DISTINCT数据去重:
案例:获取tb_student学生表学员年龄的分布情况。
mysql> select * from tb_student;
+----+--------+------+--------+-----------------------+
| id | name | age | gender | address |
+----+--------+------+--------+-----------------------+
| 1 | 刘备 | 33 | 男 | 湖北省武汉市 |
| 2 | 貂蝉 | 18 | 女 | 湖南省长沙市 |
| 3 | 关羽 | 32 | 男 | 湖北省荆州市 |
| 4 | 大乔 | 20 | 女 | 河南省漯河市 |
| 5 | 赵云 | 25 | 男 | 河北省石家庄市 |
| 6 | 小乔 | 18 | 女 | 湖北省荆州市 |
+----+--------+------+--------+-----------------------+
6 rows in set (0.00 sec)
mysql> select distinct age from tb_student;
+------+
| age |
+------+
| 33 |
| 18 |
| 32 |
| 20 |
| 25 |
+------+
5 rows in set (0.00 sec)
只要加上这个关键词,就是实现了去重的操作。
group by 子句(重点难点)
group by子句的作用:对数据进行分组操作,为什么要进行分组呢?分组的目标就是进行分组统计。
日常生活中的分组太多了,如按男女进行分组,按成绩进行分组,按院校、系部分组,按部门进行分组。
根据给定==数据列==的查询结果进行分组统计,最终得到一个==分组汇总表==
注:一般情况下group by需与==统计函数==一起使用才有意义
统计函数:
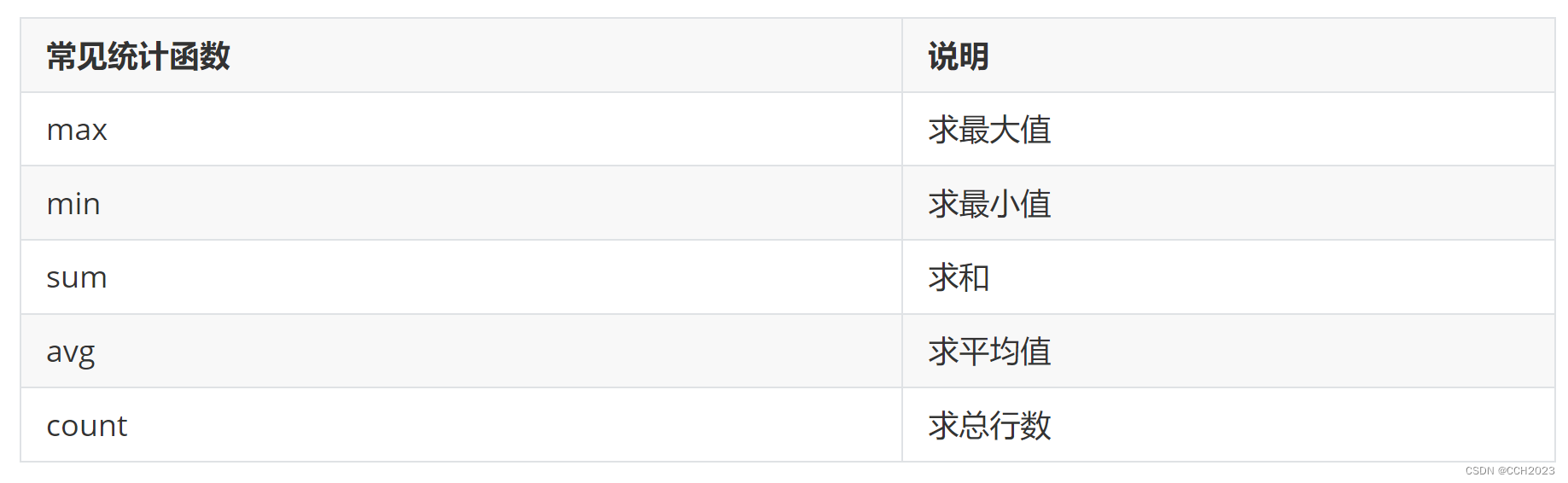
案例:求tb_student 表中应该有多少记录。
mysql> select count(*) from tb_student;
+----------+
| count(*) |
+----------+
| 6 |
+----------+
1 row in set (0.03 sec)
案例:求年龄的最大值和最小值。
mysql> select max(age) from tb_student;
+----------+
| max(age) |
+----------+
| 33 |
+----------+
1 row in set (0.00 sec)
mysql> select min(age) from tb_student;
+----------+
| min(age) |
+----------+
| 18 |
+----------+
1 row in set (0.00 sec)
案例:针对id字段求和。
mysql> select sum(id) from tb_student;
+---------+
| sum(id) |
+---------+
| 21 |
+---------+
1 row in set (0.00 sec)
案例:求年龄的平均值。
mysql> select avg(age) from tb_student;
+----------+
| avg(age) |
+----------+
| 24.3333 |
+----------+
1 row in set (0.00 sec)
GroupBy命令:实现数据的统计。
案例:求tb_student 男女同学的总数。
mysql> select gender,count(*) from tb_student group by gender;
+--------+----------+
| gender | count(*) |
+--------+----------+
| 男 | 3 |
| 女 | 3 |
+--------+----------+
2 rows in set (0.00 sec)
案例:求tb_student 中男同学的最大值与女同学的最大值。
mysql> select gender, max(age) from tb_student group by gender;
+--------+----------+
| gender | max(age) |
+--------+----------+
| 男 | 33 |
| 女 | 20 |
+--------+----------+
2 rows in set (0.00 sec)
group by的分组原理:
分组就是在内存分区域,然后分组,然后针对其中的每一列,然后进行统计。
记住:以后只要涉及到求每个学科、每个部门、每个年级、每个系部薪资最高、成绩最好、薪资的平均值等等,就是基于GROUP BY + 统计函数。
Having子句:
having与where类似,根据条件对==数据==进行过滤筛选
where==针对表中的列==发挥作用,查询数据
having==针对查询结果集==发挥作用,筛选数据
针对上次的查询结果再进行数据查询。执行两次查询。
mysql> select * from tb_student having age > 20;
+----+--------+------+--------+-----------------------+
| id | name | age | gender | address |
+----+--------+------+--------+-----------------------+
| 1 | 刘备 | 33 | 男 | 湖北省武汉市 |
| 3 | 关羽 | 32 | 男 | 湖北省荆州市 |
| 5 | 赵云 | 25 | 男 | 河北省石家庄市 |
+----+--------+------+--------+-----------------------+
3 rows in set (0.00 sec)
案例:按学科进行分组,求每个学科拥有多少人。
mysql> drop table tb_student;
Query OK, 0 rows affected (0.02 sec)
mysql> create table tb_student(
-> id mediumint not null auto_increment,
-> name varchar(20),
-> age tinyint unsigned default 0,
-> gender enum('男','女'),
-> subject enum('ui','java','yunwei','python'),
-> primary key(id)
-> ) engine=innodb default charset=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into tb_student values (null,'悟空',255,'男','ui'),(null,'八戒',250,'男','python'),(null,'唐僧',30,'男','yunwei'),(null,'沙僧',150,'男','java'),(null,'小白龙',100,'男','yunwei'),(null,'白骨精',28,'女','ui'),(null,'兔子精',22,'女','yunwei'),(null,'狮子精',33,'男','yunwei');
Query OK, 8 rows affected (0.00 sec)
Records: 8 Duplicates: 0 Warnings: 0
mysql> select * from tb_student;
+----+-----------+------+--------+---------+
| id | name | age | gender | subject |
+----+-----------+------+--------+---------+
| 1 | 悟空 | 255 | 男 | ui |
| 2 | 八戒 | 250 | 男 | python |
| 3 | 唐僧 | 30 | 男 | yunwei |
| 4 | 沙僧 | 150 | 男 | java |
| 5 | 小白龙 | 100 | 男 | yunwei |
| 6 | 白骨精 | 28 | 女 | ui |
| 7 | 兔子精 | 22 | 女 | yunwei |
| 8 | 狮子精 | 33 | 男 | yunwei |
+----+-----------+------+--------+---------+
8 rows in set (0.00 sec)
根据学科进行分组,求每个学科有多少人?
然后在这个基础上再次筛选学科人数大于3人的筛选。在查询基础上再次进行处理的,就只有having语句了。
mysql> select subject,count(*) from tb_student group by subject;
+---------+----------+
| subject | count(*) |
+---------+----------+
| ui | 2 |
| java | 1 |
| yunwei | 4 |
| python | 1 |
+---------+----------+
4 rows in set (0.00 sec)
mysql> select subject,count(*) from tb_student group by subject having count(*)>3;
+---------+----------+
| subject | count(*) |
+---------+----------+
| yunwei | 4 |
+---------+----------+
1 row in set (0.00 sec)
having语句是在原来分组操作之后,再次进行查询的操作。
Order by 子句:
其主要作用是对数据进行排序。
排序是两种:
升序(从小到大)
mysql> select * from 数据表名称 ... order by 字段名称 asc;
降序排列(从大到小)。
mysql> select * from 数据表名称 ... order by 字段名称 desc;
案例:按年龄进行排序(由小到大 ):
mysql> select * from tb_student order by age asc;
+----+-----------+------+--------+---------+
| id | name | age | gender | subject |
+----+-----------+------+--------+---------+
| 7 | 兔子精 | 22 | 女 | yunwei |
| 6 | 白骨精 | 28 | 女 | ui |
| 3 | 唐僧 | 30 | 男 | yunwei |
| 8 | 狮子精 | 33 | 男 | yunwei |
| 5 | 小白龙 | 100 | 男 | yunwei |
| 4 | 沙僧 | 150 | 男 | java |
| 2 | 八戒 | 250 | 男 | python |
| 1 | 悟空 | 255 | 男 | ui |
+----+-----------+------+--------+---------+
8 rows in set (0.00 sec)
mysql> select * from tb_student order by age desc;
+----+-----------+------+--------+---------+
| id | name | age | gender | subject |
+----+-----------+------+--------+---------+
| 1 | 悟空 | 255 | 男 | ui |
| 2 | 八戒 | 250 | 男 | python |
| 4 | 沙僧 | 150 | 男 | java |
| 5 | 小白龙 | 100 | 男 | yunwei |
| 8 | 狮子精 | 33 | 男 | yunwei |
| 3 | 唐僧 | 30 | 男 | yunwei |
| 6 | 白骨精 | 28 | 女 | ui |
| 7 | 兔子精 | 22 | 女 | yunwei |
+----+-----------+------+--------+---------+
8 rows in set (0.00 sec)
Limit子句:分页函数。
基本语法:
mysql> select * from 数据表名称 ... limit number; 查询满足条件的number条数据
或
mysql> select * from 数据表名称 ... limit offset,number; 从偏移量为offset开始查询,查询number条记录
offset的值从0开始案例:获取班级中年龄最大的学员信息。
mysql> select * from tb_student order by age desc limit 1;
+----+--------+------+--------+---------+
| id | name | age | gender | subject |
+----+--------+------+--------+---------+
| 1 | 悟空 | 255 | 男 | ui |
+----+--------+------+--------+---------+
1 row in set (0.00 sec)
案例:从偏移量为1的元素开始查询,查询2条记录。
mysql> select * from tb_student;
+----+-----------+------+--------+---------+
| id | name | age | gender | subject |
+----+-----------+------+--------+---------+
| 1 | 悟空 | 255 | 男 | ui |
| 2 | 八戒 | 250 | 男 | python |
| 3 | 唐僧 | 30 | 男 | yunwei |
| 4 | 沙僧 | 150 | 男 | java |
| 5 | 小白龙 | 100 | 男 | yunwei |
| 6 | 白骨精 | 28 | 女 | ui |
| 7 | 兔子精 | 22 | 女 | yunwei |
| 8 | 狮子精 | 33 | 男 | yunwei |
+----+-----------+------+--------+---------+
8 rows in set (0.00 sec)
mysql> select * from tb_student limit 1,2;
+----+--------+------+--------+---------+
| id | name | age | gender | subject |
+----+--------+------+--------+---------+
| 2 | 八戒 | 250 | 男 | python |
| 3 | 唐僧 | 30 | 男 | yunwei |
+----+--------+------+--------+---------+
2 rows in set (0.00 sec)
LIMIT子句在开发项目中,主要应用于数据分页。
案例:实现数据分页:
分页效果,找出下规律。
mysql> select * from tb_student limit 0,2;
+----+--------+------+--------+---------+
| id | name | age | gender | subject |
+----+--------+------+--------+---------+
| 1 | 悟空 | 255 | 男 | ui |
| 2 | 八戒 | 250 | 男 | python |
+----+--------+------+--------+---------+
2 rows in set (0.00 sec)
mysql> select * from tb_student limit 2,2;
+----+--------+------+--------+---------+
| id | name | age | gender | subject |
+----+--------+------+--------+---------+
| 3 | 唐僧 | 30 | 男 | yunwei |
| 4 | 沙僧 | 150 | 男 | java |
+----+--------+------+--------+---------+
2 rows in set (0.00 sec)
mysql> select * from tb_student limit 4,2;
+----+-----------+------+--------+---------+
| id | name | age | gender | subject |
+----+-----------+------+--------+---------+
| 5 | 小白龙 | 100 | 男 | yunwei |
| 6 | 白骨精 | 28 | 女 | ui |
+----+-----------+------+--------+---------+
2 rows in set (0.00 sec)
mysql> select * from tb_student limit 6,2;
+----+-----------+------+--------+---------+
| id | name | age | gender | subject |
+----+-----------+------+--------+---------+
| 7 | 兔子精 | 22 | 女 | yunwei |
| 8 | 狮子精 | 33 | 男 | yunwei |
+----+-----------+------+--------+---------+
2 rows in set (0.00 sec)
分页操作是程序员使用得比较多的。



![web:[极客大挑战 2019]Knife](https://img-blog.csdnimg.cn/c02023dce7804d7c9c2973bda63cd26d.png)