目录
- 一、docker 配置 gpu版pyhorch环境
- 1、显卡驱动、cuda版本、pytorch cuda版本三者对应
- 2、拉取镜像
- 二、部署Anomalib
- 1、下载Anomalib
- 2、创建容器并且运行
- 3、安装Anomalib
- 进入项目路径
- 安装依赖
- 测试:
一、docker 配置 gpu版pyhorch环境
1、显卡驱动、cuda版本、pytorch cuda版本三者对应
- 自行查看:三者对应版本信息
2、拉取镜像
-
直接在
docker.hub中拉取pytorch镜像:找到自己所需要的环境 pytorch镜像 -
点击复制 devel 版链接
docker pull pytorch/pytorch:1.9.1-cuda11.1-cudnn8-devel
二、部署Anomalib
1、下载Anomalib
- Anomalib github 地址
2、创建容器并且运行
我们需要docker容器中运行Anomalib,所以需要把主机文件挂载到容器中
- 主机路径:
/home/dell/ljn/anomalib
docker run -it --name="pytorch_docker" \
--gpus=all \
--shm-size=64G \
-v /home/dell/ljn/anomalib:/workspace/anomalib \
pytorch/pytorch:1.9.1-cuda11.1-cudnn8-devel /bin/bash
没有加这一行--shm-size=64G在docker中运行pytorch会报错
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).- 由于在docker镜像中默认限制了shm(shared memory),然而数据处理时pythorch则使用了shm。这就导致了在运行多线程时会将超出限制的DataLoader并直接被kill掉。
--shm-size=64G:这里设置为64G,根据自身电脑性能进行设置- 容器运行后可以看到挂载的目录
jn@ljn-Alienware-13:~/ai_project/anomalib$ ./run_docker.sh
root@440738bd07a3:/workspace# ls
anomalib
root@440738bd07a3:/workspace#
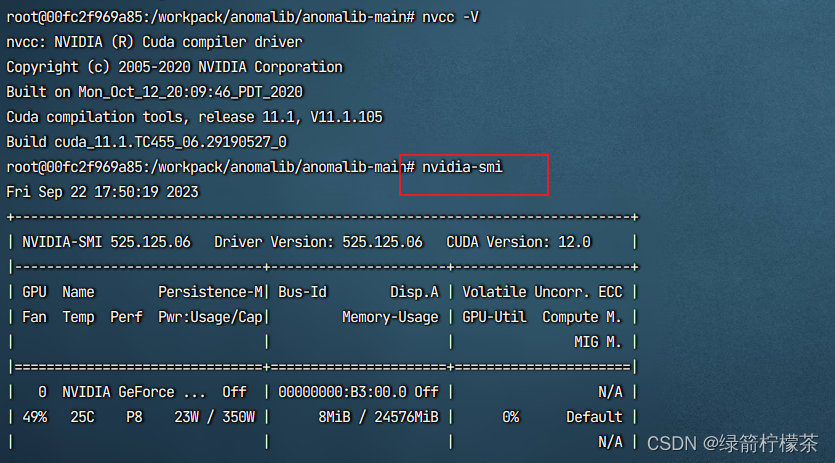
- 验证
ncvv -V
nvidia-smi
3、安装Anomalib
进入项目路径
cd anomalib/anomalib-main
安装依赖
pip install update
pip install -e .
pip install wandb
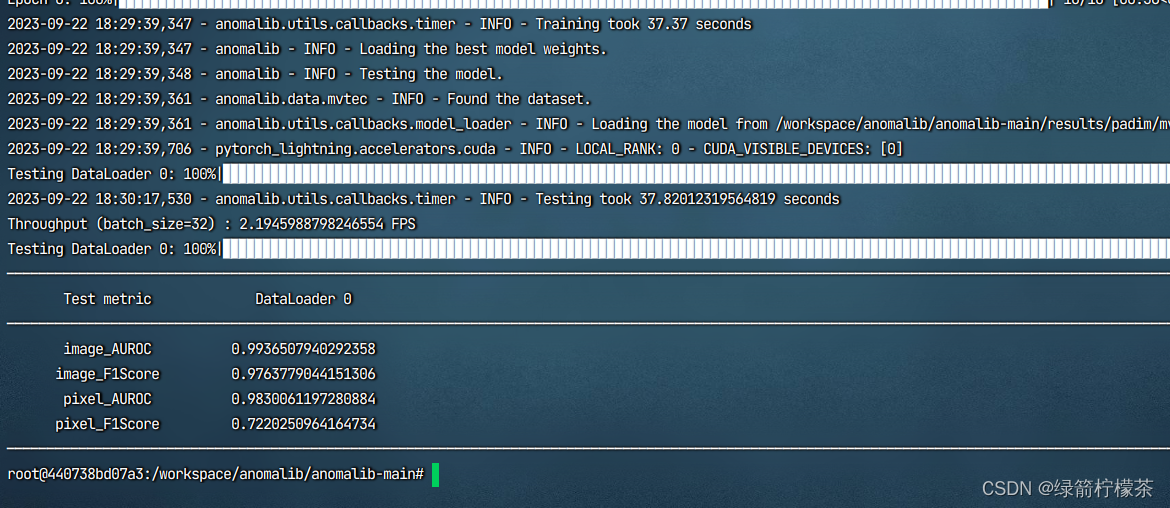
测试:
-
执行
python tools/train.py -
运行报错:
ImportError: libGL.so.1: cannot open shared object file: No such file or directory

-
需要安装opencv
apt-get update apt-get install libopencv-dev -
再次执行:
python tools/train.py -
报错
ImportError: cannot import name 'KeypointRCNN_ResNet50_FPN_Weights' from 'torchvision.models.detection' (/opt/conda/lib/python3.7/site-packages/torchvision/models/detection/__init__.py)

-
torchvision版本不兼容或缺少相关模块导致的,更新版本pip install --upgrade torchvision -
再次执行:
python tools/train.py -
运行成功:到此Anomalib项目部署完成