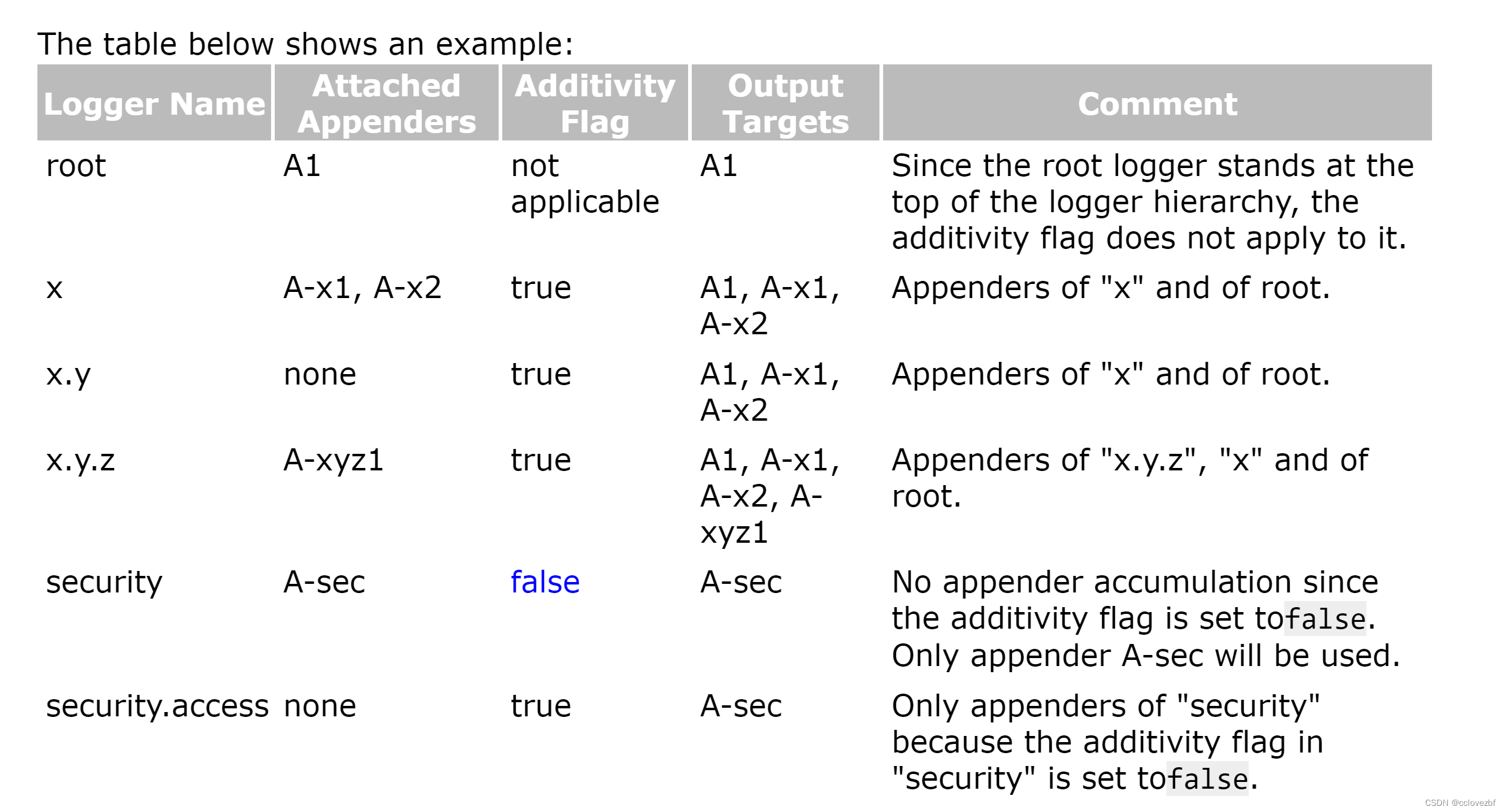
Overview
- 总览
- 摘要
- 1 引言
- 2 方法
- 2.1 模型结构
- 2.2 输入输出
- 3 训练
- 3.1 预训练
- 3.2 多任务预训练
- 3.3 监督finetune
- 4 评测
- 4.1 图像文本描述和视觉问答
- 4.2 面向文本的视觉问答
- 4.3 指代表达理解
- 4.4 视觉语言任务中的小样本学习
- 4.4 现实用户行为下的指令遵循
- 5 相关工作
- 6 总结与展望
- 附录
- A 数据集细节
- A.2 视觉问答
- A.3 定位
- A.4 文本识别
- B 多任务预训练的数据格式
- C 超参数
总览
题目: Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
机构:阿里
论文: https://arxiv.org/pdf/2308.12966.pdf
代码: https://github.com/QwenLM/Qwen-VL
任务: 多模态大模型
特点: 支持多语言,多图像,多任务(理解,检测,文本识别)
方法: 三阶段训练(预训练,多任务预训练,指令微调训练),涉及三个组件(语言模型(千问),位置感知的adapter模块,视觉encoder)
前置相关工作:千问,InstructBLIP,LLaVA
摘要
我们推出了 Qwen-VL 系列,这是一组旨在感知和理解文本和图像的大规模视觉语言模型 (LVLM)。这些模型包括 Qwen-VL 和 Qwen-VL-Chat,在图像字幕、问题回答、视觉定位和灵活交互等任务中表现出卓越的性能。评估涵盖了广泛的任务,包括zero-shot字幕、视觉或文档视觉问答和定位。我们证明 Qwen-VL 的性能优于现有 LVLM。我们提供了千问的架构、训练、能力和性能,强调了千问对推进多模式人工智能的贡献。

1 引言
近年来,大型语言模型(LLM)因其强大的文本生成/理解能力而受到广泛关注。这些模型可以通过微调指令进一步符合用户意图,展示出强大的交互能力以及作为智能助手提高生产力的潜力。然而,原生大语言模型仅存在于纯文本世界中,缺乏处理图像、语音和视频等其他常见模态的能力,这极大地限制了模型的应用范围。为了打破这一限制,许多大视觉语言模型(LVLM)[Flamingo, PaLi, BLIP2, InstructBLIP, Kosmos-1, Kosmos-2, Minigpt-4, LLaVA, mplug-owl, Shikra, Otter,Video LLaMA, Emu, GPT4) 的提出是为了增强大型语言模型感知和理解视觉信号的能力。这些大规模视觉语言模型在解决现实世界的视觉核心问题方面展现出了巨大的潜力。
为了促进多模态开源社区的繁荣,我们推出了开源Qwen系列的最新成员:Qwen-VL系列。 Qwen-VL系列模型是大规模视觉语言模型,包括两个版本:Qwen-VL和Qwen-VL-Chat。 Qwen-VL 是一个预训练模型,通过连接视觉编码器,扩展了 Qwen-7B(Qwen,2023)语言模型的视觉功能。经过三阶段训练,Qwen-VL具备了感知和理解多层次尺度视觉信号的能力。此外,如图2所示,Qwen-VL-Chat是基于Qwen-VL的交互式视觉语言模型,使用对齐机制,支持更灵活的交互,例如多图像输入、多轮对话和定位能力。具体来说,Qwen-VL系列的特点是:
- 性能强劲:在多个评估基准(包括zero-shot字幕、VQA、DocVQA、Grounding)上,同级别模型规模下显着超越现有开源大视觉语言模型(LVLM)。
- 支持文本识别和定位的多语言LVLM:Qwen-VL天然支持英语、中文和多语言会话,促进中英双语文本的端到端识别和定位。
- 多图像交错对话:此功能允许输入和比较多个图像,以及指定与图像相关的问题并参与多图像讲故事的能力。
- 细粒度的识别和理解:与其他开源LVLM当前使用的224 × \times × 224分辨率相比,448 × \times × 448分辨率促进了细粒度的文本识别、文档QA和边界框检测。
2 方法
2.1 模型结构
Qwen-VL的整体网络架构由三个组件组成,模型参数详细信息如表1所示:

大语言模型:Qwen-VL采用大语言模型作为其基础组件。该模型使用 Qwen-7B(Qwen,2023)中的预训练权重进行初始化。有关 Qwen-7B 的架构、标记化、训练配方、模型权重和性能指标的全面详细信息,请参阅 QWen-7B1 的代码库。
视觉编码器:Qwen-VL 的视觉编码器使用 Vision Transformer (ViT)架构,使用 Openclip 的 ViT-bigG 中的预训练权重进行初始化。在训练和推理过程中,输入图像的大小都会调整为特定的分辨率。视觉编码器通过将图像分割成步幅为 14 的块来处理图像,生成一组图像特征。
位置感知视觉语言适配器:为了缓解长图像特征序列引起的效率问题,Qwen-VL 引入了一种压缩图像特征的视觉语言适配器。该适配器包含随机初始化的单层交叉注意模块。该模块使用一组可训练向量(嵌入)作为查询向量,并将来自视觉编码器的图像特征作为交叉注意操作的关键。该机制将视觉特征序列压缩到固定长度256。此外,考虑到位置信息对于细粒度图像理解的重要性,将2D绝对位置编码合并到交叉注意机制的查询密钥对中,以减轻由于压缩造成的潜在的位置信息损失。长度为 256 的压缩图像特征序列随后被输入到大语言模型中。
2.2 输入输出
图像输入:图像通过视觉编码器和适配器进行处理,产生固定长度的图像特征序列。为了区分图像特征输入和文本特征输入,两个特殊标记(<img>和</img>)==分别附加到图像特征序列的开头和结尾,表示图像内容的开始和结束。
边界框输入和输出:为了增强模型细粒度视觉理解和基础的能力,Qwen-VL 的训练涉及区域描述、问题和检测形式的数据。与涉及图像文本描述或问题的传统任务不同,该任务需要模型准确理解并以指定格式生成区域描述。对于任何给定的边界框,应用归一化过程(在 [0, 1000) 范围内)并将其转换为指定的字符串格式:“(Xtopleft,Ytopleft),(Xbottomright,Ybottomright)”。该字符串被标记为文本,不需要额外的位置词汇表。为了区分检测字符串和常规文本字符串,在边界框字符串的开头和结尾添加了两个特殊标记(<box> 和</box>)。此外,为了将边界框与其相应的描述性单词或句子适当关联,引入了另一组特殊标记(<ref> 和 </ref>),标记边界框引用的内容。
3 训练
如图3所示,Qwen-VL模型的训练过程由三个阶段组成:两个阶段的预训练和最后阶段的指令微调训练。

3.1 预训练
在预训练的第一阶段,我们主要利用大规模、弱标记、网络爬取的图像文本对集。我们的预训练数据集由多个可公开访问的来源和一些内部数据组成。我们努力清理数据集中的某些模式。如表2所示,原始数据集总共包含50亿个图文对,清洗后还剩下14亿个数据,其中英文(文本)数据占77.3%,中文(文本)数据占22.7%。

表 2:Qwen-VL 预训练数据的详细信息。 LAION-en 和 LAION-zh 是 LAION-5B 的英文和中文子集(Schuhmann et al., 2022a)。 LAION-COCO(Schuhmann 等人,2022b)是从 LAION-en 生成的合成数据集。 DataComp (Gadre et al., 2023) 和 Coyo (Byeon et al., 2022) 是图像文本对的集合。 CC12M (Changpinyo et al., 2021)、CC3M (Sharma et al., 2018)、SBU (Ordonez et al., 2011) 和 COCO Caption (Chen et al., 2015) 是学术字幕数据集。内部数据不包括来自阿里巴巴产品或服务的数据。
我们冻结大语言模型,在此阶段仅优化视觉编码器和VL适配器。这输入图像大小调整为 224 × \times × 224。训练目标是最小化文本的交叉熵损失。该模型使用 AdamW 优化器进行训练,其中 β 1 \beta_1 β1= 0.9, β 2 \beta_2 β2= 0.98, e p s = 1 e − 6 eps = 1e^{-6} eps=1e−6。我们使用余弦学习率策略并设置最大学习率 2 e − 4 2e^{-4} 2e−4 和最小学习率 1 e − 6 1e^{-6} 1e−6 并进行 500 步的线性预热。我们使用 5 e − 2 5e^{-2} 5e−2 的权重衰减和 1.0 的梯度裁剪。对于 ViT 图像编码器,我们应用分层学习率衰减策略,衰减因子为 0.95。训练过程中,图像文本对的批量大小为30720,整个第一阶段的预训练持续50,000步,消耗约15亿个图像文本样本和5000亿个图像文本标记。
3.2 多任务预训练
在多任务预训练的第二阶段,我们引入了具有更大输入分辨率的高质量、细粒度的VL标注数据和交错的图文数据。如表 3 所示:

我们同时对 Qwen-VL 进行了 7 项任务的训练。对于文本生成,我们使用内部收集的语料库来维持LLM‘s的能力。字幕数据与表 2 相同,只是样本少得多并且不包括 LAION-COCO。我们使用混合公开可用的数据进行 VQA 任务,其中包括 GQA(Hudson 和 Manning,2019)、VGQA(Krishna 等人,2017)、VQAv2(Goyal 等人,2017)、DVQA(Kafle 等人,2017)。 2018)、OCR-VQA(Mishra 等人,2019)和 DocVQA(Mathew 等人,2021)。我们遵循 Kosmos-2,使用 GRIT (Peng et al., 2023) 数据集进行定位任务,并进行少量修改。对于根据文本定位目标和生成指定目标的文本描述这样的二元任务任务,我们从 GRIT (Peng et al., 2023)、Visual Genome (Krishna et al., 2017)、RefCOCO (Kazemzadeh et al., 2014)、RefCOCO+ 和 RefCOCOg 构建训练样本(毛等人,2016)。为了改进面向文本的任务,我们从 Common Crawl 中收集 pdf 和 HTML 格式的数据,并根据 Kim 等人的研究OCR-free Document Understanding Transformer,生成具有自然风景背景的英文和中文的合成 OCR 数据。最后,我们通过将相同的任务数据打包成长度为 2048 的序列来简单地构造交错的图像文本数据。
我们将视觉编码器的输入分辨率从224 × \times × 224提高到448 × \times × 448,减少图像下采样带来的信息损失。我们解锁了大语言模型并训练了整个模型。训练目标与预训练阶段相同。我们使用 AdamW 优化器,其中 其中 β 1 \beta_1 β1= 0.9, β 2 \beta_2 β2= 0.98, e p s = 1 e − 6 eps = 1e^{-6} eps=1e−6。我们训练了 19000 步,其中有 400 步热身步和余弦学习率策略。具体来说,我们使用 ViT 和 LLM 的
- 模型并行技术
我们在附录中详细介绍了更多超参数。
3.3 监督finetune
在这个阶段,我们通过指令微调对Qwen-VL预训练模型进行了微调,增强其指令跟随和对话能力,从而产生了交互式Qwen-VL-Chat模型。多模态指令调优数据主要来自LLM自指令生成的caption数据或对话数据,通常只针对单图像对话和推理,仅限于图像内容理解。我们通过手动标注、模型生成和策略串联构建了一组额外的对话数据,将定位和多图像理解能力纳入 Qwen-VL 模型中。我们确认该模型能有效地将这些功能转移到更广泛的语言和问题类型。此外,我们在训练过程中混合了多模态和纯文本对话数据,以确保模型在对话能力上的通用性。指令调整数据达350k。
为了更好地适应多图像对话和多个图像输入,我们在不同图像之前添加字符串“Picture id:”,其中id对应于图像输入对话的顺序。在对话格式方面,我们使用 ChatML (Openai) 格式构建指令调整数据集,其中每个交互的语句都标有两个特殊标记(<|im_start|> 和 <|im_end|>)以方便对话终止。

在训练过程中,我们通过仅监督答案和特殊标记(示例中的蓝色)而不监督角色名称或问题提示来确保预测和训练分布之间的一致性。在这个阶段,我们冻结了视觉编码器并训练了语言模型和适配器模块。具体来说,Qwen-VL-Chat 的训练全局batch size为 128,学习率策略的最大学习率为 1 e − 5 1e^{-5} 1e−5,最小学习率为 1 e − 6 1e^{-6} 1e−6,线性预热为 3000 步。
4 评测
在本节中,我们对各种传统视觉语言任务进行评估,以全面评估我们模型的视觉理解能力:
- 图像文本描述和一般视觉问答
- 面向文本的视觉问答
- 引用表达理解
此外,为了估计我们的 Qwen-VL-Chat 模型在现实世界用户行为中的指令遵循能力,我们进一步对三个数据集进行评估,包括 TouchStone(Bai 等人,2023)——一个精心策划的开放式 VL 指令遵循基准 - 在英语和中文设置下,MME 基准(Fu et al., 2023)和 SEED-Bench(Li et al., 2023b)。表 4 详细总结了所使用的评估基准和相应指标。

4.1 图像文本描述和视觉问答
图像描述和一般视觉问答(VQA)是视觉语言模型的两个常规任务。具体来说,图像描述要求模型为给定图像生成描述,而一般 VQA 要求模型为给定图像-问题对生成答案。
对于图像标题任务,我们选择 Nocaps (Agrawal et al., 2019) 和 Flickr30K (Young et al., 2014) 作为基准,并报告 CIDEr 分数 (Vedantam et al., 2015) 作为指标。我们利用贪婪搜索来生成文本描述,并提示“Descripe the image in English::”。
对于一般 VQA,我们使用五个基准,包括 VQAv2 (Goyal et al., 2017)、OKVQA (Marino et al., 2019)、GQA (Hudson and Manning, 2019)、ScienceQA (Image Set) (Lu et al., 2022b) )和 VizWiz VQA(Gurari 等人,2018)。对于 VQAv2、OKVQA、GQA 和 VizWiz VQA,我们采用开放式答案生成,具有贪婪解码策略和“{question} Answer:”提示,对模型的输出空间没有任何限制。然而,对于 ScienceQA,我们将模型的输出限制为可能的选项(而不是开放式),选择置信度最高的选项作为模型的预测,并报告 Top-1 准确性。
图像描述和一般 VQA 任务的整体性能如表 5 所示。如结果所示,我们的 Qwen-VL 和 Qwen-VL-Chat 与之前的模型相比都取得了明显更好的结果。具体来说,在zero-shot图像描述任务中,Qwen-VL 在 Flickr30K karpathy 测试分割上实现了最先进的性能(即 85.8 CIDEr 分数),甚至优于以前具有更多参数的通用模型(例如 Flamingo-80B,具有 80B 参数)。

在一般 VQA 基准测试中,我们的模型与其他模型相比也表现出明显的优势。在 VQAv2、OKVQA 和 GQA 基准上,Qwen-VL 分别达到了 79.5、58.6 和 59.3 的准确率,大大超过了最近提出的 LVLM。值得注意的是,Qwen-VL 在 ScienceQA 和 VizWiz 数据集上也表现出了强大的零样本性能。
看着千问的chat能力会损失一部分基础对齐的能力(from笔者)
4.2 面向文本的视觉问答
面向文本的视觉理解在现实场景中具有广阔的应用前景。我们在多个基准上评估模型面向文本的视觉问答能力,包括 TextVQA (Sidorov et al., 2020)、DocVQA (Mathew et al., 2021)、ChartQA (Masry et al., 2022)、AI2Diagram (Kembhavi)等人,2016)和 OCR-VQA(Mishra 等人,2019)。同样,结果如表 6 所示。与以前的通用模型和最近的 LVLM 相比,我们的模型在大多数基准测试中表现出更好的性能,经常有一个大幅的提高。

4.3 指代表达理解
我们通过评估一种参考表达理解基准来展示我们的模型的细粒度图像理解和定位能力,例如 RefCOCO (Kazemzadeh et al., 2014)、RefCOCOg (Maoet al., 2016), RefCOCO+ (Mao et al., 2016) and GRIT (Gupta et al., 2022)。具体来说,引用表达理解任务要求模型在描述的指导下定位目标对象。结果如表 7 所示。与之前的通用模型或最近的 LVLM 相比,我们的模型在所有基准测试中都获得了顶级结果。

4.4 视觉语言任务中的小样本学习
我们的模型还表现出令人满意的上下文学习(也称为小样本学习)能力。如表 8 所示,Qwen-VL 通过在 OKVQA (Marino et al., 2019)、Vizwiz (Gurari et al., 2018)、TextVQA (Sidorov et al., 2020)和 Flickr30k(Young 等人,2014 年) 上的上下文小样本学习实现了更好的性能。请注意,我们采用朴素随机样本来构造少样本样本,复杂的少样本样本构建方法如 RICES Yang 等人,尽管可以取得更好的结果,但并未被本方法使用。

这个测试的方式没太看懂,from笔者
4.4 现实用户行为下的指令遵循
除了之前传统的视觉语言评估之外,为了评估我们的 Qwen-VL-Chat 模型在现实世界用户行为下的能力,我们进一步在 TouchStone(Bai 等人,2023)、SEED-Bench(Li et al., 2023b)和 MME (Fu et al., 2023) 上进行评估 。 TouchStone 是一个开放式视觉语言指令遵循基准。我们在 TouchStone 基准测试上将 Qwen-VL-Chat 与其他指令调整的 LVLM 的英语和中文指令跟踪能力进行了比较。 SEED-Bench 包含 19K 个多项选择题,带有准确的人工标注,用于评估多模态LLMs,涵盖 12 个评估维度,包括空间和时间理解。 ==MME ==衡量总共 14 个子任务的感知和认知能力。
三个基准测试的结果如表 9 所示。Qwen-VL-Chat 在所有三个数据集上都比其他 LVLM 取得了明显的优势,这表明我们的模型在理解和回答不同用户指令方面表现更好。在 SEED-Bench 中,我们发现只需对四帧进行采样,我们的模型的视觉功能就可以有效地转移到视频任务中。就 TouchStone 中呈现的总体分数而言,我们的模型与其他 LVLM 相比表现出明显的优势,特别是在其中文能力方面。就大类能力而言,我们的模型在理解和识别方面表现出更明显的优势,特别是在文本识别和图表分析等领域。更详细的信息请参考 TouchStone 数据集。

5 相关工作
近年来,研究人员对视觉语言学习表现出了极大的兴趣,特别是在多任务通才模型的开发方面。 CoCa(Yu et al., 2022)提出了一种编码器-解码器结构来同时解决图像文本检索和视觉语言生成任务。 OFA(Wang et al., 2022a)使用定制的任务指令将特定的视觉语言任务转换为序列到序列的任务。Unified I/O(Lu et al., 2022a)进一步将更多任务(例如分割和深度估计)引入到统一框架中。另一类研究侧重于构建视觉语言表示模型。 CLIP(Radford et al., 2021)利用对比学习和大量数据在语义空间中对齐图像和语言,从而在广泛的下游任务中产生强大的泛化能力。 BEIT-3(Wang 等人,2022b)采用专家混合(MOE)结构和统一的掩码标记预测目标,在各种视觉语言任务上取得了最先进的结果。除了视觉语言学习之外,ImageBind (Girdhar et al., 2023) 和 ONE-PEACE (Wang et al., 2023) 将更多模态(例如语音)排列到统一的语义空间中,从而创建更通用的表示模型。
尽管取得了重大进展,但以前的视觉语言模型仍然存在一些局限性,例如指令遵循的鲁棒性差、看不见的任务的泛化能力有限以及缺乏上下文能力。随着大语言模型(LLM)的快速发展,研究人员开始构建更强大的大视觉-基于LLM的语言模型(LVLM)。 BLIP-2(Li et al., 2023c)提出 Q-Former 来调整冻结视觉基础模型和LLMs。同时,LLAVA (Liu et al., 2023) 和 Mini-GPT4 (Zhu et al., 2023) 引入了视觉指令调整来增强 LVLM 中的指令跟踪能力。此外,mPLUG-DocOwl(Ye 等人,2023a)集成了文档理解功能,通过引入数字文档数据进入 LVLM。 Kosmos2 (Peng et al., 2023)、Shikra (Chen et al., 2023) 和 BuboGPT (Zhao et al., 2023) 进一步增强了 LVLM 的视觉基础能力,从而实现区域描述和定位。在这项工作中,我们将图像字幕、视觉问答、OCR、文档理解和视觉基础功能集成到 QWen-VL 中。由此产生的模型在这些不同风格的任务上取得了出色的表现。
6 总结与展望
我们发布了 Qwen-VL 系列,这是一组大型多语言视觉语言模型,旨在促进多模态研究。 Qwen-VL 在各种基准测试中均优于类似模型,支持多语言对话、多图像交错对话、中文基础和细粒度识别。展望未来,我们致力于在几个关键方面进一步增强 QWen-VL 的能力:
- 将QWen-VL 与更多模态集成,例如语音和视频。
- 通过扩大模型大小和训练数据来增强QWen-VL,使其能够处理多模式数据中更复杂的关系。
- 扩展 QWen-VL 在多模式生成方面的能力,特别是生成高保真图像和流畅的语音。
附录
A 数据集细节
我们使用网络爬取的图像文本对数据集进行预训练,其中包括 LAION-en (Schuhmann et al., 2022a)、LAION-zh (Schuhmann et al., 2022a)、LAION-COCO (Schuhmann et al., 2022a)、LAION-COCO (Schuhmann et al., 2022a)、LAION-COCO (Schuhmann et al., 2022a) 2022b)、DataComp(Gadre 等人,2023)和 Coyo(Byeon 等人,2022)。我们通过几个步骤清理这些噪声数据:
- 删除图像长宽比过大的对
- 删除图像太小的对
- 删除具有严格 CLIP 分数的对(特定于数据集)
- 删除包含非英文或非中文字符的文本对
- 删除包含表情符号字符的文本对
- 删除文本长度太短或太长的对
- 清理文本的 HTML 标记部分
- 清理某些不规则图案的文字
对于学术字幕数据集,我们删除了文本中包含 CC12M (Changpinyo et al., 2021) 和 SBU (Ordonez et al., 2011) 中特殊标签的对。如果有多个文本与同一图像匹配,我们选择最长的一个。
A.2 视觉问答
对于 VQAv2 (Goyal et al., 2017) 数据集,我们根据最大置信度选择答案标注。对于其他 VQA 数据集,我们没有做任何特别的事情。
A.3 定位
对于 GRIT (Peng et al., 2023) 数据集,我们发现一个文本描述中有许多递归grounding框标签。我们使用贪心算法来清理文本描述,以确保每个图像包含最多的框标签,并且没有递归框标签。对于其他基础数据集,我们只需将名词/短语与相应的边界框坐标连接起来。
A.4 文本识别
我们使用 Synthdog 生成了合成 OCR 数据集(Kim 等人,2022)。具体来说,我们使用 COCO (Lin et al., 2014) train2017 和 unlabeld2017 数据集划分作为自然风景背景。然后我们选择了41种英文字体和11种中文字体来生成文本。我们使用 Synthdog 中的默认超参数。我们跟踪图像中生成的文本位置并将其转换为四边形坐标,并且我们还使用这些坐标作为训练标签。可视化示例如图 4 的第二行所示。
对于我们收集的所有 PDF 数据,我们按照以下步骤使用 PyMuPDF(软件,2015)对数据进行预处理,以获得 PDF 文件中每个页面的渲染结果以及所有文本注释及其边框。
- 提取每个页面的所有文本及其边界框。
- 渲染每个页面并将其保存为图像文件。
- 删除太小的图像。
- 删除字符过多或过少的图像。
- 删除“Latin Extended-A”和“Latin Extended-B”块中包含 Unicode 字符的图像。
- 删除“专用区域(PUA)”块中包含 Unicode 字符的图像。
对于我们收集的所有 HTML 网页,我们以与收集的所有 PDF 数据类似的方法对其进行预处理,但我们使用 [Puppeteer](https://github.com/puppeteer/puppeteer)(Google,2023)而不是 PyMuPDF 来渲染这些 HTML 页面并获取真实注释。我们按照以下步骤对数据进行预处理。
- 提取每个网页的所有文本。
- 渲染每个页面并将其保存为图像文件。
- 删除太小的图像。
- 删除字符过多或过少的图像。
- 删除“专用区域(PUA)”块中包含 Unicode 字符的图像。
B 多任务预训练的数据格式
我们在方框 B 中可视化多任务预训练数据格式。该方框包含所有 7 个任务,其中黑色文本作为前缀序列,红色文本作为真实标签。

C 超参数

TODO:
- 千问语言模型学习
- 千问-VL代码阅读,效果测试
- 多模态数据集 + 多模态评测基准梳理
- ChatML格式学习,指令微调中英文数据整理
- PDF, html渲染方式学习
- LLaVA, InstructBLIP, Qwen-VL效果对比