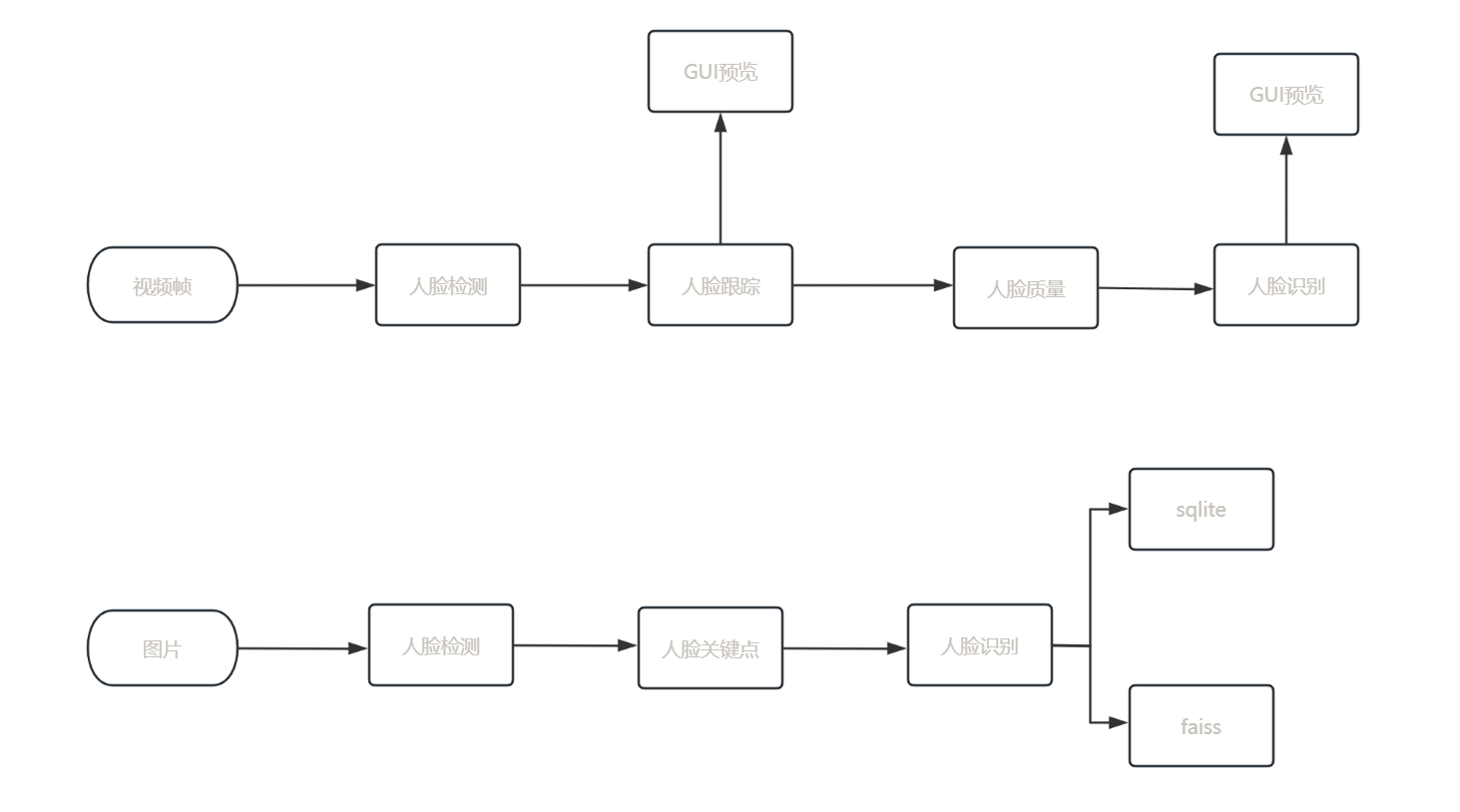
1、背景
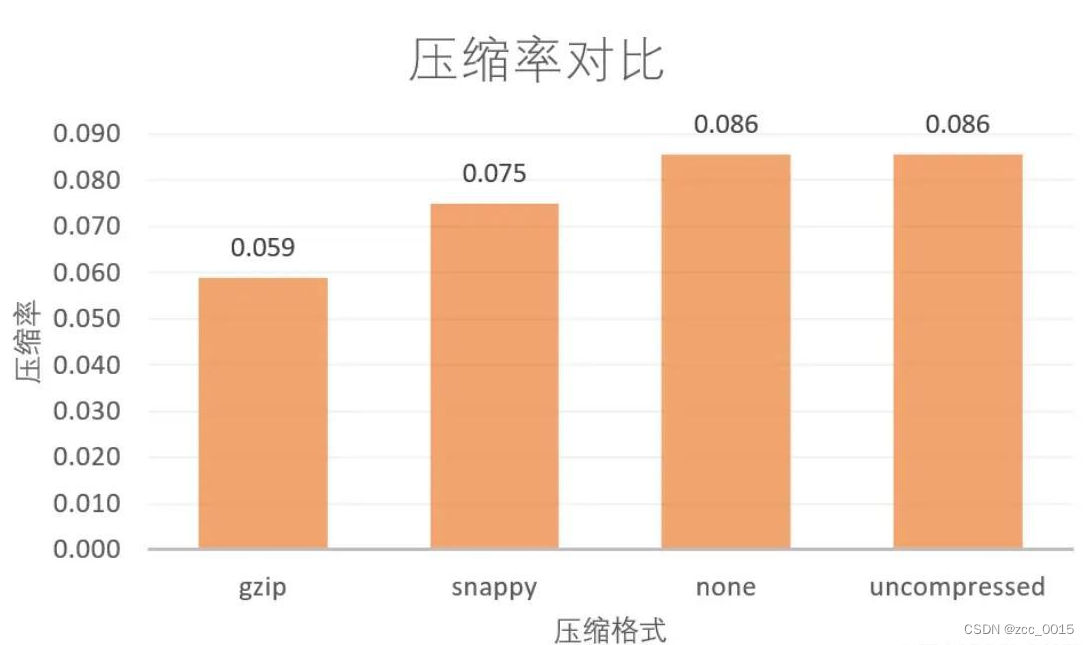
pg库存放了大量的历史数据,pg的存储方式比较耗磁盘空间,pg的备份方式,通过pgdump导出后,进行gzip压缩,压缩比大概1/10,随着数据的积累磁盘空间告警。为了解决pg的压力,尝试采用hive数据仓库存数,利用hive支持的parquet列式存储,同时支持lzo、none、uncompressed、brotil、snappy和gzip的压缩算法,更节省空间。pg同步到hive可以利用sqoop,sqoop的原理是将pg的表按一定的策略进行分批,然后并行导入以实现对大表的同步,本文尝试用spark对pg表进行读取,然后按指定的格式写入hdfs,然后与hive表进行绑定。
2、方案
2.1 spark读取pg的方法
(1)spark.read.jdbc(url, table, props)以该方式读取,默认只有一个分区,即单线程读取所有数据。该方式主要是表数据量小的本地测试,容易出现OOM问题。
(2)spark.read.jdbc(url, table, column, lower, upper, parts, props),以该方式读取,需要指定一个上届和下届,和一个分区数以及分区字段。但是这里注意,该分区字段必须是Int/Long的数值型,且该字段最好有索引,不然每个分区都是全表扫,且该方法只能全量读,比如该表有1000条记录,指定了下届是1,上届100,那么还是会读取全量1000的数据。所以该方式可以作为全量读取大表的一个方式,因为该方法会以多分区去读
(3)spark.read.jdbc(url, table, predicates, props)以该方式读取,需要指定一批分区条件这些分区条件会拼装到where后进行读取。这里注意,该条件字段可以是任意字段,但该字段最好有索引,不然每个并发都是全表扫,且该方法可以支持下推limit逻辑,比如该表有1000条记录,指定了根据id过滤,过滤条件是: id >= 1 and id <= 10,那么该方式只会读取10条记录,且可以按指定的分区去读。所以该方式可以作为读取超大表的一个方式,非常建议读取大表直接用该方式读取。
2.2 spark的parquet列式存储及压缩算法的对比
parquet是一种列式存储嵌套包含嵌套结构的数据集。RowGroup首先,要存储的对象是一个数据集,而这个数据集往往包含上亿条record,所以会进行一次水平切分,把这些record切成多个“分片”,每个分片被称为Row Group。为什么要进行水平切分?虽然Parquet的官方文档没有解释,但我认为主要和HDFS有关。因为HDFS存储数据的单位是Block,默认为128m。如果不对数据进行水平切分,只要数据量足够大(超过128m),一条record的数据就会跨越多个Block,会增加很多IO开销。Parquet的官方文档也建议,把HDFS的block size设置为1g,同时把Parquet的parquet.block.size也设置为1g,目的就是使一个Row Group正好存放在一个HDFS Block里面;Column Chunk在水平切分之后,就轮到列式存储标志性的垂直切分了。切分方式和上文提到的一致,会把一个嵌套结构打平以后拆分成多列,其中每一列的数据所构成的分片就被称为Column Chunk。最后再把这些Column Chunk顺序地保存。Page把数据拆解到Column Chunk级别之后,其结构已经相当简单了。对Column Chunk,Parquet会进行最后一次水平切分,分解成为一个个的Page。每个Page的默认大小为1m。尽管Parquet的官方文档又一次地没有解释,我认为主要是为了让数据读取的粒度足够小,便于单条数据或小批量数据的查询。因为Page是Parquet文件最小的读取单位,同时也是压缩的单位,如果没有Page这一级别,压缩就只能对整个Column Chunk进行压缩,而Column Chunk如果整个被压缩,就无法从中间读取数据,只能把Column Chunk整个读出来之后解压,才能读到其中的数据。
2.3 spark的partition的分区原理
HashPartitioner:一般是默认分区器,分析源码可知是按key求取hash值,再对hash值除以分区个数取余,如果余数<0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID。
RangePartitioner:由于HashPartitioner根据key值hash取模方法可能导致每个分区中数据量不均匀,RangePartitioner则尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,也就是说一个分区中的元素肯定都是比另一个分区内的元素小或者大;但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。参考:https://www.iteblog.com/archives/1522.html
GridPartitioner:一个网格Partitioner,采用了规则的网格划分坐标,numPartitions等于行和列之积,一般用于mlib中。
PartitionIdPassthrough:一个虚拟Partitioner,用于已计算好分区的记录,例如:在(Int, Row)对的RDD上使用,其中Int就是分区id。
CoalescedPartitioner:把父分区映射为新的分区,例如:父分区个数为5,映射后的分区起始索引为[0,2,4],则映射后的新的分区为[[0, 1], [2, 3], [4]]
PythonPartitioner:提供给Python Api的分区器
2.3 parquet文件格式与hive表的绑定
hive表的建表语句要与pg库保持一致,parquet是一种列式存储,同时可以按gz进行压缩。需要hive表在创建的时候指定Serde,Hive Serde用来做序列化和反序列化,构建在数据存储和执行引擎之间,对两者实现解耦,对于分隔符,写入hdfs文件存入的是parquet格式,org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,以行为\n,列为^A(\001)为分隔符,hive表是可以解析hdfs的,SerDe支持parquet。
3、 碰到的问题及解决
3.1 如何让spark的parquet格式使用gzip压缩
parquet默认采用的是snappy压缩算法,为了使得输出格式为gz.parquet,需要指定参数:
--conf spark.sql.parquet.compression.codec=gzip
3.2解决parquet.io.ParquetDecodingException: Can not read value at 0 in block -1 in file
该问题涉及到对decimal数据的支持问题。需要设置:
--conf spark.sql.parquet.writeLegacyFormat=true
该该参数(默认false)的作用:
(1)设置为true时,数据会以Spark1.4和更早的版本的格式写入。比如decimal类型的值会被以Apache Parquet的fixed-length byte array格式写出,该格式是其他系统例如Hive、Impala等使用的。
(2)设置为false时,会使用parquet的新版格式。例如,decimals会以int-based格式写出。如果Spark SQL要以Parquet输出并且结果会被不支持新格式的其他系统使用的话,需要设置为true。
4、同步效果
spark 3.2.2 hive-3.1.3 hadoop-3.3.4
用pg自带的hash函数分桶,执行过程cpu 80%
效果:5G的pg表,同步完200M





![[论文笔记]P-tuning v2](https://img-blog.csdnimg.cn/img_convert/dd505fa8137f31ec18647f439d986672.png)