1、环境变量
cat /etc/profile
#flink需要
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=/etc/hadoop/conf
2、Flink配置
2.1、flink-conf.yaml
jobmanager.rpc.address: node-146
jobmanager.rpc.port: 6123
# 设置jobmanager总内存
jobmanager.memory.process.size: 4096m
# 设置taskmanager的运行总内存
taskmanager.memory.process.size: 4096m
# 设置用户代码运行内存
taskmanager.memory.task.heap.size: 3072m
# 设置flink框架内存
taskmanager.memory.framework.heap.size: 128m
# 设置managed memory内存
taskmanager.memory.managed.size: 128m
# 设置堆外内存
taskmanager.memory.framework.off-heap.size: 128m
# 设置网络缓存
taskmanager.memory.network.max: 128m
# 设置JVM内存
taskmanager.memory.jvm-metaspace.size: 256m
taskmanager.memory.jvm-overhead.max: 256m
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
jobmanager.execution.failover-strategy: region
classloader.check-leaked-classloader: false
akka.ask.timeout: 50s
web.timeout: 50000
heartbeat.timeout: 180000
taskmanager.network.request-backoff.max: 240000
state.savepoints.dir: hdfs://hdfs-ha/flink/savepoints/
state.checkpoints.dir: hdfs://hdfs-ha/flink/checkpoints/
env.java.opts: -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -server -XX:+HeapDumpOnOutOfMemoryError
jvm相关参数
堆设置
-Xms :初始堆大小
-Xmx :最大堆大小
-XX:NewSize=n :设置年轻代大小
-XX:NewRatio=n: 设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n :年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n :设置持久代大小
收集器设置
-XX:+UseSerialGC :设置串行收集器
-XX:+UseParallelGC :设置并行收集器
-XX:+UseParalledlOldGC :设置并行年老代收集器
-XX:+UseConcMarkSweepGC :设置并发收集器
垃圾回收统计信息
-XX:+PrintHeapAtGC GC的heap详情
-XX:+PrintGCDetails GC详情
-XX:+PrintGCTimeStamps 打印GC时间信息
-XX:+PrintTenuringDistribution 打印年龄信息等
-XX:+HandlePromotionFailure 老年代分配担保(true or false)
并行收集器设置
-XX:ParallelGCThreads=n :设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n :设置并行收集最大暂停时间
-XX:GCTimeRatio=n :设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
并发收集器设置
-XX:+CMSIncrementalMode :设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n :设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数
2.2、masters
node-146:8081
2.2、workers
node-107
node-124
node-131
node-139
2.3、lib
flink-shaded-zookeeper-3.4.14.jar
commons-cli-1.5.0.jar
log4j-slf4j-impl-2.17.1.jar
log4j-core-2.17.1.jar
log4j-api-2.17.1.jar
log4j-1.2-api-2.17.1.jar
flink-json-1.13.6.jar
flink-csv-1.13.6.jar
flink-table_2.12-1.13.6.jar
flink-table-blink_2.12-1.13.6.jar
flink-dist_2.12-1.13.6.jar
flink-connector-jdbc_2.12-1.13.6.jar
flink-sql-connector-mysql-cdc-2.3.0.jar
flink-sql-connector-hive-3.1.2_2.12-1.13.6.jar
flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
flink-connector-starrocks-1.2.7_flink-1.13_2.12.jar
hudi-flink1.13-bundle_2.12-0.11.1.jar
mysql-connector-j-8.0.33.jar
flink-sql-connector-kafka_2.12-1.13.6.jar
flink-sql-connector-elasticsearch7_2.12-1.13.6.jar
dlink-client-base-0.7.4.jar
dlink-client-1.13-0.7.4.jar
dlink-common-0.7.4.jar
2.4、分发各节点
for host in {node-107,node-124,node-131,node-139};do scp /usr/bin/tarall root@$host:/data/app/;done
3、dinky配置
3.1、application.yml
url: jdbc:mysql://${MYSQL_ADDR:192.168.0.24:3306}/${MYSQL_DATABASE:dlink}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: ${MYSQL_USERNAME:dlink}
password: ${MYSQL_PASSWORD:Dlink*2023}
driver-class-name: com.mysql.cj.jdbc.Driver
3.2、plugins
/data/app/dlink-release-0.7.4/plugins
antlr-runtime-3.5.2.jar
flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
hive-exec-3.1.0.3.1.5.0-152.jar
javax.ws.rs-api-2.1.jar
jersey-common-2.27.jar
jersey-core-1.19.jar
libfb303-0.9.3.jar
mysql-connector-j-8.0.33.jar
3.3、plugins-flink
/data/app/dlink-release-0.7.4/plugins/flink1.13
flink-connector-jdbc_2.12-1.13.6.jar
flink-connector-starrocks-1.2.7_flink-1.13_2.12.jar
flink-csv-1.13.6.jar
flink-dist_2.12-1.13.6.jar
flink-doris-connector-1.13_2.12-1.0.3.jar
flink-json-1.13.6.jar
flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
flink-shaded-zookeeper-3.4.14.jar
flink-sql-connector-elasticsearch7_2.12-1.13.6.jar
flink-sql-connector-hive-3.1.2_2.12-1.13.6.jar
flink-sql-connector-kafka_2.12-1.13.6.jar
flink-sql-connector-mysql-cdc-2.3.0.jar
flink-table_2.12-1.13.6.jar
flink-table-blink_2.12-1.13.6.jar
hudi-flink1.13-bundle_2.12-0.11.1.jar
3.4、dinky启动
sh auto.sh start 1.13
3.5、上传jar包
3.5.1、创建HDFS目录
# 创建HDFS目录并上传dinky的jar包
sudo -u hdfs hdfs dfs -mkdir -p /dlink/{jar,flink-dist-13}
3.5.2、上传Flink的jar包
sudo -u hdfs hadoop fs -put /data/app/flink-1.13.6/lib /dlink/flink-dist-13
sudo -u hdfs hadoop fs -put /data/app/flink-1.13.6/plugins /dlink/flink-dist-13
3.5.3、上传dinky的jar包
sudo -u hdfs hdfs dfs -put /data/app/dlink-release-0.7.4/jar/dlink-app-1.13-0.7.4-jar-with-dependencies.jar /dlink/jar
sudo -u hdfs hadoop fs -put /data/app/dlink-release-0.7.4/lib/dlink-metadata-* /dlink/flink-dist-13/lib/
sudo -u hdfs hadoop fs -put druid-1.2.8.jar mysql-connector-j-8.0.33.jar /dlink/flink-dist-13/lib/
4、dinky操作
4.1、配置中心
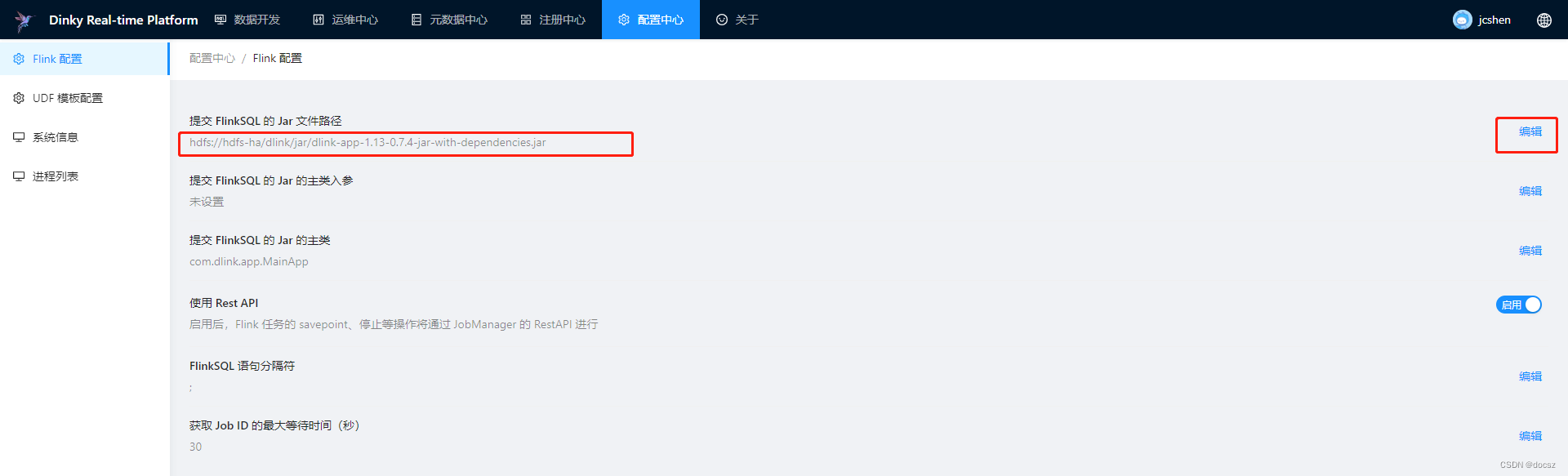
4.1.1、Flink配置
提交 FlinkSQL 的 Jar 文件路径
4.2、注册中心
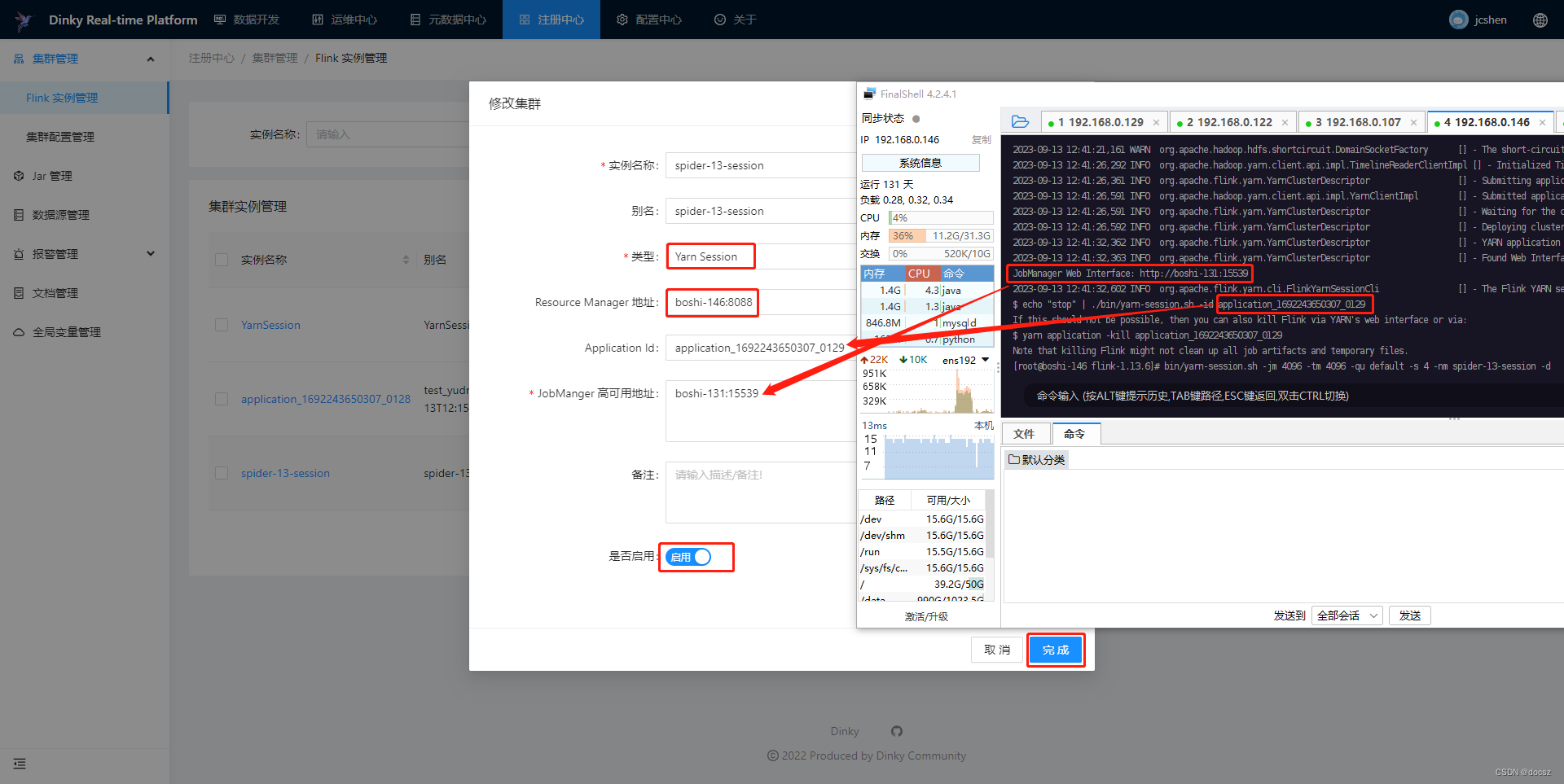
4.2.1、Flink实例管理
1、启动FlinkOnSession
bin/yarn-session.sh -jm 1024m -tm 1024m -nm flink-13-session -d
bin/yarn-session.sh -jm 4096 -tm 4096 -qu default -s 4 -nm spider-13-session -d
bin/yarn-session.sh \
-d -nm spider-13-session \
-p 2 \
-Dyarn.application.queue=default \
-Djobmanager.memory.process.size=4096mb \
-Dtaskmanager.memory.process.size=16384mb \
-Dtaskmanager.memory.framework.heap.size=128m \
-Dtaskmanager.memory.task.heap.size=15360m \
-Dtaskmanager.memory.managed.size=128m \
-Dtaskmanager.memory.framework.off-heap.size=128m \
-Dtaskmanager.memory.network.max=128m \
-Dtaskmanager.memory.jvm-metaspace.size=256m \
-Dtaskmanager.memory.jvm-overhead.max=256m \
-Dtaskmanager.numberOfTaskSlots=2
2、集群实例管理——新建
4、dinky开发
4.1、准备数据
4.1.1、MySQL中建表
-- MySQL
CREATE TABLE products (
id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description VARCHAR(512)
);
ALTER TABLE products AUTO_INCREMENT = 101;
INSERT INTO products
VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"spare tire","24 inch spare tire");
CREATE TABLE orders (
order_id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,
order_date DATETIME NOT NULL,
customer_name VARCHAR(255) NOT NULL,
price DECIMAL(10, 5) NOT NULL,
product_id INTEGER NOT NULL,
order_status BOOLEAN NOT NULL -- Whether order has been placed
) AUTO_INCREMENT = 10001;
INSERT INTO orders
VALUES (default, '2020-07-30 10:08:22', 'Jark', 50.50, 102, false),
(default, '2020-07-30 10:11:09', 'Sally', 15.00, 105, false),
(default, '2020-07-30 12:00:30', 'Edward', 25.25, 106, false);
update gmall.orders set price=55.5 where order_id=10001;
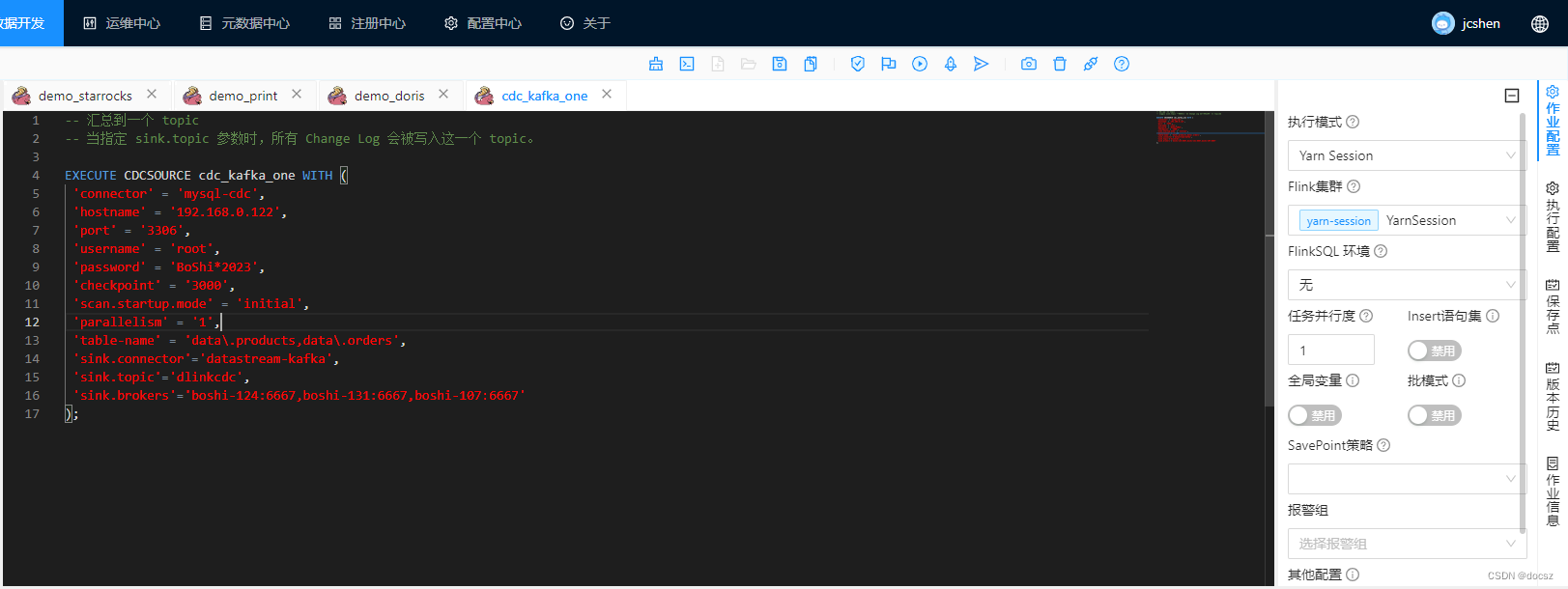
4.2、汇总到一个 topic
-- 汇总到一个 topic
-- 当指定 sink.topic 参数时,所有 Change Log 会被写入这一个 topic。
EXECUTE CDCSOURCE cdc_kafka_one WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.0.122',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '3000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'data\.products,data\.orders',
'sink.connector'='datastream-kafka',
'sink.topic'='dlinkcdc',
'sink.brokers'='node-124:6667,node-131:6667,node-107:6667'
);
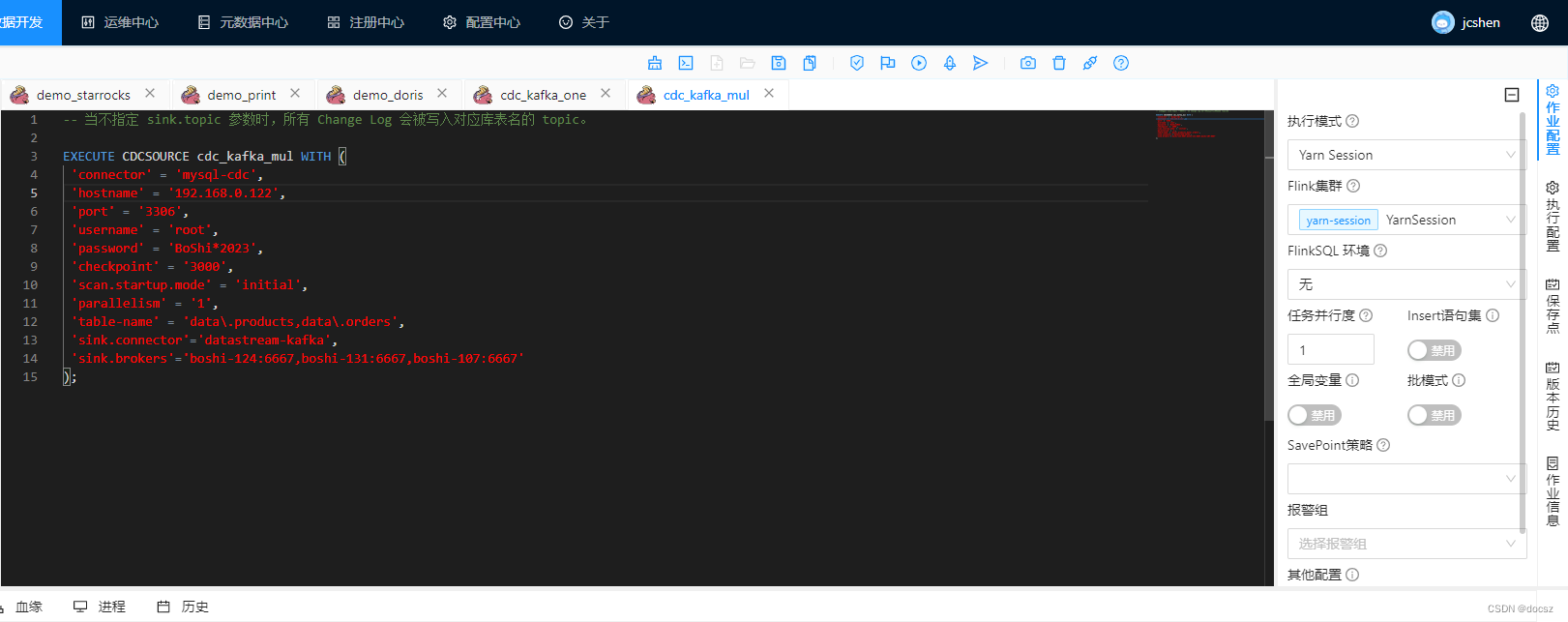
4.3、汇总到多个 topic
-- 当不指定 sink.topic 参数时,所有 Change Log 会被写入对应库表名的 topic。
EXECUTE CDCSOURCE cdc_kafka_mul WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.0.122',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'checkpoint' = '3000',
'scan.startup.mode' = 'initial',
'parallelism' = '1',
'table-name' = 'data\.products,data\.orders',
'sink.connector'='datastream-kafka',
'sink.brokers'='node-124:6667,node-131:6667,node-107:6667'
);
4.4、准备数据
4.4.1、MySQL中创建表
--MySQL中创建表s_user
CREATE TABLE `s_user` (
`id` INT(11) NOT NULL,
`name` VARCHAR(32) DEFAULT NULL,
`p_id` INT(2) DEFAULT NULL,
PRIMARY KEY (`id`)
);
--插入数据:
insert into s_user values(10086,'lm',61),(10010, 'ls',11), (10000,'ll',61);
4.4.2、StarRocks中创建表
CREATE TABLE IF NOT EXISTS tmp.`s_user` (
`id` int(10) NOT NULL COMMENT "",
`name` varchar(20) NOT NULL COMMENT "",
`p_id` INT(2) NULL COMMENT ""
)
PRIMARY KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
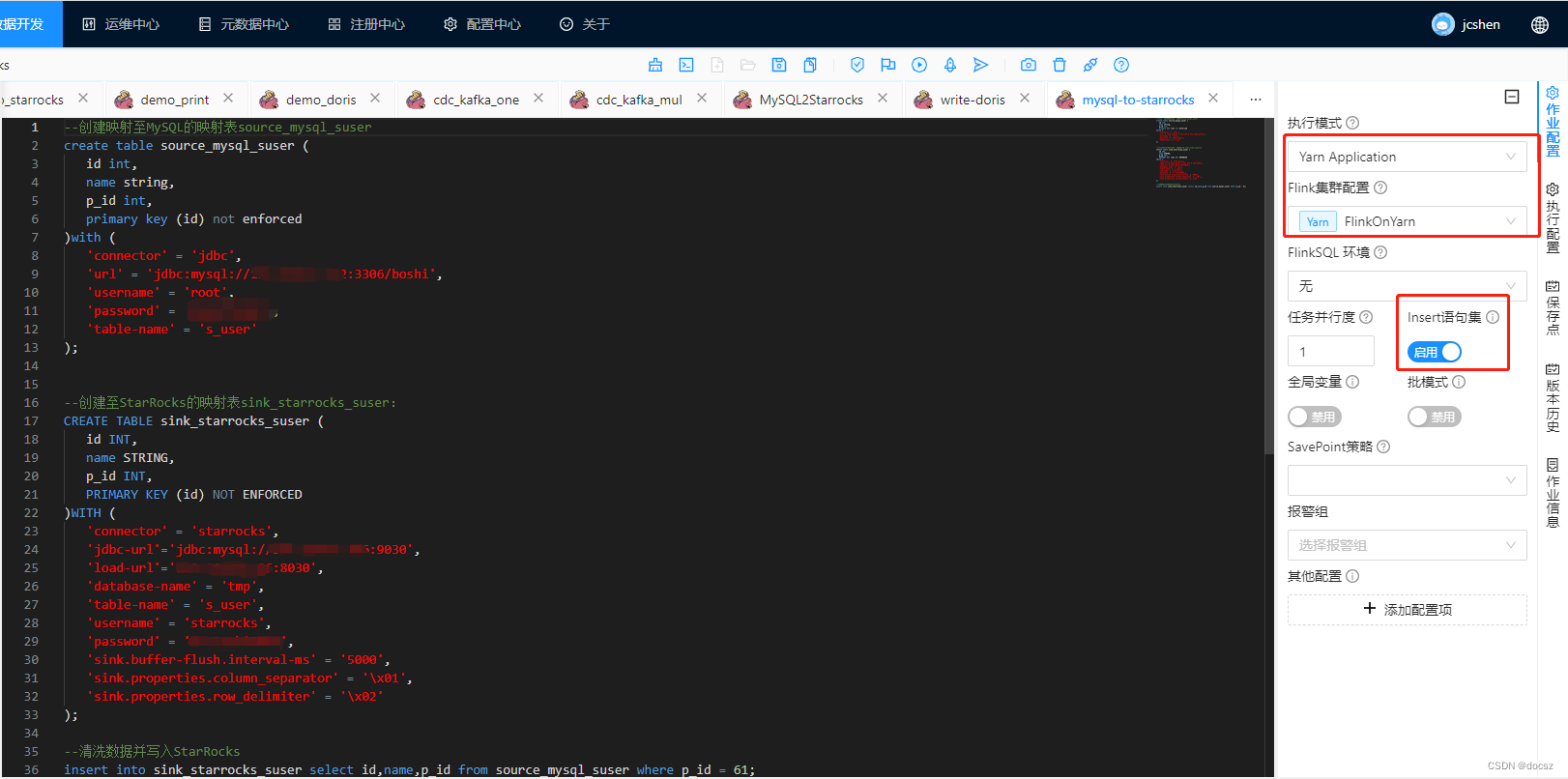
4.4.3、创建MySQL-To-StarRocks任务
--创建映射至MySQL的映射表source_mysql_suser
create table source_mysql_suser (
id int,
name string,
p_id int,
primary key (id) not enforced
)with (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.0.122:3306/data',
'username' = 'root',
'password' = '123456',
'table-name' = 's_user'
);
--创建至StarRocks的映射表sink_starrocks_suser:
CREATE TABLE sink_starrocks_suser (
id INT,
name STRING,
p_id INT,
PRIMARY KEY (id) NOT ENFORCED
)WITH (
'connector' = 'starrocks',
'jdbc-url'='jdbc:mysql://192.168.0.106:9030',
'load-url'='192.168.0.106:8030',
'database-name' = 'tmp',
'table-name' = 's_user',
'username' = 'starrocks',
'password' = 'StarRocks*2023',
'sink.buffer-flush.interval-ms' = '5000',
'sink.properties.column_separator' = '\x01',
'sink.properties.row_delimiter' = '\x02'
);
--清洗数据并写入StarRocks
insert into sink_starrocks_suser select id,name,p_id from source_mysql_suser where p_id = 61;