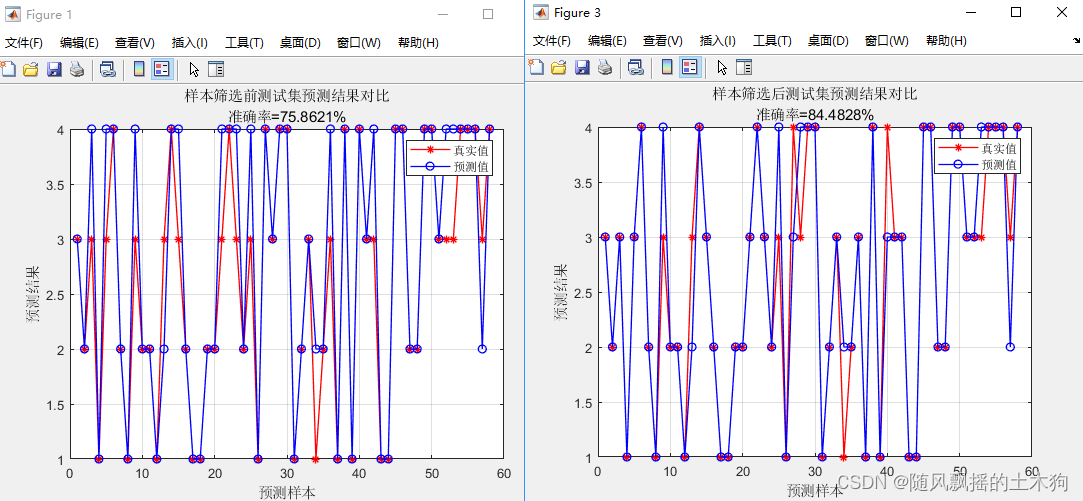
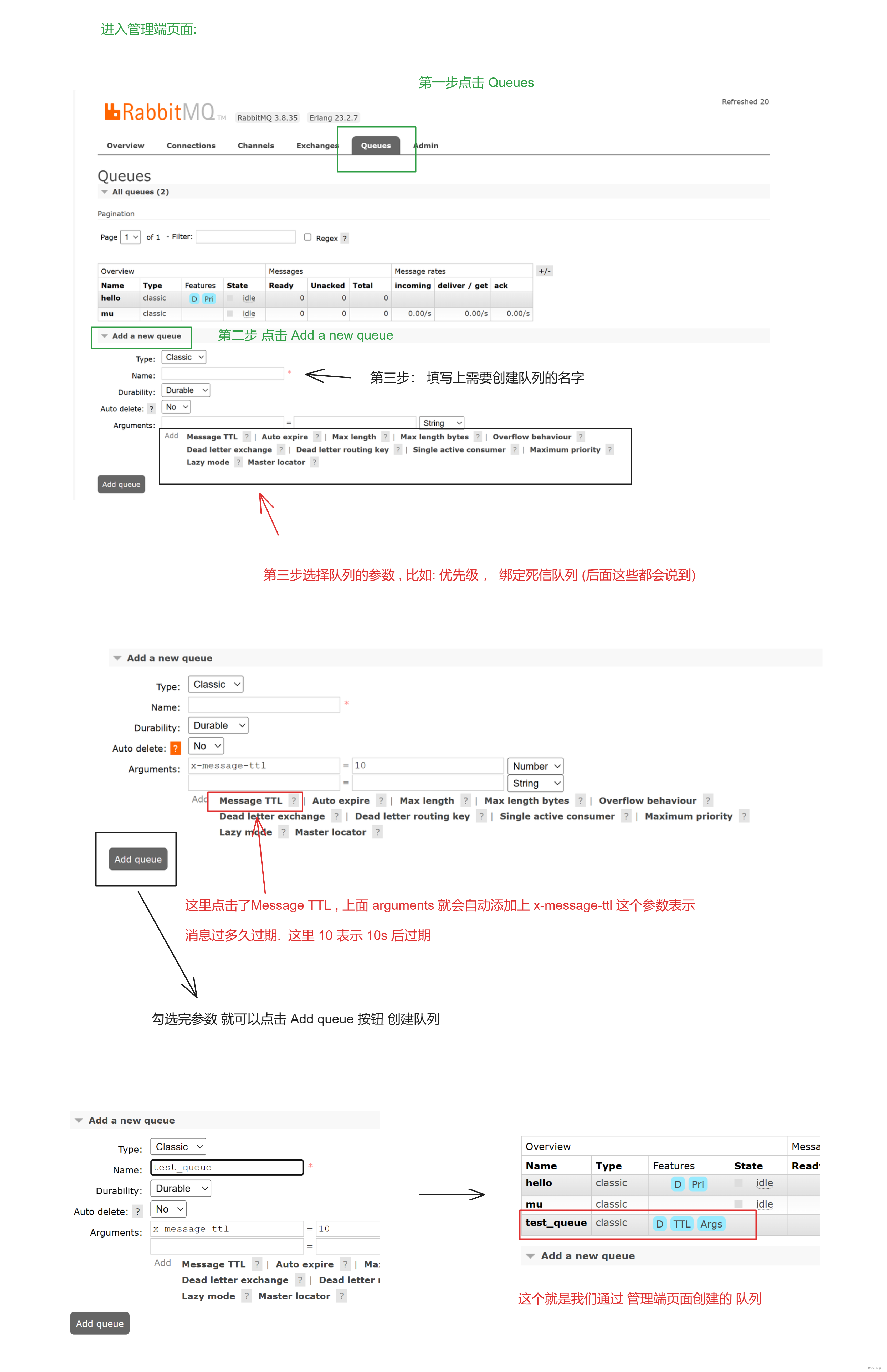
网络文学是新世纪我国流行文化中的重要领域,年轻人对网络小说更是有着广泛的喜爱。本文以抓取网络小说正文为例编写一个简单、实用的爬虫脚本。
01、分析网页
很多人在阅读网络小说时都喜欢本地阅读,换句话说就是把小说下载到手机或者其他移动设备上阅读,这样不仅不受网络的限制,还能够使用阅读App调整出自己喜欢的显示风格。但遗憾的是,各大网站很少会提供整部小说的下载功能,只有部分网站会给VIP会员开放下载多个章节内容的功能。对于普通读者而言,虽然VIP章节需要购买阅读,但是至少还是希望能够把大量的免费章节一口气看完。用户完全可以使用爬虫程序来帮助自己把一个小说的所有免费章节下载到TXT文件中,以方便在其他设备上阅读(这里也要提示大家支持正版,远离盗版,提高知识产权意识)。
以逐浪小说网为例,从排行榜中选取一个比较流行的小说(或者是大家感兴趣的)进行分析,首先是小说的主页,其中包括了各种各样的信息(如小说简介、最新章节、读者评论等),其次是一个章节列表页面(有的网站也称为“最新章节”页面),而小说的每一章有着单独的页面。很显然,如果用户能够利用章节列表页面来采集所有章节的URL地址,那么我们只要用程序分别抓取这些章节的内容,并将内容写入本地TXT文件,即可完成小说的抓取。
在查看章节页面之后,用户十分遗憾地发现,小说的章节内容使用JS加载,并且整个页面使用了大量的CSS和JS生成的效果,这给用户的抓取增加了一点难度。使用requests或者urllib库直接请求章节页面的URL是不现实的,但用户可以用Selenium来轻松搞定这个问题,对于一个规模不大的任务而言,在性能和时间上的代价还是可以接受的。
接下来分析一下如何定位正文元素。使用开发者模式查看元素(见图1),用户发现可以使用read-content这个ID的值定位到正文。不过class的值也是read-content,在理论上似乎可以使用class名定位,但Selenium目前还不支持复合类名的直接定位,所以使用class来定位的想法只能先作罢。

■ 图1 开发者模式下的小说章节内容
提示/
虽然Selenium目前只支持对简单类名的定位,但是用户可以使用CSS选择的方式对复合类名进行定位,大家感兴趣的可以了解Selenium中的find_element_by_css_selector()方法。
02、编写爬虫
使用Selenium配合Chrome进行本次抓取,除了用pip安装Selenium之外,首先需要安装ChromeDriver,可访问以下地址将其下载到本地:
https://sites.google.com/a/chromium.org/chromedriver/downloads
进入下载页面后(见图2),根据自己系统的版本进行下载即可。
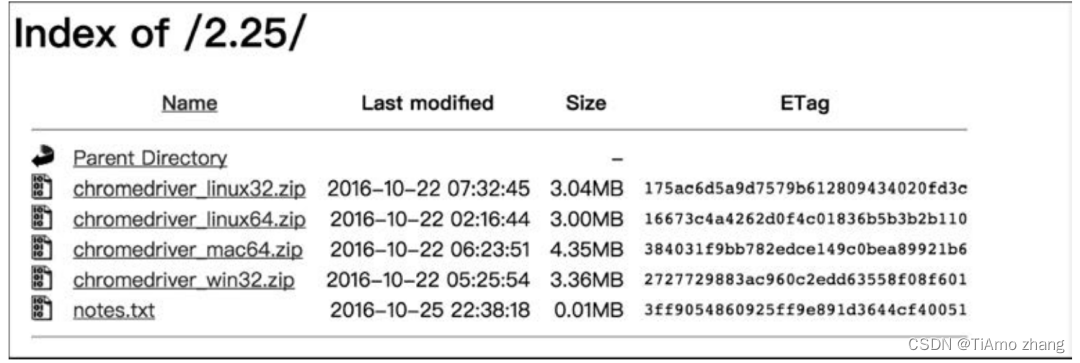
■ 图2 ChromeDriver的下载页面
之后,使用selenium.webdriver.Chrome(path_of_chromedriver)语句可创建Chrome浏览器对象,其中path_of_chromedriver就是下载的ChromeDriver的路径。
在脚本中,用户可以定义一个名为NovelSpider的爬虫类,使用小说的“全部章节”页面URL进行初始化(类似于C语言中的“构造”),同时它还拥有一个list属性,其中将会存放各个章节的URL。类方法如下。
-
get_page_urls():从全部章节页面抓取各个章节的URL。
-
get_novel_name():从全部章节页面抓取当前小说的书名。
-
text_to_txt():将各个章节中的文字内容保存到TXT文件中。
-
looping_crawl():循环抓取。
思路梳理完毕后就可以着手编写程序了,最终的爬虫代码见例1。
【例1】网络小说的爬取程序。
# NovelSpider.py
import selenium.webdriver,time,re
from selenium.common.exceptions import WebDriverException
class NovelSpider():
def init (self,url):
self.homepage = url
self.driver= selenium.webdriver.Chrome(path of chromedriver)
self.page list =[]
def del (self):
self.driver.quit(
def get page urls(self):
homepage = self.homepage
self.driver.get(homepage
self.driver.save screenshot('screenshot.png')
self.driver.implicitly_wait(5)elements = self.driver.find elements by tag name('a')
for one in elements:
page_url = one.get attribute('href')
pattern ='http:\/\/book .zhulang .com\/\df6) /\d + .html
if re.match(pattern,page url):
print(page url)
self.page list.append(page_url)
def looping crawl(self):
homepage = self.homepage
filename = self.get_novel name(homepage) + '.txtself.get_page_urls()
pages = self.page_list
# print(pages)
for page in pages:
self.driver.get(page,
print('Next page:')
self.driver.implicitly wait(3)title = self.driver.find_element by_tag_name('h2').textres = self.driver.find element by id('read - content')text= n'+ title + n'
for one in res.find elements by xpath('./p'):text += one.texttext +=n
self.text to txt(text,filename)
time.sleep(1)
print(page + '\t\t\tis Done!')
def get novel name( self,homepage):
self.driver.get(homepage)
self.driver.implicitly wait(2)
res = self.driver.find element by tag name( 'strong').find element by xpath('./a')if res is not None and len(res.text) > 0:
return res.textelse:
return 'novel
def text to txt(self,text,filename):if filename[ - 4:]!=.txt':print(Error,incorrect filename')else:
with open(filename,'a') as fp:
fp.write(text)fp.write(n')
if name == main ':
hp_url = input(输入小说"全部章节"页面:)
path of chromedriver ='your path of chrome driver!
try:
sp1 = NovelSpider(hp_url)
sp1.looping_crawl()
del sp1
except WebDriverException as e:
print(e.msg)
__init__()和__del__()方法可以视为构造函数和析构函数,分别在对象被创建和被销毁时执行。在__init__()中使用一个URL字符串进行了初始化,而在__del__()方法中退出了Selenium浏览器。try-except语句执行主体部分并尝试捕获WebDriverException异常(这也是Selenium运行时最常见的异常类型)。在lopping_crawl()方法中则分别调用了上述其他几个方法。
driver.save_screenshot()方法是selenium.webdriver中保存浏览器当前窗口截图的方法。
driver.implicitly_wait()方法是Selenium中的隐式等待,它设置了一个最长等待时间,如果在规定的时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后再执行下一步。
提示/
显式等待会等待一个确定的条件触发然后才进行下一步,可以结合ExpectedCondition共同使用,支持自定义各种判定条件。隐式等待在编写时只需要一行,所以编写十分方便,其作用范围是WebDriver对象实例的整个生命周期,会让一个正常响应的应用的测试变慢,导致整个测试执行的时间变长。
driver.find_elements_by_tag_name()是Selenium用来定位元素的诸多方法之一,所有定位单个元素的方法如下。
-
find_element_by_id():根据元素的id属性来定位,返回第一个id属性匹配的元素;如果没有元素匹配,会抛出NoSuchElementException异常。
-
find_element_by_name():根据元素的name属性来定位,返回第一个name属性匹配的元素;如果没有元素匹配,则抛出NoSuchElementException异常。
-
find_element_by_xpath():根据XPath表达式定位。
-
find_element_by_link_text():用链接文本定位超链接。该方法还有子串匹配版本find_element_by_partial_link_text()。
-
find_element_by_tag_name():使用HTML标签名来定位。
-
find_element_by_class_name():使用class定位。
-
find_element_by_css_selector():根据CSS选择器定位。
寻找多个元素的方法名只是将element变为复数elements,并返回一个寻找的结果(列表),其余和上述方法一致。在定位到元素之后,可以使用text()和get_attribute()方法获取其中的文本或各个属性。
page url = one.get attribute('href')这行代码使用get_attribute()方法来获取定位到的各章节的URL地址。在以上程序中还使用了re(Python的正则模块)中的re.match()方法,根据正则表达式来匹配page_url。形如:
'http"\/\/book\.zhulang\.com\/\d{6}\/\d+\.html'这样的正则表达式所匹配的是下面这样一种字符串:
http://book,zhulang.com/A/B.HTML其中,A部分必须是6个数字,B部分必须是一个以上的数字。这也正好是小说各个章节页面的URL形式,只有符合这个形式的URL链接才会被加入page_list中。
re模块的常用函数如下。
-
compile():编译正则表达式,生成一个Pattern对象。之后就可以利用Pattern的一系列方法对文本进行匹配/查找(当然,匹配/查找函数也支持直接将Pattern表达式作为参数)。
-
match():用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回。
-
search():用于查找字符串的任何位置,只要找到了一个匹配的结果就返回。
-
findall():以列表形式返回能匹配的全部子串,如果没有匹配,则返回一个空列表。
-
finditer():搜索整个字符串,获得所有匹配的结果。与findall()的一大区别是,它返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
-
split():按照能够匹配的子串将字符串分割后返回一个结果列表。
-
sub():用于替换,将母串中被匹配的部分使用特定的字符串替换掉。
提示/
正则表达式在计算机领域中应用广泛,大家有必要好好了解一下它的语法
在looping_crawl()方法中分别使用了get_novel_name()获取书名并转换为TXT文件名,get_page_urls()获取章节页面的列表,text_to_txt()保存抓取到的正文内容。在这之间还大量使用了各类元素定位方法(如上文所述)。
03、运行并查看TXT文件
这里选取一个小说——逐浪小说网的《绝世神通》,运行脚本并输入其章节列表页面的URL,可以看到控制台中程序成功运行时的输出,如图3所示。

■ 图3 小说爬虫的输出
抓取结束后,用户可以发现目录下多出一个名为“screenshot.png”的图片(见图4)和一个“绝世神通.txt”文件(见图5),小说《绝世神通》的正文内容(按章节顺序)已经成功保存。
 ■ 图4 逐浪小说网的屏幕截图
■ 图4 逐浪小说网的屏幕截图

■ 图5 小说的部分内容
程序圆满地完成了下载小说的任务,缺点是耗时有些久,而且Chrome占用了大量的硬件资源。对于动态网页,其实不一定必须使用浏览器模拟的方式来爬取,可以尝试用浏览器开发者工具分析网页的请求,获取到接口后通过请求接口的方式请求数据,不再需要Selenium作为“中介”。另外,对于获得的屏幕截图而言,图片是窗口截图,而不是整个页面的截图(长图),为了获得整个页面的截图或者部分页面元素的截图,用户需要使用其他方法,如注入JavaScript脚本等,本文就不再展开介绍。






![[Linux入门]---Linux项目自动化构建工具-make/Makefile](https://img-blog.csdnimg.cn/ae23cf9f3207488a9ac8ad363149c9f3.png)