Bootloader的作用
Bootloader是位于计算机系统启动过程中的程序,它的主要作用是将操作系统从磁盘等外部存储介质加载到计算机内存中,并启动操作系统执行。Bootloader通常包括硬件初始化、自检、异常处理和启动操作系统等功能。它是计算机系统中非常重要的部分,直接影响系统启动和运行的稳定性和性能。
U-boot的介绍
U-Boot是用于多种嵌入式CPU ( MIPS、x86、ARM等)的bootloader程序,U-Boot不仅 支持嵌入式Linux系统的引导,还支持VxWorks, QNX等多种嵌入式操作系统。
工作模式
- 自主模式
- 开发模式(通过运行uboot命令进行相应的开发)
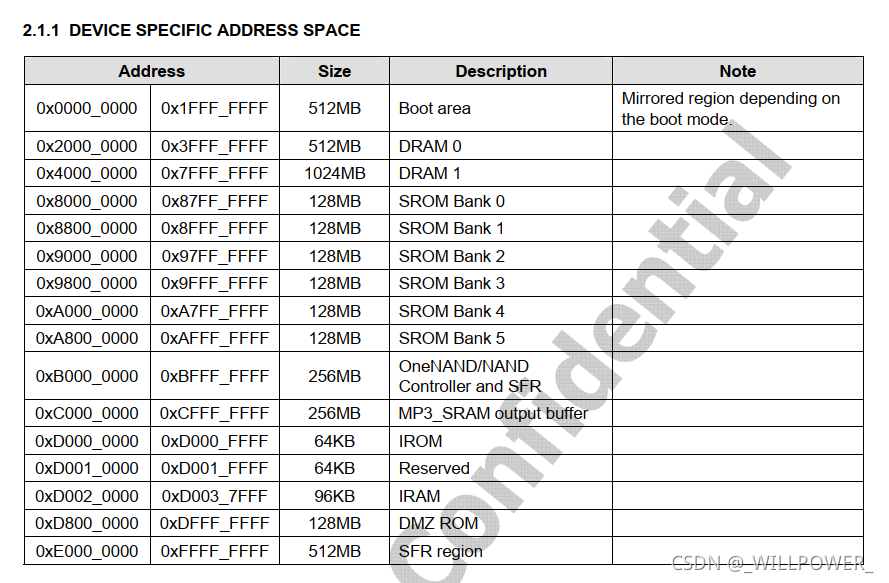
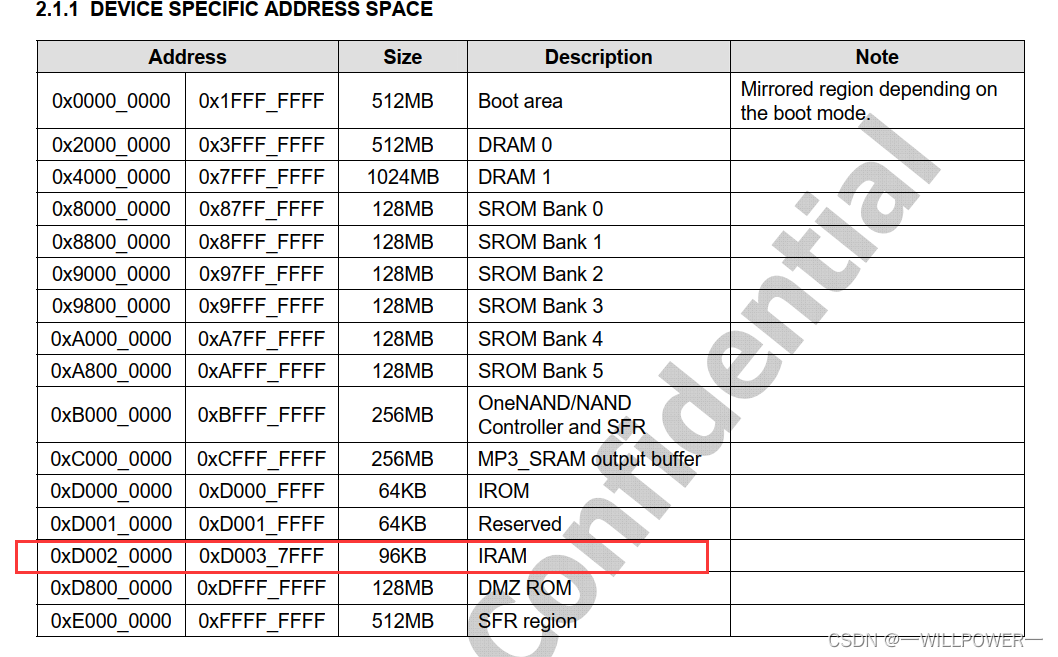
S5PV210 mapping
BootSRAM(又称为Steppingstone)
S5PV210
首先看地址空间,该芯片是从0x2000_0000的地方映射内存(DRAM)的,因此该地址就是内存的地址。
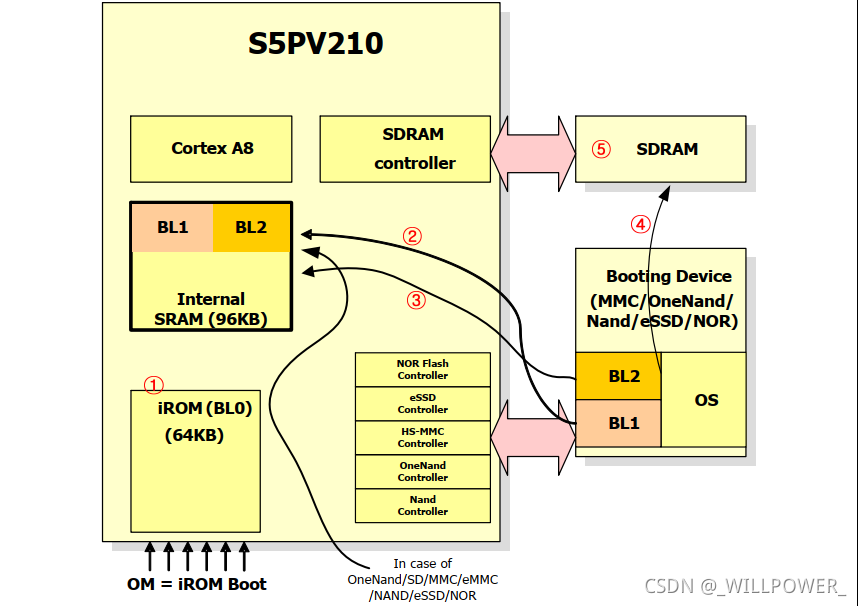
首先会从BL0开始引导,这部分iROM中的代码又芯片厂商提供,然后它最后会将BL1中的代码赋值到IRAM中拷贝运行,再之后,如果BL2容量小于80k,那么会将BL2中的也拷贝过去运行。
为什么要分为BL1和BL2?
BL1 和 BL2 在 S5PV210 芯片中分别负责不同的任务。BL1 主要用于检测存储设备,初始化芯片和内存等,然后加载 BL2 引导程序;而 BL2 则负责具体的系统启动操作,包括加载内核镜像、设备树和文件系统等任务。
虽然 BL1 和 BL2 的功能可以合并在一起,但是这样可能会让引导程序变得臃肿和复杂。而通过分离 BL1 和 BL2 可以更加灵活地对它们进行调试和优化,使得整个系统的启动过程更加高效、稳定和灵活。因此,在 S5PV210 芯片中,BL1 和 BL2 被设计为两个独立的启动加载器,以满足不同的系统需求和应用场景。
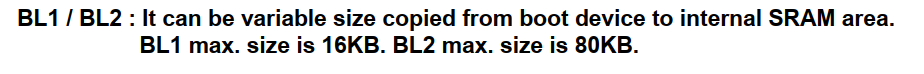
芯片手册在第2课-ARM处理器启动流程\芯片手册
S5PV210是三星公司推出的一款基于ARM Cortex-A8架构的嵌入式处理器芯片。该芯片拥有强大的多媒体处理能力和低功耗特性,广泛应用于智能手机、平板电脑、数码相机等领域。其中,S5PV210中的“S5”同样是三星公司的产品编号,“PV”代表“Processor for Video”,表示该芯片是一款用于视频处理应用的处理器,“210”则表示该芯片在该产品系列中的序号。
而S5PC110是三星公司推出的一款嵌入式处理器芯片,也是基于ARM架构的芯片。该芯片主要应用在移动设备、智能手表、便携式游戏机等嵌入式领域。同样地,S5PC110中的"S5"代表三星公司的产品编号,“PC”表示“Processor for Consumer”,即面向消费类电子产品的处理器,而“110”则代表其在该系列产品中的序号。S5PC110也被称为Exynos 3 Single,是三星公司Exynos系列处理器的一员。
环境搭建
arm-none-linux-gnu下载
下载解压
然后重命名其文件夹,后面好加入路径中
mv gcc-arm-10.3-2021.07-x86_64-arm-none-linux-gnueabihf gcc-arm
加入.bashrc中
export PATH=/mnt/g/1/gcc-arm:$PATH
然后,source ~/.bashrc
使用命令 arm-none-linux-gnueabihf-gcc -v测试
需要知道的知识
IROM中做了哪些事情?

- 关闭看门狗定时器
- 初始化指令缓存
- 初始化堆栈区域(参见第2.5章的“内存映射”)
- 初始化堆区域。(参见第2.5章的“内存映射”)
- 初始化块设备复制功能(参见第2.7章“设备复制功能”)
- 初始化锁相环和设置系统时钟。(参见第2.11章的“时钟配置”)
- 将BL1复制到内部SRAM区域(参见第2.7章的“设备复制功能”)
- 验证BL1的校验和。如果校验和失败,iROM将尝试第二次启动。(SD/MMC通道2)
- 检查是否为安全启动模式。如果在S5PV210中写入安全密钥值,则为安全启动模式。如果是安全启动模式,请验证BL1的完整性。
- 跳转到BL1的起始地址
BL1需要加头
在210启动过程中,需要校验BL1的头信息,如果头信息不正确,那么会进入二阶段
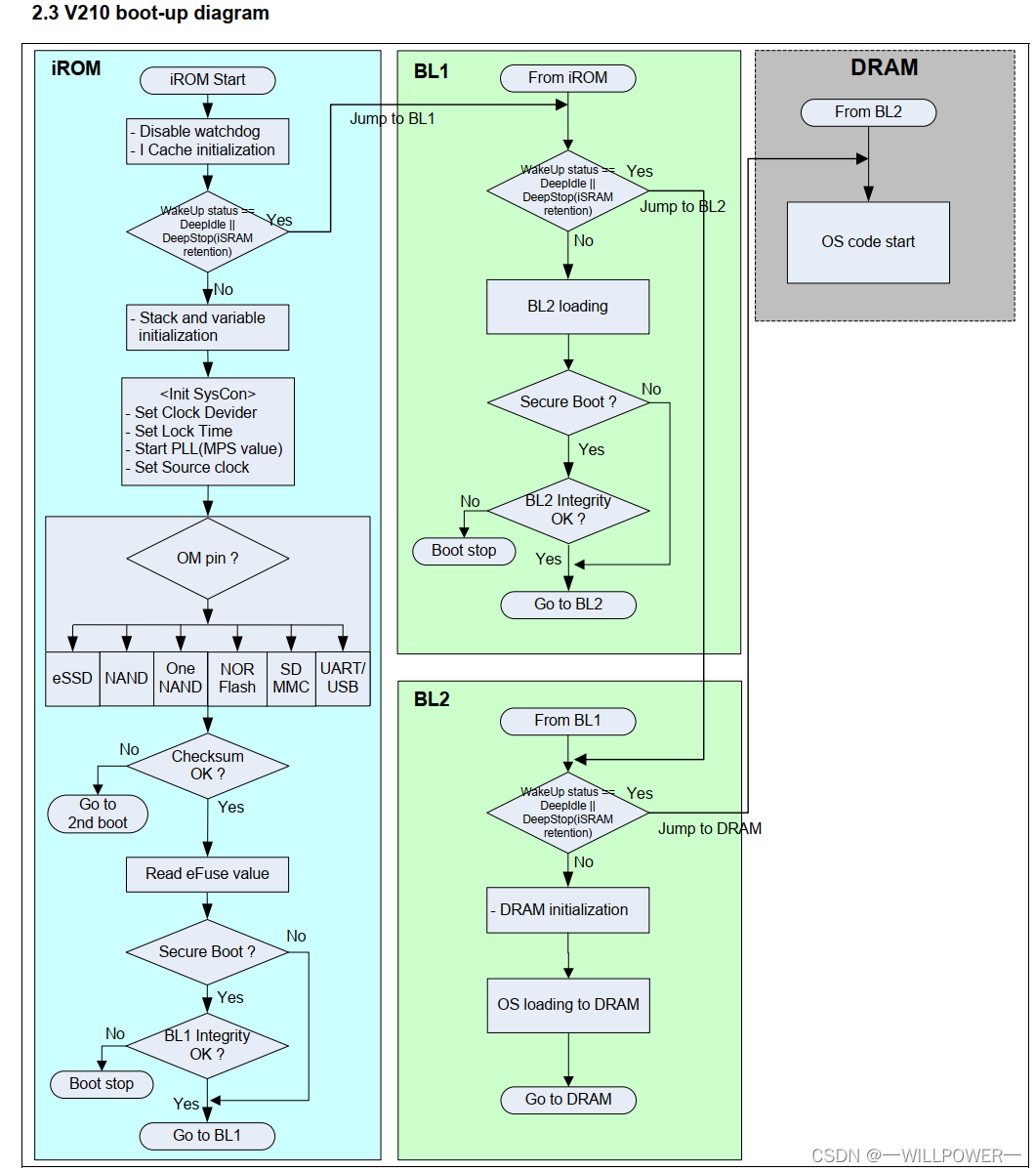
二阶段启动不成功,那么会进入Uart boot,如果不成功,则会进入USB boot

那么这个头信息是如何构成的呢?
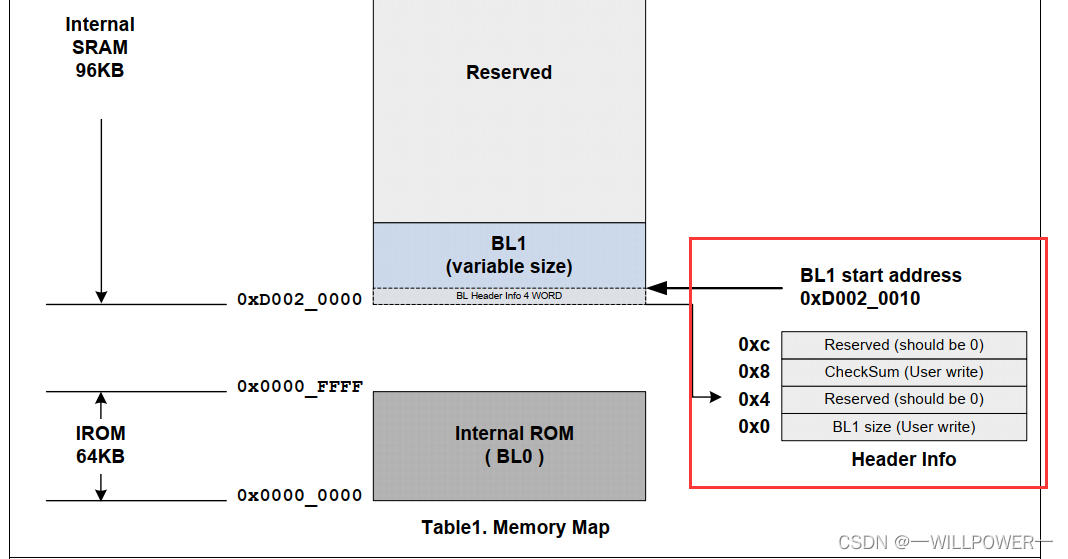
计算方法:

文章最后的问题中,给出了加头程序,直接使用gcc编译使用即可。
异常向量表
当一种异常发生的时候,ARM处理器会跳转到对应该异常的固定地址去执行异常处理程序,而这个固定的地址,就称之为异常向量。
异常由内部和外部源生成,以使处理器处理一个事件,例如外部生成的中断或试图执行未定义的指令。在处理异常之前的处理器状态通常被保留,以便在异常例程完成时可以重新开始原来的程序。可能同时出现多个异常。
ARM架构支持七种异常类型。表A2-4列出了异常的类型和用于处理每个tvpe的处理器模式。当异常发生时,强制从与异常类型对应的固定内存地址执行。这些固定地址称为异常向量
(通过协处理器CP15来决定是Normal还是High)
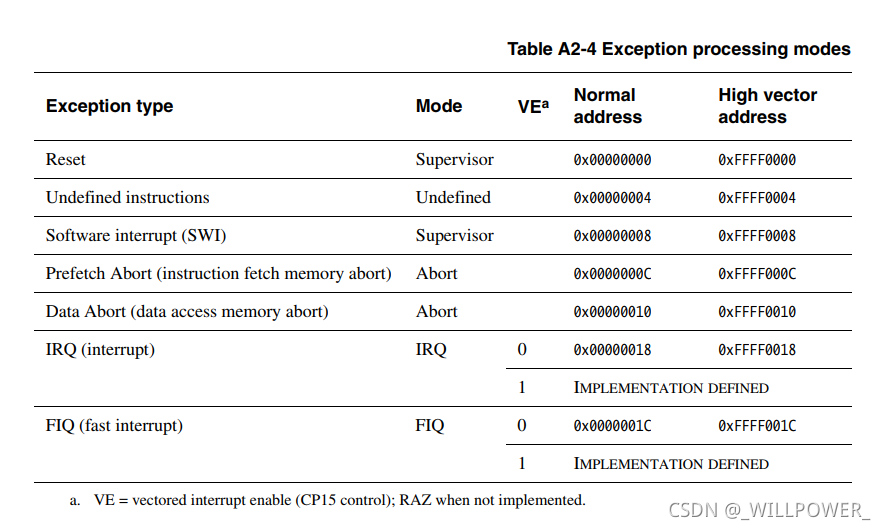
由七个异常向量及其处理函数跳转关系组成的表即为异常向量表.
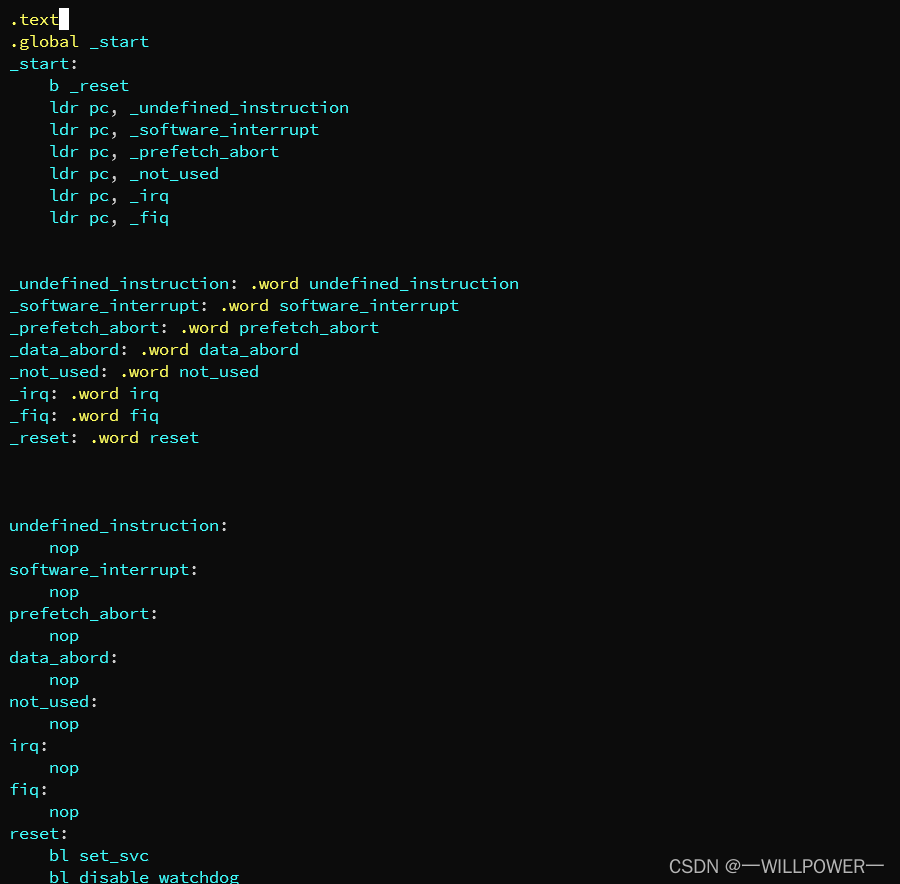
工作模式
在u-boot中,需要让soc工作在SVC模式
来源ARM Architecture Reference Manual
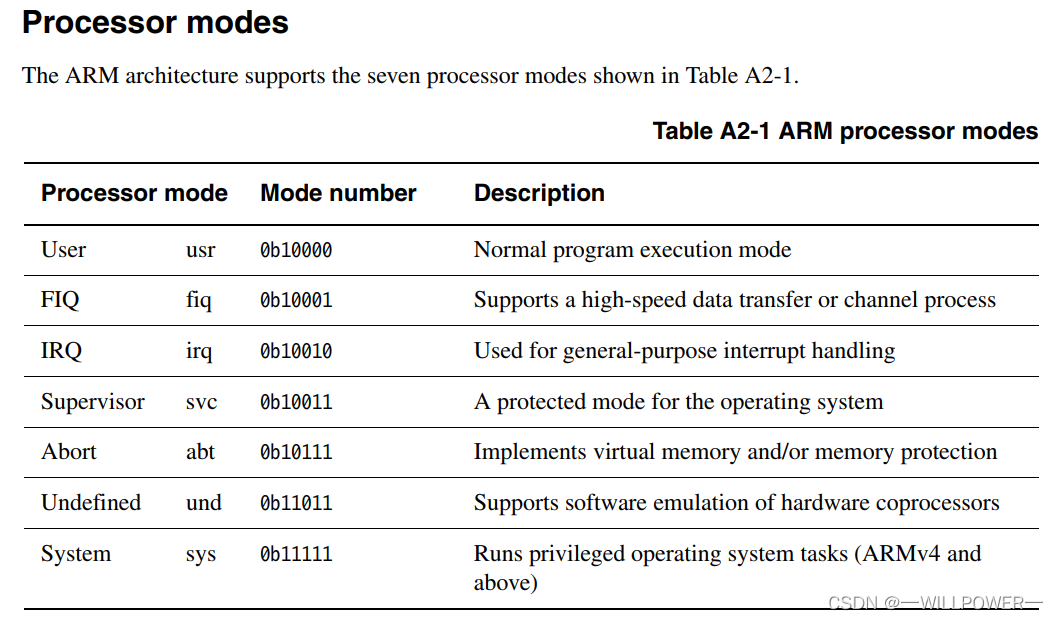
因此,需要把程序状态寄存器最后五位设置为10011,如果要屏蔽IRQ和FIQ,那么前面的I和F为也要置1



看门狗关闭
在嵌入式领域,有些系统需要长期运行在无人看守的环境。在运行过程中,难免不出现系统死机的情况,这时就需要系统自身带有一种自动重启的功能。watchdog一般是一个硬件模块,其作用就是在系统死机时,帮助系统实现自动重启。
Watchdog在硬件上实现了计时功能,启动计时后,用户(软件)必须在计时结束前重新开始计时,俗称“喂狗”,如果到超时的时候还没有重新开始计时,那么它就认为系统是死机了,就自动重启系统。
内容在S5PV210_UM_REV1.1

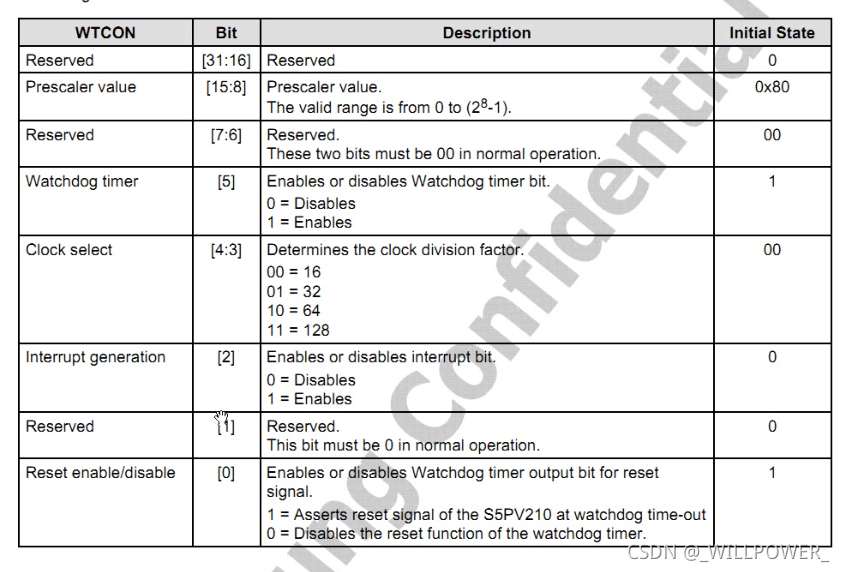
根据图中信息,关闭看门狗需要调整watchdog timer control register(WTCON)寄存器
地址: 0xE270_0000
第0位关闭触发reset功能, 第2位关闭产生看门狗中断

关闭中断
除了cpsr里面的,还有一个中断屏蔽寄存器,需要设置它,屏蔽其它中断(内容依然在S5PV210_UM_REV1.1)
210采用向量中断, 在210中有4组中断屏蔽的寄存器。因此需要将这4组地址的vicintenclear寄存器设置为全一


关闭MMU和Cache
arm存储体系
Cache
Cache是一种容量少但存取速度非常快的存储器,它保存最近用到的存储器中数据的拷贝。对于程序员来说,Cache是透明的。它自动决定保存哪些数据、覆盖哪些数据。
按照功能划分:
- I-Cache:指令Cache,用于存放指令
- D-Cache:数据Cache, 用于存放数据
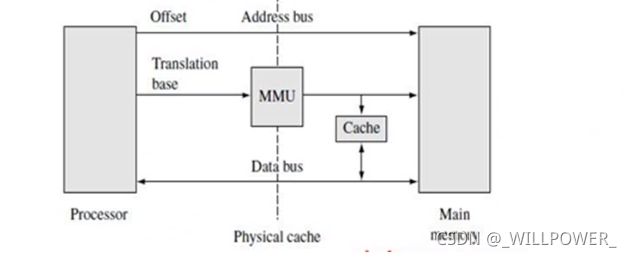
mmu
CPU中的内存管理单元(MMU)用于将虚拟内存地址翻译成物理内存地址,从而实现内存保护和虚拟内存的支持。它还能够实现内存映射和权限保护,以确保进程只能访问其所需的内存区域,并且不能越权访问其他进程的内存。
虚拟地址:程序中使用的地址。
- 可以让进程使用更大的空间
- 可以解决冲突
物理地址:物理存储单元实际的地址
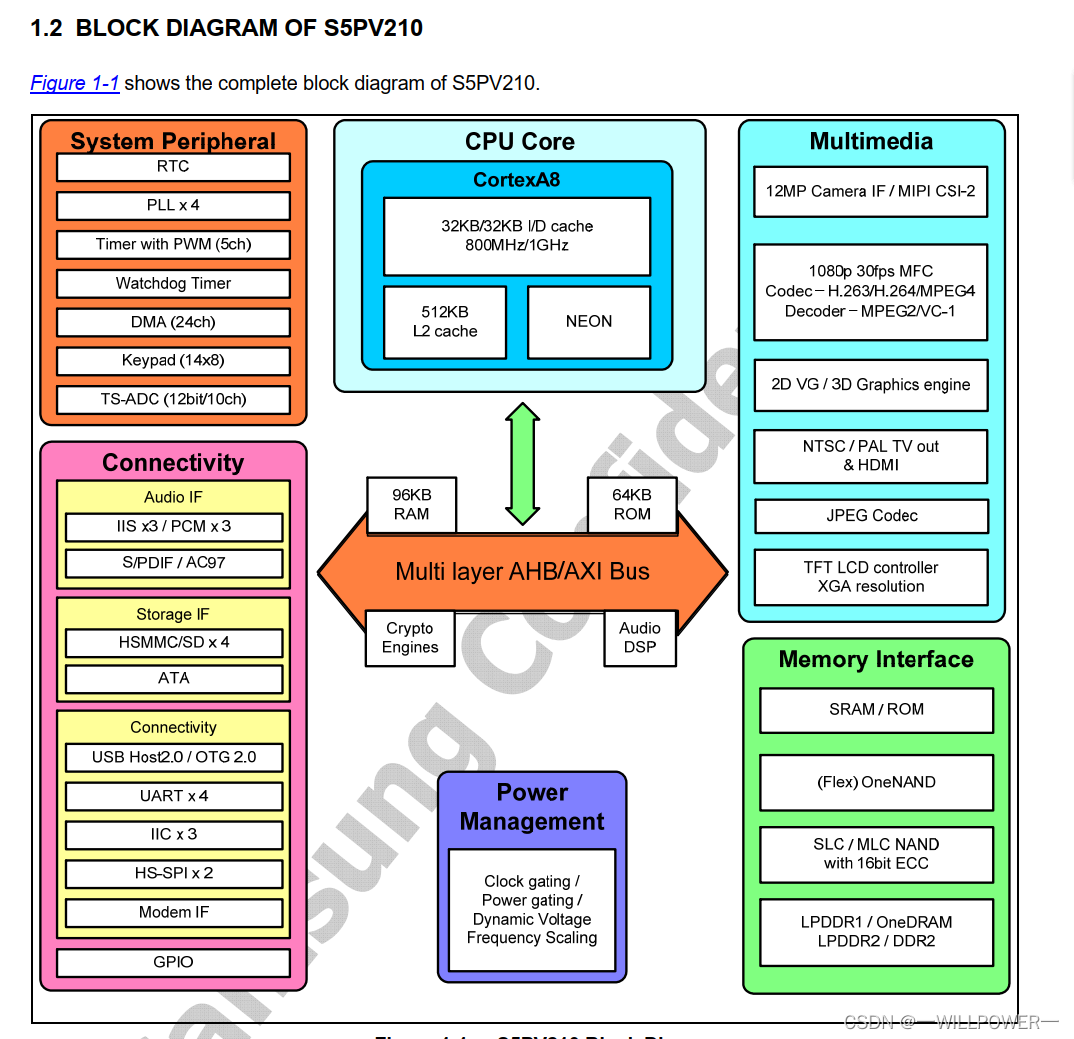
从下图中可以看到210有32kB的id_cache, 在uboot中,一般必须要dcache关闭,防止数据存在cache中,而不是内存里面,并且mmu也必须关闭,而icache可以不关闭,也可以关闭
使ICache和DCache失效
文档在cortex_a8_r3p2_trm

关闭IDCache
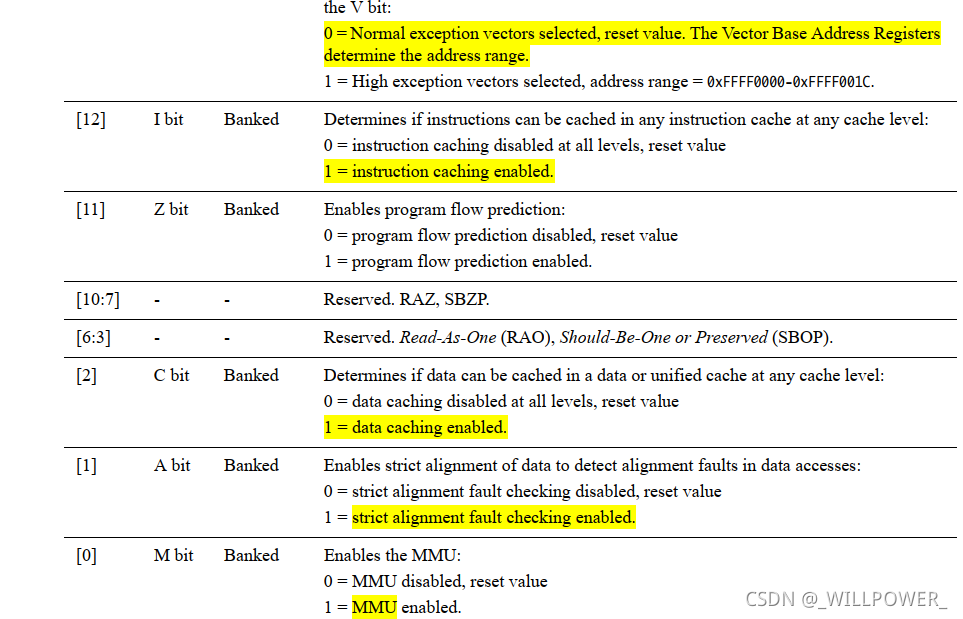


时钟配置
U-Boot-时钟初始化
内存初始化
U-Boot-内存部分
代码搬移(这里只是一个代码搬移的例子)
利用BL1将剩下的代码搬移到内存
-
起点:sram(起始地址:D0020000)
-
终点:
把iram中的代码搬移到dram中,dram起始位0x2000_0000, 因此是0x2000_0000 -
搬移方式
尽管,当前写的程序小于4kb,而irom中的固化程序会将所有程序都搬移到sram中运行是可以的,但是这里为了说明搬移过程,还是将其搬移到dram中进行运行。

C语言环境初始化
U-Boot-C语言环境初始化
U-boot工作流程分析
程序入口
第一阶段
第二阶段
其它
裸机点亮led
因为在irom中初始化了时钟,因此直接点灯就可以点亮。
如果某个阶段led不能点亮,那么说明上面的某个初始化有问题。

U-Boot-点灯
start.S
.text
.global _start
_start:
b _reset
ldr pc, _undefined_instruction
ldr pc, _software_interrupt
ldr pc, _prefetch_abort
ldr pc, _not_used
ldr pc, _irq
ldr pc, _fiq
_undefined_instruction: .word undefined_instruction
_software_interrupt: .word software_interrupt
_prefetch_abort: .word prefetch_abort
_data_abord: .word data_abord
_not_used: .word not_used
_irq: .word irq
_fiq: .word fiq
_reset: .word reset
undefined_instruction:
nop
software_interrupt:
nop
prefetch_abort:
nop
data_abord:
nop
not_used:
nop
irq:
nop
fiq:
nop
reset:
bl set_svc
bl disable_watchdog
bl disable_interrupt
bl disable_mmu
bl light_led
set_svc:
mrs r0, cpsr @因为不能直接操作cpsr,需要到register里面操作
bic r0, r0, #0x1f @后五位清零
orr r0, r0, #0xd3 @1110011(svc) 前面两个11,是屏蔽(中断)IRQ和快速中断(FIQ)
msr cpsr, r0
mov pc, lr
#define address_WTCON 0xE2700000
disable_watchdog:
ldr r0, =address_WTCON
mov r1, #0x0
str r1, [r0] @给WTCON寄存器赋值0
mov pc, lr
@屏蔽中断
disable_interrupt:
mvn r1, #0x0
ldr r0, =0xf2000014
str r1, [r0]
ldr r0, =0xf2100014
str r1, [r0]
ldr r0, =0xf2200014
str r1, [r0]
ldr r0, =0xf2300014
str r1, [r0]
mov pc, lr
@屏蔽idcache以及mmu
disable_mmu:
@设置idcache寄存器C7, 使idcache失效
mcr p15, 0, r0, c7, c5, 0
mcr p15, 0, r0, c7, c6, 1
@读出cp15协处理器的值到r0
mrc p15, 0, r0, c1, c0, 0
@将第0位和第2位设置为0 bitclear
bic r0, r0, #0x7
@将其写回cp15中
mcr p15, 0, r0, c1, c0, 0
mov pc, lr
@宏定义控制与数据寄存器
#define GPCCON 0xE0200060
#define GPCDAT 0xE0200064
light_led:
ldr r0, =GPCCON
ldr r1, =0x11000@设置3、4为输出模式
str r1, [r0]
@设置数据寄存器
ldr r0, =GPCDAT
ldr r1, =0x10@设置3亮,4不亮
str r1, [r0] @ 设置寄存器值
问题
makefile里面的变量搜不到怎么办?
比如$OBJDUMP这个变量你搜不到,那么使用
make -p | grep OBJDUMP
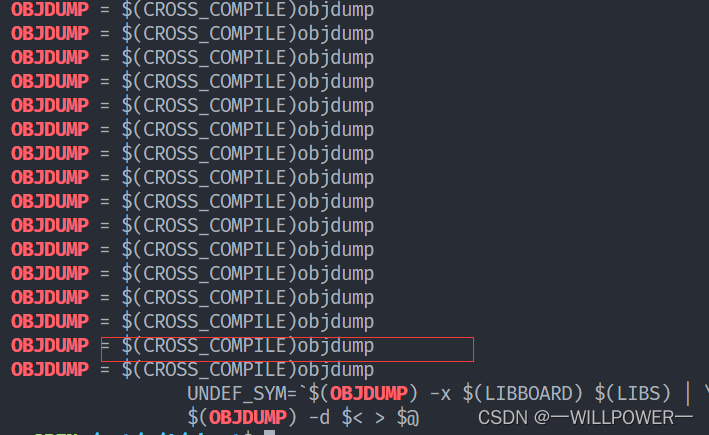
make -p 是一条用于生成包括 make 内部状态和定义的变量的完整输出的命令。它可以用于检查 Makefile 中定义的变量和目标的完整依赖关系。该命令的输出可以直接查看,也可以重定向到文件中以供以后查看。它的输出包括内部自动定义的变量、目标、规则以及当前目录中的环境变量。输出非常详细且比较冗长。因此,建议在执行此命令时使用grep等工具进行过滤,以便快速查找所需内容。
汇编冒号后面要加空格
在汇编语言中,冒号后面需要跟空格,这是语法规定,以防止出现冒号与标识符名称之间无法区分的情况。如果没有空格,编译器会将下一个符号作为标识符进行处理,从而导致编译错误。
所以,对于格式约定,最好遵循汇编语法的规范,以确保代码的正确性和可读性。加上空格可以更好地区分标识符和语法元素,使代码更易于阅读和理解。
为什么要使用类似_undefined_instruction: .word undefined_instruction这种写法?
这种写法是为了使标签 “_undefined_instruction” 指向符号 “undefined_instruction” 的地址。
在 ARM 汇编中, “.” 符号表示当前地址。“.word” 指令是将一个 32 位的字(四个字节)写入到当前地址。因此,使用 _undefined_instruction: .word undefined_instruction 可以将标签 _undefined_instruction 指向符号"undefined_instruction"的地址。
通常情况下,人们使用这种方式来定义跳转表和向量表,因为这样可以将标签映射到地址,使代码更易于阅读和维护。
直接ldr pc, =undefined_instruction 不行吗?
可以使用 “ldr pc, =undefined_instruction” 来加载地址,将标签名作为参数,不过这种写法会在编译时生成一个伪指令,称为 PC 相关伪指令 (PC-relative pseudo-instruction)。
这种伪指令是将标签的地址作为立即数存储在数据段中,并将一条 “ldr rd, [pc, #offset]” 指令插入当前位置。然后,链接器会在最终的可执行文件中将相应的地址填充到这个立即数处。
使用 “ldr pc, =undefined_instruction” 带来的好处是,它确保了跳转表项的地址中不包含偏移量(即没有“+4”),使得跳转表中的每个地址都指向指令的第一字节。而"_undefined_instruction: .word undefined_instruction"则需要在写入跳转表之前计算偏移量,并用标签和偏移量计算出正确的地址。
这两种方法都可以使用来定义跳转表。
使用 “ldr pc, =undefined_instruction” 更容易理解和维护,因为它没有需要手动计算偏移量的步骤。
使用 “_undefined_instruction: .word undefined_instruction” 的好处在于,它使用标签名显式地将指针连接到目标地址。这种方法在一些嵌入式系统中更为常见,因为在这些系统中,目标地址可以使用专门的硬件表寻址器来访问,而不需要进行计算偏移量。
默认make就是make all吗?
当你在命令行中输入make时,Make会默认执行名为“all”的目标。如果Makefile中存在“all”目标,那么执行make命令时,其实就是在执行“all”目标的规则。如果Makefile中没有“all”目标,但存在默认生成规则(例如编译生成可执行文件的规则),那么也会执行这个规则生成对应的可执行文件。因此,可以认为make命令的默认目标是“all”或者默认生成可执行文件的规则。
vim如何查看二进制文件?
使用xxd
:%!xxd
以上命令的含义为,将整个文件(buffer)传递给xxd命令用于十六进制显示。这样,vim就会将文件的每个字节都显示为十六进制编码以及对应的ASCII字符(如果可打印)。如果想要返回正常显示,可以使用以下命令:
:%!xxd -r
这个命令的含义为将整个文件(buffer)转换回原始格式(二进制)。但请注意,如果你在使用:%!xxd命令后对文件进行编辑,在使用:%!xxd -r命令将其转换回二进制格式后,可能会有部分数据损失,因此请谨慎操作。
Error: junk at end of line, first unrecognized character is `1’
注释使用@而不是分号
为什么uboot要关闭看门狗?
U-Boot可能需要在引导过程中执行多个长时间操作,如下载大型固件图像或从远程服务器启动。如果启用了看门狗定时器,它将在固定的时间范围内定期检查U-Boot的运行状态,如果检测到U-Boot停止响应或崩溃,则会强制重启系统,这可能导致引导过程中断或失败。因此,在这种情况下,关闭看门狗是一个常见的做法,以确保U-Boot的稳定性和可靠性。
为什么指定了使用arm-none-eabi-gcc,但是最后使用的是cc
根据您给出的makefile规则,您指定了在生成.o文件时使用arm-none-eabi-gcc编译器,但是在规则中您的.s文件的扩展名为大写,而您的规则用的是小写的%.s匹配符,所以make会默认使用内建的.c文件匹配规则,并且在编译时使用默认的编译器cc。 您可以将%.s修改为%.S,以匹配大写文件扩展名,从而使用指定的arm-none-eabi-gcc编译器。
VICINTENABLE和VICINTENCLEAR的区别是什么?
“VICINTENABLE”寄存器位于S5PV210处理器的中断控制器模块内,用于控制特定中断通道是否启用(enable)。写入“1”启用中断通道,写入“0”禁用中断通道。
“VICINTENCLEAR”直接位于中断控制器模块内,用于清除在VICINTENABLE中启用的中断通道,将其重新设置为禁用状态。
因此,“VICINTENABLE”和“VICINTENCLEAR”寄存器的区别是前者控制特定中断通道是否启用,而后者用于清除已启用的中断通道。
BL1加头程序
/* 在BL0阶段,Irom内固化的代码读取nandflash或SD卡前16K的内容,
* 并比对前16字节中的校验和是否正确,正确则继续,错误则停止。
*/
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define BUFSIZE (16*1024)
#define IMG_SIZE (16*1024)
#define SPL_HEADER_SIZE 16
#define SPL_HEADER "S5PC110 HEADER "
int main (int argc, char *argv[])
{
FILE *fp;
char *Buf, *a;
int BufLen;
int nbytes, fileLen;
unsigned int checksum, count;
int i;
// 1. 3个参数
if (argc != 3)
{
printf("Usage: mkbl1 <source file> <destination file>\n");
return -1;
}
// 2. 分配16K的buffer
BufLen = BUFSIZE;
Buf = (char *)malloc(BufLen);
if (!Buf)
{
printf("Alloc buffer failed!\n");
return -1;
}
memset(Buf, 0x00, BufLen);
// 3. 读源bin到buffer
// 3.1 打开源bin
fp = fopen(argv[1], "rb");
if( fp == NULL)
{
printf("source file open error\n");
free(Buf);
return -1;
}
// 3.2 获取源bin长度
fseek(fp, 0L, SEEK_END);
fileLen = ftell(fp);
fseek(fp, 0L, SEEK_SET);
// 3.3 源bin长度不得超过16K-16byte
count = (fileLen < (IMG_SIZE - SPL_HEADER_SIZE))
? fileLen : (IMG_SIZE - SPL_HEADER_SIZE);
// 3.4 buffer[0~15]存放"S5PC110 HEADER "
memcpy(&Buf[0], SPL_HEADER, SPL_HEADER_SIZE);
// 3.5 读源bin到buffer[16]
nbytes = fread(Buf + SPL_HEADER_SIZE, 1, count, fp);
if ( nbytes != count )
{
printf("source file read error\n");
free(Buf);
fclose(fp);
return -1;
}
fclose(fp);
// 4. 计算校验和
// 4.1 从第16byte开始统计buffer中共有几个1
a = Buf + SPL_HEADER_SIZE;
for(i = 0, checksum = 0; i < IMG_SIZE - SPL_HEADER_SIZE; i++)
checksum += (0x000000FF) & *a++;
// 4.2 将校验和保存在buffer[8~15]
a = Buf + 8;
*( (unsigned int *)a ) = checksum;
// 5. 拷贝buffer中的内容到目的bin
// 5.1 打开目的bin
fp = fopen(argv[2], "wb");
if (fp == NULL)
{
printf("destination file open error\n");
free(Buf);
return -1;
}
// 5.2 将16k的buffer拷贝到目的bin中
a = Buf;
nbytes = fwrite( a, 1, BufLen, fp);
if ( nbytes != BufLen )
{
printf("destination file write error\n");
free(Buf);
fclose(fp);
return -1;
}
free(Buf);
fclose(fp);
return 0;
}
ldr和bl?
在ldr pc, =start以及bl pc, =start是不同的,b是相对跳转,是相对于当前pc指针进行跳转,而ldr是绝对跳转的。
为什么要分bss和data?
当编译器编译一个程序时,它会将程序中出现的全局变量和静态变量分配到数据段或BSS段中:
已经初始化的全局变量和静态变量将被分配到数据段中,它们的初值在可执行文件的数据部分中被保存下来。
未初始化的全局变量和静态变量将被分配到BSS段中。这些变量在可执行文件中不会占用实际的存储空间,因为它们的初值为0。
这样做的好处是,可以在可执行文件中只存储已经初始化的全局变量和静态变量,从而减小可执行文件的大小。对于未初始化数据,不需要存储它们的初值,只需要在程序运行时将它们初始化为0即可(由操作系统完成)。同时,由于BSS段中的变量都被初始化为0,因此也可以节省程序运行时的初始化时间和空间。
在内存管理方面,将全局变量和静态变量分配到数据段或BSS段中,是可执行文件编译链接过程中的一种内存管理方式,可以减小可执行文件的大小,提高程序的效率。
210板子复制代码到内存需要去头!!!
编译的东西,在C语言环境电灯失败?
之前环境用的居然是arm-none-eabi-gcc而不是arm-none-linux-gnueabihf-gcc
一定要注意。
arm-none-eabi-gcc和arm-none-linux-gnueabihf-gcc的区别?
arm-none-eabi-gcc和arm-none-linux-gnueabihf-gcc是两个针对不同目标平台的交叉编译工具链。
arm-none-eabi-gcc是为嵌入式平台编译的工具链,使用Cortex-M处理器的嵌入式设备通常使用此工具链。特点是没有标准C库,因此需要使用嵌入式系统提供的函数库。
arm-none-linux-gnueabihf-gcc是针对运行Linux系统的ARM处理器的工具链。特点是包括标准C库,支持硬浮点运算(hard-float),并提供库函数和头文件供Linux系统使用。
我在developer.arm.com中为什么没有找到不带硬浮点运算的?
您可能没有找到不带硬浮点运算的工具链,因为从 ARM Compiler 6 开始,它已经默认使用硬浮点运算。这意味着,如果您想使用 ARM Compiler 6,您不能选择不使用硬浮点运算。
但是,ARM还提供了其他版本的工具链,例如ARM Compiler 5和GNU Toolchain,它们中的一些版本可能不支持硬浮点运算。请注意,选择正确的工具链版本取决于您的应用程序和目标处理器的需求。
s5pv210支持硬浮点吗?
S5PV210是一款由三星公司推出的Cortex-A8架构的处理器,支持硬浮点运算单元(hard-float unit),因此可以进行高速的浮点运算。
S5PV210的硬件架构还支持NEON(Advanced SIMD)指令集,这是一组增强的SIMD(单指令多数据)指令,可用于执行多媒体、信号处理等复杂运算,并能够显著提高运算性能。






![[Linux入门]---Linux项目自动化构建工具-make/Makefile](https://img-blog.csdnimg.cn/ae23cf9f3207488a9ac8ad363149c9f3.png)