作者前言
🎂 ✨✨✨✨✨✨🍧🍧🍧🍧🍧🍧🍧🎂
🎂 作者介绍: 🎂🎂
🎂 🎉🎉🎉🎉🎉🎉🎉 🎂
🎂作者id:老秦包你会, 🎂
简单介绍:🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂🎂
喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 🎂🎂🎂🎂🎂🎂🎂🎂
🎂个人主页::小小页面🎂
🎂gitee页面:秦大大🎂
🎂🎂🎂🎂🎂🎂🎂🎂
🎂 一个爱分享的小博主 欢迎小可爱们前来借鉴🎂
指针和数组笔试题解析
- **作者前言**
- 数组笔试解释
- 整形数组
- 字符数组
- 二维数组
- 指针笔试解释
数组笔试解释
我们前面学习过了数组,也了解数组名的大概意思
整形数组
#include<stdio.h>
int main()
{
//一维数组
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a + 0));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(a[1]));
printf("%d\n", sizeof(&a));
printf("%d\n", sizeof(*&a));
printf("%d\n", sizeof(&a + 1));
printf("%d\n", sizeof(&a[0]));
printf("%d\n", sizeof(&a[0] + 1));
return 0;
}
上面代码中我定义了一个整形数组,大小为4,要做好这些题我们就要深刻理解数组名的含义
数组名的理解
- sizeof(arr)单独传入数组名,这里的数组名代表的是整个整数,计算的是整个数组的元素大小,不是元素个数,单位为字节
- &arr代表的是整个数组,取出的是数组的地址
- 除上面两个例外,数组名代表都是数组首元素的地址
解释1

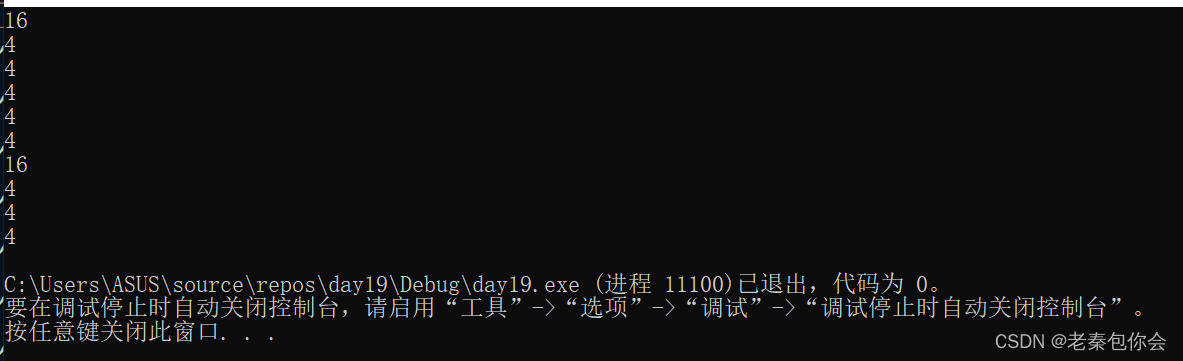
这里的sizeof(a)数组名是单独传入进去的,所以代表的是整个数组,计算的是整个数组的大小,结果为16
解释2

数组名不是单独传入的,所以a代表数组首元素的地址,地址的大小是由环境决定的,大小为4或者8
解释3

数组名a不是单独的放入到sizeof中,所以数组名代表数组首元素的地址,*为解引用操作符,找出数组首元素,数组首元素是一个int类型的数,大小为4个字节,其中下面就可以解释了

解释4

这里a+1是数组第二个元素的地址,大小是4个字节
解释5

a[1] ==*(a + 1),所以大小是4个字节
解释6

这里可能有小可爱就不明白了,为啥这里不和sizeof(a)的结果一样?前面我已经讲得很清楚了,只要数组名单独放入sizeof才是代表整个数组,计算的是整个数组的大小,&a虽然代表的是整个数组,但是取的却是数组的地址,所以&a就是数组的地址,既然是地址,就是一个数,这个数的类型是int(*)[4] ,地址的大小是4或者8个字节,记住,指针的类型的大小是4或者8个字节,地址就是一个数,用十六进制表示而已,没有啥高大尚的,如果这个&a 加1就会跳过16个字节,主要是这里很容易搞混淆,指针的大小 4或者8 字节,不同的指针类型加1跳过的字节会不相同,所以上面的结果是4或者8字节,
数组元素的地址和数组的地址的区别:是类型的区别,不是大小的区别,因为地址的大小都是4或者8个字节,
解释7

这里我们可以拆分一下,*(&a),对数组的地址解引用,得出的是整个数组,计算整个数组的大小,或者我们可以这样理解为 *&会抵消掉,结果为16
解释8

&a的类型为int(*)[4],数组地址加1 跳过整个数组,
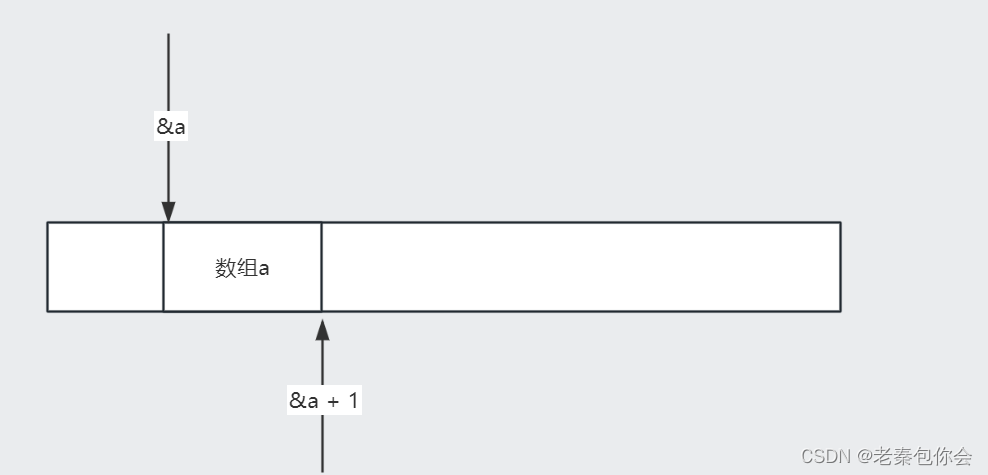
所以跳过16字节,但总归还是地址,是地址那就是4/8字节
解释9

这里是取出元素a[0]的地址,是地址,就是4/8个字节
最终的结果如下:
字符数组
#include<stdio.h>
int main()
{
//字符数组
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
return 0;
}
这里我定义了一个字符数组,我们来看看
解释1

这里数组名是单独的放的,代表整个数组,所以是计算数组的大小,单位为字节,结果是6
解释2

这里是地址,结果是4/8.不要认为是一个字节啊,指针变量的大小和类型无关,不管是啥类型的指针变量,大小都是4/8个字节
解释3

arr没有单独传入,所以代表的是数组首元素的地址,加上*解引用操作,所以计算的是是首元素的大小
解释4

这里和上面的类似,虽然&arr是代表整个数组,但是&arr取出的是数组的地址,是地址,那大小就是4或者8个字节,类型是char (*)[6]
解释5

这里和上面还是一样的,数组的地址加1,跳过整个数组,但还是地址,地址的大小是4/8个字节
解释5

strlen函数,计算字符串的长度,计算的是‘\0’前的字符个数
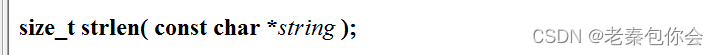
参数是一个字符指针
这里的arr是没有‘\0’的,所以是随机值
解释6

这里传入的是首元素的地址,因为strlen函数计算的是‘\0’前的字符个数,传入的只是从哪里开始计算的地址,所以大小为随机值
解释7

因为strlen函数的参数是一个字符指针,所以传入的任何数据都会被当成地址,而这里传入的是数组首元素,会转换成对应的ASCII值,然后转换成对应的十六进制,访问对应的内存,但是访问的内存不知道有没有,非法访问,所以会报错
解释8

这里传入的是数组的地址,虽然数组首元素的地址和数组的地址是一样的,但是类型不一样,数组的地址的类型为char (*)[6],而strlen的参数类型为 const char *,这里就会发生类型转换,编译器会报警告

解释9
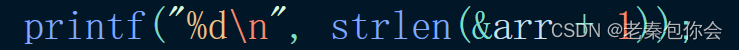
这里会跳过整个数组,结果是随机值
另一种写法
#include<stdio.h>
int main()
{
//字符数组
char arr[] = "abcdef";
printf("%d\n", sizeof(arr));
printf("%d\n", sizeof(arr + 0));
printf("%d\n", sizeof(*arr));
printf("%d\n", sizeof(arr[1]));
printf("%d\n", sizeof(&arr));
printf("%d\n", sizeof(&arr + 1));
printf("%d\n", sizeof(&arr[0] + 1));
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
return 0;
}
这里的情况和上面的类似,这里就不讲解了
另一种写法
#include<stdio.h>
int main()
{
//字符数组
char* p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p + 1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p + 1));
printf("%d\n", sizeof(&p[0] + 1));
printf("%d\n", strlen(p));
printf("%d\n", strlen(p + 1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p + 1));
printf("%d\n", strlen(&p[0] + 1));
return 0;
}
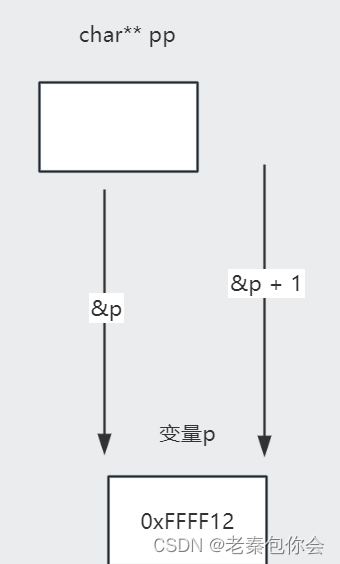
在解释之前要好好看看以下的图

可以看出p存放的是字符a的地址,而不是整个字符串
解释1

p里面存放的是字符a的地址,是地址,大小就是4/8个字节
解释2

p + 1 相当于是字符a的地址加1,偏移1个字节,地址指向的是第二个元素的地址,大小为4/8个字节
解释3

*p取出字符a,大小为1个字节
解释4

前面我们知道arr[0] <==>*(arr + 1),这里的p存储的是字符串的首元素地址,(字符a的地址),字符串相当于一个数组arr, 首元素的地址,大小为4/8个字节
解释5

这里的大小为4/8个字节,类型是char**
解释6

这里的结果是4/8个字节,&p + 1跳过4/8个字节,类型是char**
解释7

前面我们讲过p[0] ==> arr[0],也就是字符串的首元素的, &p[0] == > &arr[0] ,所以这里访问的是第二个元素的地址 ,大小为4/8个字节
解释8

p存放的是字符a的地址,所以计算的长度为6,计算’\0’前的字符个数
解释9

这里传入的是p的地址,所以大小是随机值
二维数组
#include<stdio.h>
int main()
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a));
printf("%d\n", sizeof(a[0][0]));
printf("%d\n", sizeof(a[0]));
printf("%d\n", sizeof(a[0] + 1));
printf("%d\n", sizeof(*(a[0] + 1)));
printf("%d\n", sizeof(a + 1));
printf("%d\n", sizeof(*(a + 1)));
printf("%d\n", sizeof(&a[0] + 1));
printf("%d\n", sizeof(*(&a[0] + 1)));
printf("%d\n", sizeof(*a));
printf("%d\n", sizeof(a[3]));
return 0;
}
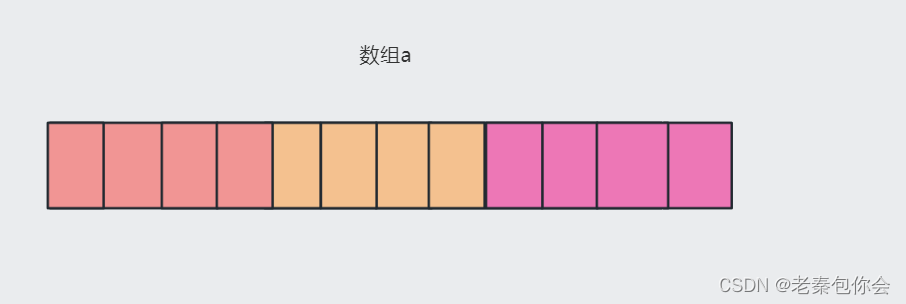
相同颜色的相当于一个一维数组,二维数组相当于是一维数组的数组,我们可以理解二维数组的元素个数是一维数组的个数,但是我们可以想象成以下场景
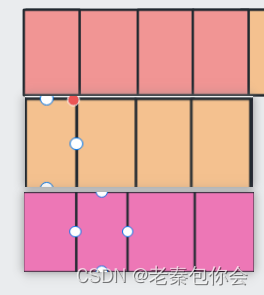
a[0]、a[1]、a[2]可以认为是数组名,一一对应第几行,a[0]第一行, a[1]第二行,a[2]第三行
解释1

这里单独传入了数组名,代表整个数组,计算整个数组的大小,单位为字节,大小为48字节
解释2

这里arr[0][0]是一个整形数据,大小为4字节
解释3

这里相当于传入了一个数组名,代表的是a[0]的一维数组,计算的是a[0]一维数组的大小,就是16字节
解释4

首先,a[0]相当于一个一维数组的数组名,没有单独放在sizeof里,所以代表的是这一维数组的首元素地址,加1,得出第二元素的地址,是地址,大小就是4/8字节
解释5

前面我们已经知道a[0]是一维数组的数组名,数组名加1,得到第二元素的地址,地址解引用指向第二元素,第二元素是一个整形,大小为4
解释6
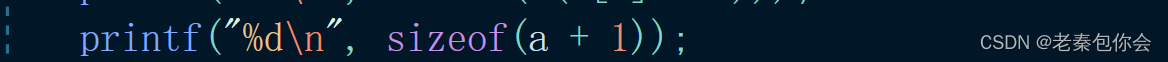
可以看出这里传入的是数组a首元素的地址,加一是第二元素的地址,是地址大小就是4/8个字节,类型是int(*)[4]
解释7
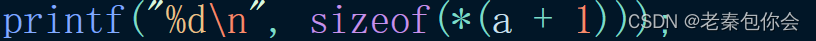
a数组首元素的地址,加1,是第二元素的地址,解引用得到第二元素, (a + 1) = a[1], 因为数组a是二维数组,相当于是一维数组的数组a[1],传入数组名,计算的是一维数组的大小,所以结果为16字节
解释8

这里是取出a[0]的地址,加1 就是a[1]的地址,是地址,那就是4/8字节,类型为int(*)[4],或者我们可以换个思路,a[0]是一维数组名, 加个&就变成了取出一维数组的地址,然后加1,跳过这个数组,因为二维数组的存储是连续,会指向第二个一维数组地址
解释9
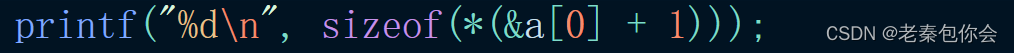
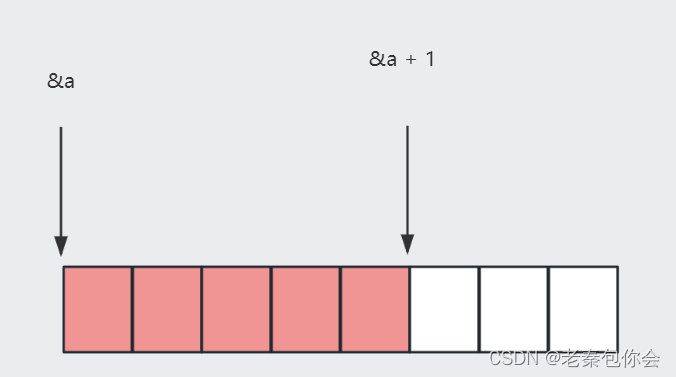
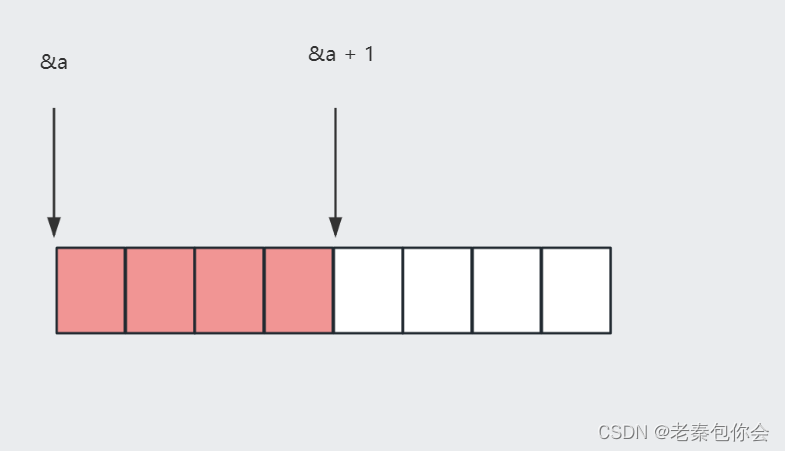
上面我们已经讲过了(&a[0] + 1)是第二个一维数组 的地址,加上就是a[1],是数组名,计算的是一维数组的大小,结果16字节
解释10
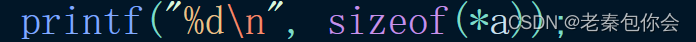
a为二维数组名,没有单独传入,所以是首元素的地址,&a[0],加上*就是一维数组名了,计算的是一维数组的大小,结果为16字节
解释11

有小可爱看到这里,越界了?,越界是要去访问对应的内存,sizeof不会去访问对应的内存,我们前面测试过sizeof(int)和sizeof(1)的大小是一样的,sizeof是根据类型来判断大小的,a[3]的类型和a[0]的类型是一样的, 所以不会去访问内存,不访问内存,就不存在越界
总结:
数组名的意义:
- sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
- 除此之外所有的数组名都表示首元素的地址。
指针笔试解释
笔试题1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
return 0;
}
结果:

可能看到这里有写些小可爱就会很困惑,
不急,我来讲解
 这道题是把&a + 1强转成int类型,加1减1都会越过4个字节,这就是(ptr - 1)最终指向的元素5的地址并解引用
这道题是把&a + 1强转成int类型,加1减1都会越过4个字节,这就是(ptr - 1)最终指向的元素5的地址并解引用
笔试题2
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sBa[4];
}*p;
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
这里结构体的大小涉及到内存对齐,后面会讲解,
我们知道这个结构体类型的大小为20字节,所以创建出来的结构体变量的大小也是20字节,
- 0x1转换成十进制是1,p + 1 跳过20个字节,因为前面已经定义了变量p是结构体指针变量
注意一下,p的数组从没有被改变 - p强转成unsigned long 类型,加1就是我们正常的十进制加1
- p强转成unsigned int *类型,加1 跳过4个字节
- %p是打印格式
笔试题3
#include<stdio.h>
int main()
{
int a[4] = { 1, 2, 3, 4 };
int* ptr1 = (int*)(&a + 1);
int* ptr2 = (int*)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}
前面我们讲过 a[0] <==> a + 0,那这里的ptr1[-1]相当于ptr +(-1),因为ptr = &a + 1,又被强转成int类型,所以减1就指向4的地址,%x为十六进制输出。
(int)((int)a + 1)这里主要是首元素的地址的类型被强转为int, 加1就是数学的加1,
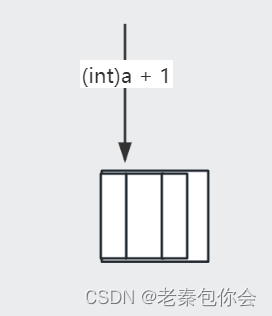
我们知道int*类型是访问4个字节,这里少了一个字节,那就会往后再访问一个字节,既然我们知道会这样访问,那我们还要知道这些内容是啥,前面我们还理解过内存的存储在vs编译器时小端存储,有不懂的可以看看我的这篇博客C语言进阶第一课,
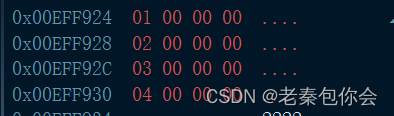

可以看到vs编译器的存储是十六进制的,一个字节是8bit 每4个bit表示一个十六进制位,所以ptr2访问的是 00 00 00 02 ,因为是小端存储,要写成我们认识的补码就是 02 00 00 00
笔试题4
#include <stdio.h>
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int* p;
p = a[0];
printf("%d", p[0]);
return 0;
}
这里主要涉及到逗号表达式,化简得int a[3][2] = {1, 3, 5}
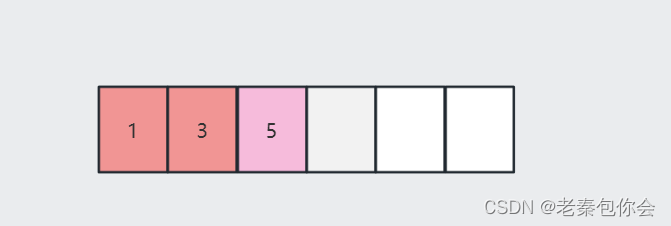
前面我们知道二维数组是一维数组的数组, a[0]是第一行一维数组的数组名,元素,所以p存储的是元素1的地址,又因为p[0] <==> *(p + 0)所以这里的结果为1
笔试题5
#include <stdio.h>
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}
这里定义了一个二维数组a和一个 数组指针变量p, p = a 所以p存储的是 &a[0],也就是二维数组名

可以看到a[4][2]是一个元素 ,&a[4][2]就是该元素的地址,而p变量的类型是int(*)[4] ,加1 就是跳过16字节, 而a[0]的类型是int(*)[5], 所以&p[4][2]是18格子,也就是&a[3][3],而 a[4][2] 是22格,而我们知道数组的内存存储是从小到大存储的,所以p[4][2]是小地址 ,两者相减就是-4,-4要在内存存储是以补码的形式存储,即:
11111111111111111111111111111100,因为是%p输出,不会去区分补码和原码,所以直接打印补码0xfffffffc,
%p是打印地址的,认为内存存储的补码就是地址,
笔试题6
#include <stdio.h>
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}
定义一个二维数组 , &aa的类型是 int(*)[2][5];
&aa + 1 跳过40个字节, aa数二维数组的首元素的地址, 也就是 &aa[0] , aa + 1就是第二行一维数组的地址,前面我讲过a[0] 等于*(a + 0), 那*(aa + 1) <==> aa[1],或者我们可以理解为二维数组的元素是一维数组名,解引用得到对应的数组名,所以ptr2存储的是6的地址,最终结果是 10 和5
笔试题7
#include <stdio.h>
int main()
{
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
return 0;
}
这里的a是一个指针数组 里面的元素类型是char , pa是一个二级指针
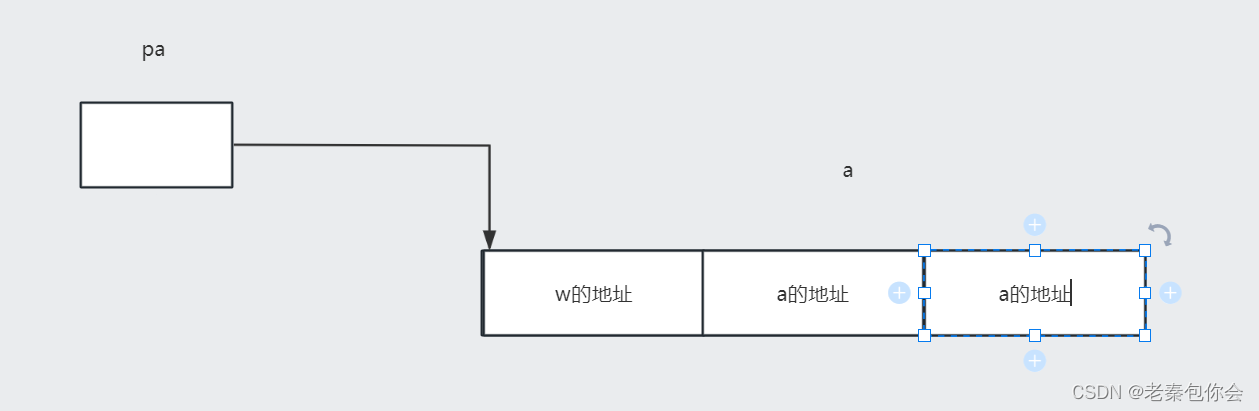
这样就很明了,我们需要注意的是%s遇到’\0’就停止了,因为pa++,所以是指向第二个元素的地址,因为 p是一个二级指针变量, 类型是 char*, 加1跳过4个字节,而a的一个元素大小是4个字节,所以打印的是at
笔试题8
#include <stdio.h>
int main()
{
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
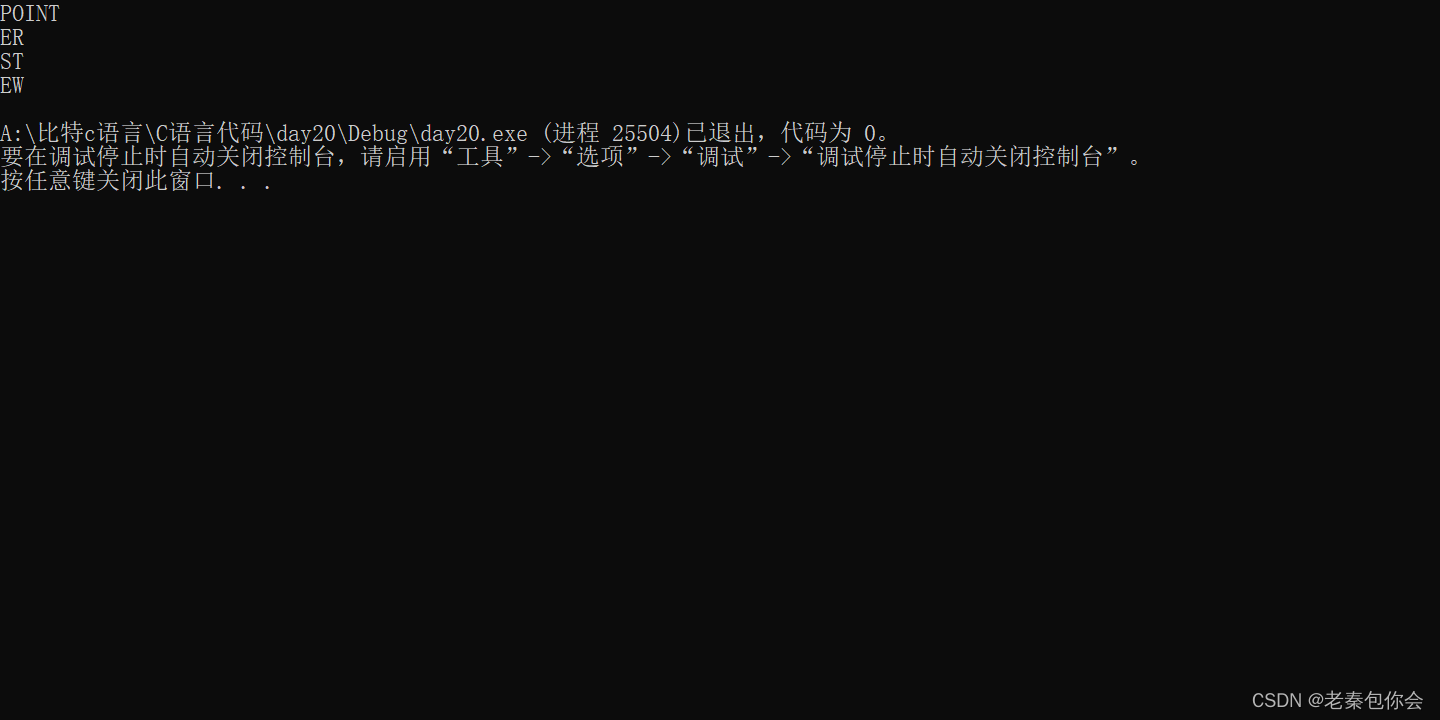
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}
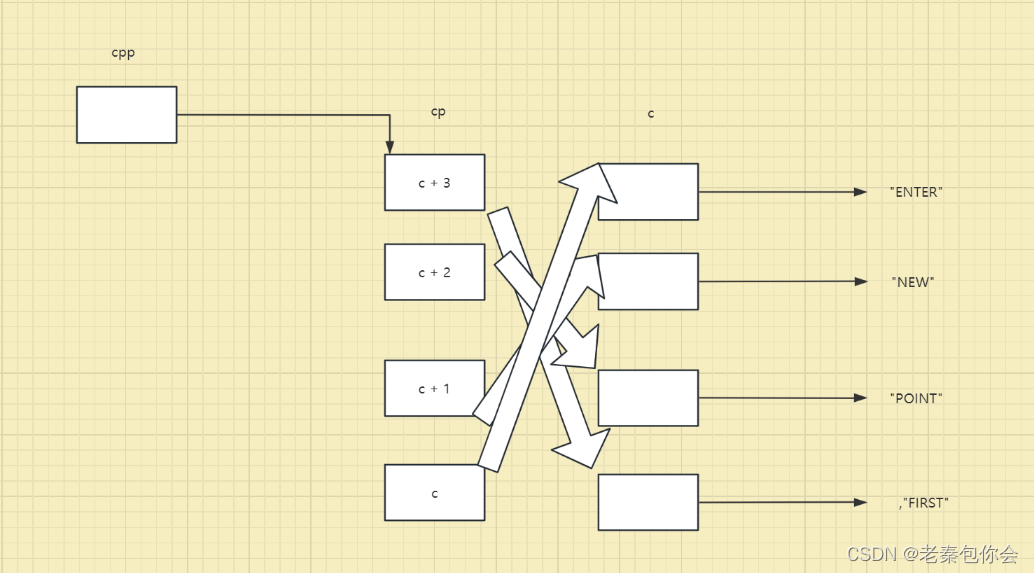
这是关系图
这里我们要注意cpp会改变,**++cpp 就是cpp先加1,cpp指向c+2 的地址.解引用两次,结果是POINT

这里我们要清楚运算符的优先级,就是 + 的优先级很低 cpp 先加1 指向c + 1 的地址,然后解引用得出 c + 1 ,c + 1再减1,cp[2] = c,然后解引用得到字符E的地址, E的地址加3 ,结果为ER
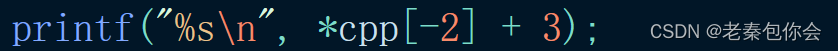
前面的cpp = &cp[2]
*cpp[-2]相当于**(cp),然后加 3 ,结果为ST,注意一下,这里的cpp没有改变
cpp = &cp[2]
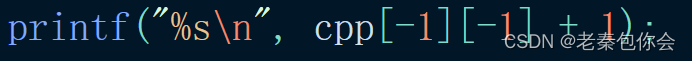
经过上面的操作 cp[2] = c
cpp[-1][-1] == cp[1][-1] == (c + 2)[-1] == c[1],最终结果为EW
C语言的进阶指针到这里就结束了,有不懂的小可爱可以私聊我