- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
目录
- 环境
- 步骤
- 环境设置
- 引用包
- 全局设备对象
- 数据准备
- 数据集信息收集
- 图像预处理
- 读取数据集
- 读取数据集分类
- 划分出训练集和测试集
- 将数据划分为批次
- 模型设计
- 用于计算same卷积下padding的数值
- 编写C3模型中基本的卷积块
- 编写C3模型中基本的bottleneck块
- 编写C3模块
- 编写本任务的模型
- 模型训练
- 编写训练函数
- 定义训练参数
- 开始训练
- 模型效果展示
- 打印训练折线图
- 加载最佳模型进行预测
- 总结与思考
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
步骤
环境设置
引用包
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, random_split
from torchvision import datasets, transforms
import random, pathlib, copy
from PIL import Image
import matplotlib.pyplot as plt
from torchinfo import summary
import numpy as np
全局设备对象
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
数据集信息收集
data_path = 'weather_photos'
image_list = list(pathlib.Path(data_path).glob('*/*'))
# 打印一下图像的大小
for _ in range(5):
path = random.choice(image_list)
print(np.array(Image.open(str(path))).shape)
# 打印一下图像的内容
plt.figure(figsize=(20, 4))
for i in range(20):
plt.subplot(2, 10, i+1)
image = random.choice(image_list)
label = image.parts[-2]
path = str(image)
plt.imshow(Image.open(path))
plt.axis('off')
plt.title(label)
plt.show()


图像预处理
通过上面对图像初步的观察,图像的尺寸不一致,需要做一下缩放操作,弄成相同的尺寸
transform = transforms.Compose([
transforms.Resize([224, 224]), # 缩放到224x224
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
读取数据集
dataset = datasets.ImageFolder(data_path, transform=transform)
读取数据集分类
class_names = [k for k in dataset.class_to_idx]
print(class_names)
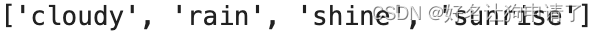
划分出训练集和测试集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
将数据划分为批次
batch_size = 32
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
用于计算same卷积下padding的数值
# 个人理解padding只和kernel_size有关,可是pytorch传入了stride就不能直接将padding设置为'same'了,因此需要一个方法计算padding的值
def same_padding(k, p=None):
if p is None:
p = k//2 if isinstance(k, int) else [ x//2 for x in k]
return p
编写C3模型中基本的卷积块
class Conv(nn.Module):
def __init__(self, in_size, out_size, kernel_size, stride=1, padding=None, groups=1, act=True):
super().__init__()
self.conv = nn.Conv2d(in_size, out_size, kernel_size, stride, padding=same_padding(kernel_size, padding), bias=False)
self.bn = nn.BatchNorm2d(out_size)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
x = self.act(self.bn(self.conv(x)))
return x
编写C3模型中基本的bottleneck块
class Bottleneck(nn.Module):
def __init__(self, in_size, out_size, shortcut=True, groups=1, expansion=0.5):
super().__int__()
hidden_size = int(out_size * expansion)
self.conv1 = Conv(in_size, hidden_size, 1)
self.conv2 = Conv(hidden_size, out_size, 3, groups=groups)
self.add = shortcut and in_size == out_size
def forward(self, x):
x = x + self.conv2(self.conv1(x)) if self.add else self.conv2(self.conv1(x))
return x
编写C3模块
class C3(nn.Module):
def __init__(self, in_size, out_size, neck_size=1, groups=1, expansion=0.5):
super().__init__()
hidden_size = int(expansion * out_size)
self.conv1 = Conv(in_size, hidden_size, kernel_size=1)
self.conv2 = Conv(in_size, hidden_size, kernel_size=1)
self.conv3 = Conv(2*hidden_size, out_size, kernel_size=1)
self.bottleneck = nn.Sequential(*(BottleNeck(hidden_size, hidden_size) for _ in range(neck_size)))
def forward(self, x):
x = self.conv3(torch.cat((self.conv2(x), self.bottleneck(self.conv1(x))), dim=1))
return x
编写本任务的模型
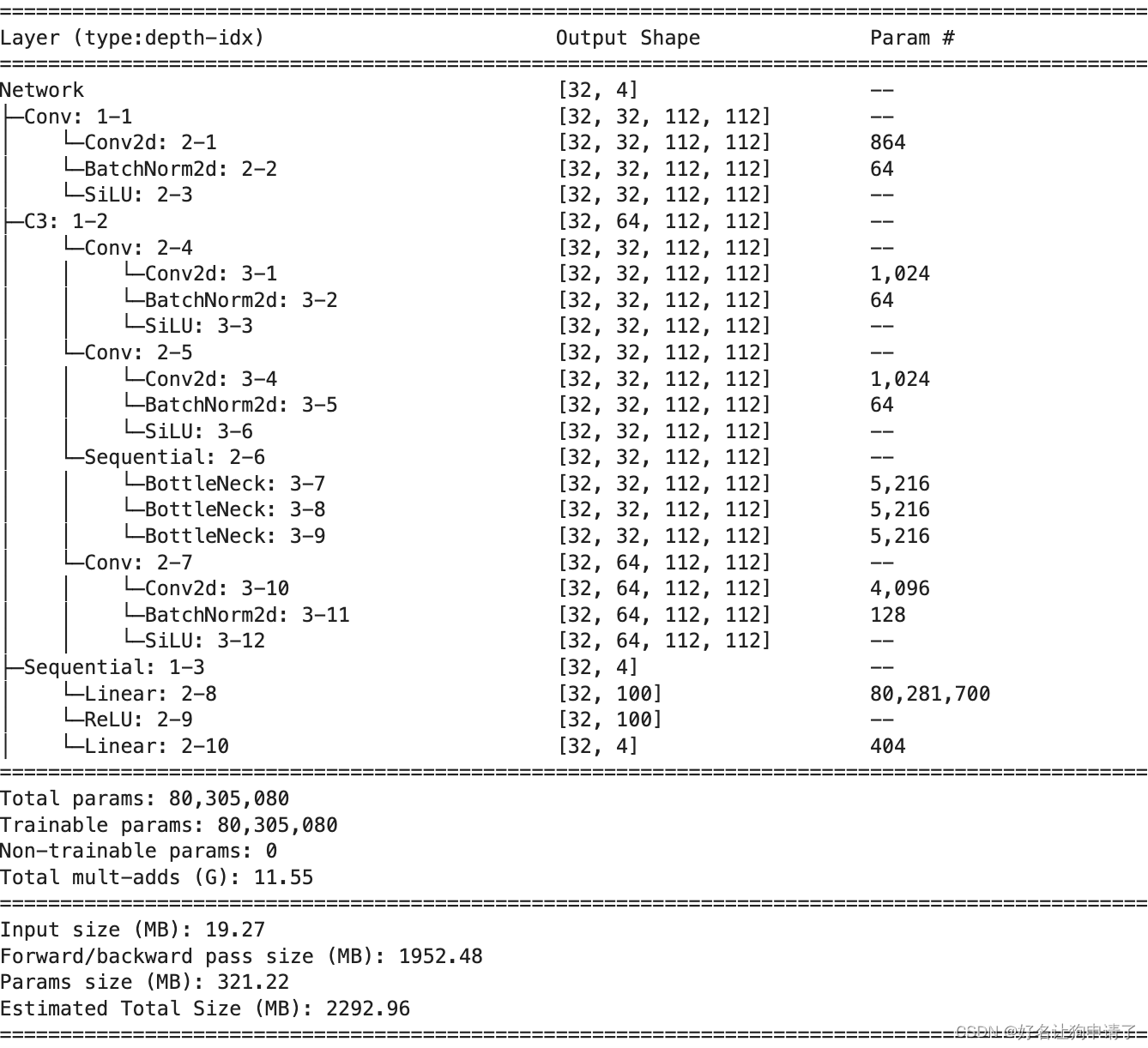
class Network(nn.Module):
def __init__(self, num_classes):
super().__init__()
# channel:3 -> channel:32,kernel_size = 3,
self.conv1 = Conv(3, 32, 3, 2)
self.c3_1 = C3(32, 64, 3)
self.classifier = nn.Sequential(
nn.Linear(802816, 100),
nn.ReLU(),
nn.Linear(100, num_classes)
)
def forward(self, x):
x = self.conv1(x)
x = self.c3_1(x)
x = x.view(x.size(0), -1)
x = slef.classifier(x)
return x
model = Network(len(class_names)).to(device)
summary(model, input_size=(32, 3, 224, 224))
print(model)

模型训练
编写训练函数
def train(train_loader, model, loss_fn, optimizer):
size = len(train_loader.dataset)
num_batches = len(train_loader)
train_loss, train_acc = 0, 0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_loss, train_acc
def test(test_loader, model, loss_fn):
size = len(test_loader.dataset)
num_batches = len(test_loader)
test_loss, test_acc = 0, 0
for x, y in test_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
test_loss += loss.item()
test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
test_acc /= size
return test_loss, test_acc
定义训练参数
epochs = 30
optimizer = optim.Adam(model.parameters(), lr=1e-4)
loss_fn = nn.CrossEntropyLoss()
best_model_path = 'best_weather_c3.pth'
best_acc = 0
开始训练
train_loss, train_acc = [], []
test_loss, test_acc = [], []
for epoch in range(epochs):
model.train()
epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)
model.eval()
with torch.no_grad():
epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)
train_loss.append(epoch_train_loss)
train_acc.append(epoch_train_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
if best_acc < epoch_test_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
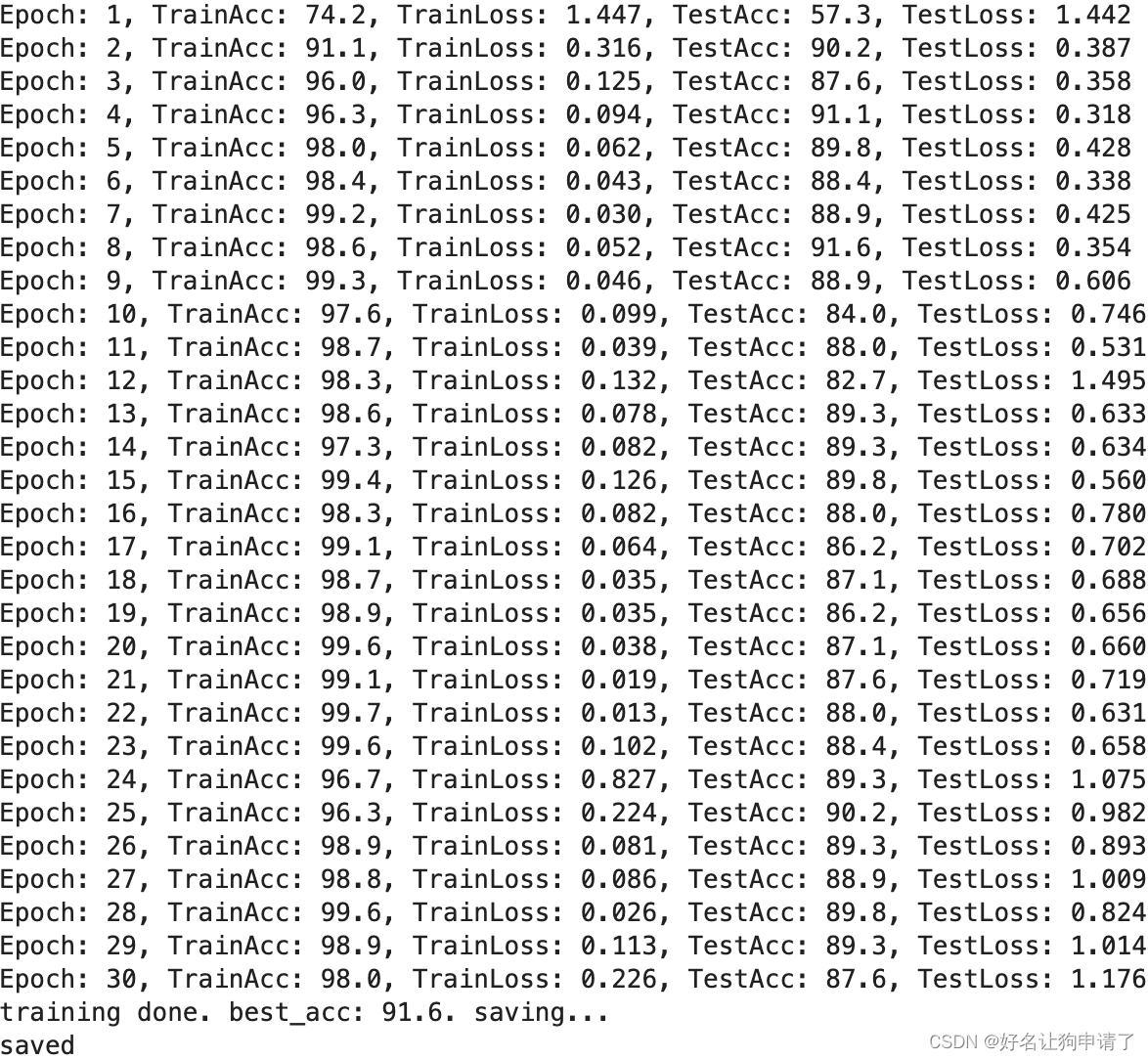
print(f'Epoch: {epoch+1}, TrainAcc: {epoch_train_acc*100:.1f}, TrainLoss: {epoch_train_loss:.3f}, TestAcc: {epoch_test_acc*100:.1f}, TestLoss: {epoch_test_loss:.3f}')
print(f'training done. best_acc: {best_acc*100:.1f}. saving...')
torch.save(best_model.state_dict(), best_model_path)
print('saved')
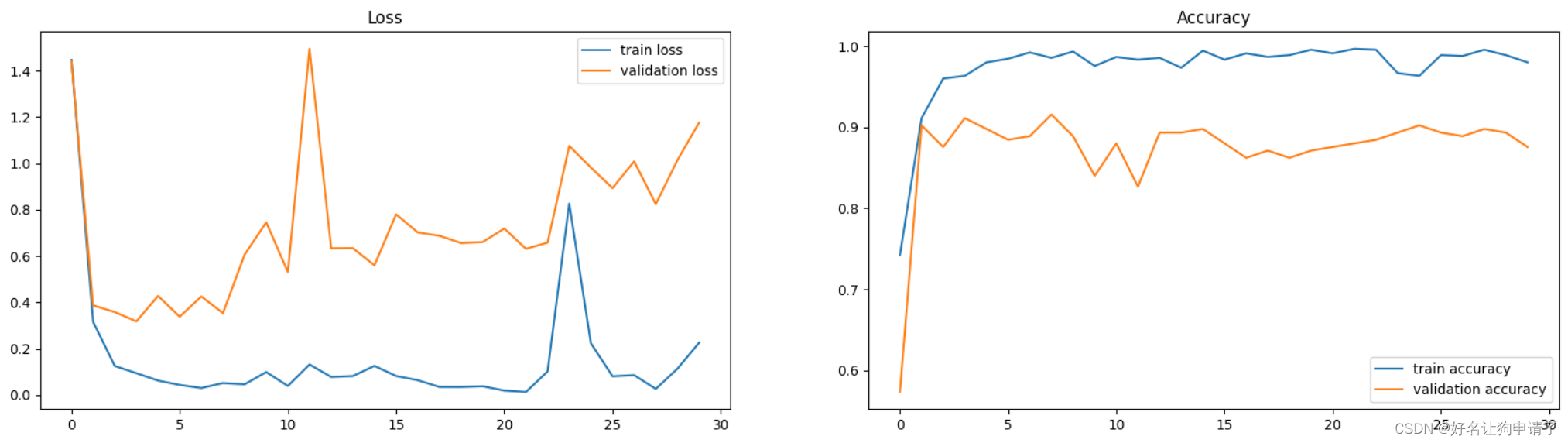
模型效果展示
通过30轮次的训练可以得到一个正确率有91.6%的模型,感觉是模型被训练的不充分。因为我前面的文章中,仅用了不到30万的参数就达到了95%以上的正确率。
打印训练折线图
epochs_range = range(epochs)
plt.figure(figsize=(10,5))
plt.subplot(121)
plt.plot(epochs_range, train_loss, label='train loss')
plt.plot(epochs_range, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.subplot(122)
plt.plot(epochs_range, train_acc, label='train accuracy')
plt.plot(epochs_range, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
plt.show()
加载最佳模型进行预测
model.load_state_dict(torch.load(best_model_path))
model.to(device)
image = random.choice(image_list)
true_label = image.parts[-2]
image = Image.open(str(image))
inputs = transform(image)
inputs = inputs.unsqueeze(0).to(device)
model.eval()
pred = model(inputs)
predict_label = class_names[pred.argmax(1).item()]
plt.figure(figsize=(5,5))
plt.imshow(image)
plt.title(f"real:{true_label}, predict:{predict_label}")
plt.axis('off')
plt.show()

总结与思考
- 1x1卷积用来操作通道数,此时特征图的大小不变
- bottleneck先将特征图通道数做压缩然后再还原到输入的通道数
- 深层的卷积神经网络保留多尺度特征的方式有两个:1. 高层特征,低层特征直接相加 2. 高层特征,低层特征堆叠在一起
- 使用的网络有8000万参数量,效果还不如前面的30万参数量的模型,不知道是否有一种粗略的标准,来拟合相同能力的模型参数量和数据量的对应关系。还有一种原因可能是C3模型被YOLO用来做目标检测,多尺度特征捕捉的能力在天气识别任务中可以说是毫无用处。

![[论文笔记]P-tuning v2](https://img-blog.csdnimg.cn/img_convert/dd505fa8137f31ec18647f439d986672.png)