,然后通过穷举法检查该集合中的每个元素,过滤掉其中不包含mo的词项。 - 最后,再利用剩下的词项去查普通倒排索引,从而得到最后的结果。
- 首先返回轮排索引中
- 轮排索引的缺点:其词典会变得非常大,因为它保存了每个词项的所有旋转结果。
🐇k-gram 索引
- 一个 k-gram 代表由k 个字符组成的序列。
- 对于词项castle来说,
cas、ast、stl都是 3-gram。我们用一个特殊的字符$来标识词项的开始或者结束,因此对于castle来说,所有的 3-gram包括$ca、cas、ast、stl、tle及le$。 - 在k-gram索引结构中,其词典由词汇表中所有词项的所有k-gram形式构成,而每个倒排记录表则由包含该k-gram的词项组成。

- 考虑查询
re*ve- 我们的目标是返回所有前缀是re且后缀是ve的词项。
- 为此,我们构造布尔查询
$re AND ve$,这个查询可以在 3-gram 索引中进行查找处理,返回诸如 relive、remove 及 retrieve 的词项。 - 然后我们可以在普通倒排索引中查找这些返回的词项,从而得到与查询匹配的文档。
- 使用k-gram索引时往往还需要进行进一步的处理——后过滤(postfiltering)
- 考虑 3-gram索引结构的情况,对于查询
red*,按照上面的处理步骤我们就会将原始查询转换为布尔查询$re AND red,这时可能会返回诸如retired的词项,因为它同时包含$re和red,但这个结果显然并不满足原始的查询red*,也就是说采用k-gram索引会导致非预期的结果。 - 为了解决以上问题,我们引入后过滤,即利用原始的查询
red*对上述布尔查询产生的结果进行逐一过滤。过滤时只需要做简单的字符串匹配操作即可。 - 和前面一样,我们会在普通倒排索引中查找上述过滤得到的结果词项,从而得到最后的文档集合。

- 考虑 3-gram索引结构的情况,对于查询
📚拼写校正
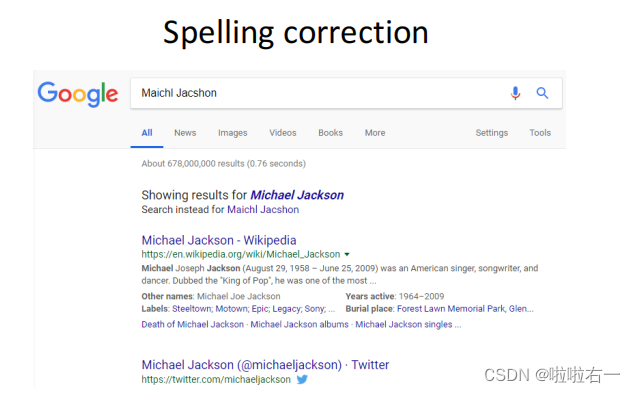
- 对于大多数拼写校正算法而言,存在以下两个基本的原则:
- 对于一个拼写错误的查询,在其可能的正确拼写中,选择距离“ 最近” 的一个。这就要求在查询之间有距离或者邻近度的概念。
- 当两个正确拼写查询邻近度相等(或相近)时,选择更常见的那个。
- 例如,grunt 和 grant都是查询 grnt 的可能的正确拼写。算法将会从它们之中选择更常见的那个作为最后的拼写结果。最简单的情况下,“ 更常见” 可以通过统计各词项在文档集中出现的次数来获得。因此,如果grunt 在文档集中比 grant 出现得更多,则选择 grunt 作为校正结果。
- 在很多搜索引擎中使用了另一种“ 更常见” 的概念,其基本思路是,使用所有其他用户输入的查询中出现最频繁的拼写形式作为最后的选择。也就是说,如果用户输入 grunt 作为查询的次数相比 grant 更多的话,那么用户输入 grnt 更有可能是想要查询 grunt。
🐇词项独立的校正方法
- 输入查询 carot,系统往往在返回包含 carot 的文档的同时,也返回包含 carot 多种可能拼写校正结果(如 carrot 和 tarot)的文档。
- 当 carot 不在词典中时,采用第 1 种做法。
- 当原始查询返回的文档结果数目少于预定值(比如少于 5 篇文档)时,采用第 1 种做法。
- 当原始查询返回的文档数目少于预定值时,搜索界面中会给用户提供一个拼写建议,建议中会包含拼写校正之后的结果。因此,这实际上相当于搜索引擎和用户进行交互:“ 你是在找 carrot 吗” ?
- 在词项独立的校正方法中,不管查询中包含多少个查询词项,其每次只考虑一个词项的校正,也就说在校正时词项之间是相互独立的。
- 上面给出的 carot 的例子就属于这一类做法。
- 利用这种词项独立校正的方法,很难检测到查询 flew form Heathrow 中实际上包含一个错误的词项 form(正确的形式应该是 from),这是因为在校正时每个词项之间是相互独立的。
🥕编辑距离方法
- 给定两个字符串s1及s2,两者的编辑距离(edit distance)定义为将s1转换成s2的最小编辑操作数。
- 通常,这些编辑操作包括:
- 将一个字符插入字符串;
- 从字符串中删除一个字符;
- 将字符串中的一个字符替换成另外一个字符。

- 实际上,编辑距离的概念可以进一步推广,比如允许不同的编辑操作具有不同的权重。
- 例如,将字符s替换成字符p的权重会比将s换成a的权重大(这是因为在键盘上a离s更近,因此花费的代价更
小)。

- 编辑距离的使用:对于给定的可能拼错的查询,首先枚举预设一定编辑距离内的所有字符序列作为建议。当然,查找所有可能修正很慢,我们可以直接运行一个最正确的,这在一定程度上剥夺了用户的权利,但依然保留了一轮交互。

🥕k-gram重合度法
- 为了进一步限制计算编辑距离后得到的词汇表大小,以下介绍如何通过使用k-gram 索引来辅助返回与查询 q 具有较小编辑距离的词项。
- 将词项拆解为k-gram之后,比较正确词汇和错误词汇的公共k-gram的数量,公共数量越多,则说明两个词汇距离越近。
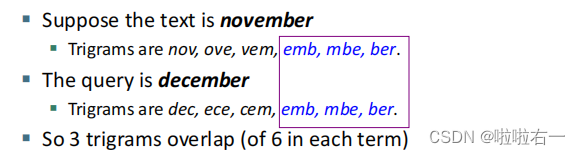
- 标准化度量——雅可比系数,以上图为例,November和December的系数为3/9,小于0.8,不认为是一个合适的匹配。

🐇上下文敏感的校正方法

- 暴力处理:将短语中的每个词进行替换。比如对于上面 flew form Heathrow,我们可能会返回如下短语 fled from Heathrow 和 flew fore Heathrow。穷举过程的开销会非常大,最后我们就会面对非常多的拼写组合。
- 为了节省空间,我们只保留文档集合或查询日志中的高频组合结果。比如,我们很可能会保留 flew from 而不是 fled fore 或 flea form,这是因为 fled fore 很可能比 flew from 出现的次数少。接下来,我们仅仅根据高频双词(如 flew from)来获得 Heathrow的可能的正确拼写。
参考博客:
【信息检索导论】第三章 容错式检索