图解GPT
除了BERT以外,另一个预训练模型GPT也给NLP领域带来了不少轰动,本节也对GPT做一个详细的讲解。
OpenAI提出的GPT-2模型(https://openai.com/blog/better-language-models/) 能够写出连贯并且高质量的文章,比之前语言模型效果好很多。GPT-2是基于Transformer搭建的,相比于之前的NLP语言模型的区别是:基于Transformer大模型、,在巨大的数据集上进行了预训练。在本章节中,我们将对GPT-2的结构进行分析,对GPT-2的应用进行学习,同时还会深入解析所涉及的self-attention结构。
语言模型和GPT-2
什么是语言模型
本文主要描述和对比2种语言模型:
- 自编码(auto-encoder)语言模型
- 自回归(auto-regressive)语言模型
先看自编码语言模型。
自编码语言模型典型代表就是BERT。如下图所示,自编码语言模型通过随机Mask输入的部分单词,然后预训练的目标是预测被Mask的单词,不仅可以融入上文信息,还可以自然的融入下文信息。
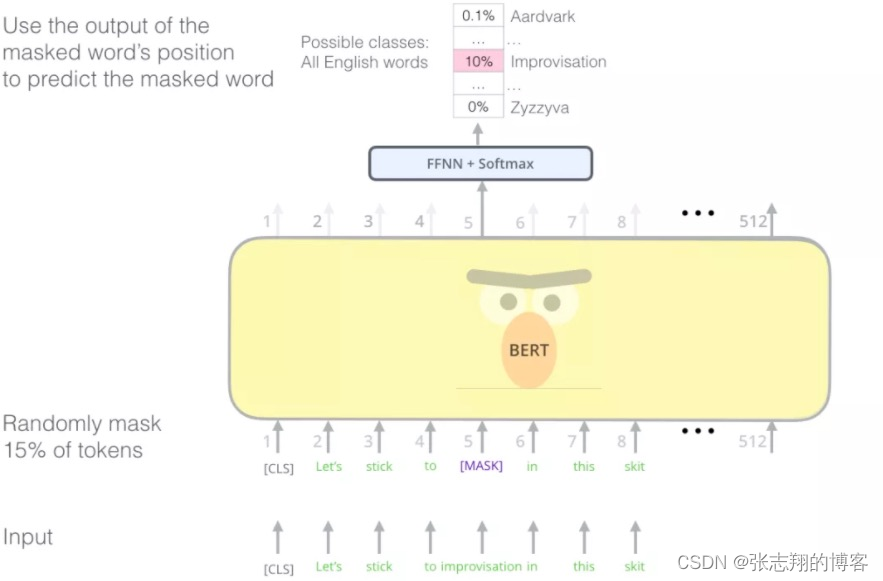
图: BERT mask
自编码语言模型的优缺点:
- 优点:自然地融入双向语言模型,同时看到被预测单词的上文和下文
- 缺点:训练和预测不一致。训练