链表的概念及结构
有了顺序表为什么还会出现链表呢?
链表和数组类似,但是功能比数组强大的多,数组的空间是固定的,在定义数组的时候空间大小就已经固定了,在使用时有可能会造成空间的浪费或者面临空间不够的风险,而链表的空间时动态的,则避免了这一问题。
概念
链表是一种物理上存储结构非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
线性表中的数据结点在内存中的位置是任意的,即逻辑上相邻的数据元素在物理位置(内存存储的位置)上不一定相邻。
链式存储结构的有优点
- 空间利用率高需要一个空间就分配一个空间
- 数据元素的逻辑次序靠节点的指针来指示,插入和删除时不需要移动数据结点,任意位置插入和删除时间复杂度为O(1)
链式存储结构的缺点 - 存储密度小,每个节点的指针域需要额外占用存储空间。当每个节点的数据域所占字节不多时,指针域所占空间比重显得很大,存储密度大空间利用率越大。
- 链式存储结构时非随机存取结构,对任一节点的操作都要从头指针依次查找到该节点,算法复杂度比较高。
链式存储的逻辑结构

从上图可以看出,链式结构在逻辑上是连续的,但是在物理上不一定连续,现实中的节点一般都是从堆上申请出来的。从堆上申请的空间,是按照一定的策略来分配的,两次申请的空间可能连续,也可能不连续。
链表的分类
实际中的链表的结构非常多样:
1.单向或者双向
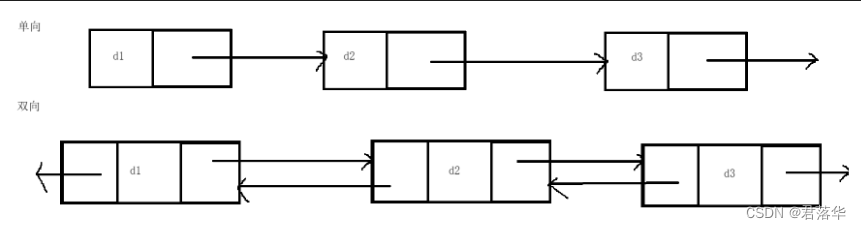
上图就是单向和双向循环的逻辑图
2.带头或不带头
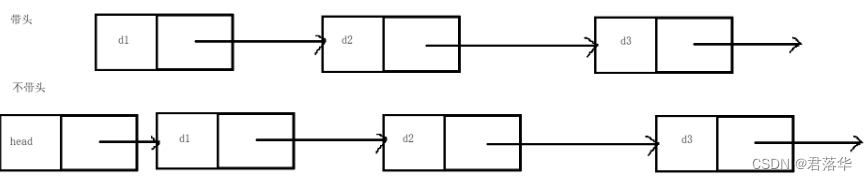
上图就是带头和不带头的逻辑图
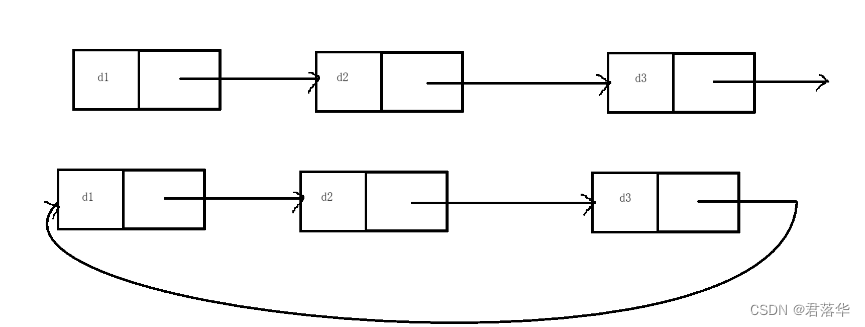
上图就是循环和非循环的逻辑图
链表的基本组合:
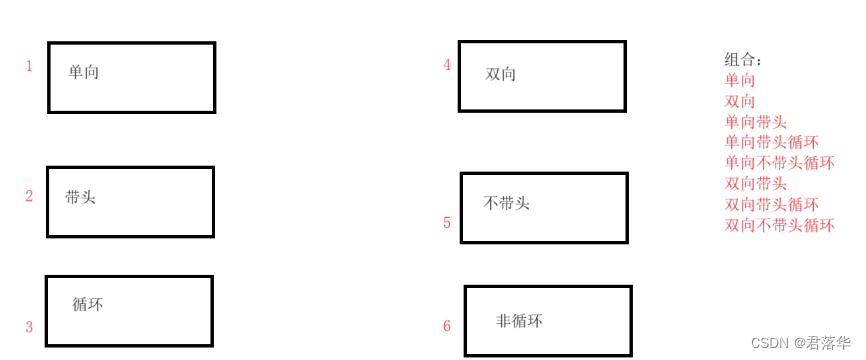
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接等等。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是双向带头循环链表。另外这个结构虽然复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了。
链表的构成
链表是由一个个节点构成,每个节点一般采用结构体的形式组织,如下:
typedef int SLDataType;
typedef struct SListNode
{
SLDataType data;
struct SListNode* next;
}SListNode;
链表节点分为两个域
数据域:存放各种类型的实际数据。
指针域:存放下一节点的首地址。
链表的操作
链表最大的作用是通过节点把离散的数据链接在一起,组成一个表。链表有那些常规操作呢?有如下操作:尾插、头插、尾删、头删、查找、在pos位置之后插入、删除pos位置之后的值等操作。
下面我们就来慢慢的分析:
动态申请空间:
首先是让链表满的时候动态申请空间,这样就不需要我们自己去手动的管理了。
1.使用malloc来创建新的节点
2.在判断节点是否创建成功
3.在给节点赋值,并把节点中的指针置空
4.返回节点的指针
代码如下:
//动态的申请节点
SListNode* BuySListNode(SLDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode==NULL)
{
perror("malloc");
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
在我们检验链表功能的时候,我们需要打印到屏幕上才能清楚我们写的链表功能是否成功。
单链表的打印:
1.首先判断指针是否是空指针
2.创建一个新的指针来指向结构体,目的就是使用这个指针来遍历
注意:一点不要使用头指针来遍历,这样会导致我们丢失数据的。
代码如下:
//链表的打印
void SListPrint(SListNode* plist)
{
assert(plist);
SListNode* cur = plist;
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("\n");
}
下图是整个遍历的过程:
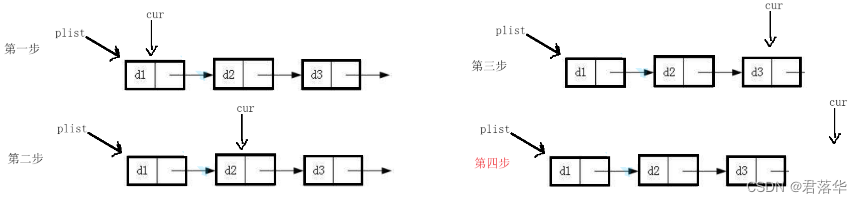
注意:这里有个坑就是循环结束的条件,一定是创建的指针走到空结束,而不是指针指向的next为结束条件。
单链表的尾插:
首先我们要分情况,第一种就是传递过来的指针是空指针,第二种情况就是不是空指针的情况,着两种情况我们都要分别写代码。
1.首先我们新创建一个节点用来存储数据
2.在判断传递过来的指针是否是空指针
1)如果是空指针,那么我们直接返回新的节点
2)要是不是空指针,那么我们就创建一个新的指针来寻找尾节点
代码如下:
//单链表尾插
void SListPushBack(SListNode** pplist, SLDataType x)
{
assert(pplist);
SListNode* newnode = BuySListNode(x);
if (*pplist==NULL)
{
*pplist = newnode;
}
else
{
SListNode* tail = *pplist;
while (tail->next!=NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
下图是逻辑图:
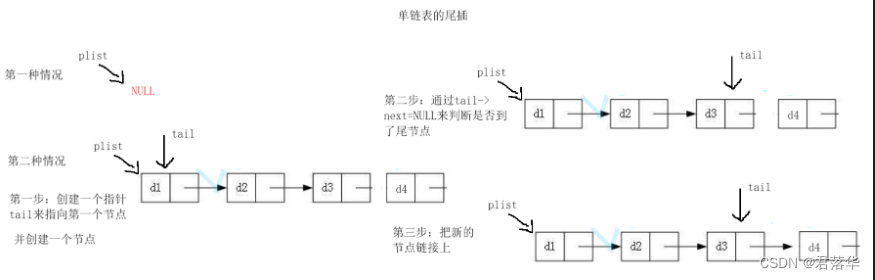
注意:在寻找尾节点的时候要注意当next为空的时候那个节点就是位节点,所以我们使用tail->next来判断。
单链表的头插:
首先我们也要分三种情况:
第一种情况就是直接传递过来的指针是空指针,对于这种情况我直接使用断言来终止程序,
第二种情况就是传递过来的指针里面的内容是空,这种情况直接返回新的节点,
第三种情况就是我们传递过来的指针有指向的数据,那么我们直接插入节点就好了。
代码如下:
1.断言接收到的指针是否位空指针
2.创建一个新的节点,用来存储要插入的数据
3.要是接收到的指针内容为空那么直接返回新的节点
4.要是里面有链表那么直接插入
//单链表的头插
void SListPushFront(SListNode** pplist, SLDataType x)
{
assert(pplist);
SListNode* newnode = BuySListNode(x);
if (*pplist==NULL)
{
*pplist = newnode;
}
else
{
newnode->next = *pplist;
*pplist = newnode;
}
}
下图是头插的逻辑图:
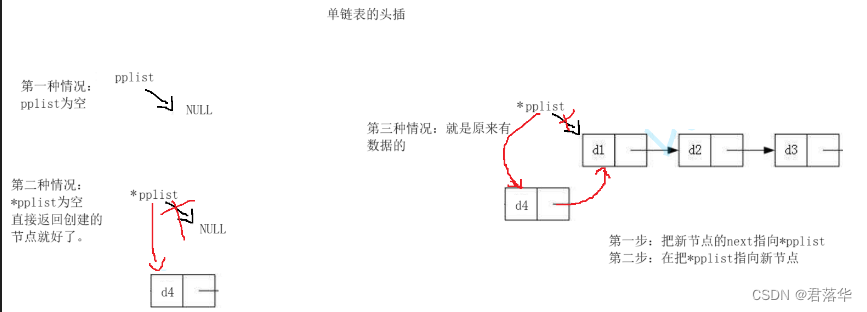
注意: 在第三步的时候不要把
newnode->next = *pplist;
*pplist = newnode;
这两行代码写反了如果写反了会导致后面的数据丢失。
单链表的尾删:
要考虑的情况:
1.是否接收的指针是空指针
2.是否只有一个节点
3.多个节点
要是为空指针那么直接就终止程序,要是只有一个节点直接释放当前节点,并且把它的头节点置空,要是有多个节点的情况我们就需要找到最后一个节点和倒数第二个节点,我们在释放最后一个节点的时候,也要把倒数第二个节点置空,只有这样才能不导致倒数第二个指针变为也指针。
void SListPopBack(SListNode** pplist)
{
assert(pplist);
SListNode* prev = NULL;
SListNode* tail = *pplist;
// 1.空、只有一个节点
// 2.两个及以上的节点
if (tail == NULL || tail->next == NULL)
{
free(tail);
*pplist = NULL;
}
else
{
while (tail->next)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}
下图是单链表的逻辑图:
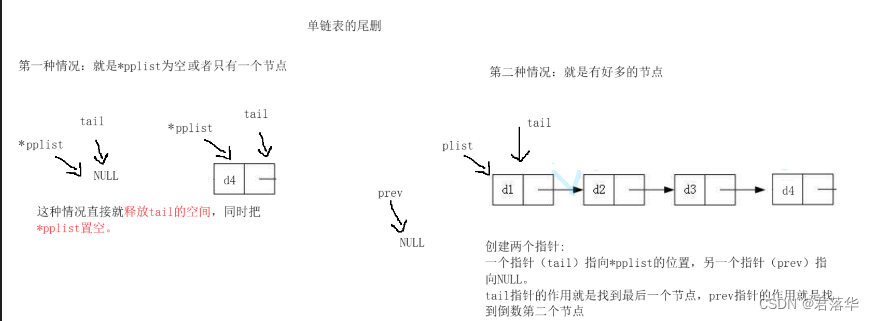
注意:在第二种情况下一定要找到倒数第二个指针,不然容易造成野指针的错误。
单链表的头删:
要考虑的情况:
第一种:为空的情况
第二种:就是不为空的情况
代码如下:
//单链表的头删
void SListPopFront(SListNode** pplist)
{
assert(pplist);
//为空的情况
assert(*pplist);
//不为空的情况
SListNode* newnode = (*pplist)->next;
free(*pplist);
*pplist = newnode;
}
下图是头删的逻辑图:
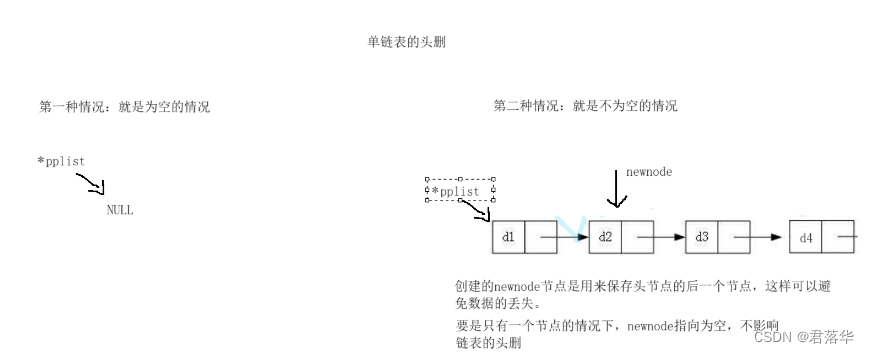
第一种情况就是为空的,对于这种情况我们直接断言终止程序;
第二种情况不为空的,对于这种情况我创建一个新的节点来保存 * pplist 指向的位置,然后再释放 * pplist
,最后再把第二个节点设置为头节点。
单链表查找:
要考虑的情况:
第一种:为空的情况
第二种:遍历完了也没有找到
第三种:找到了返回当前指针
代码如下:
//单链表查找
SListNode* SListFind(SListNode* plist, SLDataType x)
{
assert(plist);
SListNode* cur = plist;
while (cur)
{
if (cur->data==x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
下图就是单链表的查找逻辑图:
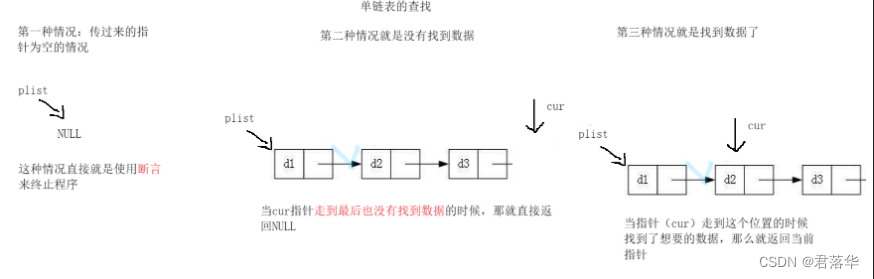
对于为空的情况我直接就是使用断言来解决,要是找到了就返回当前节点的地址,要是没有找到就返回空。
单链表在pos之前插入数据:
要考虑的情况:
第一种:为空的情况
第二种:当pos的位置等于pplist的时候
第二种:就是正常的插入
代码如下:
// 在pos之前插入x
void SLTInsert(SListNode** pplist, SListNode* pos, SLDataType x)
{
assert(pplist);
assert(pos);
if (pos==*pplist)
{
//直接调用头插
SListPushFront(pplist, x);
}
else
{
//创建新的指针来指向头
SListNode* cur = *pplist;
//创建新的节点来存储数据
SListNode* newnode = BuySListNode(x);
//当cur->next不等于pos的时候就继续循环
while (cur->next!=pos)
{
cur = cur->next;
}
cur->next = newnode;
newnode->next = pos;
}
}
下图是单链表在pos之前插入数据的逻辑图:
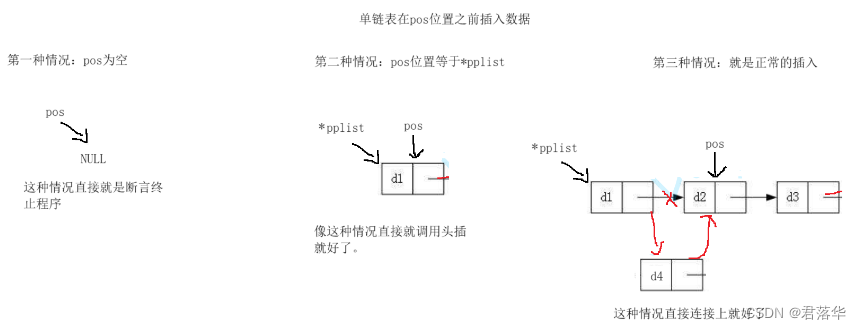
首先我使用的断言来判断指针是否为空,然后使用if来判断pos的位置是否等于pplist的位置,最后就是直接插入节点。
在pos位置之后插入数据:
这个比较简单,不需要考虑头尾的问题,只需要考虑,pos位置是否为空指针。
代码如下:
// 在pos以后插入x
void SLTInsertAfter(SListNode* pos, SLDataType x)
{
assert(pos);
//创建一个新的节点
SListNode* newnode = BuySListNode(x);
//当在中间插入的时候就需要这个步骤
newnode->next=pos->next;
pos->next = newnode;
}
下图是在pos位置之后插入数据的逻辑图:
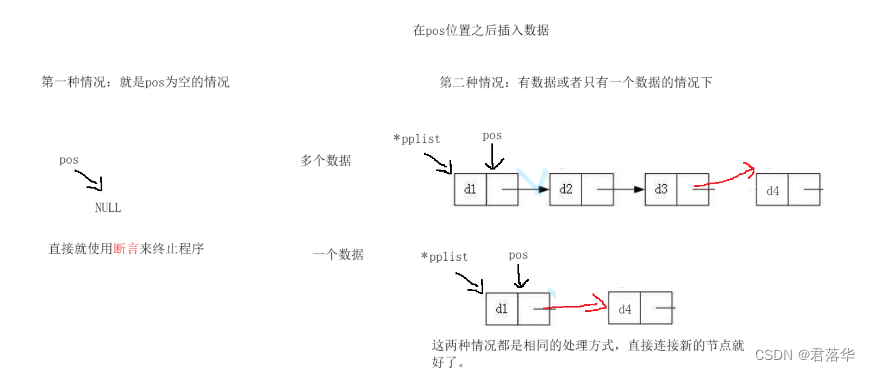
删除pos位置的值:
第一种情况:当pos位置指向的是头的时候就直接调用头删
第二种情况:在尾和中间的时候,我们之间按照中间的处理方式处理就好了,因为在尾不需要特别处理。
代码如下:
void SLTErase(SListNode** pplist, SListNode* pos)
{
assert(pplist);
assert(pos);
if (pos==*pplist)
{
SListPopFront(pplist);
}
else
{
SListNode* pre = *pplist;
while (pre->next!=pos)
{
pre = pre->next;
}
pre->next = pos->next;
free(pos);
}
}
删除pos位置的数据的逻辑图:
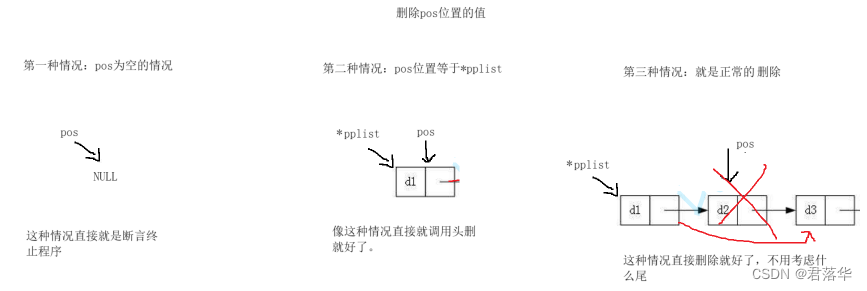
单链表的销毁:
使用遍历的方式进行处理,边遍历边删除
代码如下:
// 单链表的销毁
void SListDestroy(SListNode* plist)
{
assert(plist);
SListNode* del = plist;
while (plist)
{
plist = del;
del = del->next;
free(plist);
}
}
总代码
#define _CRT_SECURE_NO_WARNINGS 1
#include"List.h"
//动态的申请节点
SListNode* BuySListNode(SLDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode==NULL)
{
perror("malloc");
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
//链表的打印
void SListPrint(SListNode* plist)
{
assert(plist);
SListNode* cur = plist;
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("\n");
}
//单链表尾插
void SListPushBack(SListNode** pplist, SLDataType x)
{
assert(pplist);
SListNode* newnode = BuySListNode(x);
if (*pplist==NULL)
{
*pplist = newnode;
}
else
{
SListNode* tail = *pplist;
while (tail->next!=NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
//单链表的头插
void SListPushFront(SListNode** pplist, SLDataType x)
{
assert(pplist);
assert(pplist);
SListNode* newnode = BuySListNode(x);
if (*pplist==NULL)
{
*pplist = newnode;
}
else
{
newnode->next = *pplist;
*pplist = newnode;
}
}
//单链表的尾删
void SListPopBack(SListNode** pplist)
{
assert(pplist);
assert(*pplist);
if ((*pplist)->next==NULL)
{
free(*pplist);
*pplist = NULL;
}
else
{
SListNode* tail = *pplist;
//tail直接向后走两步这样可以避免使用第二个指针
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
//单链表的头删
void SListPopFront(SListNode** pplist)
{
assert(pplist);
//为空的情况
assert(*pplist);
//不为空的情况
SListNode* newnode = (*pplist)->next;
free(*pplist);
*pplist = newnode;
}
//单链表查找
SListNode* SListFind(SListNode* plist, SLDataType x)
{
assert(plist);
SListNode* cur = plist;
while (cur)
{
if (cur->data==x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
// 在pos之前插入x
void SLTInsert(SListNode** pplist, SListNode* pos, SLDataType x)
{
assert((*pplist) && pos);
if (pos==*pplist)
{
SListPushFront(pplist, x);
}
else
{
SListNode* cur = *pplist;
SListNode* newnode = BuySListNode(x);
while (cur->next!=pos)
{
cur = cur->next;
}
cur->next = newnode;
newnode->next = pos;
}
}
// 在pos以后插入x
void SLTInsertAfter(SListNode* pos, SLDataType x)
{
assert(pos);
//创建一个新的节点
SListNode* newnode = BuySListNode(x);
//当在中间插入的时候就需要这个步骤
newnode->next = pos->next;
pos->next = newnode;
}
//删除pos位置的值
void SLTErase(SListNode** pplist, SListNode* pos)
{
assert(pplist);
assert(pos);
if (pos==*pplist)
{
SListPopFront(pplist);
}
else
{
SListNode* pre = *pplist;
while (pre->next!=pos)
{
pre = pre->next;
}
pre->next = pos->next;
free(pos);
}
}
// 单链表的销毁
void SListDestroy(SListNode* plist)
{
assert(plist);
SListNode* del = plist;
while (plist)
{
plist = del;
del = del->next;
free(plist);
}
}
以上就是我关于数据结构中的单链表的细节问题和总结,下一篇博客我会写一篇关于单链表的力扣真题,并附上详细的讲解。