一、查漏补缺:
1.关于glob.glob的用法,返回一个文件路径的 列表:

当然,再套用1个sort,就是将所有的文件路径按照字母进行排序了
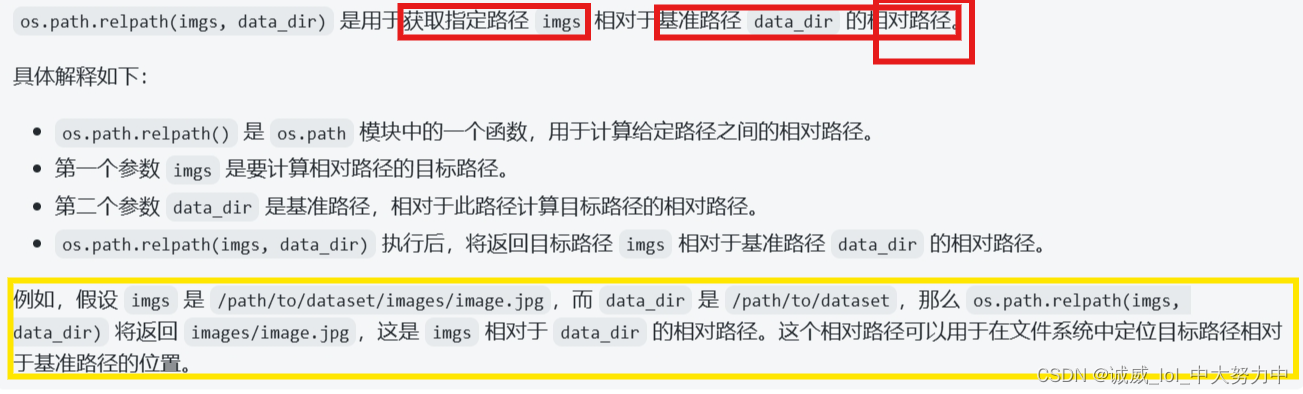
2.relpath == relative_path返回相对于基准路径的相对路径的函数
二、代码剖析:
1.加载对应的数据 和 引入必要的库+环境设置:
# set up environment
!pip install pytorchcv
!pip install imgaug
# download
!wget https://github.com/DanielLin94144/ML-attack-dataset/files/8167812/data.zip
# unzip
!unzip ./data.zip
!rm ./data.zip
import torch
import torch.nn as nn
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
batch_size = 8# the mean and std are the calculated statistics from cifar_10 dataset
cifar_10_mean = (0.491, 0.482, 0.447) # mean for the three channels of cifar_10 images
cifar_10_std = (0.202, 0.199, 0.201) # std for the three channels of cifar_10 images
# convert mean and std to 3-dimensional tensors for future operations
mean = torch.tensor(cifar_10_mean).to(device).view(3, 1, 1)
std = torch.tensor(cifar_10_std).to(device).view(3, 1, 1)
epsilon = 8/255/std #这个epsilon就是边界的限制
root = './data' # directory for storing benign images
# benign images: images which do not contain adversarial perturbations
# adversarial images: images which include adversarial perturbations2.关于Dataset的设计部分的研读:
#引入必要的库
import os
import glob
import shutil
import numpy as np
from PIL import Image
from torchvision.transforms import transforms
from torch.utils.data import Dataset, DataLoader
#定义全局的transform方式
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(cifar_10_mean, cifar_10_std)
])
#定义这200张adv_picture的攻击方式
#虽然没有看作业视频,但是我估计这个 AdvDataset不过是对选定的200张图片 最终攻击成为 目标的 names
class AdvDataset(Dataset):
def __init__(self, data_dir, transform):
self.images = []
self.labels = []
self.names = []
'''
data_dir
├── class_dir
│ ├── class1.png
│ ├── ...
│ ├── class20.png
'''
for i, class_dir in enumerate(sorted(glob.glob(f'{data_dir}/*'))): #data_dir下面有很多个class_dir
images = sorted(glob.glob(f'{class_dir}/*')) #class_dir下面有很多的class1.png、class2.png。。。。
self.images += images #将这个class_dir下面的png的绝对地址依次加到全局的images列表中
self.labels += ([i] * len(images)) #对应的label中加上i这个数值 总共加上该class_dir中的png数目
self.names += [os.path.relpath(imgs, data_dir) for imgs in images] #relpath == relative_path相对路径
self.transform = transform
def __getitem__(self, idx):
image = self.transform(Image.open(self.images[idx]))
label = self.labels[idx]
return image, label #返回 代开后的png+经过transform之后的image对象 以及对应的label(这个label还是原来的label)
def __getname__(self):
return self.names #返回的name就是class_dir/class2.png这种东西
def __len__(self):
return len(self.images)
#获取adv_dataloader 和 对应的names
adv_set = AdvDataset(root, transform=transform)
adv_names = adv_set.__getname__()
adv_loader = DataLoader(adv_set, batch_size=batch_size, shuffle=False)
print(f'number of images = {adv_set.__len__()}')3.调用原来训练好的图像分类的model:
# to evaluate the performance of model on benign images
#这个就是原来训练好的图像分类识别的model进行eval,得到对应的dataloader的loss 和 acc
def epoch_benign(model, loader, loss_fn):
model.eval()
train_acc, train_loss = 0.0, 0.0
for x, y in loader:
x, y = x.to(device), y.to(device)
yp = model(x)
loss = loss_fn(yp, y)
train_acc += (yp.argmax(dim=1) == y).sum().item()
train_loss += loss.item() * x.shape[0]
return train_acc / len(loader.dataset), train_loss / len(loader.dataset)4.总共3中生成adv_image的方式,分别是 fgsm, ifgsm ,mifgsm:
它们的想法都是 输入一张图片,然后利用已经train好的分类器的model得到对应的loss和grad,然后利用这个grad的sign将这张图片在“空间”中“反向”移动(原来我们是" -eta*grad" 现在我们是“+eta*grad”)一些,以致于之后分类器分类出来的和目标label的有区别
(目前mifgsm没有实作,具体实作可以参考这篇paper1710.06081.pdf (arxiv.org))
#定义FGSM一次就达到目的的攻击方式的对应的函数
# perform fgsm attack
def fgsm(model, x, y, loss_fn, epsilon=epsilon):
x_adv = x.detach().clone() # initialize x_adv as original benign image x
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y) # calculate loss
loss.backward() # calculate gradient
# fgsm: use gradient ascent on x_adv to maximize loss
grad = x_adv.grad.detach()
x_adv = x_adv + epsilon * grad.sign() #直接一锤定音,grad.sign就是正取1,负取-1,一拳超人
return x_adv
#总共有fgsm , ifgsm ,mifgsm 这3种model,最开始只要理解fgsm的工作方式就好了
# alpha and num_iter can be decided by yourself ,
alpha = 0.8/255/std #其实我觉得,按照李宏毅老师的讲法,这个alpha应该是8/255/std也就是和epsilon的大小一致才对
#哦!原来这里是ifgsm,所以会有20个iter,所以alpha的数值 只取到 epsilon的1/10
def ifgsm(model, x, y, loss_fn, epsilon=epsilon, alpha=alpha, num_iter=20): #参数是model,x图像,y标签,总共20个iter
x_adv = x
# write a loop of num_iter to represent the iterative times
for i in range(num_iter):
# x_adv = fgsm(model, x_adv, y, loss_fn, alpha) # call fgsm with (epsilon = alpha) to obtain new x_adv
x_adv = x_adv.detach().clone()
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y) # calculate loss
loss.backward() # calculate gradient
# fgsm: use gradient ascent on x_adv to maximize loss
grad = x_adv.grad.detach()
x_adv = x_adv + alpha * grad.sign() #得到攻击之后的图像x_adv',计算方法和李宏毅老师讲到的一致
x_adv = torch.max(torch.min(x_adv, x+epsilon), x-epsilon) # clip new x_adv back to [x-epsilon, x+epsilon]
return x_adv
#让我再看看这个mifgsm到底是个啥东西呢,也就是要额外加上一个momentum的处理 和 decay是吧
#其实,这个mifgsm就是再ifgsm的基础上,类似于原来gradient descend可能遇到的问题一样,都要借助前一次的momentum动量进行处理
def mifgsm(model, x, y, loss_fn, epsilon=epsilon, alpha=alpha, num_iter=20, decay=1.0):
x_adv = x
# initialze momentum tensor
momentum = torch.zeros_like(x).detach().to(device) #一开始设定的momentum的数值就是和x的大小完全一样的全0
# write a loop of num_iter to represent the iterative times
for i in range(num_iter):
x_adv = x_adv.detach().clone()
x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad
loss = loss_fn(model(x_adv), y) # calculate loss
loss.backward() # calculate gradient
# TODO: Momentum calculation
# grad = .....
#。。。有待进一步添加计算momentum的代码,应该会用到参数里面的decay这个参数
x_adv = x_adv + alpha * grad.sign()
x_adv = torch.max(torch.min(x_adv, x+epsilon), x-epsilon) # clip new x_adv back to [x-epsilon, x+epsilon]
return x_adv5.调用上面的fgsm或者ifgsm生成对应 adv_image并进行存储,之后再用model进行预测:
# perform adversarial attack and generate adversarial examples
#调用上述定义的 adv_attack的方法,并且生成对应的 图片的攻击后 图像
def gen_adv_examples(model, loader, attack, loss_fn):
model.eval()
adv_names = []
train_acc, train_loss = 0.0, 0.0
for i, (x, y) in enumerate(loader):
x, y = x.to(device), y.to(device)
x_adv = attack(model, x, y, loss_fn) # obtain adversarial examples ,获取到攻击后的图像
yp = model(x_adv) #攻击后的图像的预测结果yp
loss = loss_fn(yp, y) #和原来label之间的loss
train_acc += (yp.argmax(dim=1) == y).sum().item()
train_loss += loss.item() * x.shape[0]
#上面已经用model生成了我们需要的x_adv的攻击后图像,下面只是对这张图像进行 反向还原罢了
# store adversarial examples
adv_ex = ((x_adv) * std + mean).clamp(0, 1) # to 0-1 scale
adv_ex = (adv_ex * 255).clamp(0, 255) # 0-255 scale
adv_ex = adv_ex.detach().cpu().data.numpy().round() # round to remove decimal part,利用round函数取出小数点
adv_ex = adv_ex.transpose((0, 2, 3, 1)) # transpose (bs, C, H, W) back to (bs, H, W, C)
adv_examples = adv_ex if i == 0 else np.r_[adv_examples, adv_ex]
return adv_examples, train_acc / len(loader.dataset), train_loss / len(loader.dataset)
#将adv攻击之后的图片 和 对应的攻击需要 绑定的label存储到对应的文件路径种
# create directory which stores adversarial examples
def create_dir(data_dir, adv_dir, adv_examples, adv_names):
if os.path.exists(adv_dir) is not True:
_ = shutil.copytree(data_dir, adv_dir)
for example, name in zip(adv_examples, adv_names):
im = Image.fromarray(example.astype(np.uint8)) # image pixel value should be unsigned int
im.save(os.path.join(adv_dir, name))6.实例化已经train过的model 和 需要使用的loss_fn:
from pytorchcv.model_provider import get_model as ptcv_get_model
#这里直接使用了已经train好的ciFar-10的图像分类识别的model
model = ptcv_get_model('resnet110_cifar10', pretrained=True).to(device)
loss_fn = nn.CrossEntropyLoss() #loss直接使用crossEntropy
benign_acc, benign_loss = epoch_benign(model, adv_loader, loss_fn)
print(f'benign_acc = {benign_acc:.5f}, benign_loss = {benign_loss:.5f}')7.上面都是定义哈,这里才是真正的调用fgsm 和 ifgsm生成对应的 adv_图像:
#调用fgsm的结果是:
adv_examples, fgsm_acc, fgsm_loss = gen_adv_examples(model, adv_loader, fgsm, loss_fn)
print(f'fgsm_acc = {fgsm_acc:.5f}, fgsm_loss = {fgsm_loss:.5f}')
create_dir(root, 'fgsm', adv_examples, adv_names)adv_examples, ifgsm_acc, ifgsm_loss = gen_adv_examples(model, adv_loader, ifgsm, loss_fn)
print(f'ifgsm_acc = {ifgsm_acc:.5f}, ifgsm_loss = {ifgsm_loss:.5f}')
create_dir(root, 'ifgsm', adv_examples, adv_names)8.总共10个类别的CiFAR-10,每个类别分别show出1张攻击前后的图像 以及 经过同一个model的预测结果:
#这里做的事情,就是输出利用这个训练好的model,分别输入攻击前 和 攻击后的图片, 然后得到的各自的pred的概率
import matplotlib.pyplot as plt
classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10, 20))
cnt = 0
for i, cls_name in enumerate(classes): #10个种类,每个种类展示1.png那个图片攻击前后的识别结果
path = f'{cls_name}/{cls_name}1.png'
# benign image
cnt += 1
plt.subplot(len(classes), 4, cnt)
im = Image.open(f'./data/{path}') #这一段 和 下面一段的唯一的区别 只是打开的图片的文件不同罢了
logit = model(transform(im).unsqueeze(0).to(device))[0]
predict = logit.argmax(-1).item()
prob = logit.softmax(-1)[predict].item()
plt.title(f'benign: {cls_name}1.png\n{classes[predict]}: {prob:.2%}')
plt.axis('off')
plt.imshow(np.array(im))
# adversarial image
cnt += 1
plt.subplot(len(classes), 4, cnt)
im = Image.open(f'./fgsm/{path}')
logit = model(transform(im).unsqueeze(0).to(device))[0]
predict = logit.argmax(-1).item()
prob = logit.softmax(-1)[predict].item()
plt.title(f'adversarial: {cls_name}1.png\n{classes[predict]}: {prob:.2%}')
plt.axis('off')
plt.imshow(np.array(im))
plt.tight_layout()
plt.show()9.对1张狗狗的图像,用原来的model可以识别它是dog,但是经过adv_攻击后的图像在model中识别就会变成cat,
最后,我们将这个adv_攻击图像 经过1个JPEG压缩,然后再通过model识别,就成功抵御了这个adv_攻击:
#这一部分只不过是对上面的那段代码的 单次循环的版本而已
# original image
path = f'dog/dog2.png'
im = Image.open(f'./data/{path}')
logit = model(transform(im).unsqueeze(0).to(device))[0]
predict = logit.argmax(-1).item()
prob = logit.softmax(-1)[predict].item()
plt.title(f'benign: dog2.png\n{classes[predict]}: {prob:.2%}')
plt.axis('off')
plt.imshow(np.array(im))
plt.tight_layout()
plt.show()
# adversarial image
adv_im = Image.open(f'./fgsm/{path}')
logit = model(transform(adv_im).unsqueeze(0).to(device))[0]
predict = logit.argmax(-1).item()
prob = logit.softmax(-1)[predict].item()
plt.title(f'adversarial: dog2.png\n{classes[predict]}: {prob:.2%}')
plt.axis('off')
plt.imshow(np.array(adv_im))
plt.tight_layout()
plt.show()


#为啥这里还有1个defence的部分捏,好奇怪哦
#虾米那就是干了这么一件事情,就是对adv攻击之后产生的图片 再通过1个JPEG的压缩,然后再用model进行pred
#观察,这个adv攻击是否就已经失效了
#我觉得,最大的成就感,来源于自己的创造,不是光读懂别人代码就行了,那样也迟早会劝退
#而是要,创造自己的那部分!那样,你才会更想去做这件事情
#所以,就先完成下面这个JPEG压缩的部分吧,有chatGPT,怕什么,什么都可以独立的实现,多花时间,自然能多收获
import imgaug.augmenters as iaa
# pre-process image
x = transforms.ToTensor()(adv_im)*255
x = x.permute(1, 2, 0).numpy()
x = x.astype(np.uint8)
# TODO: use "imgaug" package to perform JPEG compression (compression rate = 70)
# compressed_x = ... x ..
seq = iaa.JpegCompression(compression=70)
compressed_x = seq.augment_image(x)
logit = model(transform(compressed_x).unsqueeze(0).to(device))[0]
predict = logit.argmax(-1).item()
prob = logit.softmax(-1)[predict].item()
plt.title(f'JPEG adversarial: dog2.png\n{classes[predict]}: {prob:.2%}')
plt.axis('off')
plt.imshow(compressed_x)
plt.tight_layout()
plt.show()