2020 年 Open AI 发布了由包含 1750 亿参数的神经网络构成的生成式大规模预训练语言模型 GPT-3 (Gener- ative Pre-trained Transformer 3)。开启了大规模语言模型的新时代。由于大规模语言模型的参数量巨大, 如果在 不同任务上都进行微调需要消耗大量的计算资源, 因此预训练微调范式不再适用于大规模语言模型。但是研究 人员发现, 通过语境学习(Incontext Learning ,ICL) 等方法, 直接使用大规模语言模型就可以在很多任务的少 样本场景下取得很好的效果。此后, 研究人员们提出了面向大规模语言模型的提示词(Prompt) 学习方法、模型 即服务范式(Model as aService,MaaS)、指令微调(Instruction Tuning) 等方法, 在不同任务上都取得了很好的 效果。与此同时, Google 、Meta、百度、华为等公司和研究机构都纷纷发布了包括 PaLM 、LaMDA 、T0 等不同 大规模语言模型。2022 年底 ChatGPT 的出现, 将大规模语言模型的能力进行了充分的展现, 也引发了大规模语 言模型研究的热潮。
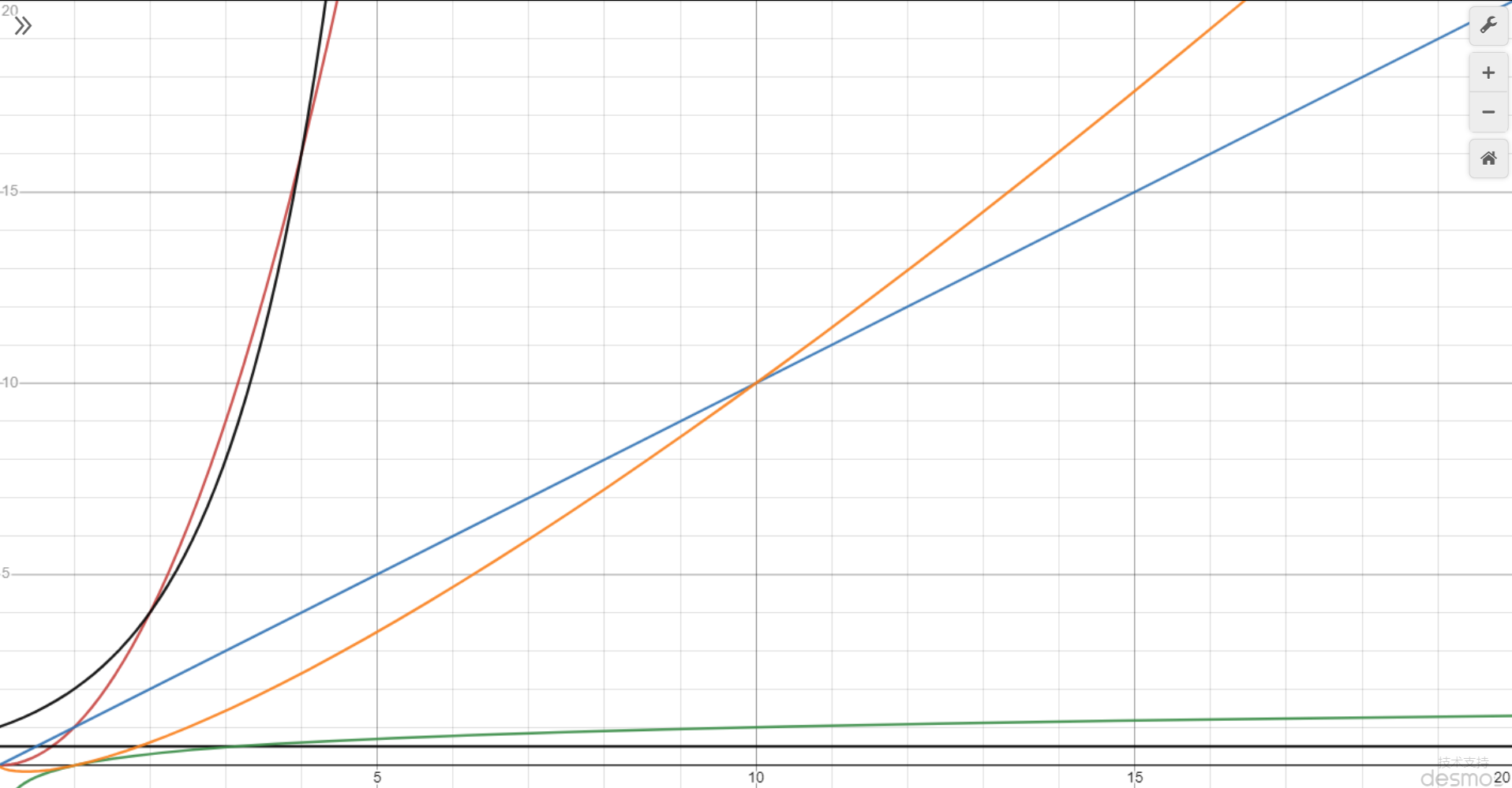
Kaplan 等人在文献中提出了缩放法则(Scaling Laws), 指出模型的性能依赖于模型的规模, 包括:参数数 量、数据集大小和计算量, 模型的效果会随着三者的指数增加而线性提高。如下图所示, 模型的损失(Loss) 值 随着模型规模的指数增大而线性降低。这意味着模型的能力是可以根据这三个变量估计的, 提高模型参数量, 扩 大数据集规模都可以使得模型的性能可预测地提高。这为继续提升大模型的规模给出了定量分析依据。

大规模语言模型的缩放法则(Scaling Laws)
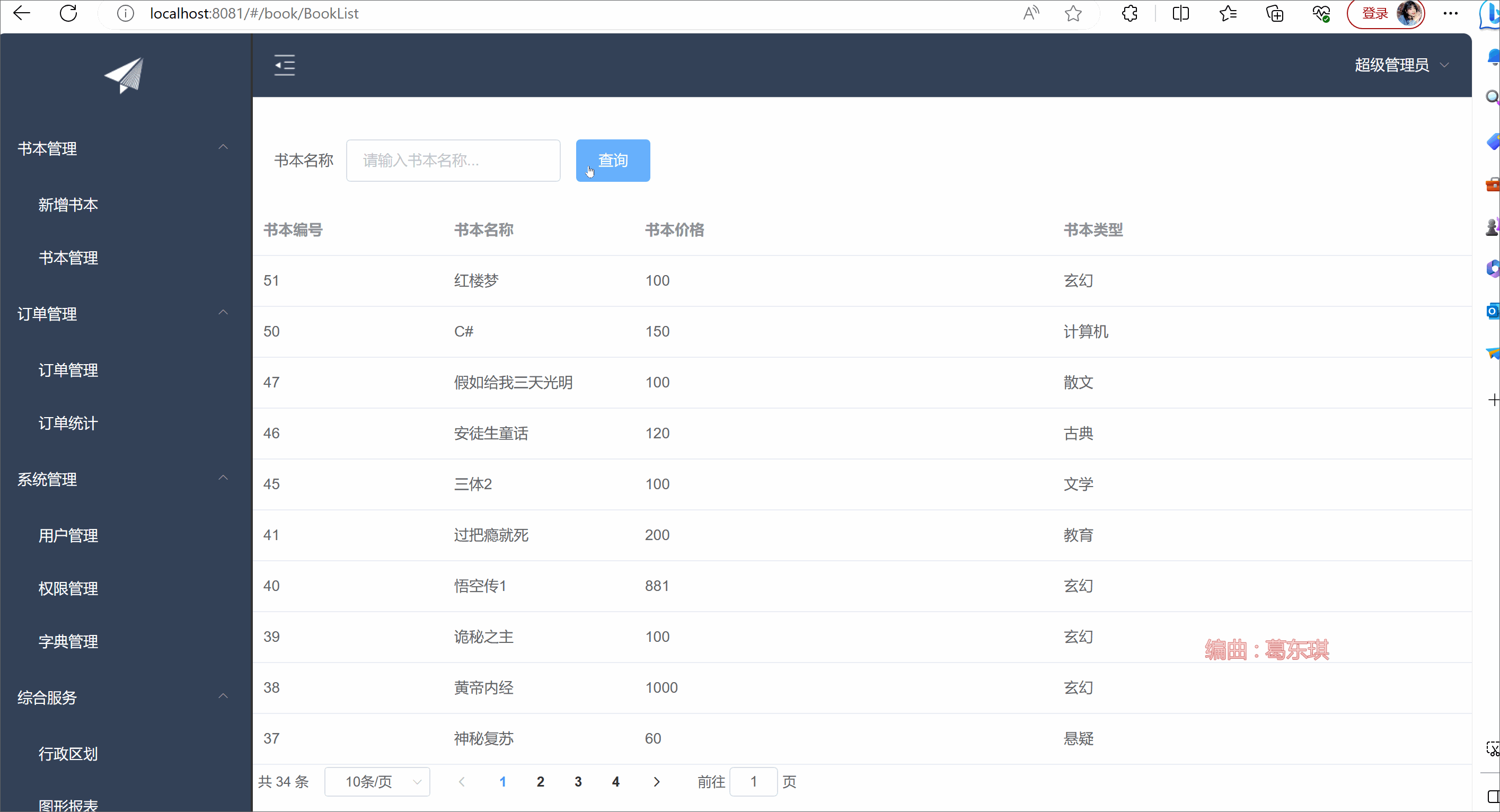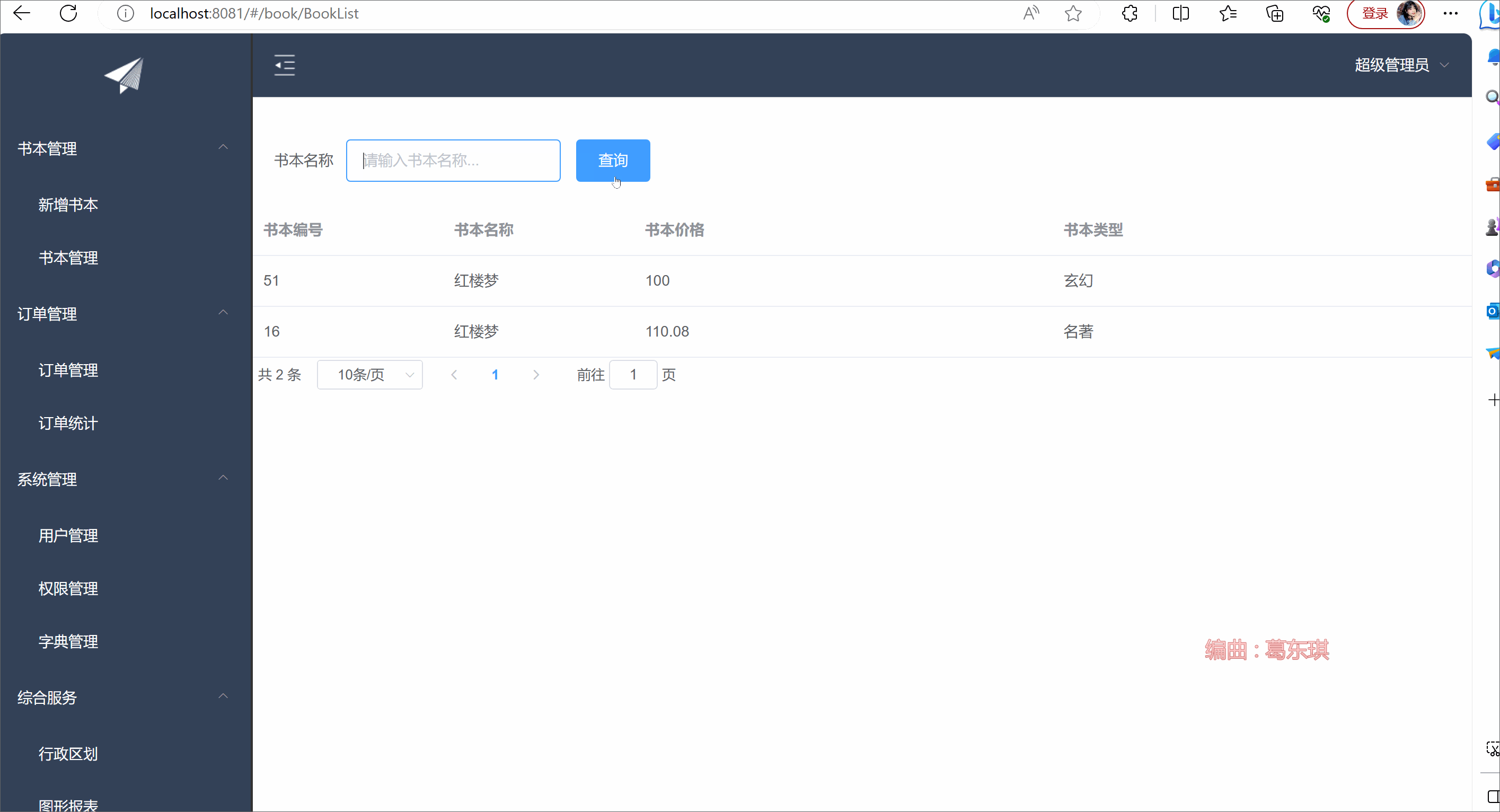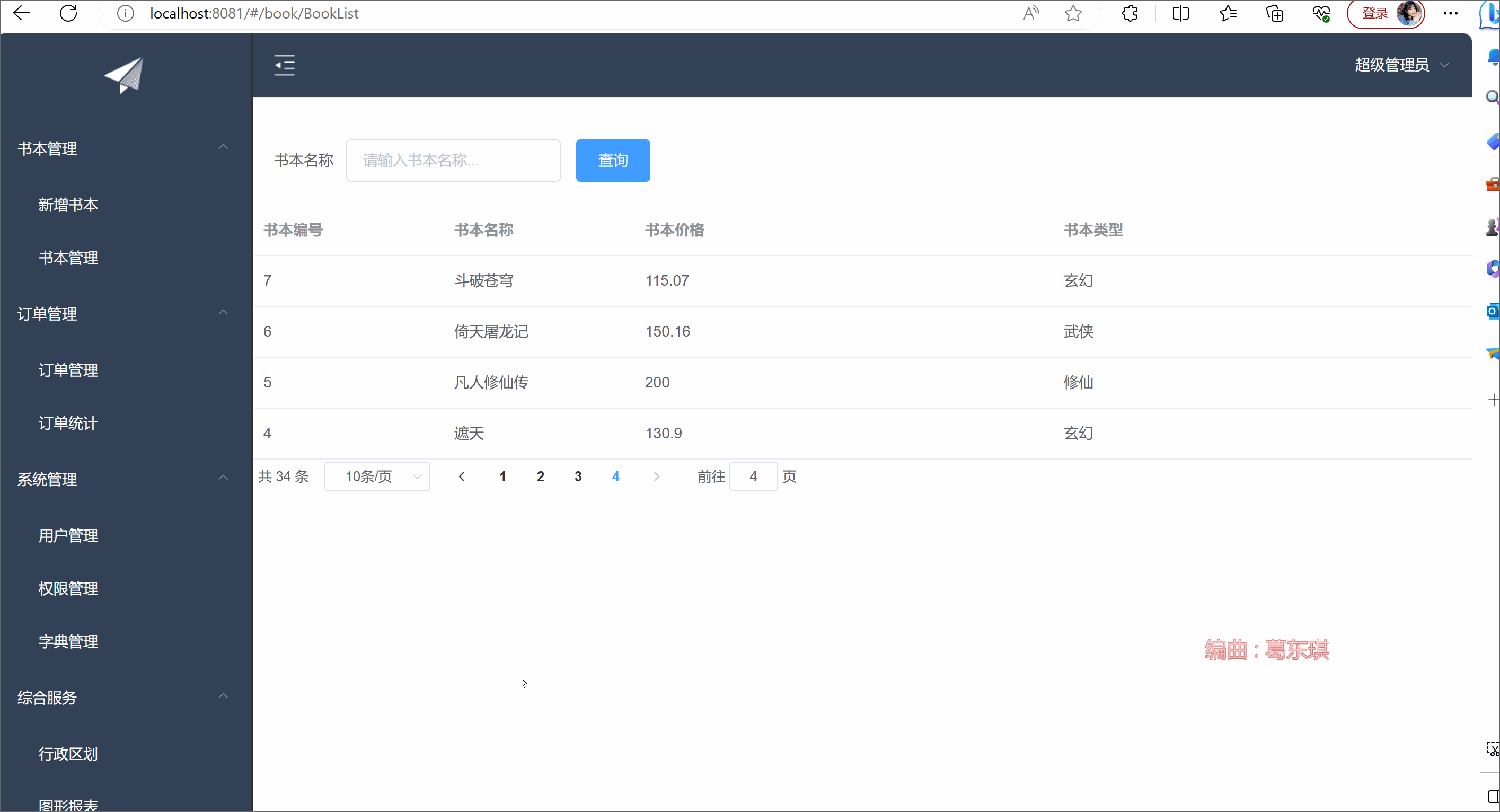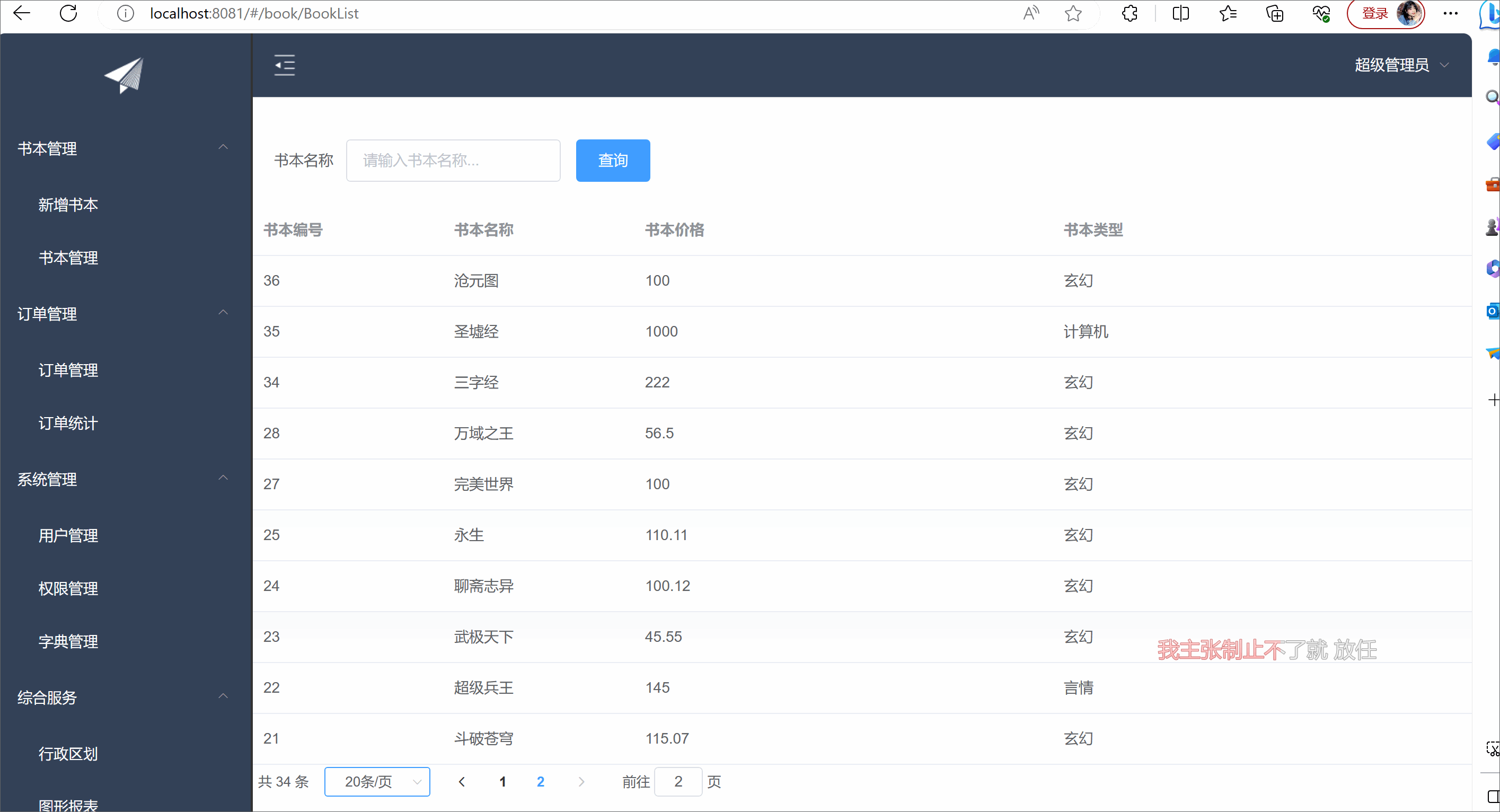
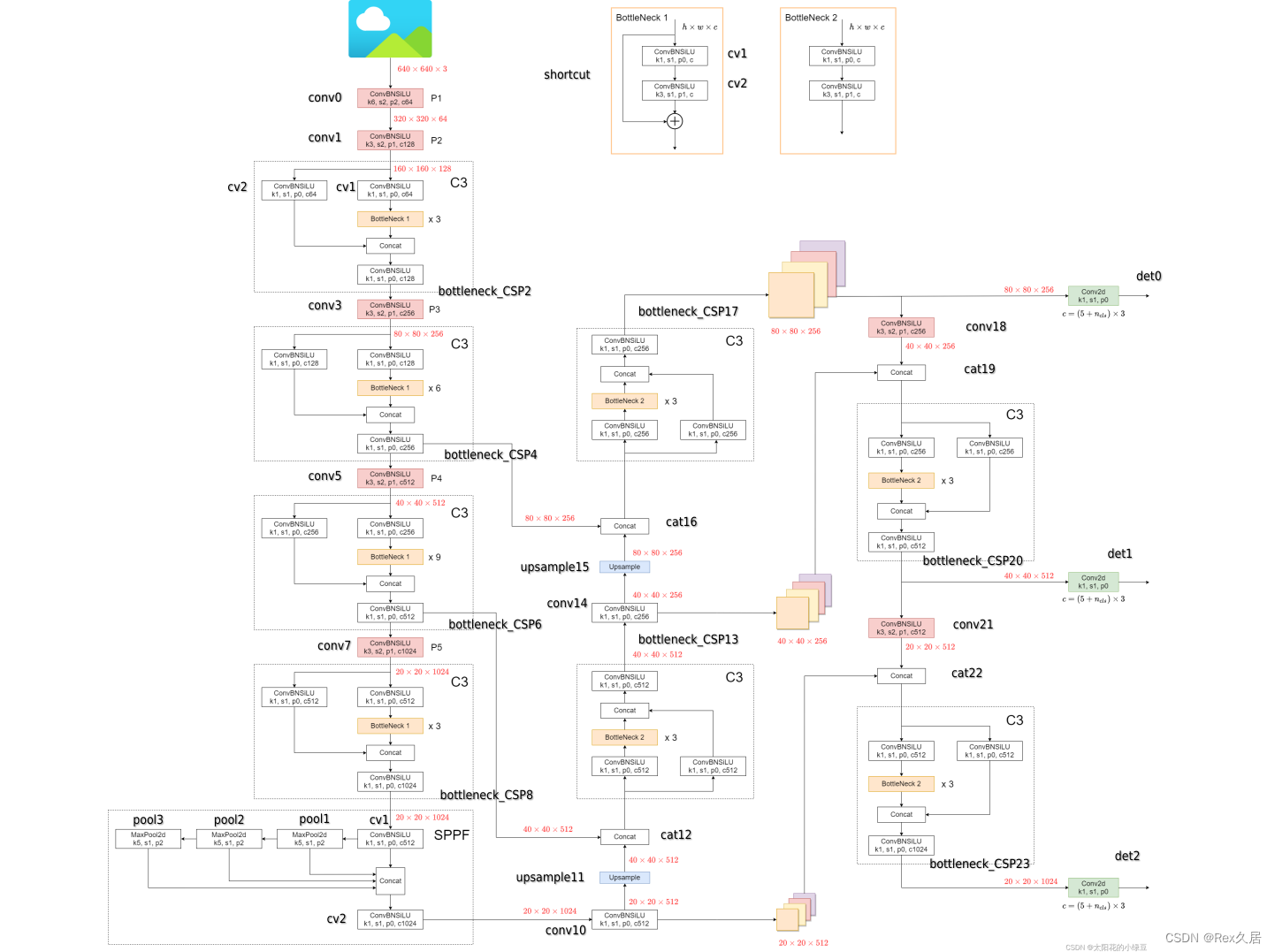
我们从下图中可以看出, 这些语言模型主要分为三类。一是“仅编码器(encoder-only)”组(上图中的粉色部 分),该类语言模型擅长文本理解, 因为它们允许信息在文本的两个方向上流动。二是“仅解码器(decoder-only)” 组(上图中的蓝色部分),该类语言模型擅长文本生成, 因为信息只能从文本的左侧向右侧流动, 以自回归方式 有效生成新词汇。三是“编码器-解码器(encoder-decoder)”组(上图中的绿色部分),该类语言模型对上述两种 模型进行了结合,用于完成需要理解输入并生成输出的任务,例如翻译。接下来主要介绍模型参数量大于100亿的具有代表性的大语言模型。
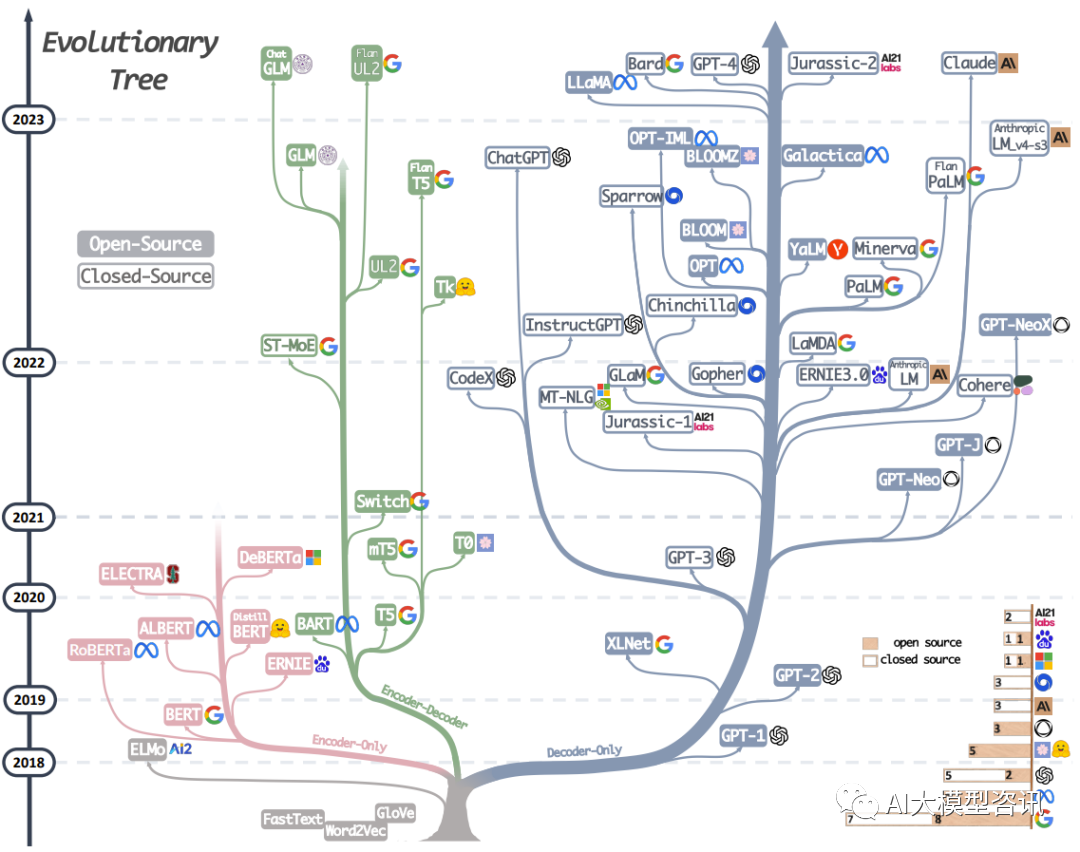
大型语言模型的进化树
编码器结构
顾名思义, 属于编码器结构(encoder-only) 的语言模型只参照了 transformer 结构里的 encoder 部分并在其 基础上进行修改。自 2018 年 BERT 公布后, 直到 2021 年, encoder-only 的语言模型一直是预训练语言模型的主 要组成部分。这类模型适合被用来执行辨别词汇类任务。
从上图中可以看出, 这一切都主要始于文本理解类模型。最初是使用 RNN 的 ELMo,之后是谷歌著名的 BERT 模型及其派生模型(如 RoBERTa) ,它们都基于 Transformer。这些模型通常具有几亿个参数(相当于约 1GB 的计算机内存),在大约 10GB 到 100GB 的文本上进行训练(通常为几十亿个单词), 并且可以在现代笔记 本电脑上以约 0.1 秒的速度处理一段文本。这些模型极大地提升了文本理解任务的性能, 如文本分类、实体检测 和问题回答等。这已然是 NLP (自然语言处理)领域的一场革命,不过才刚刚拉开序幕……
编码器-解码器结构
有同时采用 encoder 和 decoder 结构的大语言模型, 即直接调整 transformer 结构的大语言模型 GLM 和 UL2 等系列模型。
GLM
GLM,全名为 General Language Model,是由清华大学所开发的开源语言模型。其目的是为了在所有的 NLP 任务中都达到最佳表现。尽管其他模型之前有试图通过多任务学习以达到结合目标和不同的框架的目标, 但自回归与自编码有着天然的差异, 单独的融合无法继承它们的所有优点。而 GLM 的预训练目标为优化过的 自回归空白填空, 是在 T5 的空白填空的基础上进行改进:span shuffling 和 2D positional encoding。给定文本 x = [x1 , ..., xn ],选取多个文本 spans{s1 , ..., sm },每个 span 代表着连续的文本 token,并被一个 [MASK] token 取 代, 模型以自回归的方式去预测 span 中被 [MASK] 替代的 token。在预测时, 模型能够看见被破坏的文本和该 span 之前被预测过的 span。为了捕获 span 之间的独立性, span 的顺序会被打乱。正式来说, 让 Zm 为 [1, 2, ..., m] 的所有可能排列集合, szi 为 [sz 1 , ..., szi − 1 ] ,则预训练的目标公式定义为:
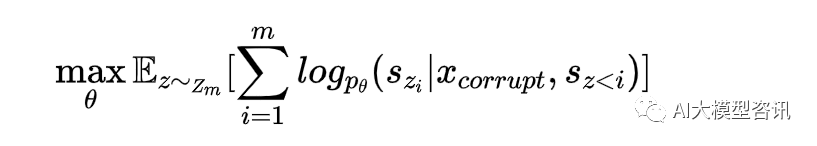
输入 x 被分为两部分: Part A 为被破坏文本, PART B 为masked spans 。PART A 的 token 彼此可见, 但无法 见到 PART B 的 token 。PART B 的 token 可以见到 PART A 的 token 和过去的 PART B 的 token,但无法见到未来 的 PART B 的 token。为了自回归生成, 每个 span 前后都添加了特殊 token [START] 和 [END]。这样模型可以自 动学习双向 encoder 和单向decoder。其中 span 的长度也是从 λ = 3 的泊松分布里选取。 Mask token 的比例也是 15%为最佳比例。
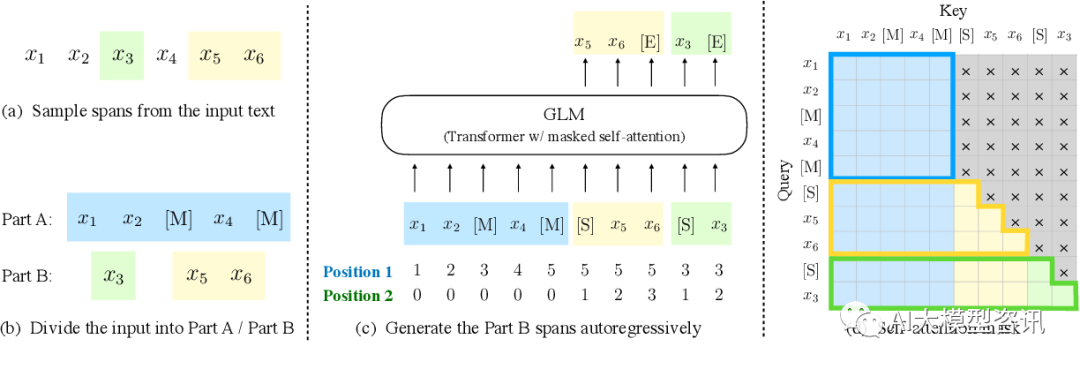
GLM 的预训练方式。 [M]=[MASK] ,[S]=[START] ,[E]=[END]
为了让预训练的模型能处理 NLU 以及文本生成任务, GLM 需要加入一个多目标预训练, 让 GLM 的次要目标为生成更长的文本并与空白填充优化。具体包含一下两个目标:
-
文档级别:选取一个长度为原文 50%到 100%的正态分布的 span。
-
句子级别:限制 masked span 必须为完整的句子。挑选 15%的 token 作为 span。
GLM 的模型结构也是经过修改的 Transformer 结构。其中修改的内容为:更换了 layer normalization 和 residual connection 的顺序,用单层线性层预测 output token,以及用 GeLUs函数去替换 ReLU 激活函数。
自回归空白填空任务的其中一个挑战是如何编译位置信息。Transformer 使用位置编码来标记各个 token 的 绝对和相对位置。因此, GLM 使用了优化方法, 2D positional encoding,即二维位置编码。每个 token 有两个位置 id。第一个位置 id 标志在被破坏文本中的位置。对于 masked span 来说, 这是对应 [MASK] token 的位置。第二 个位置 id 表示在对应的masked span 内部的位置。这两个位置 id 会通过 embedding 表格被投影为两个向量, 并 加入到输入 token 的embedding 中。这种方法可以使模型注意不到 masked span 的长度。
通常对于 NLU 的下游任务来说, 预训练模型产出的序列或 token 会被当作输入, 并用一个线性分类器来预 测 label,这与生成类的预训练任务有所不同, 导致预训练和微调之间的不协调。GLM 根据 PET,将 NLU 分 类任务转化为空白填充的生成任务。具体来说, 给予一个标注样本 (x, y)1,将输入文本 x 转化为包含一个mask token 的问题。比如一个情感分类任务可以被转化为“SENTENCE. It’s really [MASK]”。标签 y 也会被映射到问 题的答案中。例如标签“positive”和“negative”对应的就是“good”和“bad”。因此句子为正面或负面的概率 与预测空白内容为“good”或“bad”成比例。
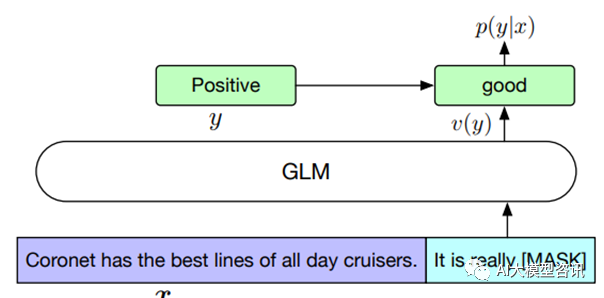
通过 GLM 将情感分类问题转化成空白填充
之后清华智谱 AI 开源放出了 GLM- 130B。该模型是一个底层架构为 GLM,参数量为 1300 亿的双语(中 英文) 双向语言模型。同样的 GLM- 130B 使用了自回归空白填充作为其主要预训练目标。另外, GLM- 130B 使 用了两种 mask token:[MASK] 对应短文本, [gMASK] 对应长文本。 GLM- 130B 也采用了旋转位置编码(RoPE), DeepNorm 层规范化和 GeGLU 技术。 GLM- 130B 对超过 4000 亿个 token 进行预训练。 95%的 token 是自监督的 空白填充训练, 另外 5%的 token 则是进行多任务指令训练,格式为基于指令的多任务多提示序列到序列的生成。 从结果上来看, GLM- 130B 能够支持中文和英文两种语言, 且在两种语言上都有高精度的表现, 拥有着快速推 理的能力, 结果可以轻松复现, 并且能够在多个平台, 包括 NVIDIA ,Hygon DCU ,Ascend 910 和 Sunway上进行训练和推理。
ChatGLM-6B
清华智谱 AI 最新的千亿中英语言模型 ChatGLM 依旧处于内测状态中。为了与社区推动大模型技术的发展, 清华智谱 AI 开源了 62 亿参数版本的 ChatGLM-6B 模型, 其可以在消费级的显卡上进行本地部署(INT4 量化级 别下最低只需 6GB 显存)。ChatGLM-6B 的优点包含了充分的中英双语预训练, 优化的模型架构和大小, 较低的 部署门槛, 更长的序列长度, 以及人类意图对齐训练。但其仍然有许多不足需要克服, 例如模型容量较小, 可能 会产生有害说明或有偏见的内容,较弱的多轮对话能力,英文能力不足,以及易被误导。
ChatGLM-6B 生成回复的两种接口 stream_chat() 和 chat(), 接口与各个类之间的调用关系如下图所示:
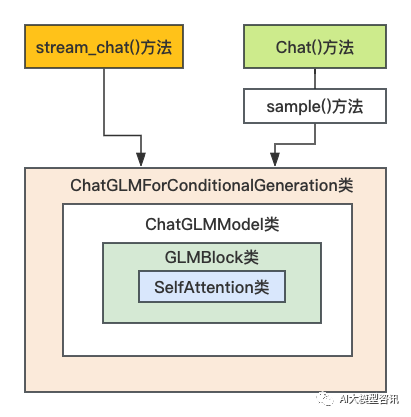
stream_chat() 和 chat() 接口与各个类之间的调用关系
-
stream_chat():流式输出回复,这种方式与 ChatGPT 的方式有些类似,可以看到生成回复的过程;
-
chat():一次输出全部回复;
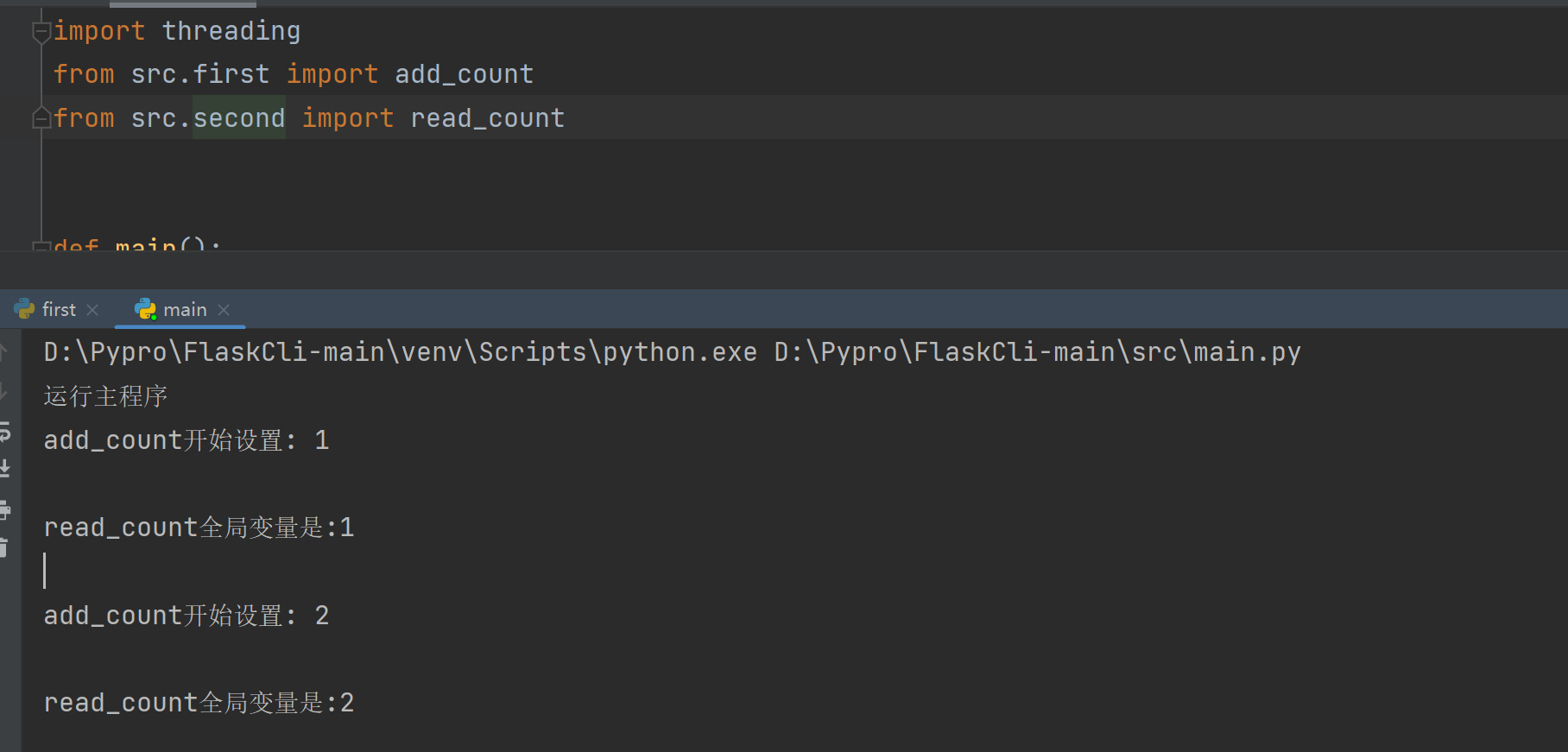
steam_chat 接口 () 中, ChatGLM-6B 完成一轮对话, 由输入的 query 经过流式接口, 得到 response 的框架如 下图所示。chat() 接口与stream_chat() 的区别很小,默认都是采用next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)来获取 next_tokens,即 is_sample_gen_model。两种接口的区别是:在生成回复时能够采用的模式不同。流式接 口除了支持 is_sample_gen_model,此外仅支持 is_greedy_gen_mode 贪心搜索模式。
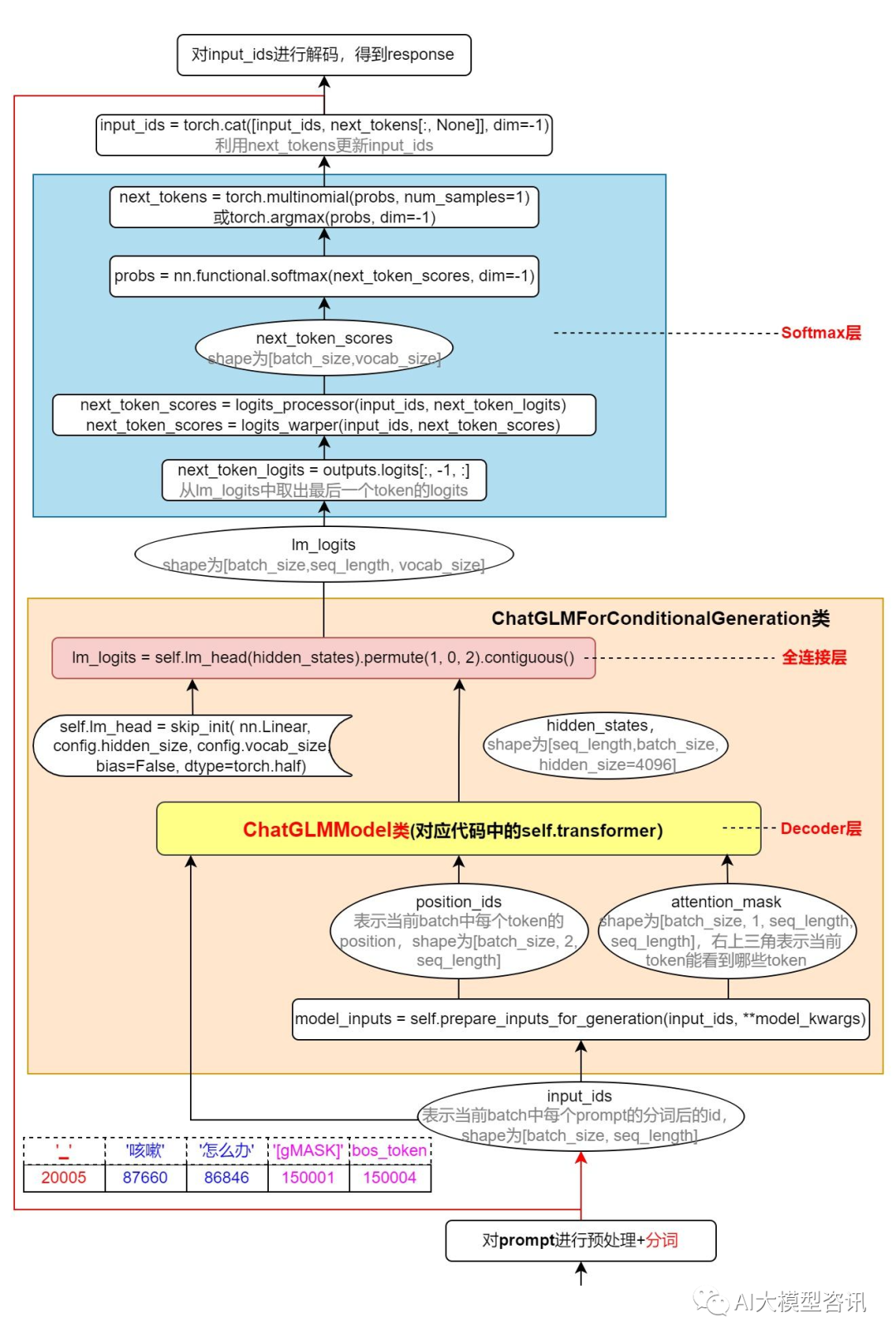
ChatGLM-6B 流式输出接口完成对话的框架
在 chat() 方法中, 将每一轮历史问答记录 old_query 、response 与当前输入的 query 拼接起来, 得到 prompt, 并肩 prompt 分词得到 token_id,构建 input_ids。代码如下:

上图中 bos_token (即’<sop>’) 是下一个句子开始的标记。得到的 input_ids 是一个 BatchEncoding 类对象, 根据上 图中的例子,它的值为’input_ids’: tensor([[ 20005, 87660, 86846, 150001, 150004]])。
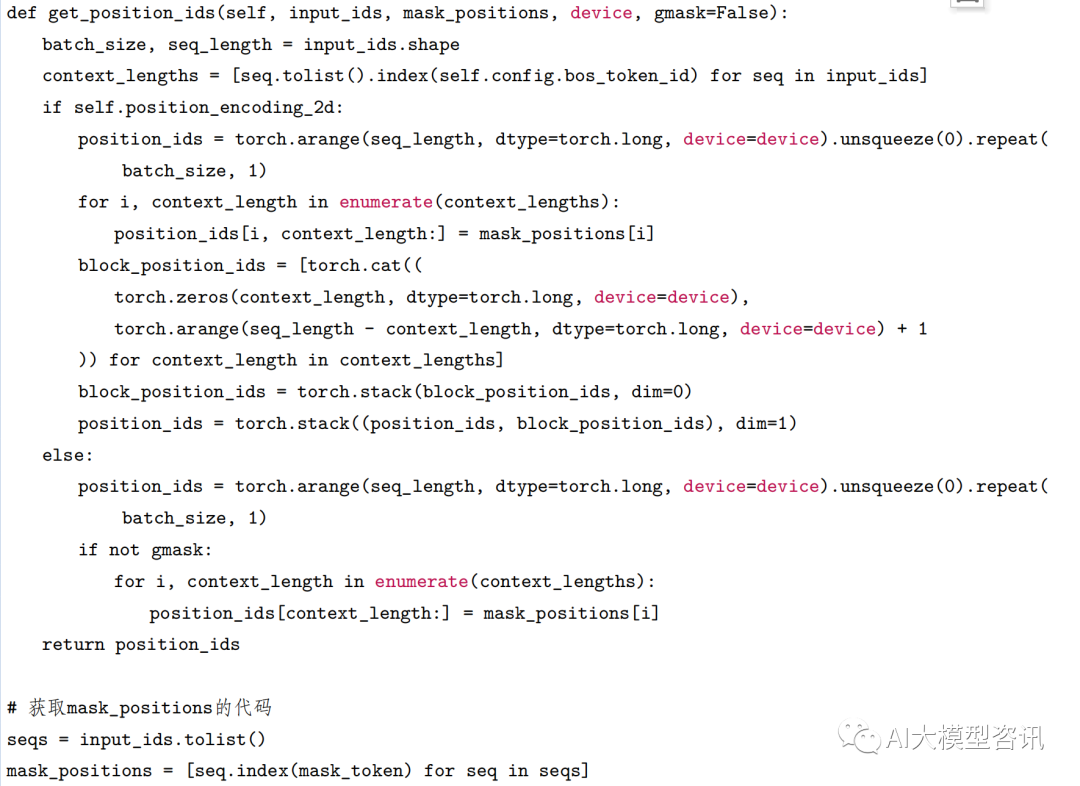
之后将 input_ids 输入 prepare_inputs_for_generation() 方法中得到 position_ids 和 attention_mask,如下图所示:

由 input_ids 得到 position_ids 和 attention_mask
position_ids 是为了后面计算 RoPE 旋转位置编码使用, 它是由两部分组成, 一部分是 token 在input_ids 中 的索引;另一部分是 token 所对应的 block (即 block_position_ids)。
-
attention_mask 是为了后面计算 attention_scores 使用, attention_mask 的 shape 为 [batch_size, 1, seq_length, seq_length],右上三角表示当前 token 能看到哪些 token。
在上图中, ” 咳嗽怎么办” 经过预处理和分词后, 得到 5 个 token (即 [”_”, ” 咳嗽”, ” 怎么办”, ”[gMASK]”, bos_token]),即变量 seq_length 的值为 5 。context_length 表示 bos_token 左边的 token 的个数, bos_token 的左边 共有 4 个 token (即 [”_”, ” 咳嗽”, ” 怎么办”, ”[gMASK]”]),即 context_length 为 4。构造 position_ids 的代码如下所示:
构造 attention_mask 的代码如下所示:

UL2
谷歌在 2022 年 5 月发布的一个大语言模型框架:即一个统一语言学习范式 Unifying Language Learning Paradigms (简称 UL2) 的框架, 这是一种“无关模型架构”“无关下游任务”的预训练策略, 即, 此策略无论什 么预训练模型架构, 什么任务都可以灵活适配, 不需要再根据任务去选择模型架构及预训练策略(自监督目标)。在近些年的论文中看到了一种未来趋势:模型大一统,目前的论文中的统一可以概括为以下两种角度:
-
结构统一:通过一些对 PLM 结构或策略的改动,统一不同 PLM 结构的优点,规避缺点问题,如 XLNet;
-
任务统一:改变 PLM 结构或任务表示 (multi-task learning),使一种模型具备处理多种不同任务的能力, 如T5;
-
模态统一:同时进行单模态和多模态的内容理解和生成任务, 如 Unimo (已有的预训练模型主要是单独地 针对单模态或者多模态任务, 但是无法很好地同时适应两类任务。同时, 对于多模态任务, 目前的预训练 模型只能在非常有限的多模态数据(图像-文本对)上进行训练。)
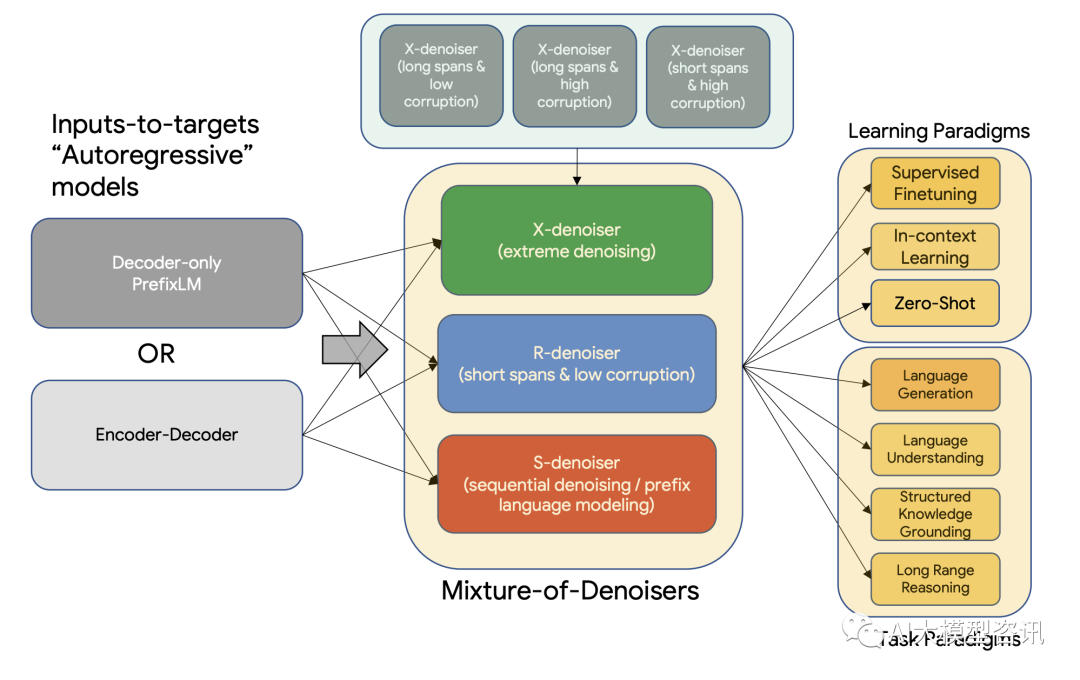
UL2 的预训练范式概览图
也许大家觉得 T5,XLNet 统一了 NLU 和 NLG,那为什么还需要 UL2 呢?
-
XLNet: 融合了 BERT 和 GPT 这两类预训练语言模型的优点, 并且解决了 BERT 中 pretrain 和 finetune 阶段 存在不一致的问题(pretrain 阶段添加 mask 标记, finetune 过程并没有 mask 标记)
-
T5:将 NLP 任务都转换成 Text-to-Text 形式, 然后使用同样的模型(encoder-decoder) ,同样的损失函数, 同样的训练过程, 同样的解码过程来完成所有 NLP 任务。UL2:构建一种独立于模型架构以及下游任务类 型的预训练策略(自监督目标), 可以灵活地适配不同类型的下游任务。UL2 工作的落点是要比现有的这些工作更高的,并且分离了模型架构和预训练目标。
UL2 模型参数达到 200 亿, 准确地说, 是 19.5B 的参数, 这个模型完全是在 C4 语料库上训练的(类似于 T5 模型)。UL2 模型是在新的 UL2 目标上训练的, 该目标在 denoisers 的混合物上训练(多样化的跨度腐败和前缀 语言建模任务) ,UL2 的架构如上图所示。
UL2 的核心是一个新提出的混合去噪器 Mixture-of-Denoisers (MoD),这是一个预训练目标,能够在任务中实 现强大的性能。MoD 是几个已确立的去噪目标与新目标的混合体;即考虑极端跨度长度和损坏率的 X-denoising (极端去噪),严格遵循序列顺序的 S-denoising (顺序去噪), 以及作为标准跨度损坏目标的 R-denoising (常规去 噪)。论文表明, MoD 在概念上很简单,但对于不同的任务集非常有效。

混合降噪中三种不同的降噪任务的设置
论文的方法利用了这样一种认识, 即大多数(如果不是全部) 经过充分研究的预训练目标在模型所处的环境 类型上有所不同。例如, span 损坏目标类似于调用前缀语言建模(PLM) 的多个区域, 其中前缀是未损坏tokens 的连续段, 目标可以完全访问所有 PLM 段的前缀。跨度接近全序列长度的设置大约是一个以长范围上下文为条 件的语言建模目标。因此, 能够设计一个预训练目标, 以平滑地插入这些不同的范例(范围损坏与语言建模与 前缀语言建模)。
很容易看出, 每个去噪器都有不同的困难。它们在外推(或内插) 的性质上也有所不同。例如, 通过双向上 下文(或未来)(即, 范围损坏) 来限定模型可以使任务更容易, 并且更接近于事实完成。同时, PrefixLM/LM 目标通常更“开放”。通过监测这些不同降噪目标的交叉熵损失,可以很容易地观察到这些行为。
根据 MoD 公式, 论文的模型不仅可以在预训练期间区分不同的去噪器, 而且可以在学习下游任务时自适应 切换模式。论文引入了模式切换这一新概念, 它将预训练任务与专用哨兵令牌(tokens) 相关联, 并允许通过离 散提示进行动态模式切换。经过预训练后,模型能够根据需要在 R 、S 和 X 去噪器之间切换模式。
Flan-UL2
随后谷歌在开源的 UL2 上用 Flan 进行了指令微调得到了 Flan-UL2 20B。在《Scaling Instruction-Finetuned language models》论文中 (有时也被称为 Flan2 论文) ,其关键思想是在一组数据集上训练一个大型语言模型。这些数据集被表述为指令, 能够在不同的任务中进行泛化。Flan 主要在学术任务上进行训练。Flan 数据集也已 在”The Flan Collection ” 中公开发布。论文中使用各种指令模板类型对数据源集合进行指令微调, 如下图所示。论文中将此微调过程称为 Flan,并在得到的微调模型前加上“Flan”。
研究者对带有 Flan 的 UL2 20B 模型做了两个主要更新。
- 最初的 UL2 模型只在接受域为 512 的情况下进行训练, 这使得它对于 N 大的 N-shot 提示不理想。这个 Flan-UL2 检查点使用的是 2048 的接受域,这使得它更适用于几张照片的语境学习。
- 最初的 UL2 模型也有模式切换标记, 这可以获得良好的性能。不过稍微有点麻烦, 因为这需要在推理或微 调时经常进行一些改变。在这次更新/改变中, 继续对 UL2 20B 进行额外的 10 万步训练(小批量), 以便 在应用 Flan 指令调整之前忘记” 模式标记”。这个 Flan-UL2 检查点不再需要模式令牌了。
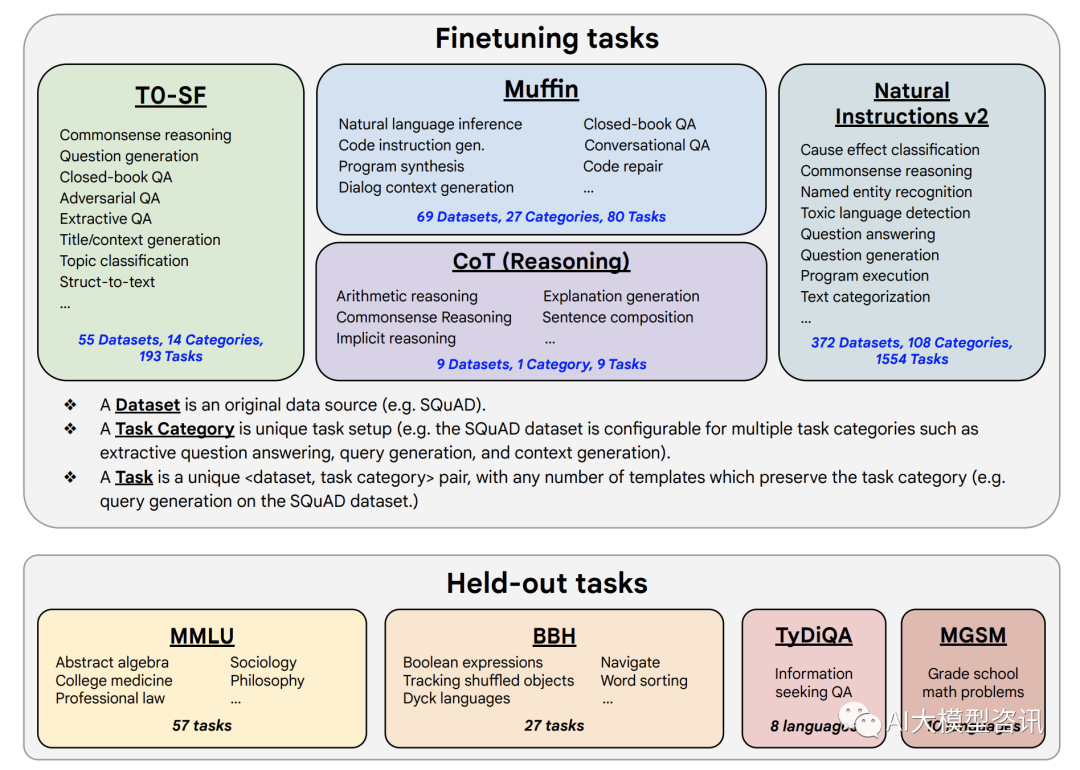
FLAN 微调数据包括 473 个数据集、 146 个任务类别和 1,836 个任务
ps:欢迎扫码关注公众号^_^.