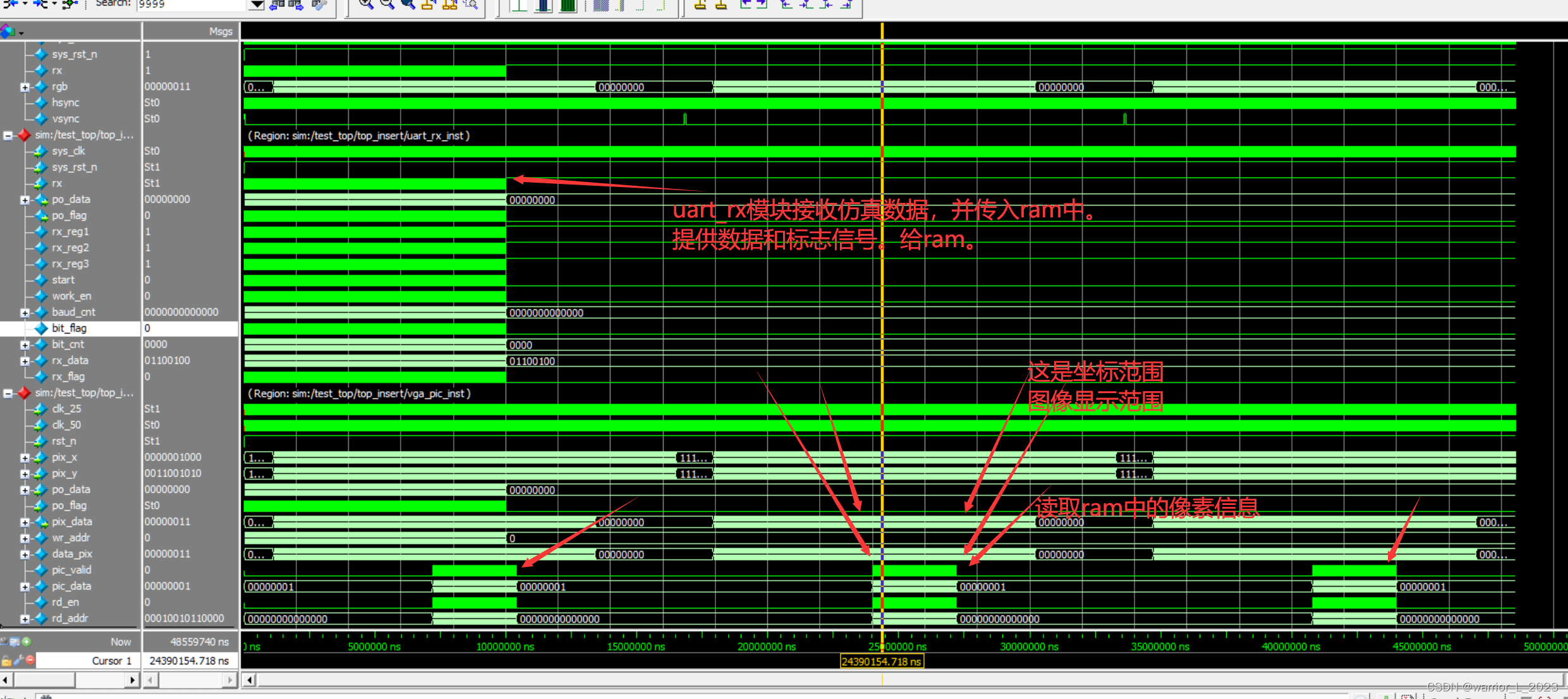
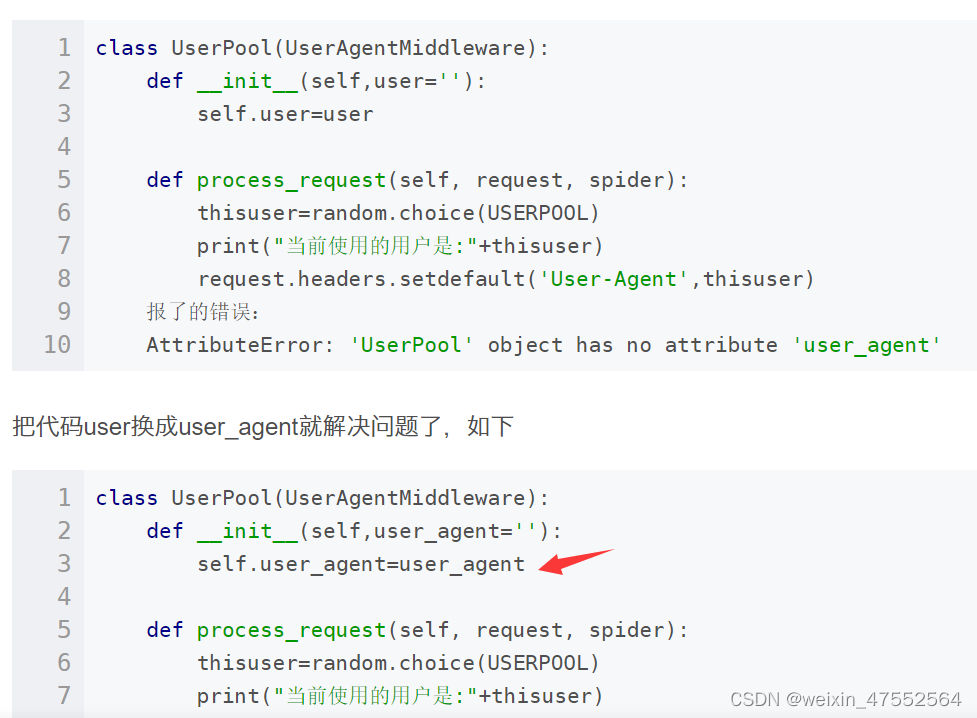
参考自https://blog.csdn.net/y472360651/article/details/130002898
记得把BanSpider改成自己的项目名,还有一个细节要改一下,把代码user换成user_agent
禁止Cookie
在Scrapy项目中的settings文件,可以发现文件中有以下代码:
COOKIES_ENABLED = False
设置下载延时与自动限速
有的网站会通过我们队网页的访问频率进行分析,如果爬取频率过快,则判断为爬虫自动爬取行为,识别后对我们进行相应限制,比如禁止我们再爬取该服务器上的网页等。对于这一类网站,我们只需要控制一下爬行时间间隔即可。在Scrapy项目中,我们可以直接在settings.py文件进行相应的设置:
DOWNLOAD_DELAY = 3
1
这样,我们就实现了下载延时的功能,下载网页的时间间隔将为3秒。设置好了之后,就可以避免被这一类反爬虫机制的网站禁止。其实DOWNLOAD_DELAY = 3在settings.py中是存在的,只不过被注释了,我们只需要将这一行的注释取消即可。但是存在一个问题,DOWNLOAD_DELAY设置完成之后,不能动态改变,导致访问延时都差不多,也容易被发现。不过我们可以设置RANDOMIZE_DOWNLOAD_DELAY字段,进行动态调整:
RANDOMIZE_DOWNLOAD_DELAY = True
1
如果启用,当从相同的网站获取数据时,Scrapy将会等待一个随机的值,延迟时间为0.5到1.5之间的一个随机值乘以DOWNLOAD_DELAY。这回大大降低被发现的几率,有一些网站会检测访问延迟的相似性,也有被发现的可能。Scrapy提供了一种更智能的方法来解决限速的问题:通过自动限速扩展,该扩展能根据Scrapy服务器及爬取的网站的负载自动限制爬取速度。
Scrapy是如何实现自动限速扩展的呢?在Scrapy中,下载延迟是通过计算建立TCP连接并接收到HTTP包头之间的时间间隔来测量的,该扩展就是以此为前提进行编写的,实现自动限速功能组要几个重要的配置:
启动自动限速扩展
AUTOTHROTTLE_ENABLED = True
初始下载延时,单位为秒
AUTOTHROTTLE_START_DELAY = 5
在高延迟情况下的最大下载延迟,单位为秒
AUTOTHROTTLE_MAX_DELAY = 60
启动DEBUG模式
AUTOTHROTTLE_DEBUG = True
对单个网址进行并发请求的最大值
CONCURRENT_REQUESTS_PER_DOMAIN = 8
对单个IP进行并发请求的最大值,如果非零,则自动忽略CONCURRENT_REQUESTS_PER_DOMAIN
CONCURRENT_REQUESTS_PER_IP = 0
设置IP池
有的网站会对用户的IP进行检测,如果同一个IP在短时间内对自己服务器上的网页进行大量的爬取,那么可以初步判定为网络爬虫的自动爬取行为,该网站有可能会针对该IP的用户禁止访问。如果我们的IP被禁止访问了,就需要更换IP,对于普通用户来说IP资源可能会有限,那么怎么样才能有较多的IP呢?利用代理服务器我们可以获取不同的IP,所以此时我们可以获取多个代理服务器,将这些服务器的IP组成一个IP池,爬虫每次对网页进行爬取的时候,可以随机选择IP池中的一个IP进行访问。如需满足以上需求,须要几个重要步骤: