读高性能MySQL(第4版)笔记14_备份与恢复(中)
news2026/3/20 21:15:59
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1033463.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
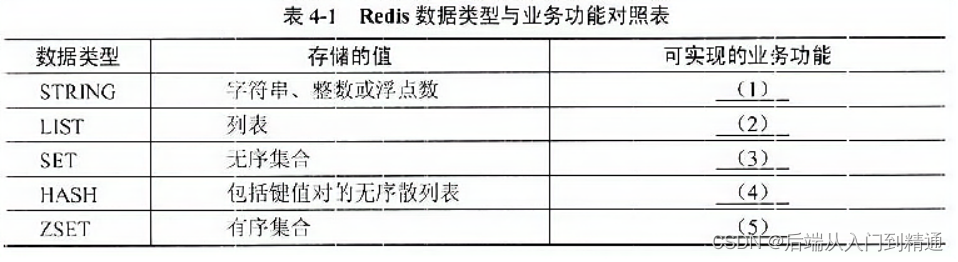
Redis淘汰策略-架构案例2020(三十六)
上篇案例回顾:
解释器,管道过滤,隐式调用优缺点?
解释器 则是独立的语法规则,可以通过解释器来解析,可扩展性很高,灵活性强。
管道过滤则是侧重于数据的输入和输出,上一个模块的数…

2023.9.20 简单了解 HTTP协议 及 Fiddle 安装使用
目录
HTTP 协议基本概念
Fiddle 下载
HTTP 请求格式 HTTP 响应格式 HTTP 协议基本概念 应用层使用最广泛的协议浏览器 基于 HTTP协议 获取网站是 浏览器 和 服务器 之间的交互桥梁HTTP协议 基于传输层的 TCP协议 实现HTTP 全称为 HyperText Transfer Protocol,中…

Java IO流实现文件复制
目录
前言
文件复制底层逻辑 代码实现
编辑 重点!!!
完整代码 改善思考 前言
Windows文件复制时我们是使用Ctrl C复制Ctrl V粘贴,上一篇文章Java基础入门对存储文件的相关操作
我们学习了Java IO流对文件的读写操作&…

数据结构--排序(1)
文章目录 排序概念直接插入排序希尔排序冒泡排序堆排序选择排序验证不同排序的运行时间 排序概念
排序指的是通过某一特征关键字(如信息量大小,首字母等)来对一连串的数据进行重新排列的操作,实现递增或者递减的数据排序。
稳定…
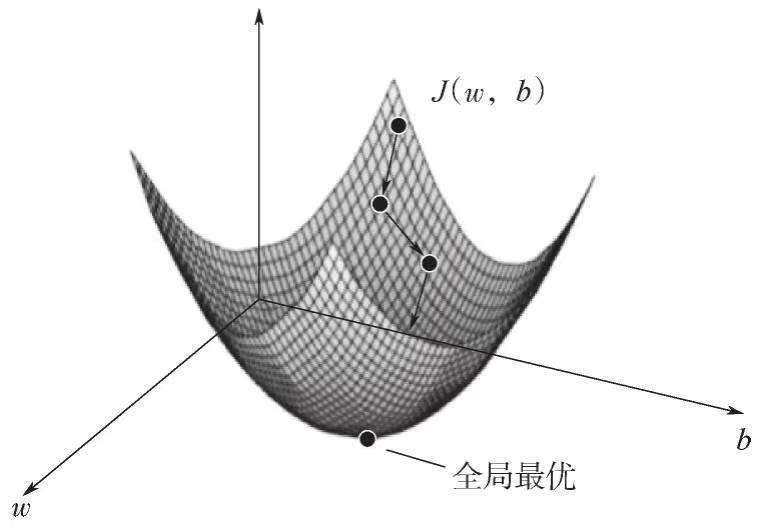
深度学习自学笔记二:逻辑回归和梯度下降法
目录 一、逻辑回归
二、逻辑回归的代价函数
三、梯度下降法 一、逻辑回归
逻辑回归是一种常用的二分类算法,用于将输入数据映射到一个概率输出,表示为属于某个类别的概率。它基于线性回归模型,并使用了sigmoid函数作为激活函数。
假设我们…
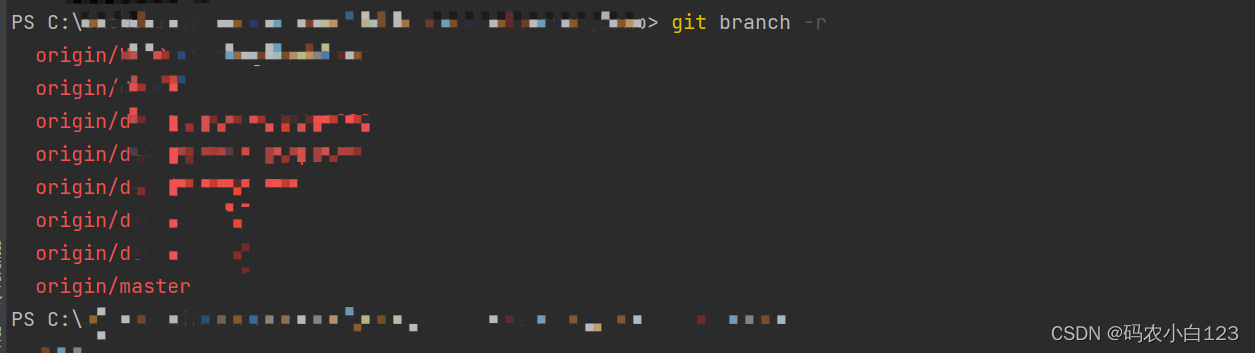
Git_06_创建分支/查看分支
创建分支
# 创建分支的同时,切换到该分支上
> git checkout -b 分支名称
#
> git push origin 分支名称查看分支
# 查看本地分支
> git branch
# 查看远程分支
> git branch -r
# 查看所有分支
> git branch -a删除分支
# 删除本地分支
> git …
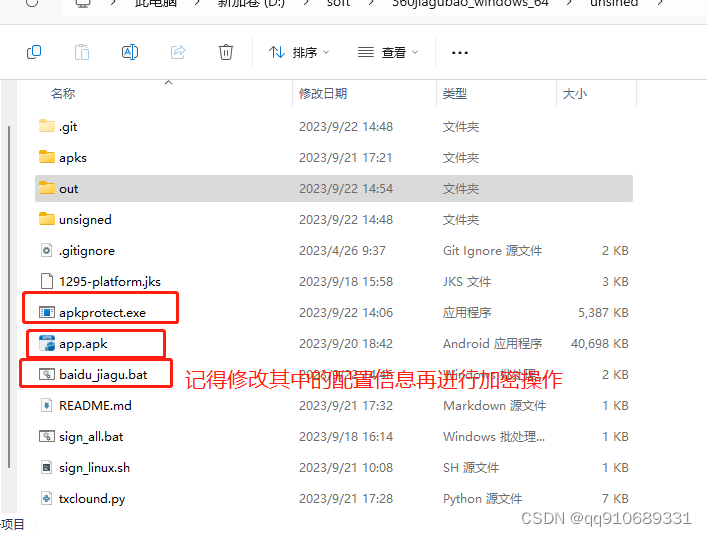
app一键加固加签名脚本 百度加固 window版本
echo off
setlocal enabledelayedexpansionset KEYSTORE_PATH*.jks
set KEYSTORE_PASSWORD*
set KEY_ALIAS*
set KEY_PASSWORD*set OUTPUT_DIR%cd%\out
set UNSIGNED_DIR%cd%\unsignedREM 设置加固工具的路径和密钥
set APKPROTECT_PATH"apkprotect"
set AKEY替换成你…
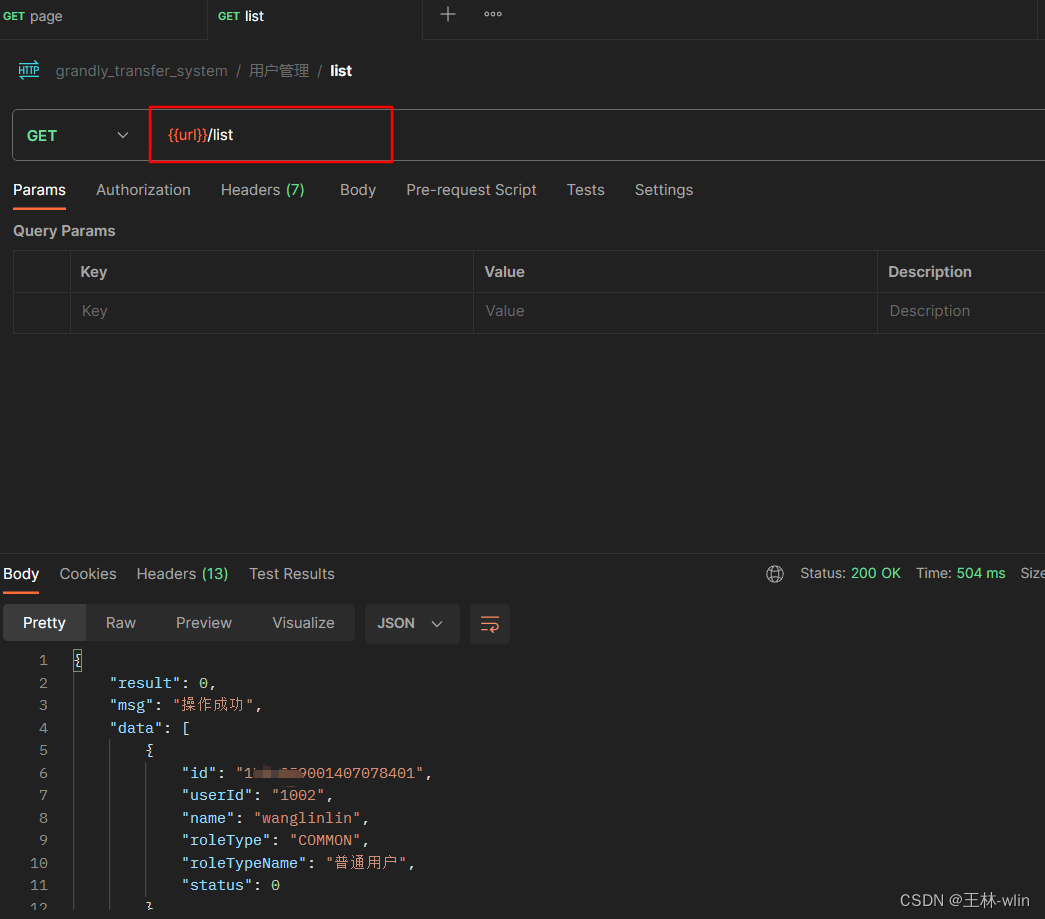
Postman 全局配置接口路径变量等
Postman 全局配置接口路径变量等
一、简介 这里主要是介绍通过配置postman接口测试工具,简化每次新增模块等接口时修改url的繁琐过程,方便以后查阅!!! 二、全局变量设置
1、新增测试环境 新增测试环境 2、接口集合设…
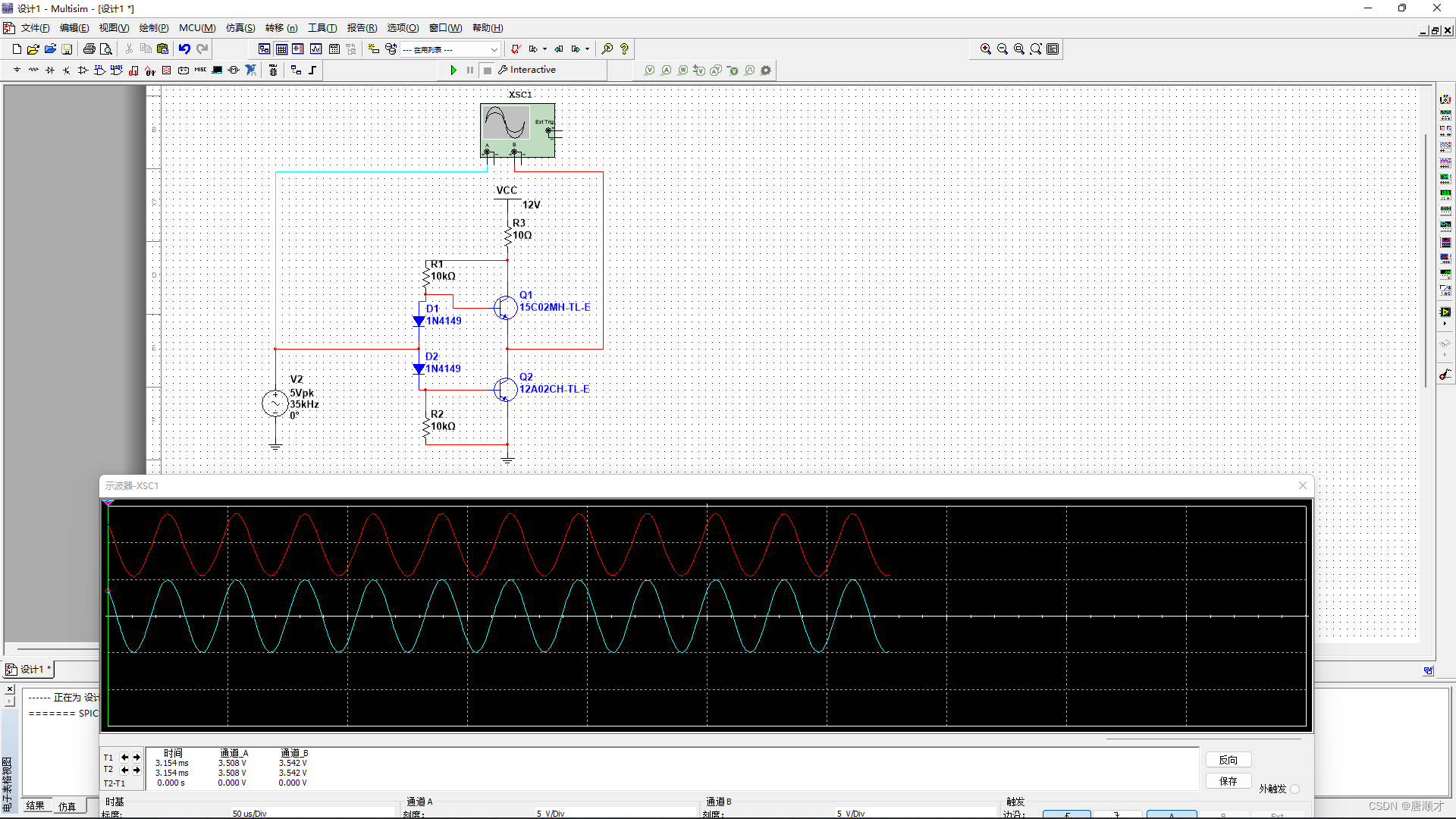
上N下P三极管推挽电路----》交越失真问题的解决
交越失真现象: 波形失真原因: 三极管的导通条件是Vbe > 0.7V,在正弦波驱动波形介于-0.7v ~ 0.7v之间时,上N管子截止、下P管子也截止,此时波形失真。 (关于三极管的伏安特性曲线、米勒效应,请自行百度)
…
UOS Deepin Linux 安装 anaconda
UOS Deepin Linux 安装 anaconda
下载 anaconda 官网下载 国内开源镜像站下载 官网下载 anaconda 官网: https://www.anaconda.com/ 点击右上角 Free Download 按钮 跳转值下载页面:https://www.anaconda.com/download 国内开源镜像站下载 清华大学开源…
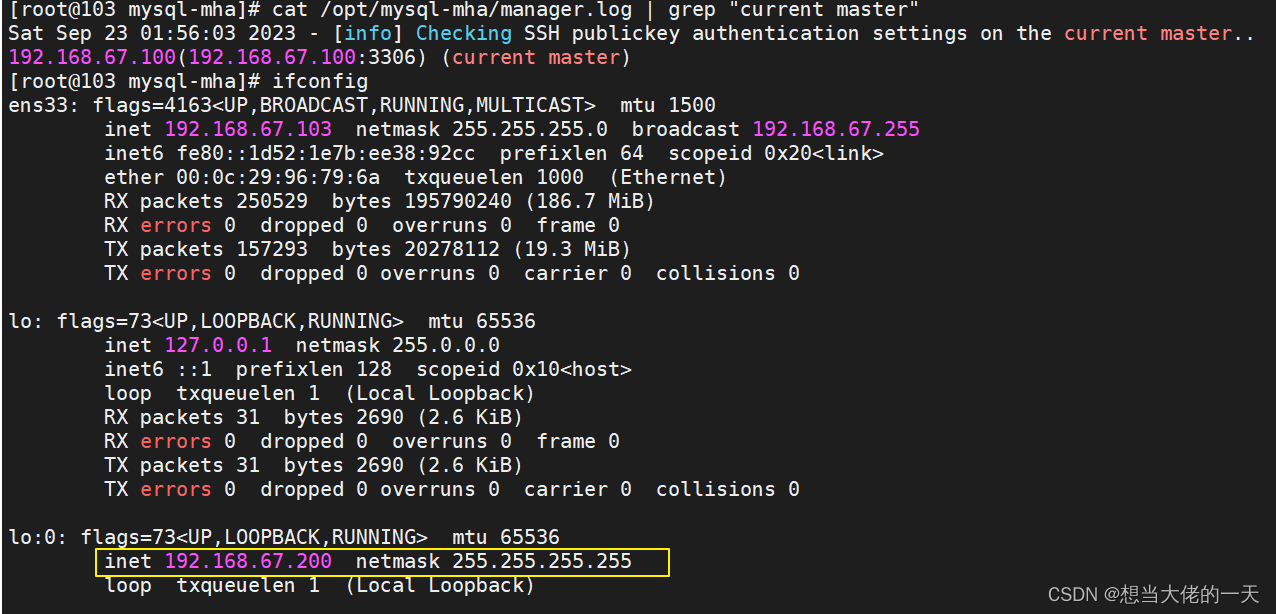
MySQL案例详解 二:MHA高可用配置及故障切换
文章目录 1. MHA的简单介绍1.1 MHA概述1.2 MHA的核心组件1.2.1 Manager 节点1.2.2 Master 节点1.2.3 Slave 节点 1.3 MHA的工作原理1.4 工作流程1.5 MHA架构的特点 2. 部署MHA实现MySQL高可用2.1 首先实现主从复制2.1.1 前置准备2.1.2 配置主服务器2.1.3 配置从服务器12.1.4 配…
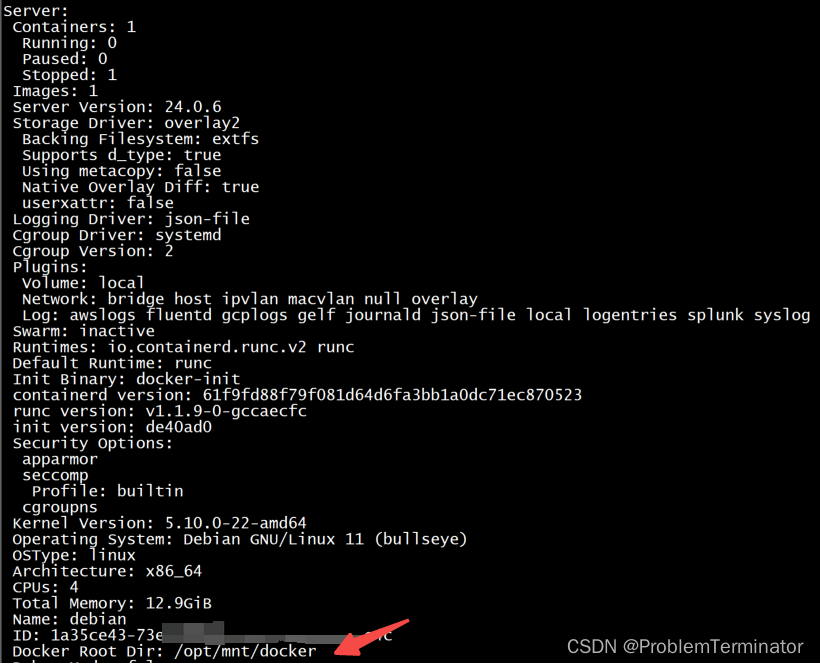
给/etc/docker/daemon.json中配置graph后docker启动失败
目录
背景
排查
解决
另外注意 背景
启动报错:
Job for docker.service failed because the control process exited with error code.
See "systemctl status docker.service" and "journalctl -xe" for details.
迁移docker目录&…

Neo4j CQl语句(持续更新)
1.清空所有数据
MATCH (n)
OPTIONAL MATCH (n)-[r]-()
DELETE n,r2.删除一个节点及其所有的关系
MATCH (r)
WHERE id(r) 11
DETACH DELETE r3.删除一个节点 DELETE(通过属性删除)
MATCH (n:标签{name:temp})
delete n4.删除所有节点和所有的关系
MA…

Android事件分发机制源码解析
触摸事件传递机制是Android中一块比较重要的知识体系,了解并熟悉整套的传递机制有助于更好的分析各种滑动冲突、滑动失效问题,更好去扩展控件的事件功能和开发自定义控件。
预备知识
MotionEvent
在Android设备中,触摸事件主要包括点按、长…
Steam VR Plugin 2.7.3爬坑指南
因为项目有VR串流的需要,于是就用起了PicoSteam VR串流,真是一把心酸泪,坑还真不少。有些解决了,有些没有,等待后续更新或者有好心人指点一下啊,进入正题。 (1)导入插件之后…
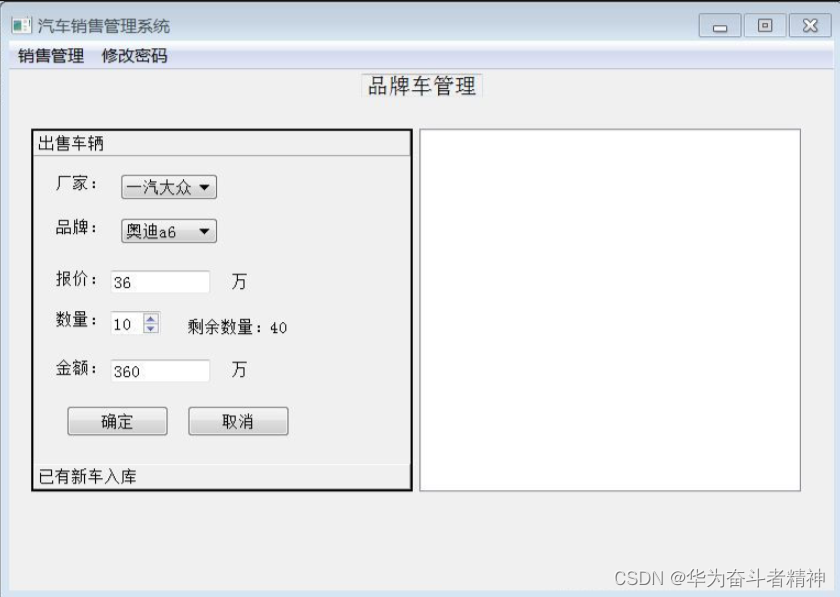
Qt5开发及实例V2.0-第十六章-Qt汽车销售管理系统实例
Qt5开发及实例V2.0-第十六章-Qt汽车销售管理系统实例 Qt汽车销售管理系统实例一、 系统概述二、 系统模块三、 界面设计四、 代码实现五、 总结 本章相关例程源码下载 Qt汽车销售管理系统实例 一、 系统概述
汽车销售管理系统是一款基于QT5框架开发的管理系统,主要…

回归预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据回归预测
回归预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据回归预测 目录 回归预测 | Matlab实现基于MIC-BP最大互信息系数数据特征选择算法结合BP神经网络的数据回归预测效果一览基本介绍研究内容程序设计参考资料 效果一览 基本介绍 Matlab实现基于…

LeetCode【69. x 的平方根】
给你一个非负整数 x ,计算并返回 x 的 算术平方根 。
由于返回类型是整数,结果只保留 整数部分 ,小数部分将被 舍去 。
注意:不允许使用任何内置指数函数和算符,例如 pow(x, 0.5) 或者 x ** 0.5 。 示例 1࿱…

智云谷再获AR HUD新项目定点,打开HUD出口海外新通道
深圳前海智云谷科技有限公司(以下简称“智云谷”)于近日收到国内某新能源车企的《定点通知书》,选择智云谷作为其新车型AR HUD开发与量产供应商。智云谷获得定点的车型为海外出口车型,该车型预计在2024年下半年量产。
中国汽车全产业链出海“圈粉”
随…