一、MySQL强制使用索引的两种方式
1、使用 FORCE INDEX 语句:
explain
select
*
from
tbl_test force index (index_item_code)
where
(item_code between 1 and 1000) and (random between 50000 and 1000000)
order by
random
limit 1;使用 FORCE INDEX(索引名称)走索引:

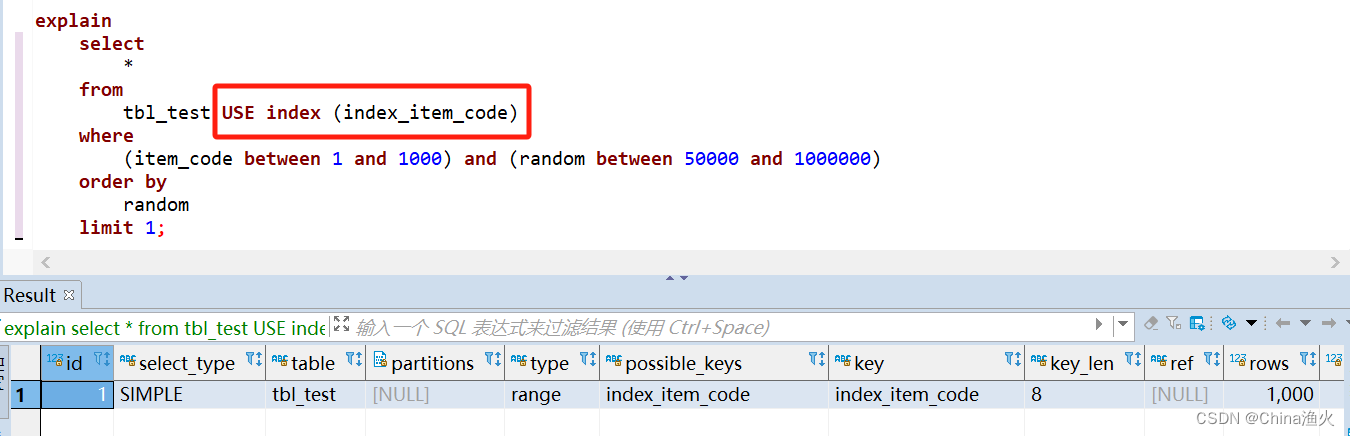
2、使用 USE INDEX 语句:
explain
select
*
from
tbl_test USE index (index_item_code)
where
(item_code between 1 and 1000) and (random between 50000 and 1000000)
order by
random
limit 1;使用 USE INDEX(索引名称)走索引:
FORCE INDEX 或 USE INDEX 的区别?
- FORCE INDEX :这个语句指示MySQL强制查询使用特定的索引。它会忽略优化器的选择,无论索引的选择性如何,都会使用指定的索引。这意味着即使使用了不太适合的索引,MySQL也会强制使用它。这可能会导致性能下降,因为不适合的索引可能会导致查询变慢。
- USE INDEX :这个语句也允许你指定要使用的索引,但它与"FORCE INDEX"不同的是,它只是暗示MySQL在可能的情况下使用指定的索引。如果MySQL认为其他索引更适合查询,它仍然可以选择其他索引。这样可以保留一定的灵活性,让MySQL根据实际情况选择最佳的索引。
总的来说,"FORCE INDEX"是强制使用指定索引,而"USE INDEX"是暗示使用指定索引,但MySQL仍然可以根据优化器的判断选择其他索引。实际使用时,应根据具体情况进行评估选择。
二、具体实现数据如下
1、创建一张数据表及索引:
CREATE TABLE `tbl_test` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(100) NOT NULL COMMENT '姓名',
`item_code` bigint NOT NULL COMMENT '子项编号',
`order_code` varchar(100) NOT NULL COMMENT '订单编号',
`id_card` varchar(30) NOT NULL COMMENT '身份证',
`goods_number` bigint NOT NULL COMMENT '商品数量',
`amount` decimal(6,2) NOT NULL COMMENT '金额',
`create_time` datetime NOT NULL COMMENT '创建时间',
`random` bigint NOT NULL COMMENT '数据数',
PRIMARY KEY (`id`),
KEY `index_item_code` (`item_code`),
KEY `index_id_card` (`id_card`),
KEY `index_random` (`random`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;注:表创建完成后,使用如下命令新增索引:
-- 查看tbl_test表中全部的索引信息
show index from tbl_test;
添加索引:
-- 在tbl_test表中,goods_number列上创建索引
CREATE INDEX index_goods_number ON tbl_test (goods_number);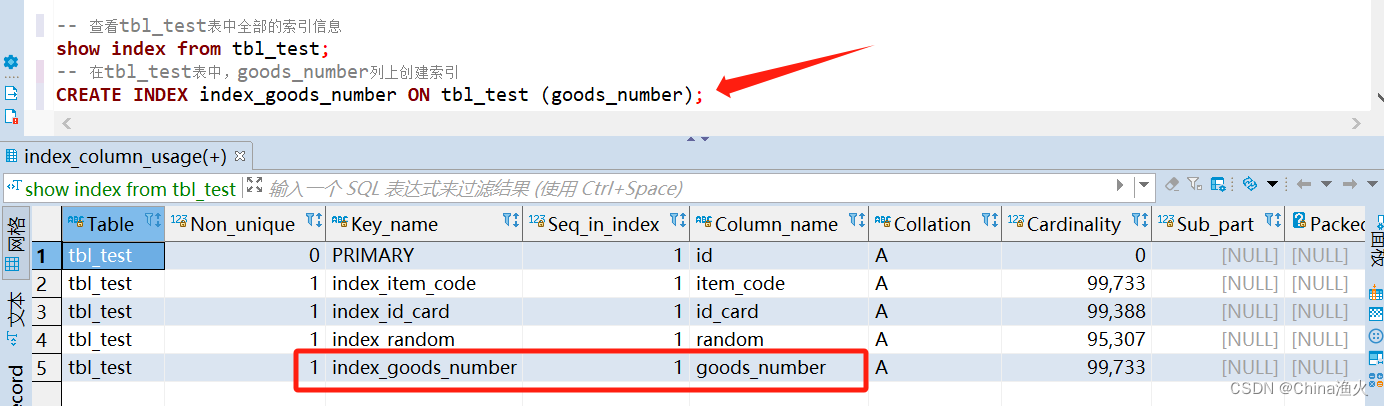
删除索引:
-- 在tbl_test表中,删除名称为 index_goods_number 的索引
ALTER TABLE tbl_test DROP INDEX index_goods_number;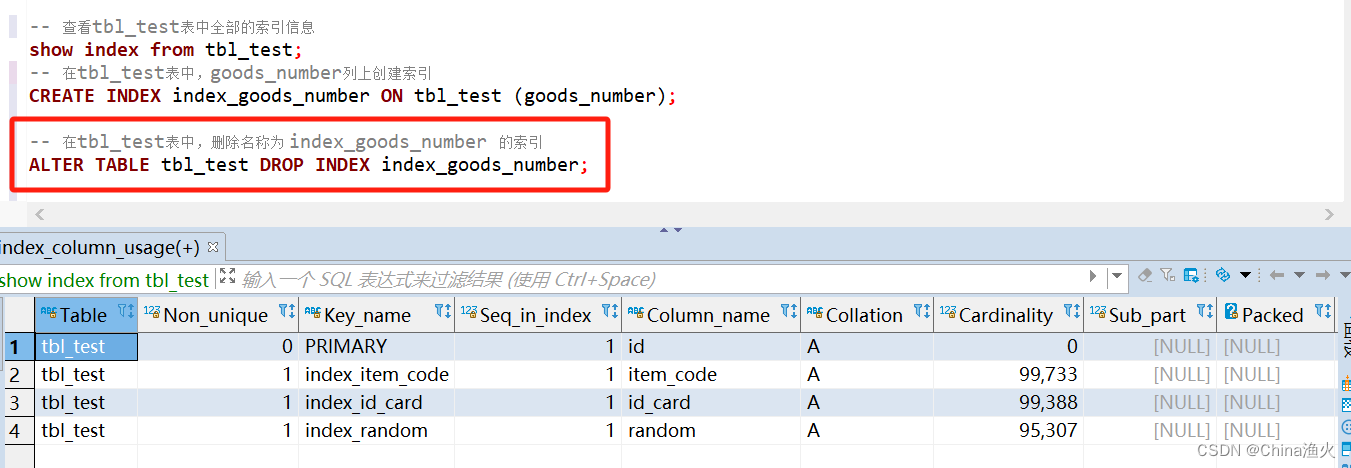
2、创建存储过程:
-- 创建存储过程
create procedure insert_data() begin declare i INT default 1;
while i <= 100000 DO
insert into test.tbl_test (
name,
item_code,
order_code,
id_card,
goods_number,
amount,
create_time,
random)
values (
CONCAT("test", i),
i,
CONCAT("order", i),
FLOOR(RAND() * 10000000000000),
i,
ROUND(RAND() * 100, 2),
NOW(),
FLOOR(RAND() * 1000000)
);
set
i = i + 1;
end while;
end
-- 结束执行完成后,可在此处查看:

然后,调用存储过程:
-- 调用储存过程
CALL insert_data();执行完后,数据信息如下:
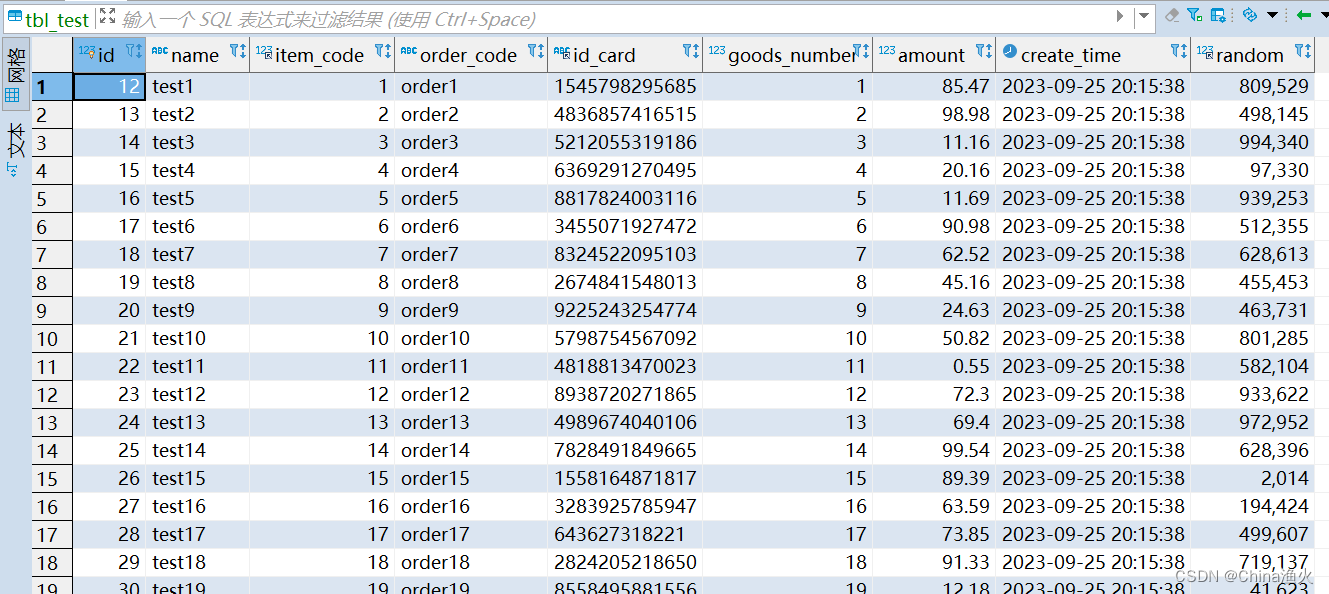
这里,可以通过存储过程的执行时间,看看慢SQL的定位方式
三、慢SQL的发现
1、执行show variables like '%general%'; 命令,查看日志功能是否开启
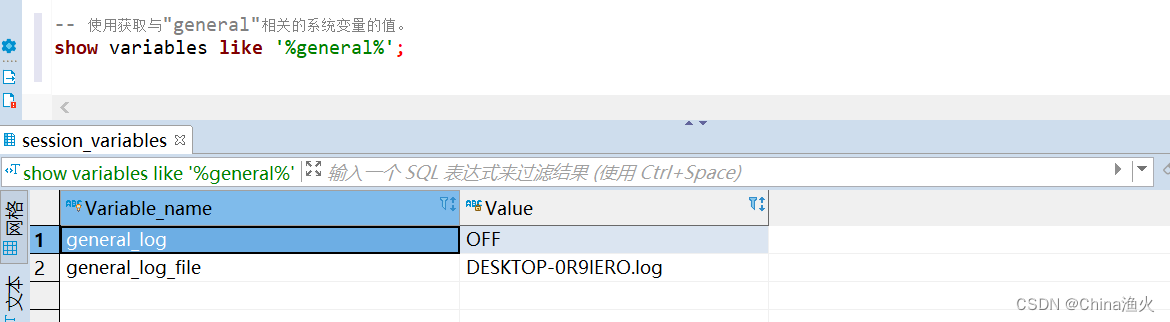
主要使用命令如下:
- set global general_log=on; 这个语句将全局变量 general_log 的值设置为 "on",表示启用了全局查询日志。启用后,MySQL服务器将记录所有的查询语句到查询日志文件中,包括 SELECT、INSERT、UPDATE、DELETE 等操作。
- set global general_log=off; 这个语句将全局变量 general_log 的值设置为 "off",表示禁用了全局查询日志。禁用后,MySQL服务器将停止记录查询日志,不再将查询语句写入查询日志文件。
通过修改全局变量 general_log 的值,可以控制全局查询日志的开启和关闭。
2、查看当前慢查询日志的开启情况
-- 查看当前慢查询日志的开启情况
show variables like '%quer%';执行信息如下:

设置信息解析:
- binlog_rows_query_log_events:该属性设置为"OFF",表示不记录二进制日志中的查询事件。
- ft_query_expansion_limit:该属性设置为20,表示在全文搜索查询中,扩展查询的限制为最多20个词。
- have_query_cache:该属性设置为"NO",表示当前MySQL服务器未启用查询缓存功能。
- log_queries_not_using_indexes:该属性设置为"OFF",表示不记录未使用索引的查询语句。
- log_throttle_queries_not_using_indexes:该属性设置为0,表示未使用索引的查询语句不会被限制。
- long_query_time:该属性设置为10.000000,表示执行时间超过10秒的查询将被认为是慢查询。
- query_alloc_block_size:该属性设置为8192,表示分配给查询内存块的大小为8KB。
- query_prealloc_size:该属性设置为8192,表示预分配给查询的内存大小为8KB。
- slow_query_log:该属性设置为"ON",表示慢查询日志功能已启用。
- slow_query_log_file:该属性设置为"DESKTOP-0R9IERO-slow.log",表示慢查询日志文件的名称为"DESKTOP-0R9IERO-slow.log"。
我们通过解析,还是默认设置慢日志阀值为10秒 (设置命令:set global long_query_time = 10)
通过slow_query_log_file的值,我们找到慢SQL文件DESKTOP-0R9IERO-slow.log,我这里在本地C盘:C:\ProgramData\MySQL\MySQL Server 8.0\Data 目录下:
慢SQL日志信息,查看存储过程的执行情况:

四、索引的优化
1、EXPLAIN 是一个在 MySQL 中用于查询执行计划的命令。它可以帮助您了解查询语句的执行方式、优化和性能。
EXPLAIN SELECT * FROM table_name WHERE column = 'value';以下是 EXPLAIN 命令的一些关键信息:
id:表示查询的标识符,如果查询包含子查询,每个子查询都有一个唯一的标识符。select_type:表示查询的类型,常见的类型包括 SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)等。table:表示查询涉及的表名。type:表示访问表的方式,常见的类型有 ALL(全表扫描)、INDEX(索引扫描)、RANGE(范围扫描)等。possible_keys:表示可能应用到查询中的索引。key:表示实际使用的索引。key_len:表示索引字段的长度。ref:表示与索引比较的列或常数。rows:表示估计需要扫描的行数。Extra:提供其他额外的信息,如是否使用了临时表、排序方式等。
通过分析 EXPLAIN 的输出,您可以获得以下信息:
- 查询是否有效利用了索引。
- 查询的执行顺序和方式。
- 哪些表被访问以及访问方式。
- 估计扫描的行数和数据访问的成本。
这些信息可以帮助您优化查询语句、调整索引和改进性能。
2、常见索引优化1:条件字段函数操作
当前表中已创建索引:

函数作用在条件列上,索引失效:

修改后:

2、常见索引优化2:隐式类型转换
当前id_card字段在数据库中是 varchar 类型,直接以数值类型查询,导致索引失效:

修改后,如下:
-- 使用如下写法:
explain select * from tbl_test where id_card != '2674841548013'
-- 或者:
-- CAST(267484154801 AS CHAR) 将数值类型的 2674841548013 转换为与 id_card 列的数据类型( varchar )匹配的字符类型。
-- 通过这样做,确保了 id_card 和值之间的比较使用匹配的数据类型,使索引能够有效使用。
explain select * from tbl_test where id_card = CAST(2674841548013 AS CHAR)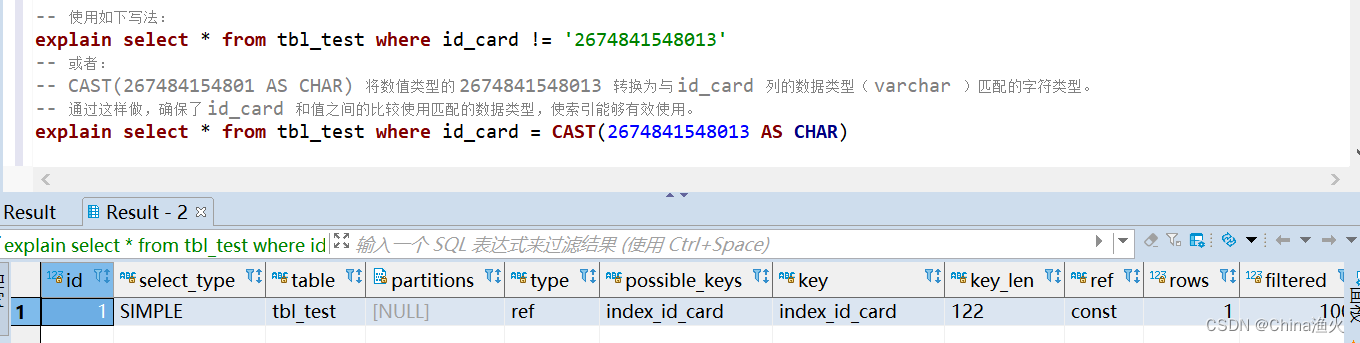
失效的原因跟案例一类型,数据类型隐式转换,对于优化器来说,这个语句相当于:
select * from tbl_test where CAST(id_card AS signed int) = 66778899;这样,在WHERE 子句中使用函数、表达式或算术,索引列错误使用,导致索引失效。
3、常见索引优化3:隐式字符编码转换
当使用不同的字符集进行隐式编码转换时,可能会导致索引失效。这是因为MySQL在进行索引查找时,会使用字符集的排序规则进行比较。如果字符集不同,排序规则也会不同,从而导致索引无法正确使用。
例如下面的例子,因字符集utf8mb4和utf8隐式字符编码转换而导致索引失效的情况:
假设有一个表my_table,其中有一个名为column的列,该列使用utf8mb4字符集,并且创建了索引。
CREATE TABLE my_table (
id INT PRIMARY KEY,
column VARCHAR(255) CHARACTER SET utf8mb4
) ENGINE=InnoDB;
CREATE INDEX idx_column ON my_table (column);
然后,我们向表中插入一些数据:
INSERT INTO my_table (id, column) VALUES (1, 'abc');
INSERT INTO my_table (id, column) VALUES (2, 'def');
现在,如果我们使用不同字符集的查询语句进行隐式编码转换,可能会导致索引失效。例如,以下查询使用了utf8字符集的字符串进行查询,这与表中的utf8mb4字符集不同:
SELECT * FROM my_table WHERE column = 'ghi';
在这个情况下,由于字符集不同,MySQL无法正确使用索引,从而进行全表扫描。这会导致查询性能下降,因为全表扫描比使用索引更耗时。要避免这种情况,可以确保查询语句中的字符集与表中的字符集一致,或者显式地进行字符编码转换。
五、MySQL索引失效原因的大致汇总
1、前导模糊查询不能利用索引,比如查询语句是LIKE '%XX'或LIKE '%XX%',而'A%'就可以正常使用索引。
2、如果MySQL估计使用全表扫描要比使用索引快,则不使用索引。
3、OR前后存在非索引的列,索引失效。如果想使用OR,又想让索引生效,只能将OR条件中的每个列都加上索引。
4、普通索引的不等于不会走索引,如果是主键,则还是会走索引;如果是主键或索引是整数类型,则还是会走索引。
5、is null可以使用索引,is not null无法使用索引。
6、在设计表时设置NOT NULL约束最好,比如将INT类型的默认值设为0,将字符串默认值设为''。
7、如果在查询条件中对索引列使用了任何操作(计算,函数),或者进行了类型转换,可能会导致索引失效。
8、如果在复合索引中,查询条件没有遵循最左匹配原则,那么索引可能也不会生效。
9、如果MySQL优化器认为全表扫描的速度快于使用索引,它可能会选择全表扫描而不使用索引。