1、Spark SQL是什么
Spark SQL是Spark中用于处理结构化数据的一个模块,前身是Shark,但本身继承了前身Hive兼容和内存列存储的一些优点。Spark SQL具有以下四个特点:
- 综合性(Integrated):Spark中可以加入SQL查询,也可以使用DataFrame API,其中API提供了多种语言选择,Python、R、Java和Scala都支持。
- 连接统一性(Uniform Data Access):使用相同的方式连接不同的数据源(Hive、Json和JDBC等等)。
- Hive兼容性:能够在已有数据仓库中执行SQL或者Hive查询
- 标准化连接(Standard Connectivity):提供了JDBC或者ODBC的数据接口,可以给其他BI工具使用。
Spark SQL的优点
- 代码量少:可以直接写SQL语句或者DataFrame 。
- 性能更高:在使用DataFrame API时,DataFrame转成RDD时,会进行代码优化,执行效率更高;Spark SQL代码的RDD还行效率比Python、Java等编写的RDD效率高。
2、DataFrame简介
Spark中DataFrame是⼀个分布式的⾏集合,可以想象为⼀个关系型数据库的表,或者⼀个带有列名的Excel表格。不过它跟RDD有以下共同之处:
- 不可变(Immuatable):跟RDD一样,一旦创建就不能更改你,只能通过transformation生成新的DataFrame;
- 懒加载(Lazy Evaluations):只有action才会让transformation执行;
- 分布式(Distributed):也是分布式的。
DataFrame跟RDD的比较
| DataFrame | RDD | |
|---|---|---|
| 逻辑框架 | 提供详细结构信息,例如列的名称和类型 | 不知道类的内部结构 |
| 数据操作 | API更丰富、效率更高 | 代码少时,速度更快 |
DataFrame API常用代码
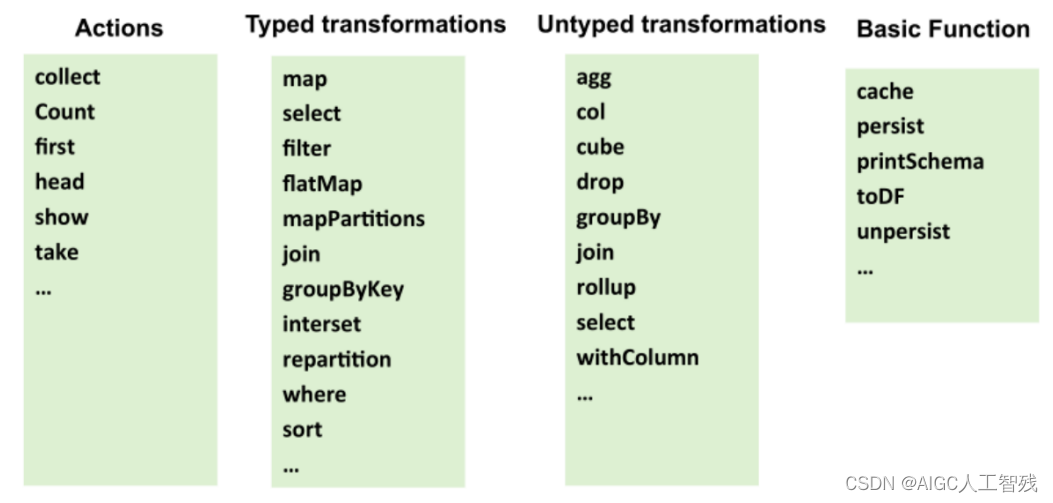
DataFrame的API也分为transformation和action两类
- transformation 延迟操作
- action 立即操作
- 创建SparkSession对象
SparkSession.builder.master("local") \
... appName("Word Count") \
... getOrCreate()
# Builder 是 SparkSession 的构造器。 通过 Builder, 可以添加各种配置
# master (master)设置要链接到的spark master节点地址, 传⼊ “local” 代表本地模式, “local[4]”代表本地模式4内核运⾏
# appName (name)为Spark应⽤设置名字
# getOrCreate ()获取⼀个已经存在的 SparkSession 或者如果没有已经存在的, 创建⼀个新的SparkSession
- 通过SparkSession创建DataFrame
sparkSession.createDataFrame
- 读取文件生成DataFrame
# json格式
spark.read.json("xxx.json")
spark.read.format('json').load('xxx.json')
# parquet格式
spark.read.parquet("xxx.parquet")
# jdbc格式
spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/db_name")\
.option("dbtable","table_name").option("user","xxx").option("password","xxx").load()
- 基于RDD创建DataFrame
# rdd中读取数据
spark = SparkSession.builder.master('local').appName('Test').getOrCreate()
sc = spark.sparkContext
list1 = [('Ankit',25),('Jalfaizy',22),('saurabh',20),('Bala',26)]
rdd = sc.parallelize(list1)
# 添加数据列名
people = rdd.map(lambda x:Row(name=x[0], age=int(x[1])))
# 创建DataFrame
df_pp = spark.createDataFrame(people)
print(df_pp.show(2))
- 从CSV文件中读取数据
# # rdd中读取数据
spark = SparkSession.builder.master('local').appName('Test').getOrCreate()
df = spark.read.format('csv').option('header','true').load('iris.csv')
df.printSchema()
df.show(5)
print(df.count())
print(df.columns)
- 增加列、删除列和提取部分列
# 增加列
df.withColumn('newWidth', df.SepalWidth*2).show()
# 删除列
df.drop('cls').show()
# 提取部分列
df.select('SepalLength','SepalWidth').show()
- 统计信息、基本统计功能和分组统计
#统计信息 describe
df.describe().show()
#计算某⼀列的描述信息
df.describe('cls').show()
# 基本统计信息
df.select('cls').distinct().count()
# 分组统计
df.groupby('cls').agg({'SepalWidth':'mean','SepalLength':'max'}).show()
# avg(), count(), countDistinct(), first(), kurtosis(),
# max(), mean(), min(), skewness(), stddev(), stddev_pop(),
# stddev_samp(), sum(), sumDistinct(), var_pop(), var_samp() and variance()
- 采集数据、拆分数据集和查看两个数据集的差异
# ================采样数据 sample===========
#withReplacement:是否有放回的采样
#fraction:采样⽐例
#seed:随机种⼦
sdf = df.sample(False,0.2,100)
#设置数据⽐例将数据划分为两部分
trainDF, testDF = df.randomSplit([0.6, 0.4])
#查看两个数据集在类别上的差异 subtract,确保训练数据集覆盖了所有分类
diff_in_train_test = testDF.select('cls').subtract(trainDF.select('cls'))
diff_in_train_test.distinct().count()
- 自定义函数和交叉表
# 交叉表 crosstab
df.crosstab('cls','SepalLength').show()
# 自定义函数UDF
# 找到数据,做后续处理
traindf, testdf = df.randomSplit([0.7,0.3])
diff_in_train_test = testdf.select('cls').subtract(traindf.select('cls')).distinct().show()
# 找到类,整理到一个列表中
not_exist_cls = traindf.select('cls').subtract(testdf.select('cls')).distinct().rdd.map(lambda x:x[0]).collect()
# 定义一个方法
def shou_remove(x):
if x in not_exist_cls:
return -1
else:
return x
# 在RDD中可以直接定义函数,交给rdd的transformatioins⽅法进⾏执⾏
# 在DataFrame中需要通过udf将⾃定义函数封装成udf函数再交给DataFrame进⾏调⽤执⾏
from pyspark.sql.types import StringType
from pyspark.sql.functions import udf
check = udf(shou_remove, StringType())
resultdf = traindf.withColumn('new_cls',check(traindf['cls'])).filter('new_cls<>-1')
resultdf.show()
- 加载json的API
1)以通过反射⾃动推断DataFrame的Schema
# 1) json→RDD→DataFrame
spark = SparkSession.builder.appName('json_demo').getOrCreate()
sc = spark.sparkContext
jsonString = [
"""{ "id" : "01001", "city" : "AGAWAM", "pop" : 15338, "state" : "MA" }""",
"""{ "id" : "01002", "city" : "CUSHMAN", "pop" : 36963, "state" : "MA" }"""
]
jsonrdd = sc.parallelize(jsonString) # json 2 rdd
jsondf = spark.read.json(jsonrdd) #rdd 2 dataframe
jsondf.printSchema()
jsondf.show()
# 2) 直接从文件中加载
spark = SparkSession.builder.appName('json_demo').getOrCreate()
sc = spark.sparkContext
jsondf = spark.read.json('zips.json')
jsondf.printSchema()
jsondf.filter(jsondf.pop>40000).show(10)
jsondf.createOrReplaceTempView('temp_table')
resulfdf = spark.sql('select * from temp_table where pop>40000')
resulfdf.show(10)
2)通过StructType对象指定Schema
spark = SparkSession.builder.appName('json_demo').getOrCreate()
sc = spark.sparkContext
jsonSchema = StructType([
StructField("id", StringType(), True),
StructField("city", StringType(), True),
StructField("loc" , ArrayType(DoubleType())),
StructField("pop", LongType(), True),
StructField("state", StringType(), True)
])
reader = spark.read.schema(jsonSchema)
jsondf = reader.json('zips.json')
jsondf.printSchema()
jsondf.show(2)
jsondf.filter(jsondf.pop>40000).show(10)