HashMap中的hash方法为什么要右移 16 位异或?
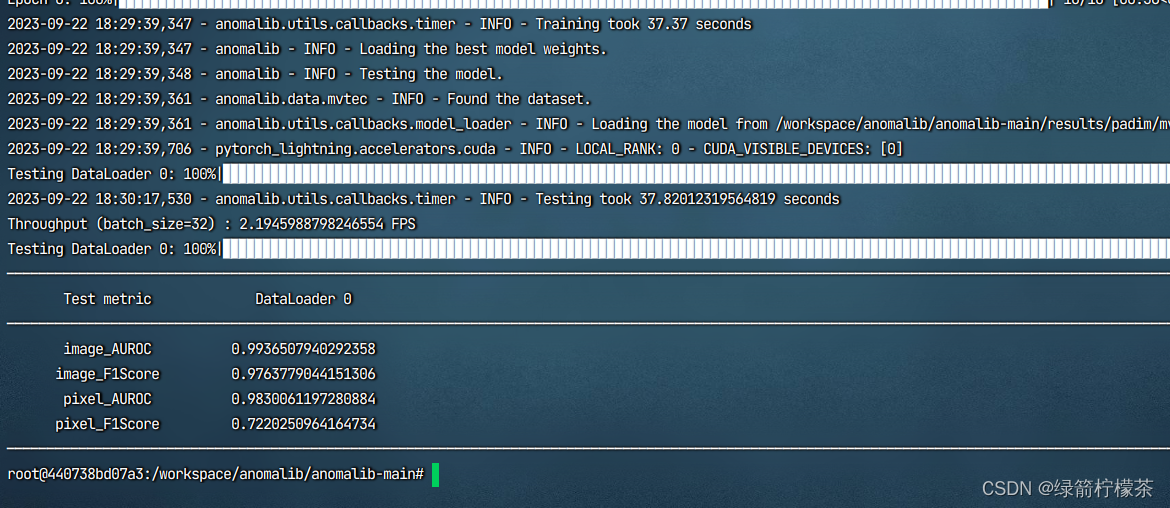
之所以要对 hashCode 无符号右移 16 位并且异或,核心目的是为了让 hash 值的散列度更高,尽可能减少 hash 表的 hash 冲突,从而提升数据查找的性能。
HashMap 的 put 方法
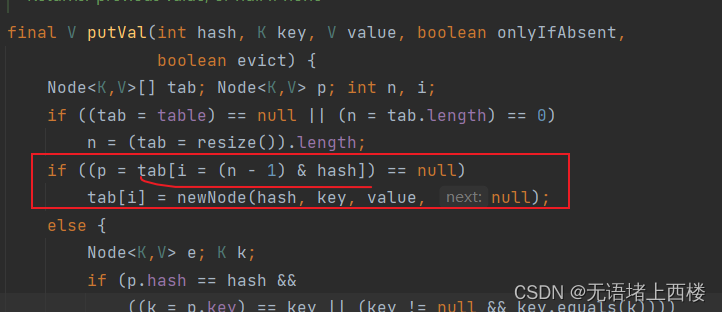
在 HashMap 的 put 方法里面,是通过 Key 的 hash 值与数组的长度取模计算
得到数组的位置。
而在绝大部分的情况下,n 的值一般都会小于 2^16 次方,也就是 65536。所以也就意味着 i 的值 , 始终是使用 hash 值的低 16 位与(n-1)进行取模运算,这个是由与运算符&的特性决定的。
这样就会造成 key 的散列度不高,导致大量的 key 集中存储在固定的几个数组位置,很显然会影响到数据查找性能。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
HashMap 的 hash 方法
为了提升 key 的 hash 值的散列度,在 hash 方法里面,做了位移运算。首先使用 key 的 hashCode 无符号右移 16 位,意味着把 hashCode 的高位移动到了低位。然后再用 hashCode 与右移之后的值进行异或运算,就相当于把高位和低位的特征进行和组合。从而降低了 hash 冲突的概率。如下图:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}