题目:找树左下角的值
- 给定一个二叉树的 根节点
root,请找出该二叉树的 最底层 最左边 节点的值。假设二叉树中至少有一个节点。
题解
-
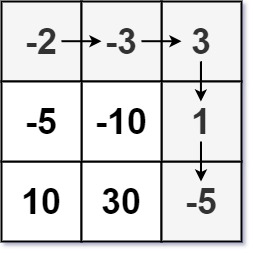
使用 height 记录遍历到的节点的高度,curVal 记录高度在 curHeight 的最左节点的值。在深度优先搜索时,我们先搜索当前节点的左子节点,再搜索当前节点的右子节点,然后判断当前节点的高度 height 是否大于 curHeight,如果是,那么将 curVal 设置为当前结点的值,curHeight 设置为 height。因为我们先遍历左子树,然后再遍历右子树,所以对同一高度的所有节点,最左节点肯定是最先被遍历到的。
-
class Solution { public: void dfs(TreeNode *root,int height,int &curval,int &curheight){ if(root==nullptr){ return; } height++; dfs(root->left,height,curval,curheight); dfs(root->right,height,curval,curheight); if(height>curheight){ curheight=height; curval=root->val; } } int findBottomLeftValue(TreeNode* root) { int curval=0,curheight=0; dfs(root,0,curval,curheight); return curval; } }; -
时间复杂度:O(n),其中 nnn 是二叉树的节点数目。需要遍历 n 个节点。空间复杂度:O(n)。递归栈需要占用 O(n) 的空间。
-
使用广度优先搜索遍历每一层的节点。在遍历一个节点时,需要先把它的非空右子节点放入队列,然后再把它的非空左子节点放入队列,这样才能保证从右到左遍历每一层的节点。广度优先搜索所遍历的最后一个节点的值就是最底层最左边节点的值。
-
int findBottomLeftValue(TreeNode* root) { int ret; queue<TreeNode*> temp_que; temp_que.push(root); while(!temp_que.empty()){ auto p=temp_que.front(); temp_que.pop(); if(p->right){ temp_que.push(p->right); } if(p->left){ temp_que.push(p->left); } ret=p->val; } return ret; } -
时间复杂度:O(n),其中 n 是二叉树的节点数目。空间复杂度:O(n)。如果二叉树是满完全二叉树,那么队列 temp_que 最多保存 ⌈ n 2 ⌉ \big \lceil \dfrac{n}{2} \big \rceil ⌈2n⌉ 个节点。
题目:路径总和
- 给你二叉树的根节点
root和一个表示目标和的整数targetSum。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和targetSum。如果存在,返回true;否则,返回false。叶子节点 是指没有子节点的节点。
题解
-
可以使用深度优先遍历的方式(本题前中后序都可以,无所谓,因为中节点也没有处理逻辑)来遍历二叉树。
-
确定递归函数的参数和返回类型:参数:需要二叉树的根节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。再来看返回值,递归函数什么时候需要返回值?什么时候不需要返回值?这里总结如下三点:
-
如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。
-
如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。
-
如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。
-

-
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。
-
-
确定终止条件:不要去累加然后判断是否等于目标和,那么代码比较麻烦,可以用递减,让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。如果遍历到了叶子节点,count不为0,就是没找到。
-
确定单层递归的逻辑:因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
-
class Solution { public: bool traversal(TreeNode* cur,int count){ if(!cur->left&&!cur->right&&count==0){ return true; } if(!cur->left&&!cur->right){ return false; } if(cur->left){ count-=cur->left->val; if(traversal(cur->left,count)){ return true; } count+=cur->left->val; } if(cur->right){ count-=cur->right->val; if(traversal(cur->right,count)){ return true; } count+=cur->right->val; } return false; } bool hasPathSum(TreeNode* root, int targetSum) { if(root==nullptr){ return false; } return traversal(root,targetSum-root->val); } };
-
-
解法二:首先我们可以想到使用广度优先搜索的方式,记录从根节点到当前节点的路径和,以防止重复计算。这样我们使用两个队列,分别存储将要遍历的节点,以及根节点到这些节点的路径和即可。
-
bool hasPathSum(TreeNode* root, int targetSum) { if(root==nullptr){ return false; } queue<TreeNode*> temp_que_node; queue<int> temp_que_int; temp_que_node.push(root); temp_que_int.push(root->val); while(!temp_que_node.empty()){ TreeNode *temp_node=temp_que_node.front(); int temp_int=temp_que_int.front(); temp_que_node.pop(); temp_que_int.pop(); if(temp_node->left==nullptr&&temp_node->right==nullptr){ if(temp_int==targetSum){ return true; } continue; } if(temp_node->left!=nullptr){ temp_que_node.push(temp_node->left); temp_que_int.push(temp_node->left->val+temp_int); } if(temp_node->right!=nullptr){ temp_que_node.push(temp_node->right); temp_que_int.push(temp_node->right->val+temp_int); } } return false; } -
时间复杂度:O(N),其中 N 是树的节点数。对每个节点访问一次。空间复杂度:O(N),其中 N 是树的节点数。空间复杂度主要取决于队列的开销,队列中的元素个数不会超过树的节点数。
-
题目:从中序与后序遍历序列构造二叉树
- 给定两个整数数组
inorder和postorder,其中inorder是二叉树的中序遍历,postorder是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
题解
-
以 后序数组的最后一个元素为切割点,先切中序数组,根据中序数组,反过来再切后序数组。一层一层切下去,每次后序数组最后一个元素就是节点元素。
-

-
来看一下一共分几步:
- 第一步:如果数组大小为零的话,说明是空节点了。
- 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
- 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点。
- 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)。
- 第五步:切割后序数组,切成后序左数组和后序右数组。
- 第六步:递归处理左区间和右区间
-
class Solution { public: TreeNode* traversal(vector<int>& inorder,vector<int>& postorder){ if(postorder.size()==0){ return nullptr; } int rootval=postorder[postorder.size()-1]; TreeNode* root=new TreeNode(rootval); if(postorder.size()==1){ return root; } int delimiterindex; for(delimiterindex=0;delimiterindex<inorder.size();delimiterindex++){ if(inorder[delimiterindex]==rootval){ break; } } vector<int> leftinorder(inorder.begin(),inorder.begin()+delimiterindex); vector<int> rightinorder(inorder.begin()+1+delimiterindex,inorder.end()); postorder.resize(postorder.size()-1); vector<int> leftpostorder(postorder.begin(),postorder.begin()+leftinorder.size()); vector<int> rightpostorder(postorder.begin()+leftinorder.size(),postorder.end()); root->left=traversal(leftinorder,leftpostorder); root->right=traversal(rightinorder,rightpostorder); return root; } TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { if(inorder.size()==0||postorder.size()==0) return nullptr; return traversal(inorder,postorder); } }; -
首先解决这道题我们需要明确给定一棵二叉树,我们是如何对其进行中序遍历与后序遍历的:
-
中序遍历的顺序是每次遍历左孩子,再遍历根节点,最后遍历右孩子。
-
后序遍历的顺序是每次遍历左孩子,再遍历右孩子,最后遍历根节点。
-
void inorder_fun(TreeNode* node){//中序遍历 if(root==nullptr){ return; } inorder_fun(root->left); queue<TreeNode*> temp_que; temp_que.push_back(root->val); inorder_fun(root->right); } void postorder_fun(TreeNode* node){//后序遍历 if(root==nullptr){ return; } postorder_fun(root->left); postorder_fun(root->right); queue<TreeNode*> temp_que; temp_que.push_back(temp_que); }
-
-
因此根据上文所述,我们可以发现后序遍历的数组最后一个元素代表的即为根节点。知道这个性质后,我们可以利用已知的根节点信息在中序遍历的数组中找到根节点所在的下标,然后根据其将中序遍历的数组分成左右两部分,左边部分即左子树,右边部分为右子树,针对每个部分可以用同样的方法继续递归下去构造。
-
为了高效查找根节点元素在中序遍历数组中的下标,我们选择创建哈希表来存储中序序列,即建立一个(元素,下标)键值对的哈希表。定义递归函数
helper(in_left, in_right)表示当前递归到中序序列中当前子树的左右边界,递归入口为helper(0, n - 1):-
如果
in_left > in_right,说明子树为空,返回空节点。 -
选择后序遍历的最后一个节点作为根节点。
-
利用哈希表 O(1) 查询当根节点在中序遍历中下标为 index。从 in_left 到 index - 1 属于左子树,从 index + 1 到 in_right 属于右子树。
-
根据后序遍历逻辑,递归创建右子树 和左子树 。 注意这里有需要先创建右子树,再创建左子树的依赖关系。 可以理解为在后序遍历的数组中整个数组是先存储左子树的节点,再存储右子树的节点,最后存储根节点,如果按每次选择「后序遍历的最后一个节点」为根节点,则先被构造出来的应该为右子树。helper(index + 1, in_right);helper(in_left, index - 1)。
-
返回根节点
root。 -
class Solution { int post_index; unordered_map<int,int> idx_map; public: TreeNode* helper(int in_left,int in_right,vector<int>& inorder,vector<int>& postorder){ if(in_left>in_right){ return nullptr; } int rootval=postorder[post_index]; TreeNode* root = new TreeNode(rootval); int index=idx_map[rootval];// 根据 root 所在位置分成左右两棵子树 post_index--; root->right=helper(index+1,in_right,inorder,postorder); root->left=helper(in_left,index-1,inorder,postorder); return root; } TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) { post_index=postorder.size()-1; int idx=0; for(auto &val:inorder){ idx_map[val]=idx++; } return helper(0,(int)inorder.size()-1,inorder,postorder); } }; -
时间复杂度:O(n),其中 n 是树中的节点个数。空间复杂度:O(n)。我们需要使用 O(n) 的空间存储哈希表,以及 O(h)(其中 h 是树的高度)的空间表示递归时栈空间。这里 h<n,所以总空间复杂度为 O(n)。
-
题目:从前序与中序遍历序列构造二叉树
- 给定两个整数数组
preorder和inorder,其中preorder是二叉树的先序遍历,inorder是同一棵树的中序遍历,请构造二叉树并返回其根节点。
题解
-
前序和中序可以唯一确定一棵二叉树。后序和中序可以唯一确定一棵二叉树。前序和后序不能唯一确定一棵二叉树!,因为没有中序遍历无法确定左右部分,也就是无法分割。
-
二叉树前序遍历的顺序为:先遍历根节点;随后递归地遍历左子树;最后递归地遍历右子树。[ 根节点, [左子树的前序遍历结果], [右子树的前序遍历结果] ]
-
二叉树中序遍历的顺序为:先递归地遍历左子树;随后遍历根节点;最后递归地遍历右子树。[ [左子树的中序遍历结果], 根节点, [右子树的中序遍历结果] ]
-
在「递归」地遍历某个子树的过程中,我们也是将这颗子树看成一颗全新的树,按照上述的顺序进行遍历。挖掘「前序遍历」和「中序遍历」的性质,我们就可以得出本题的做法。
-
只要我们在中序遍历中定位到根节点,那么我们就可以分别知道左子树和右子树中的节点数目。由于同一颗子树的前序遍历和中序遍历的长度显然是相同的,因此我们就可以对应到前序遍历的结果中,对上述形式中的所有左右括号进行定位。
-
这样以来,我们就知道了左子树的前序遍历和中序遍历结果,以及右子树的前序遍历和中序遍历结果,我们就可以递归地对构造出左子树和右子树,再将这两颗子树接到根节点的左右位置。
-
在中序遍历中对根节点进行定位时,一种简单的方法是直接扫描整个中序遍历的结果并找出根节点,但这样做的时间复杂度较高。我们可以考虑使用哈希表来帮助我们快速地定位根节点。对于哈希映射中的每个键值对,键表示一个元素(节点的值),值表示其在中序遍历中的出现位置。在构造二叉树的过程之前,我们可以对中序遍历的列表进行一遍扫描,就可以构造出这个哈希映射。在此后构造二叉树的过程中,我们就只需要 O(1)O(1)O(1) 的时间对根节点进行定位了。
-
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode *right; * TreeNode() : val(0), left(nullptr), right(nullptr) {} * TreeNode(int x) : val(x), left(nullptr), right(nullptr) {} * TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {} * }; */ class Solution { unordered_map<int,int> index; public: TreeNode* mytree(const vector<int>& preorder,const vector<int>& inorder,int preorder_left,int preorder_right,int inorder_left,int inorder_right){ if(preorder_left>preorder_right){ return nullptr; } // 前序遍历中的第一个节点就是根节点 int preorder_root=preorder_left; // 在中序遍历中定位根节点 int inorder_root=index[preorder[preorder_root]]; // 先把根节点建立出来 TreeNode* root=new TreeNode(preorder[preorder_root]); int size_lefttree=inorder_root-inorder_left; // 递归地构造左子树,并连接到根节点 // 先序遍历中「从 左边界+1 开始的 size_lefttree」个元素就对应了中序遍历中「从 左边界 开始到 根节点定位-1」的元素 root->left=mytree(preorder,inorder,preorder_left+1,preorder_left+size_lefttree,inorder_left,inorder_root-1); // 递归地构造右子树,并连接到根节点 // 先序遍历中「从 左边界+1+左子树节点数目 开始到 右边界」的元素就对应了中序遍历中「从 根节点定位+1 到 右边界」的元素 root->right=mytree(preorder,inorder,preorder_left+size_lefttree+1,preorder_right,inorder_root+1,inorder_right); return root; } TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) { int n=preorder.size(); for(int i=0;i<n;i++){ index[inorder[i]]=i; } return mytree(preorder,inorder,0,n-1,0,n-1); } };- 时间复杂度:O(n),其中 n 是树中的节点个数。空间复杂度:O(n),除去返回的答案需要的 O(n) 空间之外,我们还需要使用 O(n) 的空间存储哈希映射,以及 O(h)(其中 h 是树的高度)的空间表示递归时栈空间。这里 h<n,所以总空间复杂度为 O(n)。