一、前言
在深度学习中,数据量通常是都非常多,非常大的,如此大量的数据,不可能一次性的在模型中进行向前的计算和反向传播,经常我们会对整个数据进行随机的打乱顺序,把数据处理成一个个的batch,同时还会对数据进行预处理。
所以,接下来我们来学习pytorch中的数据加载的方法。
二、数据集类
2.1、Dataset基类
在torch中提供了数据集的基类torch.utils.data.Dataset,继承这个基类,我们能够非常快速的实现对数据的加载。
torch.utils.data.Dataset的源码如下:
class Dataset(object):
"""An abstract class representing a Dataset.
All other datasets should subclass it. All subclasses should override
``__len__``, that provides the size of the dataset, and ``__getitem__``,
supporting integer indexing in range from 0 to len(self) exclusive.
"""
def __getitem__(self, index):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
def __add__(self, other):
return ConcatDataset([self, other])
我们需要在自定义的数据集类中继承Dataset类,同时还需要实现两个方法:
__len__方法,能够实现通过全局的len()方法获取其中的元素个数__getitem__方法,能够通过传入索引的方式获取数据,例如通过dataset[i]获取其中的第i条数据__add__方法不用实现,它是将多条数据合并
2.2、例子
下面通过一个例子来看看如何使用Dataset来加载数据
数据来源:http://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
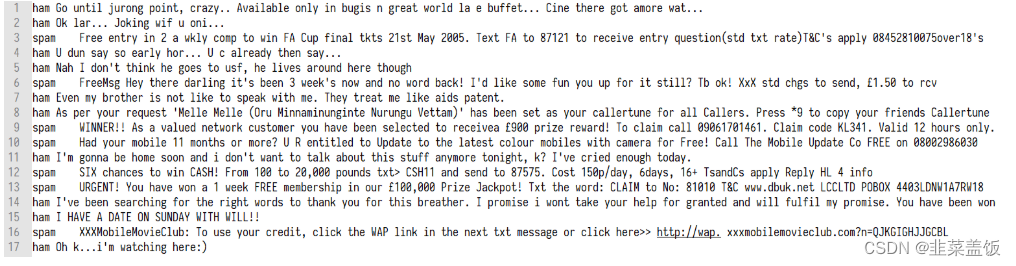
数据介绍:SMS Spam Collection是用于骚扰短信识别的经典数据集,完全来自真实短信内容,包括4831条正常短信和747条骚扰短信。正常短信和骚扰短信保存在一个文本文件中。 每行完整记录一条短信内容,每行开头通过ham和spam标识正常短信和骚扰短信
数据实例:
代码如下:
from torch.utils.data import Dataset
data_path = r"D:\djangoProject\practice\SMSSpamCollection"
#定义数据集类
class MyDataset(Dataset): #继承Dataset类
def __init__(self):
self.lines = open(data_path,encoding='utf-8').readlines()
def __getitem__(self, index):
#获取索引对应位置的一条数据
#将标签和文本分开
cur_line = self.lines[index].strip()
label = cur_line[:4].strip() #strip()为了去点换行符
content = cur_line[4:].strip()
return label,content #返回元组的形式
def __len__(self):
#返回数据总量
return len(self.lines)
if __name__ == '__main__':
my_data = MyDataset()
print((my_data[0]))
print(len(my_data))
效果如下:

三、数据加载器
使用上述的方法能够进行数据的读取,但是其中还有很多内容没有实现:
- 批处理数据(Batching the data)
- 打乱数据(Shuffling the data)
- 使用多线程
multiprocessing并行加载数据。
在pytorch中torch.utils.data.DataLoader提供了上述的所用方法
DataLoader的使用方法示例:
我们将上述代码进行修改
from torch.utils.data import Dataset,DataLoader
data_path = r"D:\djangoProject\practice\SMSSpamCollection"
#定义数据集类
class MyDataset(Dataset): #继承Dataset类
def __init__(self):
self.lines = open(data_path,encoding='utf-8').readlines()
def __getitem__(self, index):
#获取索引对应位置的一条数据
#将标签和文本分开
cur_line = self.lines[index].strip()
label = cur_line[:4].strip() #strip()为了去点换行符
content = cur_line[4:].strip()
return label,content #返回元组的形式
def __len__(self):
#返回数据总量
return len(self.lines)
my_data = MyDataset()
data_load = DataLoader(dataset=my_data,batch_size=2,shuffle=True,num_workers=2) #使用数据加载器
if __name__ == '__main__':
#两次的数据都不一样 是因为shuffle的原因,打乱了数据的顺序
for i in data_load:
print(i)
break
for i in data_load:
print(i)
break
其中参数含义:
dataset:提前定义的dataset的实例batch_size:传入数据的batch的大小,常用128,256等等shuffle:bool类型,表示是否在每次获取数据的时候提前打乱数据num_workers:加载数据的线程数
效果如下:
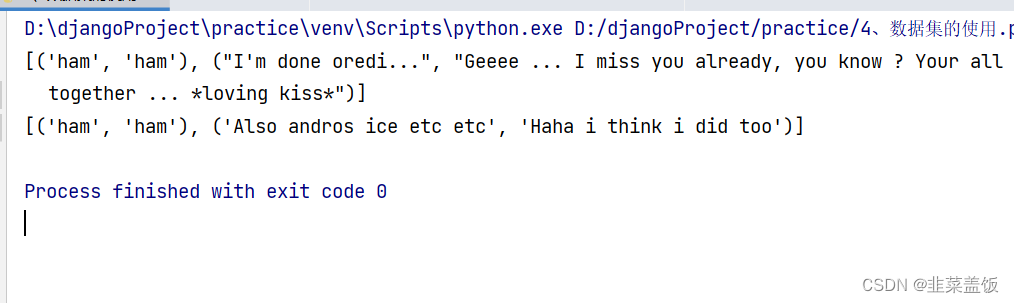
两次索引一样,单打印的数据是不一样的,因为使用shuffle打乱了数据,且每个元组的大小为2,是batch_size为2的原因