取长补短之 Redis vs MySQL
做一个简单测试,分别填充 10 万条数据到 Redis 和 MySQL 中。MySQL 中的 name字段做了索引,相当于 Redis 的 Key,data 字段为 100 字节的数据,相当于 Redis 的Value。
在我的电脑上,使用 wrk 加 10 个线程 50 个并发连接做压测。可以看到,MySQL 90% 的请求需要 61ms,QPS 为 1460;而 Redis 90% 的请求在 5ms 左右,QPS 达到了 14008,几乎是 MySQL 的十倍。
但 Redis 薄弱的地方是,不擅长做 Key 的搜索。对 MySQL,我们可以使用 LIKE 操作前匹配走 B+ 树索引实现快速搜索;但对 Redis,我们使用 Keys 命令对 Key 的搜索,其实相当于在MySQL 里做全表扫描。在 QPS 方面,MySQL 的 QPS 达到了 Redis 的 157 倍;在延迟方面,MySQL的延迟只有 Redis 的十分之一。
Redis 慢的原因有两个:
- Redis 的 Keys 命令是 O(n) 时间复杂度。如果数据库中 Key 的数量很多,就会非常慢。
- Redis 是单线程的,对于慢的命令如果有并发,串行执行就会非常耗时。
一般而言,我们使用 Redis 都是针对某一个 Key 来使用,而不能在业务代码中使用 Keys 命令从 Redis 中“搜索数据”,因为这不是 Redis 的擅长。对于 Key 的搜索,我们可以先通过关系型数据库进行,然后再从 Redis 存取数据(如果实在需要搜索 Key 可以使用 SCAN 命令)。在生产环境中,我们一般也会配置 Redis 禁用类似 Keys 这种比较危险的命令,可以参考这里 ,一般不要把redis当数据库使用。
取长补短之 InfluxDB vs MySQL
使用 InfluxDB 来做的 Metrics 打点。时序数据库的优势,在于处理指标数据的聚合,并且读写效率非常高。
分别填充了 1000 万条数据到 MySQL 和 InfluxDB 中。其中,每条数据只有 ID、时间戳、10000 以内的随机值这 3 列信息,对于 MySQL 我们把时间戳列做了索引:
InfluxDB 批量插入 1000 万条数据仅用了 54 秒,相当于每秒插入 18 万条数据,速度相当
快;MySQL 的批量插入,速度也挺快达到了每秒 4.8 万。
对这 1000 万数据进行一个统计,查询最近 60 天的数据,按照 1 小时的时间粒度聚合,统计value 列的最大值、最小值和平均值,并将统计结果绘制成曲线图:
分别调用两个接口,可以看到 MySQL 查询一次耗时 29 秒左右,而 InfluxDB 耗时 980ms。
在按照时间区间聚合的案例上,我们看到了 InfluxDB 的性能优势。但,我们肯定不能把InfluxDB 当作普通数据库,原因是:
- InfluxDB 不支持数据更新操作,毕竟时间数据只能随着时间产生新数据,肯定无法对过去的数据做修改;
- 从数据结构上说,时间序列数据数据没有单一的主键标识,必须包含时间戳,数据只能和时间戳进行关联,不适合普通业务数据。
此外需要注意,即便只是使用 InfluxDB 保存和时间相关的指标数据,我们也要注意不能滥用tag。
InfluxDB 提供的 tag 功能,可以为每一个指标设置多个标签,并且 tag 有索引,可以对 tag 进行条件搜索或分组。但是,tag 只能保存有限的、可枚举的标签,不能保存 URL 等信息,否则可能会出现high series cardinality 问题,导致占用大量内存,甚至是 OOM。
你可以点击这里,查看 series 和内存占用的关系。对于 InfluxDB,我们无法把 URL 这种原始数据保存到数据库中,只能把数据进行归类,形成有限的 tag 进行保存。
总结一下,对于 MySQL 而言,针对大量的数据使用全表扫描的方式来聚合统计指标数据,性能非常差,一般只能作为临时方案来使用。此时,引入 InfluxDB 之类的时间序列数据库,就很有必要了。时间序列数据库可以作为特定场景(比如监控、统计)的主存储,也可以和关系型数据库搭配使用,作为一个辅助数据源,保存业务系统的指标数据。
取长补短之 Elasticsearch vs MySQL
Elasticsearch(以下简称 ES),是目前非常流行的分布式搜索和分析数据库,独特的倒排索引结构尤其适合进行全文搜索。
倒排索引可以认为是一个 Map,其 Key 是分词之后的关键字,Value 是文档 ID/片段 ID 的列表。我们只要输入需要搜索的单词,就可以直接在这个 Map 中得到所有包含这个单词的文档 ID/ 片段 ID 列表,然后再根据其中的文档 ID/ 片段 ID 查询出实际的文档内容。
对比下使用 ES 进行关键字全文搜索、在 MySQL 中使用 LIKE 进行搜索的效率差距
ES 耗时仅仅 48ms,MySQL 耗时 6 秒多是 ES 的 100 倍。很遗憾,虽然新闻分类 ID 已经建了索引,但是这个索引只能起到加速过滤分类 ID 这一单一条件的作用,对于文本内容的全文搜索,B+ 树索引无能为力。
MySQL 可以做到仅更新某行数据的某个字段,但 ES 里每次数据字段更新都相当于整个文档索引重建。即便 ES 提供了文档部分更新的功能,但本质上只是节省了提交文档的网络流量,以及减少了更新冲突,其内部实现还是文档删除后重新构建索引。因此,如果要在 ES 中保存一个类似计数器的值,要实现不断更新,其执行效率会非常低
ES 是一个分布式的全文搜索数据库,所以与 MySQL 相比的优势在于文本搜索,而且因为其分布式的特性,可以使用一个大 ES 集群处理大规模数据的内容搜索。但,由于 ES 的索引是文档维度的,所以不适用于频繁更新的 OLTP 业务。
一般而言,我们会把 ES 和 MySQL 结合使用,MySQL 直接承担业务系统的增删改操作,而ES 作为辅助数据库,直接扁平化保存一份业务数据,用于复杂查询、全文搜索和统计。接下来,我也会继续和你分析这一点。
结合 NoSQL 和 MySQL 应对高并发的复合数据库架构
我们设计了一个包含多个数据库系统的、能应对各种高并发场景的一套数据服务的系统架构,其中包含了同步写服务、异步写服务和查询服务三部分,分别实现主数据库写入、辅助数据库写入和查询路由。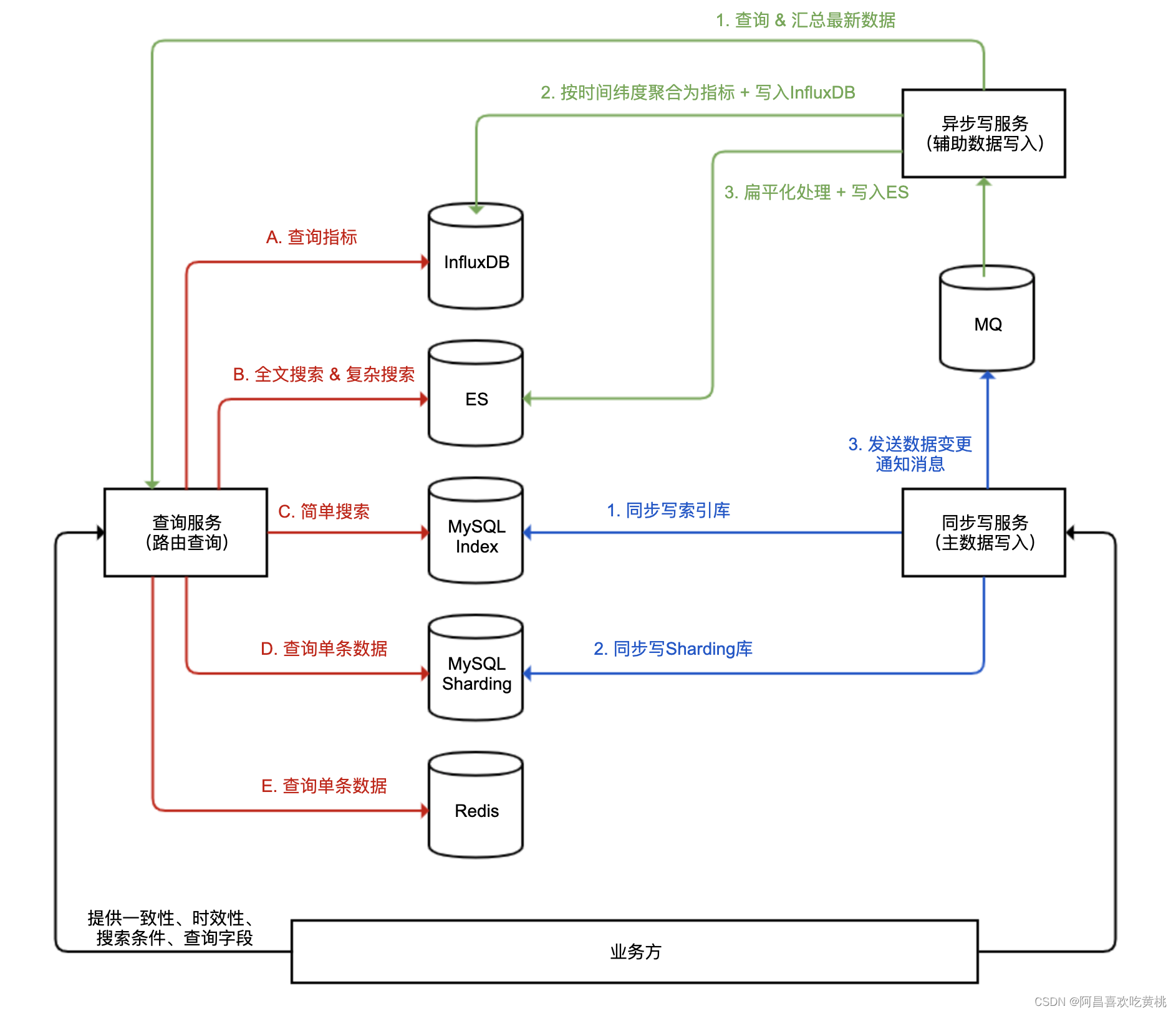
- RDBMS 经过了几十年的验证,已经非常成熟;
- RDBMS 的用户数量众多,Bug 修复快、版本稳定、可靠性很高;
- RDBMS 强调 ACID,能确保数据完整。
MySQL 擅长的地方:
按照主键 ID 的查询。直接查询聚簇索引,其性能会很高。但是单表数据量超过亿级后,性能也会衰退,而且单个数据库无法承受超大的查询并发,因此我们可以把数据表进行Sharding 操作,均匀拆分到多个数据库实例中保存。我们把这套数据库集群称作Sharding 集群。
按照各种条件进行范围查询,查出主键 ID。对二级索引进行查询得到主键,只需要查询一棵 B+ 树,效率同样很高。但索引的值不宜过大,比如对 varchar(1000) 进行索引不太合适,而索引外键(一般是 int 或 bigint 类型)性能就会比较好。因此,我们可以在 MySQL中建立一张“索引表”,除了保存主键外,主要是保存各种关联表的外键,以及尽可能少的varchar 类型的字段。这张索引表的大部分列都可以建上二级索引,用于进行简单搜索,搜索的结果是主键的列表,而不是完整的数据。由于索引表字段轻量并且数量不多(一般控制在 10 个以内),所以即便索引表没有进行 Sharding 拆分,问题也不会很大。
小结:
- Redis 对单条数据的读取性能远远高于 MySQL,但不适合进行范围搜索。
- InfluxDB 对于时间序列数据的聚合效率远远高于 MySQL,但因为没有主键,所以不是一个通用数据库。
- ES 对关键字的全文搜索能力远远高于 MySQL,但是字段的更新效率较低,不适合保存频繁更新的数据。
最后,我们给出了一个混合使用 MySQL + Redis + InfluxDB + ES 的架构方案,充分发挥了各种数据库的特长,相互配合构成了一个可以应对各种复杂查询,以及高并发读写的存储架构。
主数据由两种 MySQL 数据表构成,其中索引表承担简单条件的搜索来得到主键,Sharding 表承担大并发的主键查询。主数据由同步写服务写入,写入后发出 MQ 消息。辅助数据可以根据需求选用合适的 NoSQL,由单独一个或多个异步写服务监听 MQ 后异步写入。
由统一的查询服务,对接所有查询需求,根据不同的查询需求路由查询到合适的存储,确保每一个存储系统可以根据场景发挥所长,并分散各数据库系统的查询压力。