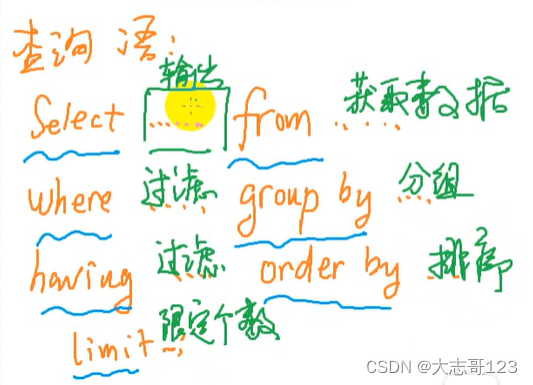
MySQL
- 一、MySQL整体架构
- 1.1 SQL接口
- 1.2 解析器 Parser
- 1.3 查询优化器 Optimizer
- 1.3.1 逻辑优化
- 1.3.2 物理优化
- 1.3.3 explain
- 1.4 缓存 Cache
- 1.5 存储引擎 Stroage Management
- 1.6 一条查询SQL的执行流程
- 二、缓存池(Buffer Pool)
- 2.1 Buffer Pool 预读机制
- 2.2 Buffer Pool free链
- 2.3 Buffer Pool 空间管理
- 2.4 Buffer Pool 脏页(Flush链)
- 三、Redo Log
- 3.1 Redo Log Buffer
- 3.2 Redo Log Buffer 刷盘机制
- 四、Undo Log
- 4.1 Undo Tablespace
- 4.2 相关参数
- 五、Change Buffer
- 5.1 Change Buffer缓存操作类型
- 5.2 Change Buffer被 Merge 情况
- 六、Doublewrite Buffer
- 6.1 相关参数
- 七、InnoDB 整体架构图
【MySQL系统架构设计】
【MySQL索引设计与选择】
【MySQL事务底层原理】
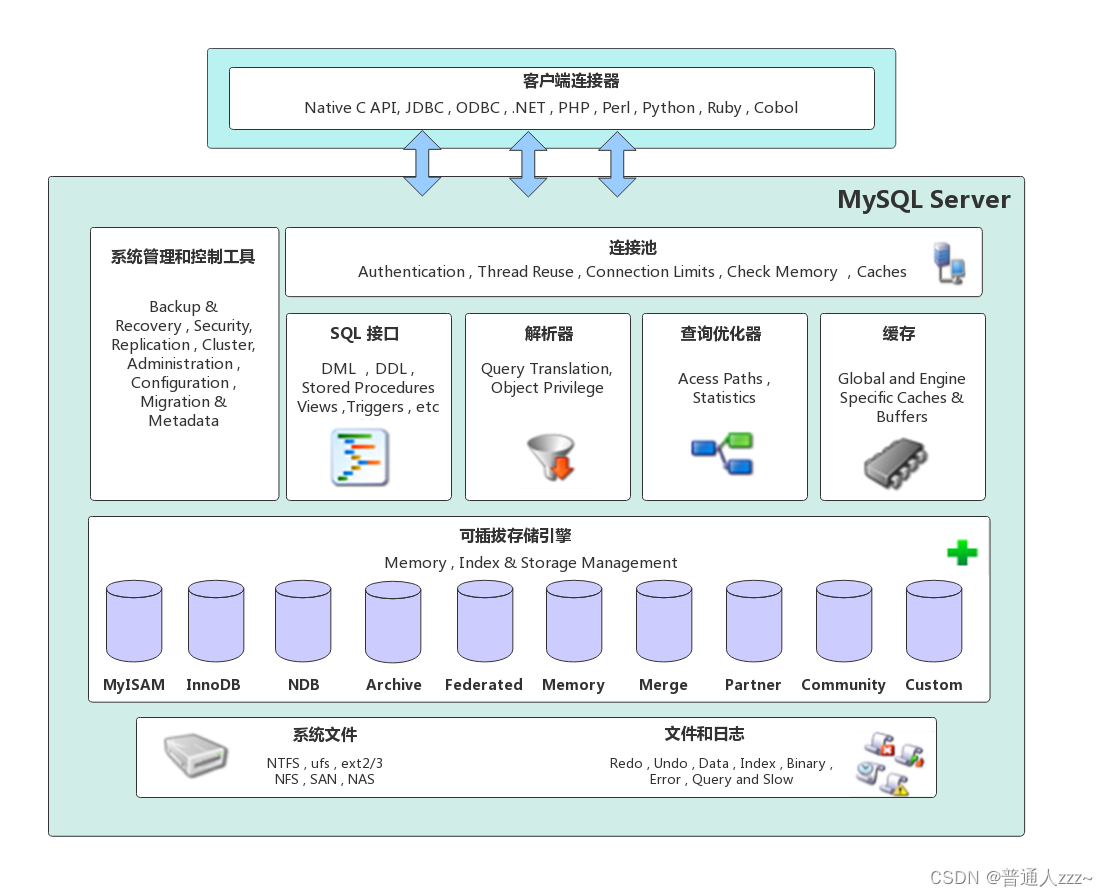
一、MySQL整体架构
在 MySQL 整体架构中,主要包括两个部分:
- MySQL Client:用于连接 MySQL 服务端,场景的有MySQL Shell、JDBC、.NET、Python等;
- MySQL Server:MySQL 服务端,主要分为几个核心模块;
2.1 基础模块:授权认证、线程模型(处理客户端连接)、连接池、缓存等;
2.2 SQL接口;
2.3 SQL解析器;
2.4 查询优化器;
2.5 缓存;
2.6 存储引擎:插件式设计,支持多种存储方式选择;
2.7 系统文件:存储 MySQL 数据、索引、日志文件等;
1.1 SQL接口
SQL接口主要用于接收客户端的DML、DDL、存储过程、视图、触发器等语句。
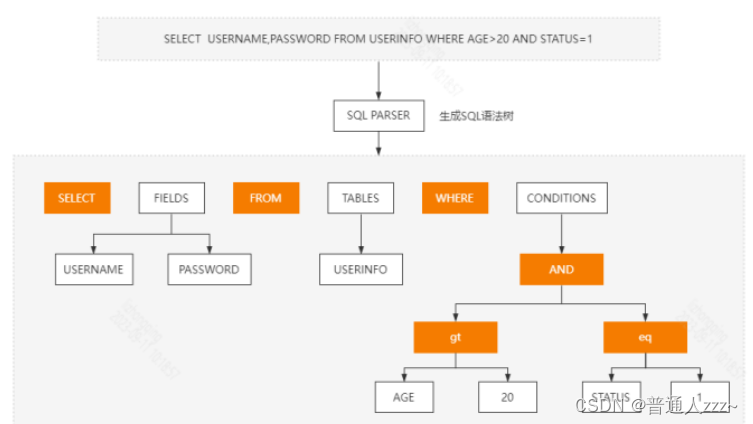
1.2 解析器 Parser
一个语法正确SQL语句,通过Parser解析器进行处理后,会被解析为一颗SQL语法树,如下:
1.3 查询优化器 Optimizer
一条SQL的执行方式(执行计划)有很多种方式,最终的执行计划是由 Optimizer 决定的,可以通过 explain 关键字来获取 SQL 语句的最终执行计划。
工作原理:根据 Parser 生成的解析树,产生多条执行计划(Execution Plan),最终选择一种最优的执行计划,进行 SQL 语句执行。在 MySQL Optimizer 中,默认采用的是基于开销的优化器,最优的执行计划,也就是开销最小的执行计划。
MySQL 的优化包括两种:逻辑优化、物理优化,运行流程如下:
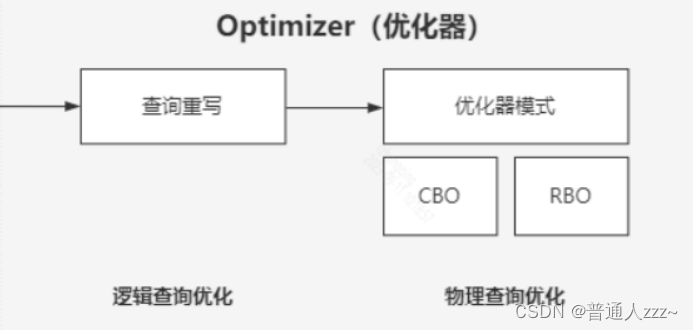
不管是逻辑优化还是物理优化,都是对 Parser 生成的语法树进行修改,最终生成最优的执行计划。
1.3.1 逻辑优化
主要是通过关系代数对 SQL 语句进行一些等价替换,使得 SQL 执行效率更优。
- 子查询优化:子查询合并
- 等价谓词重写:如将in转化为or规则,
status IN(1, 2) -----> status = 1 OR status = 2,LIKE优化,name LIKE 'mic%' ----> name >= 'mic' AND name < 'mid' - 条件简化:WHERE、HAVING、ON条件可能是由很多的表达式组成的,而这些表达式 在某些情况下存在一定的联系, 数据库可以利用等式和不等式的性质,把 WHERE、HAVING、ON条件简化。如:
- 把HAVING条件并入到WHERE条件, 方便统一、集中化解子条件,节 约多次化解的时间。
- 去除表达式中的冗余括号,减少语法分析时产生的AND和OR 树的层 次,比如
((a AND b) AND (c AND d))简化为a AND b AND c AND d。 - 常量传递,比如
col_1 = col_2 AND col_2 = 3可以简化成col_1 = 3 AND col_2 = 3。 - 表达式计算, 对可以求解的表达式进行计算,比如 WHERE col_1=1+2 转化为 WHERE col_1=3 。
1.3.2 物理优化
在生成逻辑查询计划后,查询优化器会进一步对查询树进行物理查询优化, 物理优化主要解决几个问题:
- 在单表扫描方式中,选择什么样的单表扫描方式是最优的
- 对于存在两个表连接时,那种连接方式最优
- 对于多个表连接,连接顺序有多种组合,那种连接顺序是最优的
物理查询优化一般分为两种
- 基于规则的优化(RBO,Rule-Based Optimizer),这种方式主要是基于 一些预置的规则对查询进行优化。
- 基于代价的优化(CBO,Cost-Based Optimizer,默认方式),这种方式会根据模型计算出各个可能的执行计划的代价,然后选择代价最少的那个。它会利用数据库里面的统计信息来做判断,因此是动态的。基于代价估算是基于CPU代价和IO代价这两个纬度来实现的。
总代价 = IO代价 + CPU代价
1.3.3 explain
在 MySQL 中,可以通过 explain 关键字查看 SQL 的执行计划,如下:

可以获取信息如上,每列意思为:
id:表的读取顺序。每一行记录代表一个表的执行计划,执行顺序如下:id不同,按照id方式递减方式执行;id相同,按照从上往下执行。select_type:查询类型。可选值如下:SIMPLE:建档的 SELECT 查询,不使用 union 及子查询;PARMARY:最外层的 SELECT 查询;UNION:UNION 中的第二个或随后的 SELECT 查询,不依赖于外部查询的结果集;DEPENDENT UNION:UNION 中的第二个或随后的 SELECT 查询,依赖于外部查询的结果集;SUBQUERY:子查询中的第一个 SELECT 查询,不依赖于外部查询的结果集;
table:表名,如果 SQL 语句中定义了别名,则展示表的别名。partitions:分区。表示当前查询匹配记录的分区,对于未分区的表,返回 NULL。type:表示当前 SELECT 查询数据表中的方式,以及查找数据行记录的大概范围。该列的取值优化程度如下:
最优 -> 最差
null -> system -> const -> eq_ref -> ref -> range -> index -> ALL
一般来说,需要保证查询语句type类型达到 range 基本,最好是 ref。
| type | 说明 | 优化建议 |
|---|---|---|
| NULL | MySQL优化器在优化阶段分解查询语句,在优化过程中就已经可以得到结果,那么在执行阶段就不用再访问表或索引。 | |
| system | system是const的特例,表中数据只有一条匹配时为system。 | |
| const | const出现在用 primary key(主键) 或 unique key(唯一键) 的所有列与常数比较时,优化器对查询进行优化并将其部分查询转化成一个常量。最多有一个匹配行,读取1次,速度非常快。 | |
| eq_ref | primary key(主键)或 unique key(唯一键) 索引的所有构成部分被join使用 ,只会返回一条符合条件的数据行。 | |
| ref | 与eq_ref相比,ref类型不是使用primary key(主键) 或 unique key(唯一键)等唯一索引,而是使用普通索引或者联合唯一性索引的部分前缀,索引和某个值相比较,可能会找到符合条件的多个数据行。 | |
| range | 使用一个索引来查询给定范围的行,如通过in()、between、>、>=、< 等操作符进行查询。 | 建议优化 |
| index | 扫描全表索引。index是从索引中读取,所有字段都有索引。 | 需优化 |
| ALL | 全表扫描。需从磁盘中读取数据。 | 需优化 |
possible_keys:表示当前 SELECT 可能使用到那些索引。但有些时候也会出现出现 possible_keys 列有结果,而 key=NULL ,这是因为此时表中数据不多,优化器认为查询索引对查询帮助不大,所以没有走索引查询而是进行了全表扫描。key:表名当前 SELECT 实际采用那个索引。返回 NULL 表示未使用索引。key_len:表示在索引里使用的字节数。通过 key_len 值,可以估算出具体使用了联合索引中的几列。ref:表示在 key 列记录的索引中,SELECT 查询所用到的列或常量。可选值:const-常量、字段名,如user.name。rows:表示当前 SELECT 大概需要读取并检测的数据行数。filtered:Extra:顾名思义,这一列表明的是额外信息。这一列的取值对 SQL 优化非常有参考意义。可选值有:NULL:被查询的列没有被索引覆盖,但 WHERE 条件是索引的前导列,需要通过 “回表” 动作来获取所有列数据;Using index:被查询的列都是索引列(称为覆盖索引);Using where:被查询的列没有被索引覆盖,WHERE 条件也并非索引的前导列;Using where; Using index:被查询的列被索引覆盖,并且 WHERE 条件是索引列之一,但不是所有的前导列,也就是没有办法直接通过索引来查询到符合条件的数据;Using index condition:被查询的列不完全被索引覆盖,WHERE 条件中是一个前导列的范围。User temporary:表明需要通过创建临时表来处理查询结果。出现这种情况一般需要优化,创建临时表情况有distinct、group by、order by、子查询等;Using filesort:使用 order by 时,MySQL 会对结果使用一个外部索引排序,而不是按索引次序从表中读取行。此时mysql会根据连接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下要考虑使用索引来优化的。
1.4 缓存 Cache
查询缓存,在 MySQL 8.0 已经移除该模块。
1.5 存储引擎 Stroage Management
表示数据如何存储、如何提取、如何更新等具体的实现,不同存储引擎的底层实现方式不同,因此会呈现不同存储引擎独特的功能和特点。
在 MySQL 中支持多种存储引擎,最常用的引擎是 MyISAM、InnoDB、Memory,可以根据实际的业务场景来选择使用不同的存储引擎。
- MyISAM:写多读少,不支持事务,数据和索引分开存储,索引会存储一份数据。
- InnoDB:支持事务,数据和索引存储在一个文件,聚簇索引(主键索引,如果没有主键索引,MySQL会默认生成一个
_rowid为主键索引,如果存在,_rowid = id)会存储数据,非聚簇索引(除主键索引外,其他索引),不存储数据,通过主键索引进行 “回表” 获取数据。 - Memory:基于内存存储。
MySQL 5.5 版本前默认存储引擎是 MyISAM,在5.5 版本后默认的存储引擎是 InnoDB,因为它在大多数情况下都提供更好的性能和可靠性。根据不同业务场景,我们可以选择不同存储引擎。
MyISAM:
- 读多写少:MyISAM 在读取性能上有一定的优势,适用于大多数读多写少的应用,比如博客、新闻网站等;
- 全文搜索:MyISAM 支持全文搜索功能,适合需要进行全文搜索的应用,如搜索引擎;
- 空间数据存储:MyISAM 提供了空间索引的支持,可以存储地理信息数据或空间数据;
InnoDB:
- 事务支持:InnoDB 支持事务ACID特性。事务是数据库保持数据完整性和一致性的关键;
- 高并发写入:InnoDB 支持行级锁,对于高并发写入的应用,InnoDB 的性能更好;
- 数据完整性:InnoDB 支持外键约束、主键约束等数据完整性控制功能,对于要求数据一致性和完整性的应用更合适;
- 崩溃恢复:InnoDB 支持崩溃恢复功能(redo log、undo log、doublewrite log files),可以在数据库崩溃后进行恢复,确保数据不丢失;
1.6 一条查询SQL的执行流程
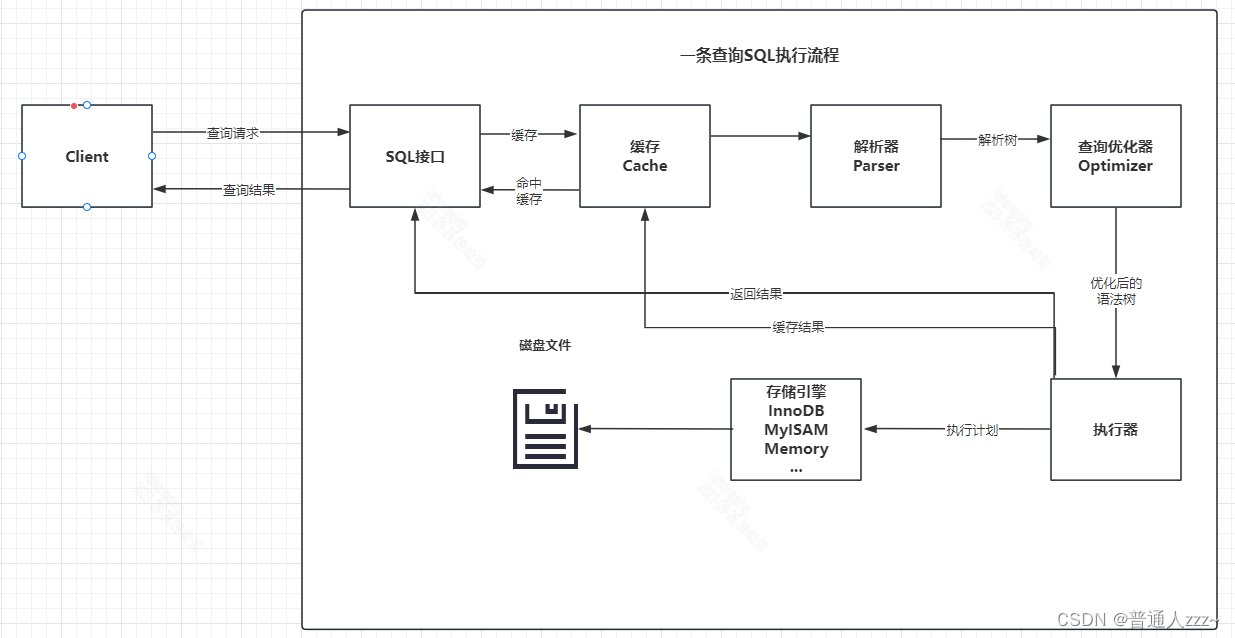
二、缓存池(Buffer Pool)
MySQL 除了使用 Memory 存储引擎以外,其他存储引擎最终都需要将数据存储到磁盘上。先假如我们需要对某个数据进行操作,步骤如下:
- 需先找到当前数据在磁盘中存储的位置;
- 将磁盘中的数据加载到内存中;
- 对数据进行修改;
- 将修改后的数据写入磁盘;
将数据写入磁盘的效率是非常低的,如果每次数据操作都重复上面的步骤,MySQL 性能是会存在非常大的性能瓶颈,那 MySQL 是怎么解决这个问题的呢?
Buffer Pool 概念由此产生。
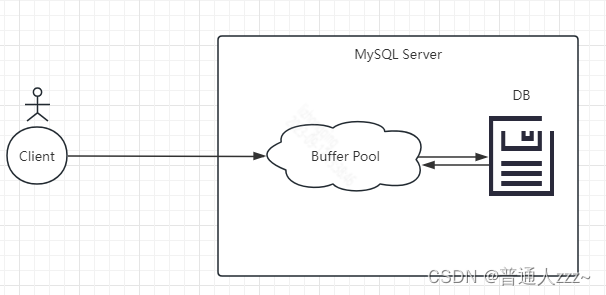
用户操作数据,不直接和磁盘交互,而是和内存中的一块区域进行交互,该区域就叫做 Buffer Pool。具体操作步骤如下:
- 读取数据时,先判断数据是否存在 Buffer Pool,如果存在直接获取并返回,否则将磁盘数据读取到 Buffer Pool,然后返回;
- 修改数据时,先将数据读取到 Buffer Pool 中,然后修改 Buffer Pool 中对应的数据,并放入一块特定区域中,由 MySQl 后台线程将这特定区域的数据写入磁盘,这一块特定的区域叫 脏链。
不管是查询、修改数据,都需要先将数据从磁盘读取到 Buffer Pool 中,那对于数据的一次读取操作,会将磁盘中的多少数据加载到 Buffer Pool 中呢?加入当前数据只占了15个字节,那一次读取操作,只会加载这15个字节数据吗?
很显然不是,磁盘I/O相对内存来说是非常慢的,特别是磁盘的随机读操作,产生的I/O次数更多。
所以这里也用到了 预读取 的概念,也就是说,当磁盘上的某块数据被读取时,根据局部性原理,很有可能它附近位置的数据马上也会被用到。所以,MySQL 在进行一次性读取时,会尽量多读取一些数据保存到 Buffer Pool 中,通过空间换时间的设计思想, 提升数据的IO效率。
InnoDB 为 MySQL 最常使用的存储引擎,后续都是围绕 InnoDB Stroage Management 进行分析。
2.1 Buffer Pool 预读机制
MySQL 设定了一个存储引擎从磁盘读取数据到内存的最小单位叫 页缓存(Page Cache)。InnoDB 中,Page Cache 默认大小为 16kb,既一次数据读取操作,会从磁盘加载 16kb 大小的数据到 Buffer Pool 中,可通过参数 innodb_page_size 将页的大小设置为4K、8K、16K进行调整。
每个Page Cache 会对应一个描述数据,这个描述数据本身也是一块数据,它包含 Page 所属的表空间、数据页编号、数据页在Buffer Pool中的地址等信息。在 Buffer Pool 中,每个 Page Cache 的描述数据放在最前面,Page Cache放在后面。结构如下:
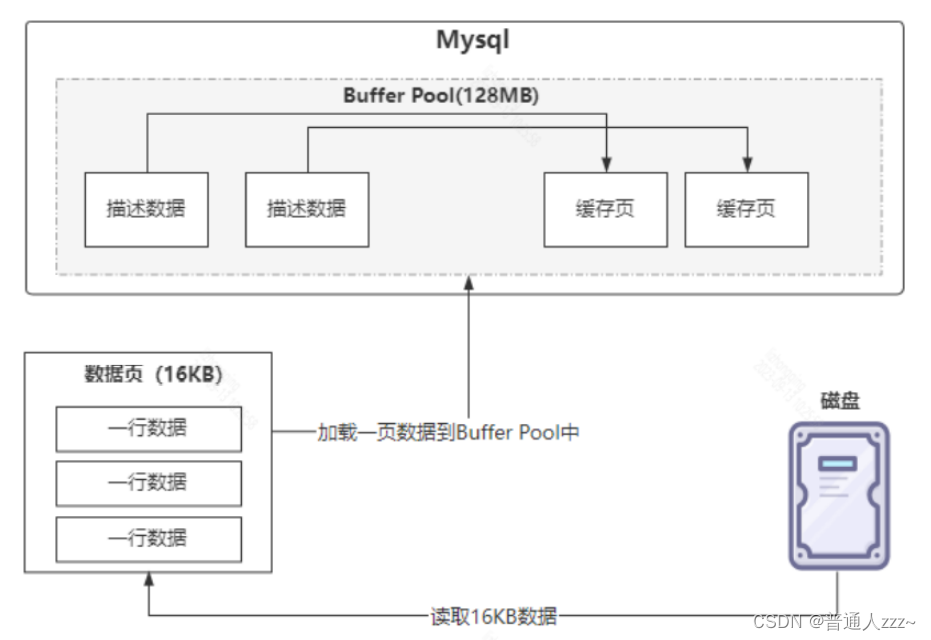
操作系统也存在 页缓存 的概念,默认大小为 4kb。
在 MySQL InnoDB 中,通过将数据存储分为不同级别,如下:
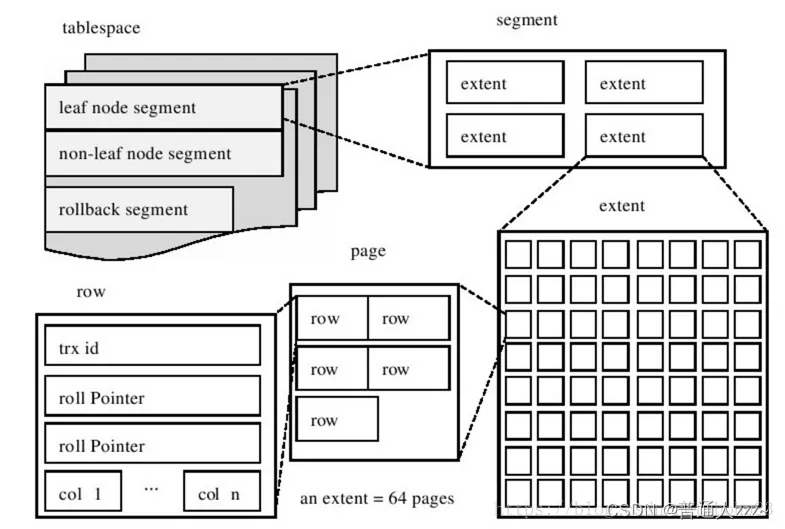
- 行(Row):数据行。
- 页(Page):为 InnoDB 存储引擎磁盘管理的最小单元,每页大小默认为 16kb。
- 区(Extent):64个相邻的 Page 称为一个 Extent。默认情况下 Extent 大小为 16kb * 64 = 1024kb = 1MB。
- 段(Segment):Segment 由一个或多个 Extent 组成,在 Segment 中不要求区与区之间是相邻的。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。
- 表空间(Tablespace):Tablespace 是一个逻辑容器,存储的对象是 Segment,在一个 Tablespace 中可以有一个或多个 Segment,但是一个 Segment 只能属于一个 Tablespace。数据库由一个或多个 Tablespace 组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。在 InnoDB 中存在两种表空间的类型:共享表空间和独立表空间。如果是共享表空间就意味着多张表共用一个表空间。如果是独立表空间,就意味着每张表有一个独立的表空间,也就是数据和索引信息都会保存在自己的表空间中。独立的表空间可以在不同的数据库之间进行迁移。可通过命令
show variables like 'innodb_file_per_table';查看当前系统启用的表空间类型。目前最新版本已经默认启用独立表空间。InnoDB把数据保存在表空间内,表空间可以看作是InnoDB存储引擎逻辑结构的最高层。本质上是一个由一个或多个磁盘文件组成的虚拟文件系统。InnoDB用表空间并不只是存储表和索引,还保存了回滚段、双写缓冲区等。
由此可见,InnoDB 中的存储结构如下:
InnoDB 使用两种预读算法来减少磁盘I/O,提高系统性能,默认采用线性预读:
- 线性预读 linear read-ahead:以 Extent 为单位,将下一个 Extent 提前读取到 Buffer Pool 中。
- 随机预读 random read-ahead:随机预读以 Page 为单位,将当前 Extent 中剩下的 Page 提前读取到 Buffer Pool 中。不建议使用随机预读,会降低 MySQL 效率。
2.2 Buffer Pool free链
上面说到,每个 Page Cache 存放在 Buffer Pool 中都会对应一个描述数据。在 MySQL 中,将所有 空闲的缓存页的描述数据块 所组成的双向链表定义为 free链。由此可知,free 链具有如下特征:
- 双向链表;
- 每个节点为空闲的缓存页对应的描述数据块;
- 当缓存页存在数据时,将从 Free 链中移除;
在缓存页的描述数据区中存在两个指针:free_pre 和 free_next ,分别指向自己的上一个 free链节点,以及下一个 free链节点。当需要操作的数据在 Buffer Pool 中不存在时,会先将其存在的 Page 缓存到 Buffer Pool 中,然后再对齐进行操作,那整个过程是怎样的呢?
- 判断当前操作数据是否存在 Buffer Pool 中(通过
表空间号+数据页号判断); - 存在,直接进行操作;
- 不存在,从 free链 中获取一个描述数据块;
- 将 Page 写入当前描述数据块对应的 Page Cache 中;
- 将 Page 相关的一些描述数据写入当前描述数据块中;
- 最后将当前描述数据块从 free 中移除,并把当前缓存页写入一个哈希表中;
上面提及到的哈希表结构如下:
- key -> 表空间号 + 数据页号;
- value -> 缓存页地址;
2.3 Buffer Pool 空间管理
Buffer Pool 为系统内存,默认大小为 128M,可通过参数 innodb_buffer_pool_size 调整 Buffer Pool 大小,官方建议实际生产中,Buffer Pool 大小可以配置为机器内存的 50% ~ 75% 左右。
Buffer Pool 的大小设置合理,对整个 MySQL 性能也是具体非常大的优化的,涉及到相关参数如下:
# 缓存区域的大小,建议配置为机器内存的 50% ~ 75% 左右
innodb_buffer_pool_size=1024M
# 在mysql 5.7.5之前,buffer pool的大小只能在mysql启动之前通过innodb_buffer_pool_size设置,在mysql运行过程中是不允许进行修改的。
# 在mysql5.7.5及之后的版本中支持运行过程中修改innodb_buffer_pool_size的值,每次修改都需要重新向服务器申请连续的内存空间,把旧的
# buffer pool数据放到新的buffer pool中,这样的操作是特别费时的。innodb使用chunk为单位来申请连续的内存空间,一个buffer pool由多个
# chunk组成,每个chunk里面存放控制块和缓存页对,一个chunk的默认大小是128M。这样在运行过程中修改buffer pool的大小,只用增加或者删
# 除chunk的数量,使chunk的累计大小等于新的buffer pool值即可达到修改的效果。
#
# 配置chunk值需要注意的点:
# innodb_buffer_pool_size的值必须是innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances的整数倍,为了保证每个buffer pool
# 的chunk数量相同;当innodb_buffer_pool_size不是他们两乘积的整数倍时,会自动把innodb_buffer_pool_size的值设置为他们乘积的整数倍。
innodb_buffer_pool_chunk_size=128M
# 当buffer pool比较大的时候(超过1G),innodb会把buffer pool划分成几个instances,这样可以提高读写操作的并发,减少竞争。读写page都使用hash函数分配给一个instances。把需要缓冲的数据hash到不同的缓冲池中,这样可以并行的内存读写。innodb_buffer_pool_instances 参数显著的影响测试结果,特别是非常高的 I/O 负载时。
innodb_buffer_pool_instances=8
既然 Buffer Pool 是一块内存区域,那内存是空间大小总是有上限的,数据不可能一直存储在 Buffer Pool 中,所以,可以想象到,存储在 Buffer Pool 中的数据肯定会存在一个淘汰机制,常见的数据淘汰算法有LRU(最久未使用)、LFU(最少使用),辣么 Buffer Pool 采用什么方式进行数据淘汰呢?
Buffer Pool 内存结构整体采用 LRU 算法进行数据淘汰,但相比 LRU 算法做了一些升级优化,将 Buffer Pool 的 LUR 链表拆分为两部分:冷数据链(Old Sublist)、热数据链(Old Sublist),通过分割线 Midpoint 对 Buffer Pool 的冷热数据进行分离。整体结构如下:
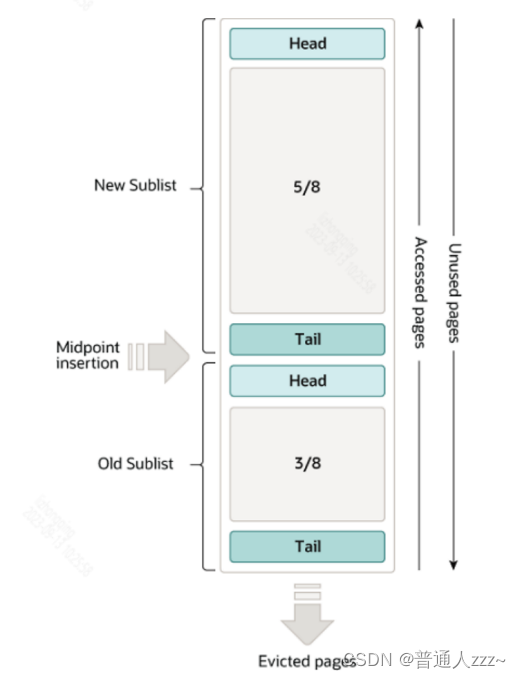
如上图,默认情况下,冷热数据空间占比为 New Sublist : Old Sublist = 5 : 3 ,可通过参数 innodb_old_blocks_pct=37 进行调整。
注意:参数
innodb_old_blocks_pct代表 Old Sublist 所占用比率,值区间为 5-95 之间。
值越小,冷数据区没有被访问的数据淘汰速度越快。
一般生产的机器,内存比较大。我们会把innodb_old_blocks_pct 值调低,防止热数据被刷出内存。
Buffer Pool 的 LRU 算法整体原理如下:
- 所有新数据页加入 Buffer Pool 时,一律先放入 Old 区的 Head;
- 默认在 1s(可通过参数innodb_old_blocks_time=1000进行调整,毫秒) 后,如果该缓存页再次被访问,则会移动到 New 区的 Head位置;
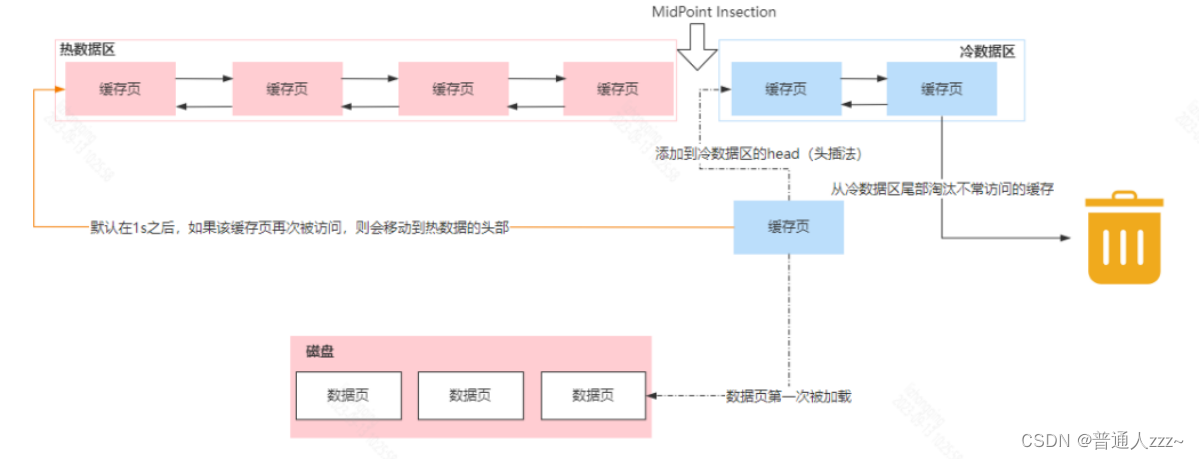
2.4 Buffer Pool 脏页(Flush链)
当我们在执行增删改的时候,会先访问 Buffer Pool 中是否存在当前数据,如果不存在,那么必然会基于 free链表找到一个空闲的缓
存页,然后读取到缓存页中,如果存在,则直接对其进行操作。在 MySQL 中,为了提供效率,数据的任何操作都是基于 Buffer Pool 的,当我们更新了 Page Cache 中的数据后,就会导致缓存页数据与磁盘存储数据不一致,我们将被修改过的缓存页称为脏页。
为了根据便捷将脏页的数据刷到磁盘中,MySQL 将所有脏页组成一个 Flush链,Flush链的也是由描述数据块中的两个指针(flush_pre 和 flush_next)组成的双向链表,那什么时候触发将 Flush链中的脏页数据刷新到磁盘中?
- 后台线程定时执行刷新;
- Buffer Pool 内存不足时(冷热数据区不足都会触发刷新);
- 数据库正常关闭;
- Redo Log写满;
三、Redo Log
在进行 MySQL 数据修改时,都是先修改 Buffer Pool 中数据,然后将存在修改的 Page Cache 加入脏页,最后由后台线程进行刷盘,整体流程如下:
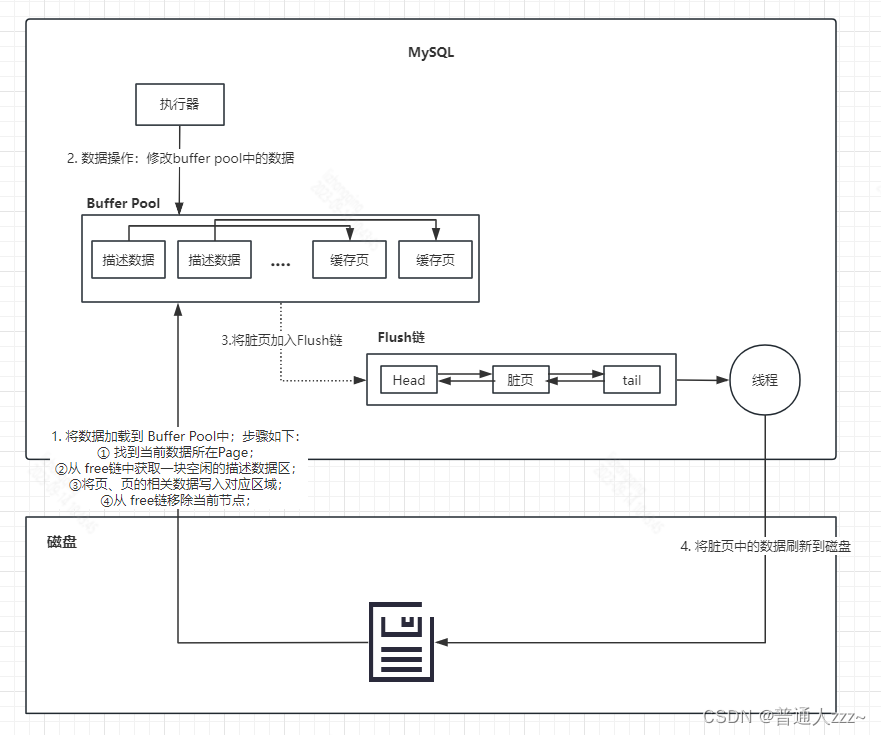
我们都知道,MySQL 是支持ACID特性的,那在整个过程中,数据都是由后台线程刷新到磁盘,假如在进行刷盘之前数据库宕机,那内存中修改的持久化数据是不是就丢失了???
为了处理上面这种异常情况,MySQL 引入了 Redo Log 日志机制。MySQL 在修改 Buffer Pool 中数据记录是,会同步向 Redo Log 中写入一条记录,如果数据库宕机后,存在未同步到磁盘的数据,在后续数据库重启时,会从 Redo Log 中读取之前已经进行过的操作,然后将这些操作重新再内存中执行一遍,最后由后台线程进行刷盘,完成数据崩溃恢复。这也是事务ACID特性中 D(Durability,持久性)的保障机制。
3.1 Redo Log Buffer
基于以上流程,MySQL 在修改 Buffer Pool 中数据记录是,会同步向 Redo Log 写一条记录,如果每一次修改,都需要和磁盘进行一次 IO 那将非常影响 MySQL 效率,于是,MySQL 在这基础上引入了一个 Redo Log Buffer 机制,整体流程如下:
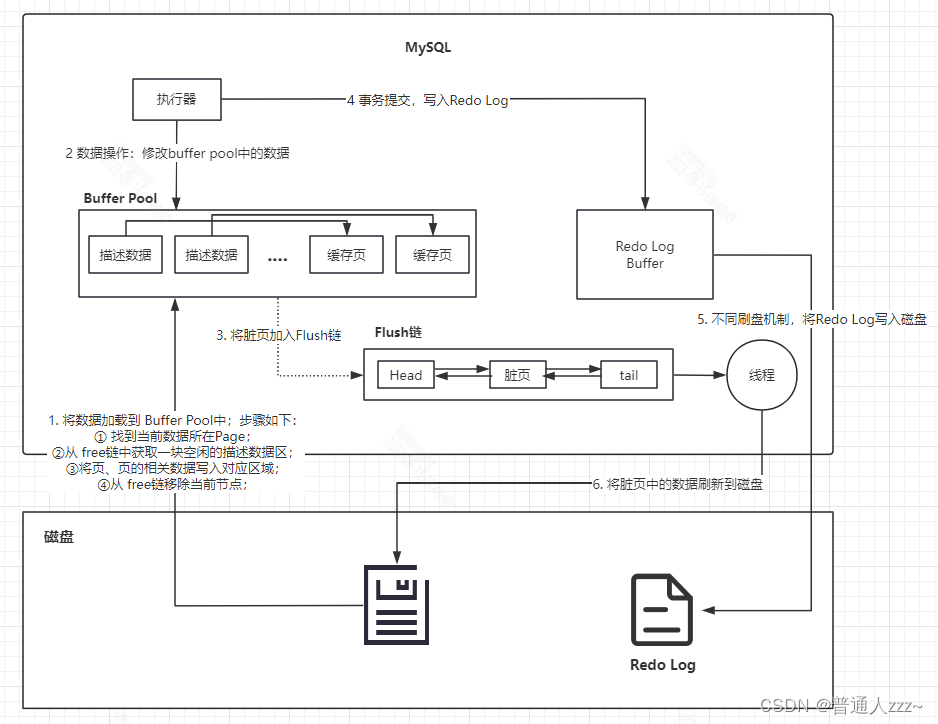
Redo Log Buffer 也是存在大小的,默认为 16MB,可通过参数 innodb_log_buffer_size=16MB 变量来调整。
Redo Log Buffer空间越大,可以容纳更大的事务操作,而无需将数据直接写入到 Redo 磁盘日志中,减少了与磁盘的交互。所以,如果事务中如果有大量的DML操作,可 以考虑增大 Log Buffer 的值,减少磁盘 IO 从而提升效率。
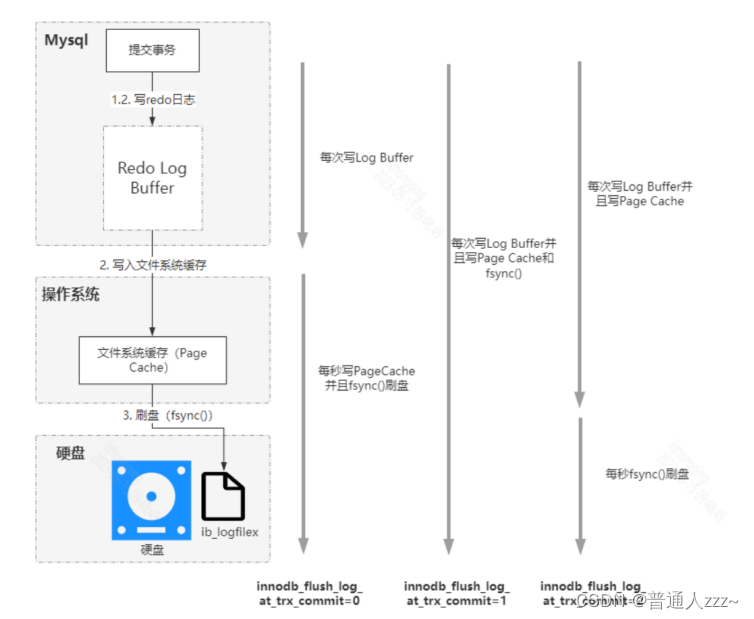
3.2 Redo Log Buffer 刷盘机制
在将任何内存中的数据刷新到磁盘,都需要经历如下节点:内存 -> 操作系统页缓存 -> 磁盘,所以,MySQL 提供了三种 Redo Log Buffer 刷盘机制,来满足不同业务场景,可通过参数 innodb_flush_log_at_trx_commit 进行设置,具体如下:
innodb_flush_log_at_trx_commit=0:将每秒一次地将 Redo Log Buffer 中的数据写入 Redo Log File 中,并且 Redo Log File 的 flush 操作同时进行。该模式下,在事务提交的时候,不会主动触发写入磁盘的操作。这个策略的性能是最佳的,但是会存在 1s 的数据丢失。innodb_flush_log_at_trx_commit=1:每次事务提交时 MySQL 都会把 Redo Log Buffer 的数据写入 Redo Log File,并且调用 flush 操作刷新到磁盘中去。这个策略能保证强一致性,也是InnoDB默认的配置,为的是保证事务的ACID特性。innodb_flush_log_at_trx_commit=2:每次事务提交时 MySQL 都会把 Redo Log Buffer 的数据写入 Redo Log File。但是 flush 操作并不会同时进行,由后台线程每秒执行一次 flush 操作,交由操作系统保证数据刷新到磁盘。这种策略,如果操作系统出现崩溃,也可能会存在 1s 的数据丢失,当相比 0 这种策略,数据丢失概率更小。
四、Undo Log
MySQL InnoDB是支持事务回滚(ACID中的Atomiciy,原子性),一个事务要么全部执行,要么全部失败。那当失败时,MySQL 通过什么来进行回归呢??
在 MySQL InnoDB中,任何数据的修改前,都需先记录修改前数据,用于后续事务回滚操作,我们将记录修改前数据定义为 Undo Log。引入 Undo Log 后数据修改流程如下:
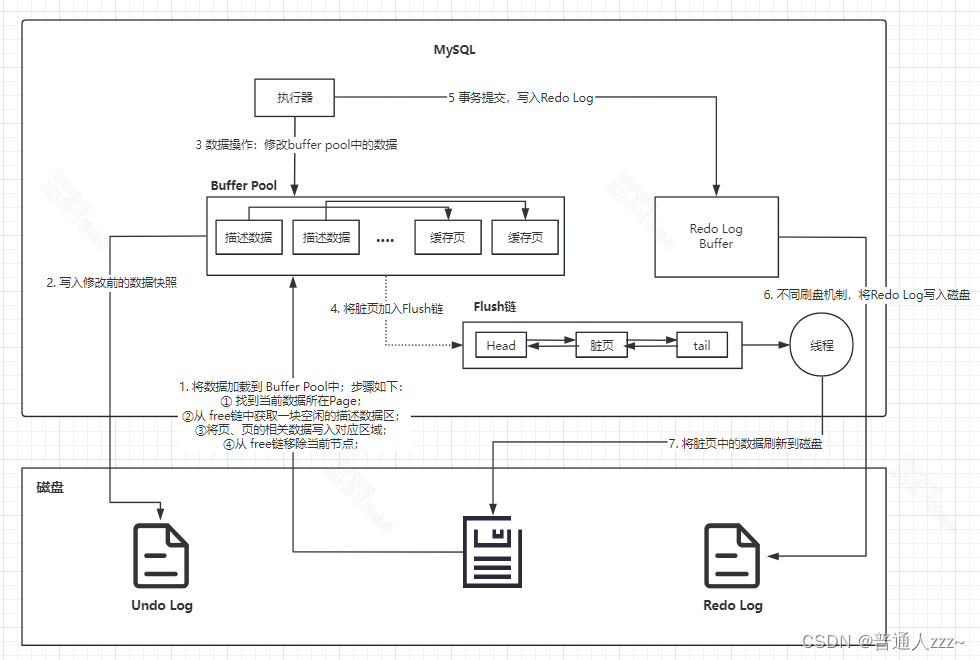
MySQL Undo Log存储的信息主要有:
- 修改前的数据值:用于数据回滚;
- 修改后的数据值:如果事务执行了更新、插入或删除等操作,Undo Log 也会记录新值,以便在回滚时撤销这些更改;
- 事务元数据:每个 Undo Log 记录都会包括与事务相关的信息,如事务ID、事务的状态(开始、提交、回滚等)以及其他元数据。
在 MySQL 官网描述中,Undo Log 主要作用除了用于支持事务 rollback,保证原子性,还用于支持事务的 MVCC (多版本并发控制)机制。MVCC 允许多个事务同时访问相同的数据表,每个事务都能看到自己的数据版本,而不会互相干扰。如果事务需要回滚,Undo Log 中的旧值信息将被用来还原数据到事务开始之前的状态。
需要注意的是,Undo Log是存储在磁盘上的,但在事务执行期间,它的一部分可能会暂时存储在内存中的Undo Log Buffer中,以提高性能。在事务提交之后,Undo Log中的数据将被清理或重用。
4.1 Undo Tablespace
在 MySQL 中,将 Undo Log 存储的内容也包括一部分数据,所以在整体架构设计时,定义了一个组件,用于 Undo Log 日志的管理、存储、清理等,这个组件为 Undo Tablespace。
Undo Tablespace在MySQL数据库中扮演着重要的角色,主要用于以下几个方面:
- 用于回滚:当一个事务需要回滚到之前的状态时,使用 Undo Tablespace 中的数据来还原数据到事务开始之前的状态。
- 多版本并发控制 (MVCC):MySQL通过 Undo Tablespace 中的数据来支持 MVCC,允许多个事务同时访问相同的数据表,每个事务都能看到自己的数据版本,从而提高了并发性能。
- 垃圾收集:当事务提交或回滚后,Undo Tablespace中的数据可能会变得无效。MySQL会定期进行垃圾收集,回收不再需要的 Undo 数据,以释放空间。
- 长事务处理:长时间运行的事务可能导致 Undo Tablespace 中的数据积累,因此它需要足够的空间来存储这些数据。管理Undo Tablespace的大小对于处理长事务至关重要。
4.2 相关参数
| 参数 | 说明 | 默认值 |
|---|---|---|
innodb_undo_tablespaces | 指定InnoDB Undo Tablespace的个数,不支持后续修改。默认值为0,表示不独立设置 undo 的 tablespace,默认记录到 ibdata 中;否则,则在undo目录下创建这么多个undo文件(每个文件的默认大小为10M)。最多可以设置到126。例如假定设置该值为4,那么就会在mysql的data目录下创建命名为 undo001~undo004 的 undo tablespace 文件 | 0 |
innodb_undo_logs | 指定InnoDB引擎中Undo Log的数量,每个Undo Log用于存储不同的事务数据 | 128 |
innodb_max_undo_log_size | 控制每个Undo Log文件的最大大小,当Undo Log文件达到这个大小时,会触发回收操作 | 1GB |
innodb_undo_log_truncate | undo是否加密 | OFF |
innodb_undo_directory | 指定Undo Log文件的存储目录。如果未设置,Undo Log文件将存储在数据目录中。 |
五、Change Buffer
在之前的数据修改流程中,MySQL InnoDB 的 Buffer Pool 会缓存磁盘中的数据页,所以当我们在进行数据修改的时候,会先从 Buffer Pool 中通过表空间号+数据页号查找对应数据,如果数据存在,就直接修改,并把修改后的数据添加到 Flush 链表中,等待刷新到磁盘。如果在数据修改的时候,对应的数据页不存在,那么就会先从磁盘中加载数据到 Buffer Pool,然后进行修改,执行之前流程。
但是,这种对于写多读少的场景,会产生大量的磁盘IO,即会存在很多数据都不存在Buffer Pool中,会产生大量的磁盘IO。MySQL基于以上场景,设计了一个 Change Buffer 来优化,目的是在写多读少的情况下,降低磁盘IO交互,提高效率。
Changer Buffer 是对 非唯一性普通索引 数据不在缓冲区中,但是又要对数据进行修改操作,在不影响数据一致性的前提下,InnoDB 不会将数据加载到 Buffer Pool 中,而是将更新操作缓冲到 Change Buffer 中,最后再某一时刻进行Merge,延迟更新,从而减少和磁盘IO次数。
Change Buffer 也是属于 Buffer Pool 中的一块内存区域,可通过参数 innodb_change_buffer_max_size=25 设置,默认为 Buffer Pool 大小25%,最大可设置为 50%。
- 当在系统中存在大量插入,更新和删除操作时,可以增大
innodb_change_buffer_max_size,以提高系统的写入性能。 - 当在系统中有大量查询操作时,可以减小
innodb_change_buffer_max_size,以减少 Buffer Pool 中数据页的淘汰的概率,提高系统的读取性能。 innodb_change_buffer_max_size设置是动态的,它允许修改设置而无需重新启动服务器。
Change buffer为什么只针对【非唯一普通索引】数据修改??
因为如果是唯一性索引,InnoDB在修改的时候,必须要去校验这个数据是否违反唯一性约束条件,从而直接将数据直接加载到 Buffer Pool 中,不会走 Change Buffer 逻辑。
5.1 Change Buffer缓存操作类型
Change Buffer 在 MySQL5.5 之后可以支持新增、删除、修改的写入,对于受 I/O 限制的操作(大量DML、如批量插入)有很大的性能提升价值。但是对于一些特定的场景,可以通过修改参数 innodb_change_buffering 来变更 Change Buffer 支持的类型。
- all :默认值,缓冲区插入,删除和清除。
- none:不缓存任何操作;
- inserts:插入操作;
- deletes:删除标记操作;
- changes:插入、删除标记操作;
- purges:后台发生的物理删除操作;
5.2 Change Buffer被 Merge 情况
上面提及到的,针对 非唯一性普调索引 的数据操作,会先将更新写入 Change Buffer 中,最后再某一时刻进行 Merge,那什么情况下会触发 Merge ???
- 读取Change buffer中记录的数据页时,会将 Change buffer 合并到 Buffer Pool 中,然后被刷新到磁盘;
- 当系统空闲或者 slow shutdown 时,后台master线程发起merge;
- Change Buffer 的内存空间用完,后台master线程会发起merge;
- Redo Log写满(也会触发Flush链刷盘);
六、Doublewrite Buffer
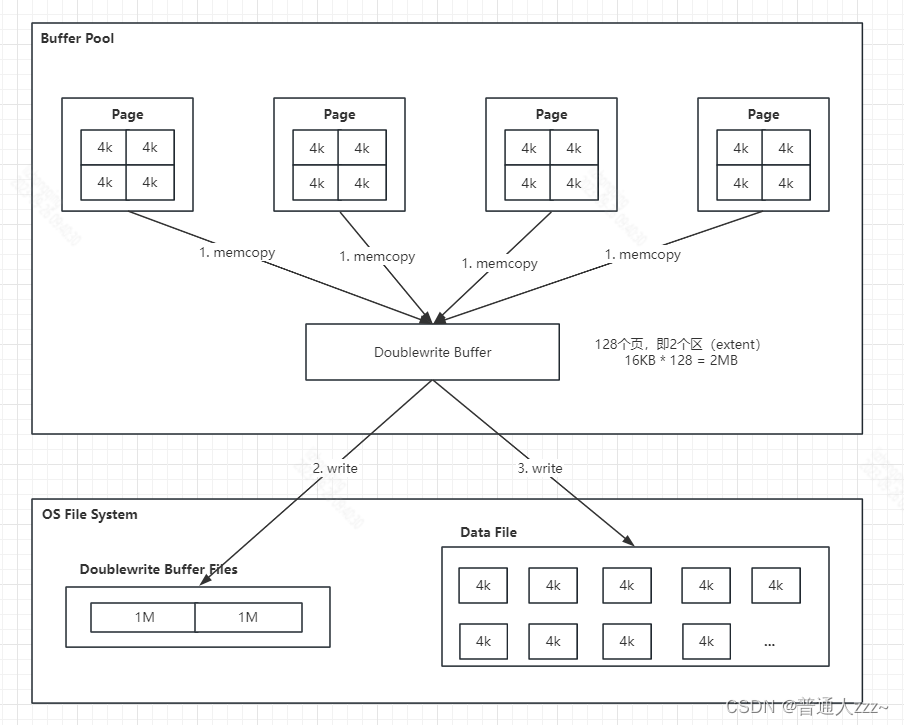
MySQL InnoDB 的 Page Cache 默认大小为 16k,但是正常操作系统 Page 为 4k,所以会存在 16K 只写入了一部分的极端情况,如当 InnoDB 在进行数据页的写入操作时,磁盘挂了,就可能导致 16k 只写了一部分情况,产生页断裂,导致数据部分失效,这种失效是无法回滚的,所以为了避免这种情况,引入了 Doublewrite Buffer。
Doublewrite Buffer 包括两个部分:
- 内存中的一块缓冲区 Doublewrite Buffer,大小为2MB;
- 磁盘文件 Doublewrite Buffer Files,为物理磁盘上共享表空间中连续的128个页,即2个区(extent),大小同样为2MB;
在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过 memcopy 函数将脏页先复制到内存中的 doublewrite buffer,之后通过doublewrite buffer再分两次,每次1MB顺序地写入共享表空间的物理磁盘上,然后马上调用 fsync 函数,同步磁盘,避免缓冲写带来的问题。在这个过程中,因为 doublewrite 页是连续的,因此这个过程是顺序写的,开销并不是很大。在完成 doublewrite 页的写入后,再将doublewritebuffer中的页写入各个表空间文件中,此时的写入则是离散的。所以当进行故障恢复的时候,InnoDB 会去检查 Doublewrite Buffer 的页和本来位置页的内容, 如果不一致,会从 Doublewrite Buffer 中进行恢复,如果 Doublewrite Buffer 中的页也不完整,会进行丢弃。
主要流程如下:
6.1 相关参数
| 参数 | 说明 | 默认值 |
|---|---|---|
innodb_doublewrite | 是否启用开关,可选值:on / off | on |
innodb_doublewrite_batch_size | 批量写入的页数。此变量用于高级性能调整。默认值应该适合大多数用户,0~256 | 0 |
innodb_doublewrite_dir | doublewrite buffer files目录,如果未指定,则默认为数据目录 | |
innodb_doublewrite_files | doublewrite buffer files文件数量 | 默认情况下,为每个缓冲池实例创建两个双写文件,缓冲池实例的数量由 innodb_buffer_pool_instances 控制 |
Innodb_dblwr_pages_written | 写的总的页数 | |
innodb_dblwr_writes | 实际写入的次数 |
Innodb_dblwr_pages_written : innodb_dblwr_writes 可判断当前数据库写入压力,当值远远小于 64:1 时,表明压力并不高。
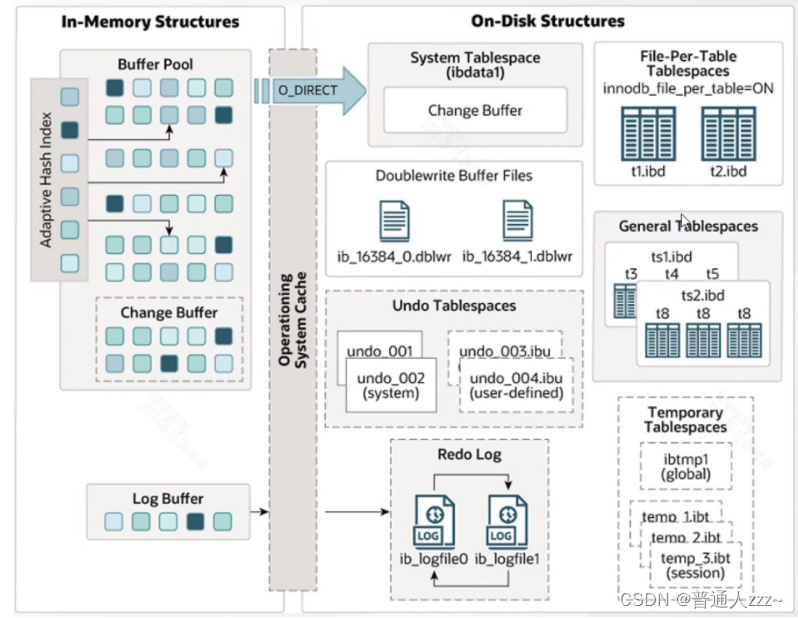
七、InnoDB 整体架构图