一、数据中的缺省值
气象数据中经常存在缺省值,比如未入库的站点数据、比如海温格点实况数据中的陆地区域。这些缺省值往往被赋予NaN(Not a Number,非数)。NaN是计算机科学中数值数据类型的一类值,表示未定义或不可表示的值。
这些NaN值一般需要在计算时被去除掉,以免影响计算结果。那么,该怎么去除呢?
二、NaN的定义和特点
(一)如何设置nan
这里介绍两种方法设置一个变量为nan。
a = float('nan')
import numpy as np
a = np.nan
(二)如何判断一个数是nan
和设置nan的方式对应,也可以用np和math两种库函数来判断一个变量是否为nan。
import numpy
a = np.nan
if np.isnan(a):
print('这是个NaN!')
import math
a = math.nan
if math.isnan(a):
print('这是个NaN!')
需要说明一下,直接用==来判断是不行的。

(三)NaN的特点
NaN因为是Not a Number,所以它和所有数字变量(包括整数和浮点数,不论大小和正负)的所有判断(包括大于、小于和等于)都会返回false。
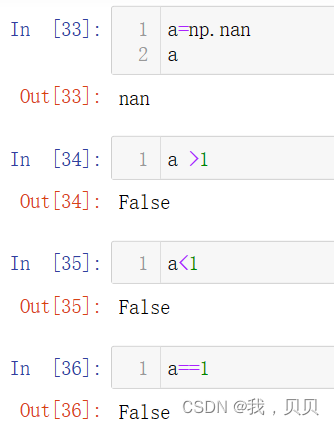
它和所有数字变量(包括整数和浮点数,不论大小和正负)的所有运算都会返回nan。

三、处理数据中的NaN
我这里把常用气象数据分为站点数据(一般存为dataframe格式)和格点数据(一般存为array、dataarrray或dataset格式)。
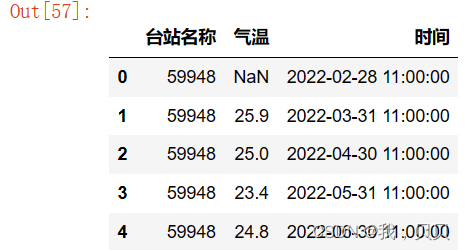
先编一个站点数据,设置一个数值为NaN。
import pandas as pd
import numpy as np
import datetime
df = pd.DataFrame({'台站名称':['59948']*5,'气温':[round(i,1)+25 for i in np.random.normal(0, 1, [5]).tolist()]})
df['时间'] = pd.date_range("2022-02-13 11", periods=5, freq='m')
df.loc[0,'气温'] = np.nan
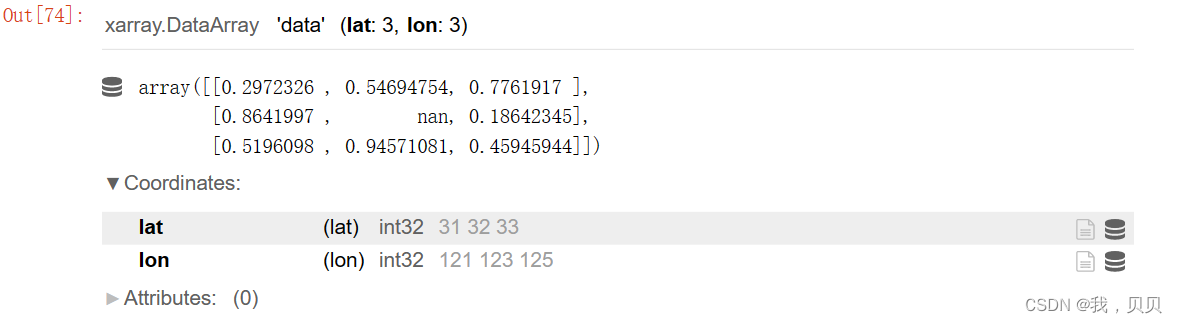
再编一个格点数据存为array,设置一个数值为NaN。
data = np.random.rand(3, 3)
data[1,1] = np.nan

在array的基础上构造dataarray。
#构造DataArray
import numpy as np
import xarray as xr
lat = [31,32,33]
lon = [121,123,125]
da = xr.DataArray(data, coords=[lat, lon], dims=["lat", "lon"])
da.name = 'data'
print(da)
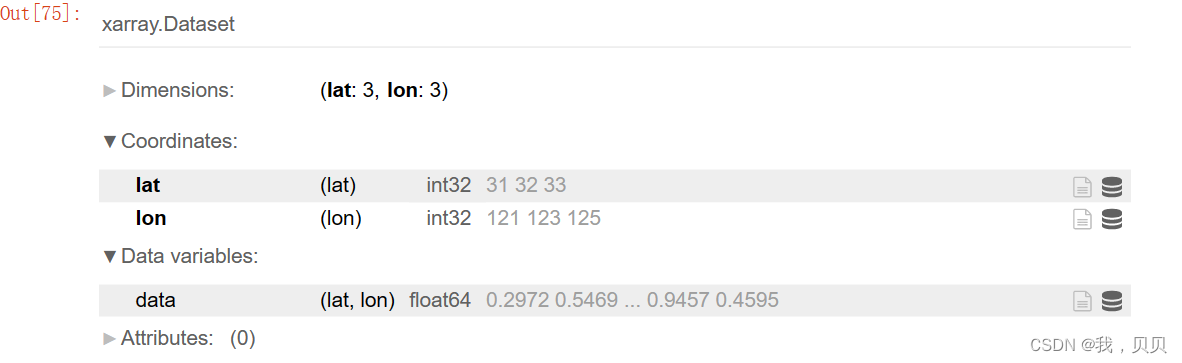
在dataarrray的基础上构造dataset。
ds = da.to_dataset(name = 'data')
(一)利用nan的特性在质控中直接去除
如果是想从数据中直接去除nan。那么,我们可以利用nan的“和所有数字变量(包括整数和浮点数,不论大小和正负)的所有判断(包括大于、小于和等于)都会返回false。”的特点,把去除nan这个步骤放在质量控制中常用的范围筛选中,直接筛除掉。
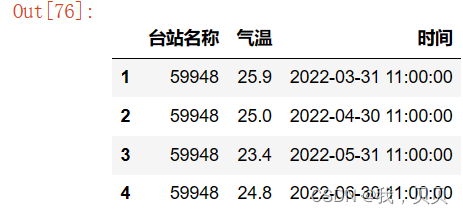
对dataframe格式:
df = df[df['气温']<50]
对array格式:
data[np.where(data<50)]
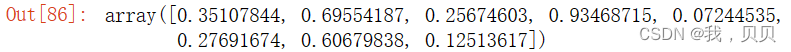
可以看到虽然nan值被去除掉了,但是3*3的array的形状已经变了(对于气象格点数据,二维的数据的每个点都自带经度和纬度,所以形状很重要,形状变了理解起来都困难了)。如果后续要做矩阵运算什么的,就不咋方便了。前面也说过,nan和数字之间的任何运算都返回nan,所以,大部分时候矩阵做加减乘除等运算,正常的点返回正常的计算值,nan返回nan,互不影响。不去除nan也不错。
对dataarray和dataset:
不能删除nan,只能替换nan。
xr.where(da <50,da,0)
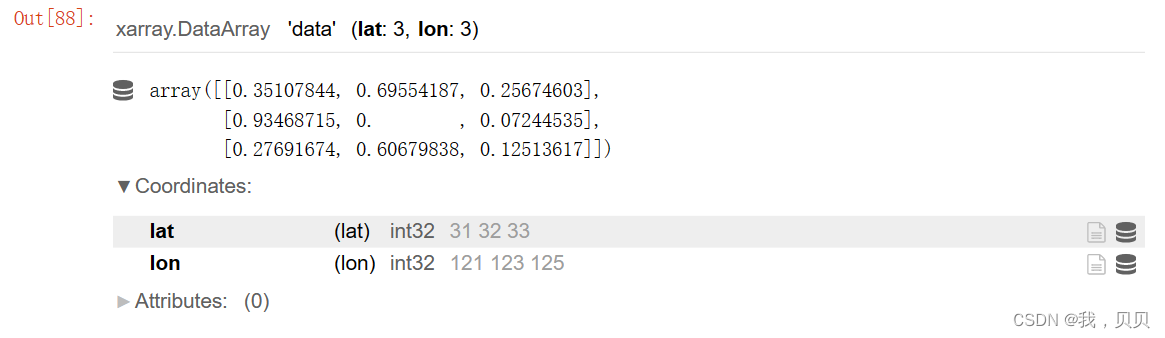
嗯,这样替代还不如不代呢。
对dataset甚至还有筛选条件后设置为nan的代码:
ds.where(ds.data < 50, drop=True)