前言
在搜索/推荐场景中(一般是CTR/CVR预估)Serving的模型一般是稀疏参数占比比较大,工程落地方面会遇到两方面的困难:
- 稀疏参数的存储/IO
- 网络结构的优化
对于稀疏参数的存储/IO,在上一篇【深度学习推荐系统 工程篇】二、从TF-Serving看生产环境的模型推理服务 有提及,这篇是想总结下 网络结构的优化
本篇借助分析FasterTransformer框架,看Transformer在工程落地中需要做什么样的优化,然后总结一些通用的优化思路
读完这篇文章,希望读者可以:
- 了解FasterTransformer整体框架以及流程
- 了解推理过程中GPU的优化思路和方法
一、Transformer算法理论基础
关于Transformer的网络结构,网上都有了各种分析,但大多良莠不齐,随便找一个看大概率容易一头雾水;
1.1 Transformer相关资料
这里分享下找到比较优秀的资料:
- Transformer原论文:https://arxiv.org/abs/1706.03762
- 李沐精读论文:https://www.bilibili.com/video/BV1pu411o7BE/
- Transformer详解:http://jalammar.github.io/illustrated-transformer/
- Harvard NLP 团队用Pytorch实现Transformer:http://nlp.seas.harvard.edu/annotated-transformer/
- Tensor2Tensor代码:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
看完这几个,基本可以对Transformer的结构有大致的了解。
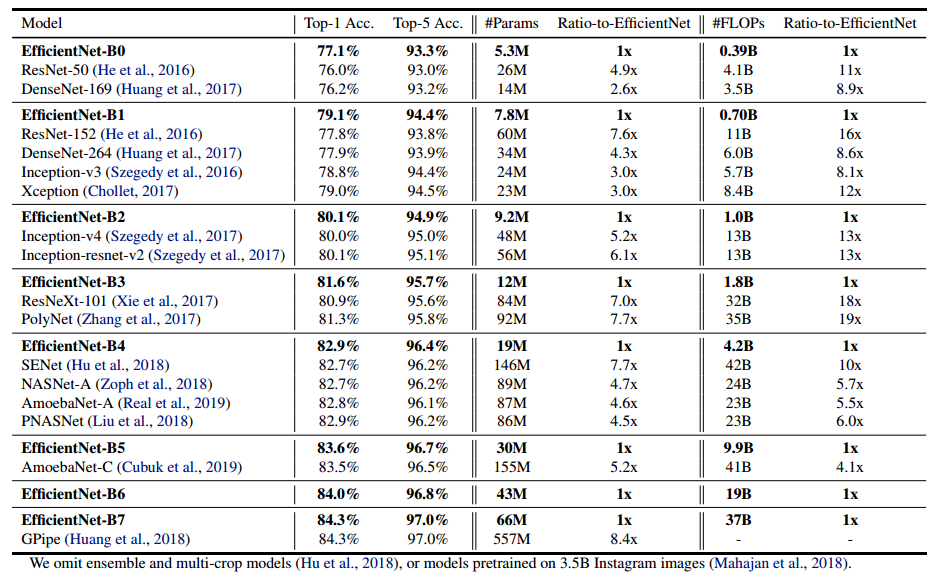
1.2 理论计算复杂度
如果想要进行工程落地,最好对Transformer理论上的计算复杂度有个大概了解;
在实际推理过程中,假设输入的BatchSize为 M M M,每条的SequenceLength为 N N N,
网络的hidden_dim为 D D D,Encoder个数为 e n c o d e r _ s i z e encoder\_size encoder_size,Decoder的个数为 d e c o d e r _ s i z e decoder\_size decoder_size;
一次推理的计算复杂度:
O ( M N ˙ 2 D ˙ ) ∗ ( e n c o d e r _ s i z e + d e c o d e r _ s i z e ) O(M \dot N^2 \dot D) * (encoder\_size +decoder\_size) O(MN˙2D˙)∗(encoder_size+decoder_size)
PS:计算量的大头 是 Attention结构中QKV的计算
二、浅析FastTransformer框架
2.1 框架目录
本次分析FastTransformer源码是v5.0版本,项目地址:https://github.com/NVIDIA/FasterTransformer
项目框架比较清晰,将Attention结构封装成Layer,内部再实现调用高度优化的kernel函数
目录结构如下:
/src/fastertransformer: source code of FasterTransformer
|–/models: Implementation of different models, like BERT, GPT.(常用网络的实现)
|–/layers: Implementation of layer modeuls, like attention layer, ffn layer.(封装成Layer模块,如attention/ffn等结构)
|–/kernels: CUDA kernels for different models/layers and operations, like addBiasResiual.(CUDA Kernel算子实现,一般在layer中调用)
|–/tf_op: custom Tensorflow OP implementation(封装成TensorflowOp)
|–/th_op: custom PyTorch OP implementation(封装成PytorchOp)
|–/triton_backend: custom triton backend implementation()
|–/utils: Contains common cuda utils, like cublasMMWrapper, memory_utils(封装成的工具类,如cublas参数,Allocator接口,Tensor接口)
上述目录中,最重要的是layers和kernels,layer抽象了计算流程,kernel给出了高效实现;
在Transformer结构中,两个重要的layer就是AttentionLayer和FFNLayer,这里画了类图整理下层次关系:
Attention layer:

FFN layer:

整体层次比较简单,下面以Example里的Bert模型为例,看下Forward流程
2.2 Bert模型的Forward流程
相应的代码在:https://github.com/NVIDIA/FasterTransformer/blob/release/v5.0_tag/src/fastertransformer/models/bert/Bert.h
相应的文档:https://github.com/NVIDIA/FasterTransformer/blob/release/v5.0_tag/docs/bert_guide.md
Bert模型主要包括 AttentionLayer和FFNLayer,可通过参数配置具体实现:
// Attention Layer
enum class AttentionType
{
UNFUSED_MHA,
UNFUSED_PADDED_MHA,
FUSED_MHA,
FUSED_PADDED_MHA
};
// FFN Layer
enum ActivationType
{
Gelu,
Relu
};
Bert模型的一次Forward流程:

2.3 Forward流程中的优化思路
2.3.1 流程优化(Remove Padding)
在这个文档中 https://github.com/NVIDIA/FasterTransformer/blob/release/v5.0_tag/docs/bert_guide.md 给出了去除Padding的流程图,
一个Batch中,对于没有达到MaxSeqLen的输入,一般会进行padding,补齐到MaxSeqLen,但显而易见会引入不必要的计算;
Effective-transformer 引入segment offset数组来去除Padding;FasterTransformer把这个优化集成到了项目中
2.3.2 OpFusion
OpFusion是网络结构优化中常见的手段,主要是以下几点目标:
- 减少 Kernel Launch 次数以及开销
- 在CPU/GPU异构架构中,如果部分算子仅有CPU实现的话会造成频繁的H2D/D2H,用GPU实现相应的cpu算子逻辑,可以避免HostMem,DeviceMem互相拷贝
- 即使相邻的两个Op均有GPU实现,融合成一个算子,也可以减少计算结果显存读写的开销(否则需要先写回GlobalMemory,再从GlobalMemory读
回到FastTransformer,它将琐碎的操作尽可能的合并成一个Kernel;
PS:Tensorflow框架的一个特点是算子比较琐碎,一个操作经常由多个基础算子组成,因此针对Tensorflow的模型,OpFusion几乎是上线推理前必做的优化手段
2.3.3 优化Gemm
这里主要有几点:
- 对QKV计算,调用Gemm或者BatchedGemm
- FP16/FP32分别调用不同的gemm api接口(fp32 use cublas as default,fp16 use cublasLt as default)
- AutoTunning
这里想分享2点:
一个是NV的线性计算库
看代码的时候发现用到Blas库比较多,除了基础的cublas接口,还有cuBlasLT,cuBlasXT等等,特意查了下资料:
- cuBlas/cuBlasLT简单的介绍和区别:https://developer.nvidia.com/blog/new-cublas-12-0-features-and-matrix-multiplication-performance-on-nvidia-hopper-gpus/
- cuBLas的官方API:https://docs.nvidia.com/cuda/cublas/index.html
二是针对Gemm/Kernel函数的AutoTunning思路
背景:由于GPU架构的复杂性,没有一组通用的参数,可以让某一操作 在所有数据规模/硬件 上达到最优的性能
在这种限制下,一种可能的做法 是将可调的参数独立出来组成参数空间(如 O ( b a t c h _ s i z e , m , n , k , d a t a _ t y p e ) O(batch\_size, m, n, k, data\_type) O(batch_size,m,n,k,data_type) 这几个参数够成了参数空间),在上线前,针对线上的真实请求,遍历参数空间中的性能指标,挑出最优的一组 写到 config文件里 使用;
适用的场景不仅包括Gemm,也可以对Kernel函数的BlockSize, ThreadSize进行调整
2.3.4 低精度优化
- 使用half2类型,进行向量化读取操作,在相同的指令周期内处理更多数据(类似于CPU上的AVX指令集操作),提升吞吐
- FP16发挥硬件TensorCore的能力,加速计算
关于half2,额外找了些资料:
half2提升数据读取:https://developer.nvidia.com/blog/cuda-pro-tip-increase-performance-with-vectorized-memory-access/
关于half2与half的区别:https://forums.developer.nvidia.com/t/half2-vs-half-datatype/219492/3
另外关于低精度还想再分享一点,就是能降存储,
最近比较火的大模型动辄上百亿参数,很难进行进行单机加载(近期发布的BaiChuan-13B,模型大小约30GB),
如果想在显存较小的显卡上加载,只能尝试低精度的方式(FP16或量化)降低数据存储(不过会影响网络精度,需要客观评估带来的业务影响)
2.3.5 高效的Kernel函数实现
项目中Kernel函数上都实现的很高效,如Reduce操作,都可以当做CUDA编程例子来学,
主要的点:
- shared_memory 加速读取
- __ldg缓存的使用
- #pragma unroll
- half2/INT8 低精度实现
三、GPU 推理优化思路
3.1 GPU推理存在的问题
谈问题之前,我们首先设想一个能充分发挥GPU算力的完美推理框架,它应该是这样
- 几乎没有Kernel lanuch开销(NVProf中Kernel之间没有空隙),最好所有的操作都能在一个Kernel中完成
- 接近全部的时间都用在 计算 上,达到硬件算力指标
但实际情况中,:
- Kernel Lanuch开销总是存在
- 永远会有访存的开销(尤其GPU中的GlobalMemory / SharedMemory 访问差了一个数量级,使得访存可能成为计算的瓶颈)
这些问题是GPU硬件架构 客观决定的,所以我们的优化工作只能是尽力缓解,然后去逼近理论计算的上限
3.2 可能的优化思路
针对上面提到的问题,我们可以总结下可能优化思路(在2.3中已经提到):
- 流程优化
- OpFusion
- Gemm优化
- 低精度优化
- 高效的Kernel实现
基本上涵盖了可能的思路
3.3 “No silver bullet”(没有银弹)
另外对于模型的优化,笔者想借助软件工程的一句经典名言来发表下自己的想法:“No sliver bullet”,
即优化框架的通用性 和 极致性能很难兼得,没有一种框架可以对 现在所有的网络结构以及未来可能出现的结构 提供极致的优化;
优化 的 过程永远是 螺旋式的迭代前进,即
- 新的网络结构(算法)
- Perf分析热点,进行可能优化,抽出通用的部分作为框架(工程)
- 新的网络结构(算法)
- Perf分析热点,进行可能优化,抽出通用的部分作为框架(工程)
- …

![web:[极客大挑战 2019]Knife](https://img-blog.csdnimg.cn/c02023dce7804d7c9c2973bda63cd26d.png)