目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 模型构建
- 1)定义模型结构
- 2)优化损失函数
- 3. 模型训练及保存
- 1)模型训练
- 2)模型保存
- 4. 模型应用
- 1)制作页面
- 2)模型导入及调用
- 3)模型应用代码
- 系统测试
- 1. 训练准确率
- 2. 测试效果
- 3. 模型应用
- 1)程序使用说明
- 2)测试结果
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
本项目采用了矩阵分解算法,用于对玩家已游玩的数据进行深入分析。它的目标是从众多游戏中筛选出最适合该玩家的游戏,以实现一种相对精准的游戏推荐系统。
首先,项目会收集并分析玩家已经玩过的游戏数据,包括游戏名称、游戏时长、游戏评分等信息。这些数据构成了一个大型的用户-游戏交互矩阵,其中每一行代表一个玩家,每一列代表一个游戏,矩阵中的值表示玩家与游戏之间的交互情况。
接下来,项目运用矩阵分解算法,将用户-游戏这稀疏矩阵用两个小矩阵——特征-游戏矩阵和用户-特征矩阵,进行近似替代。这个分解过程会将玩家和游戏映射到一个潜在的特征空间,从而能够推断出玩家与游戏之间的潜在关系。
一旦模型训练完成,系统可以根据玩家的游戏历史,预测他们可能喜欢的游戏。这种预测是基于玩家与其他玩家的相似性以及游戏与其他游戏的相似性来实现的。因此,系统可以为每个玩家提供个性化的游戏推荐,考虑到他们的游戏偏好和历史行为。
总的来说,本项目的目标是通过矩阵分解和潜在因子模型,提供一种更为精准的游戏推荐系统。这种个性化推荐可以提高玩家的游戏体验,同时也有助于游戏平台提供更好的游戏推广和增加用户黏性。
总体设计
本部分包括系统整体结构图和系统流程图。
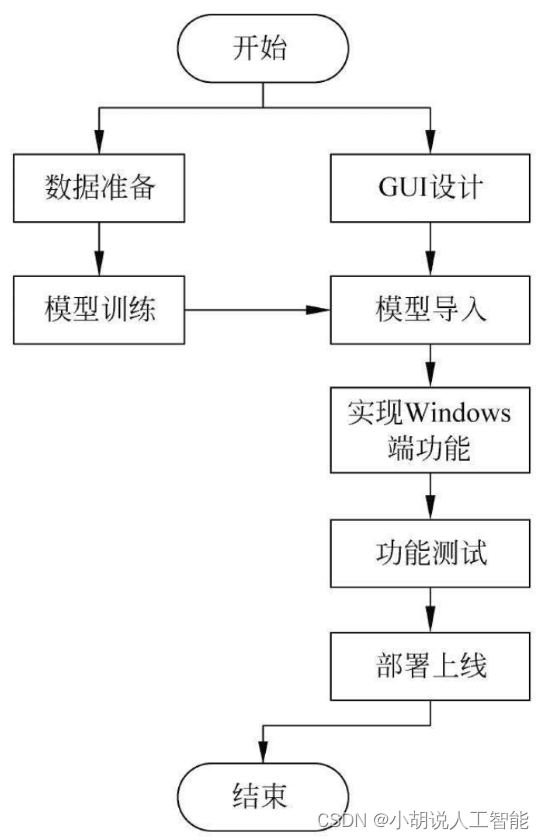
系统整体结构图
系统整体结构如图所示。
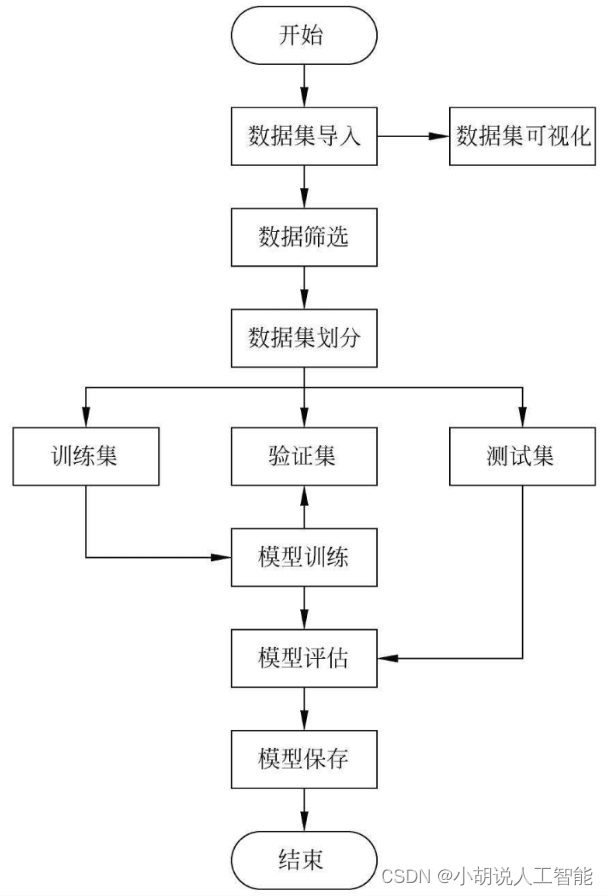
系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 环境、TensorFlow环境、 PyQt5环境。
详见博客:https://blog.csdn.net/qq_31136513/article/details/133148686#_38
模块实现
本项目包括4个模块:数据预处理、模型构建、模型训练及保存、模型测试,下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
数据集来源于Kaggle,链接地址为https://www.kaggle.com/tamber/steam-video-games,此数据集包含了用户的ID、游戏名称、是否购买或游玩、游戏时长,其中:共包含12393名用户,涉及游戏数量5155款。将数据集置于Jupyter工作路径下的steam-video-games文件夹中。
详见博客:https://blog.csdn.net/qq_31136513/article/details/133148686#1__97
2. 模型构建
数据加载进模型之后,需要定义模型结构,并优化损失函数。
1)定义模型结构
使用矩阵分解算法,将用户-游戏这稀疏矩阵用两个小矩阵——特征-游戏矩阵和用户-特征矩阵,进行近似替代。
详见博客:https://blog.csdn.net/qq_31136513/article/details/133151049#1_54
2)优化损失函数
L2范数常用于矩阵分解算法的损失函数中。因此,本项目的损失函数也引入了L2范数以避免过拟合现象。使用Adagrad优化器优化模型参数。
详见博客:https://blog.csdn.net/qq_31136513/article/details/133151049#2_91
3. 模型训练及保存
由于本项目使用的数据集中,将游戏的DLC (Downloadable Content,后续可下载内容)单独作为另一款游戏列举,因此,在计算准确率时,DLC和游戏本体判定为同一款游戏,同系列的游戏也可以判定为同一款。
详见博客:https://blog.csdn.net/qq_31136513/article/details/133151049#3__105
1)模型训练
详见博客:https://blog.csdn.net/qq_31136513/article/details/133151049#1_148
2)模型保存
为方便使用模型,需要将训练得到的结果使用Joblib进行保存。
详见博客:https://blog.csdn.net/qq_31136513/article/details/133151049#2_187
4. 模型应用
一是制作页面的布局,获取并检查输入的数据;二是将获取的数据-与之前保存的模型进行匹配达到应用效果。
1)制作页面
详见博客:https://blog.csdn.net/qq_31136513/article/details/133151109#1_80
2)模型导入及调用
详见博客:https://blog.csdn.net/qq_31136513/article/details/133151109#2_290
3)模型应用代码
详见博客:https://blog.csdn.net/qq_31136513/article/details/133151109#3_341
系统测试
本部分包括训练准确率、测试效果及模型应用。
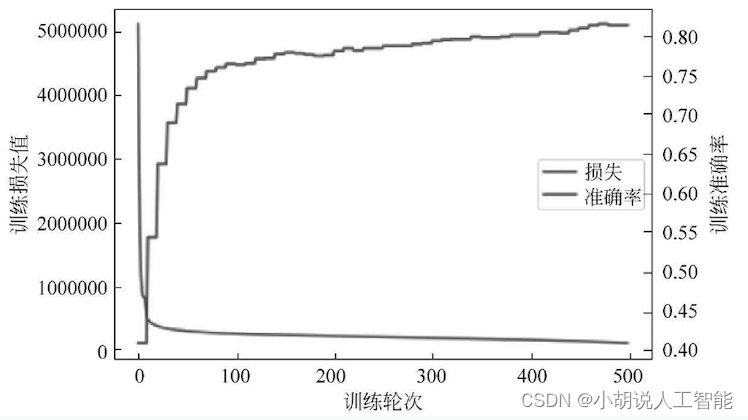
1. 训练准确率
训练集上的准确率达到81%以上,如图所示。
2. 测试效果
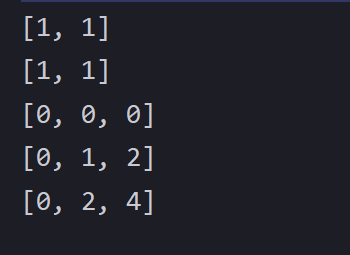
将数据代入模型进行测试,使用上述步骤中的准确度计算函数,推荐游戏与实际购买游戏进行对比。
相关代码如下:
import numpy as np
n_examples = 5
users = np.random.choice(test_users_idx, size=n_examples, replace=False)
rec_games = np.argsort(-rec)
for user in users:
purchase_history = np.where(train_matrix[user, :] != 0)[0]
recommendations = rec_games[user, :]
new_recommendations = recommendations[~np.in1d(recommendations, purchase_history)][:k]
print('给id为{0}的玩家推荐的游戏如下: '.format(idx2user[user]))
print(','.join([idx2game[game] for game in new_recommendations]))
print('玩家实际购买游戏如下: ')
print(','.join([idx2game[game] for game in np.where(test_matrix[user, :] != 0)[0]]))
precision = 100 * precision_at_k(new_recommendations, np.where(test_matrix[user, :] != 0)[0])
print('准确率: {:.2f}%'.format(precision))
print('\n')
测试集输出结果如图所示。

3. 模型应用
本部分包括程序使用说明和测试结果。
1)程序使用说明
打开程序,初始界面如图所示。
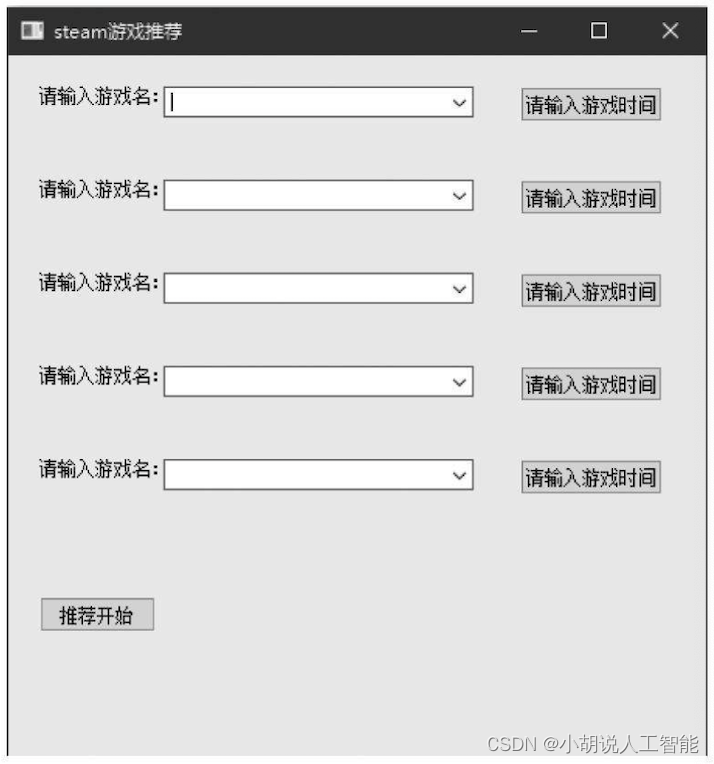
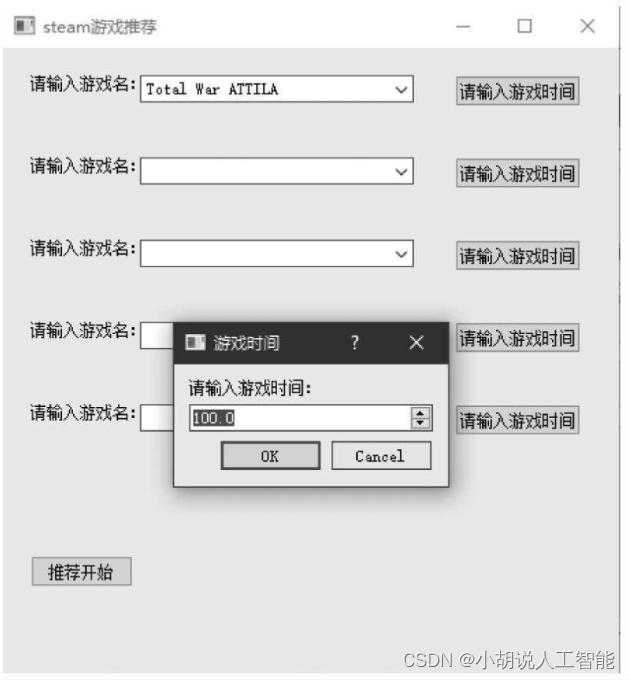
界面分为5个下拉输入框和6个按钮,通过输入或者选项选择游戏,单击“请输入游戏时间”的按钮,如图所示。

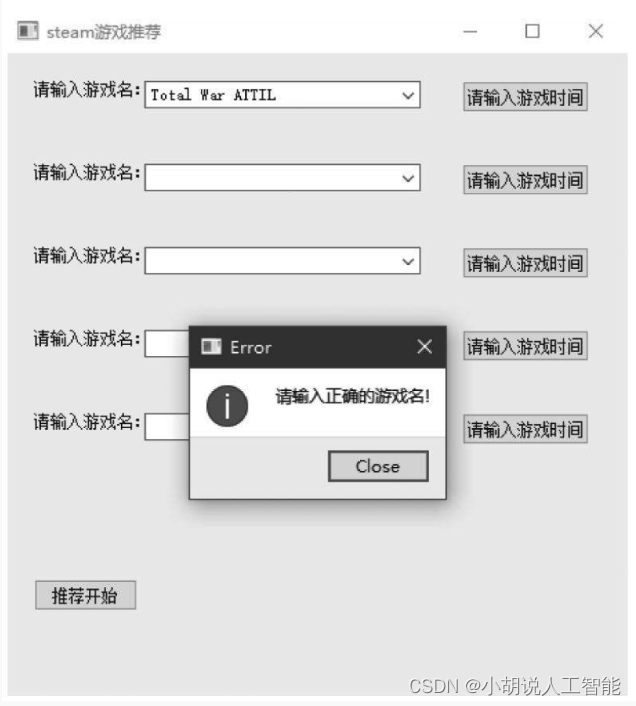
如果前面对应的游戏名输入正确,可以输入游戏时间,如图所示。
如果不正确,会弹出对话框,要求正确输入,如图所示。
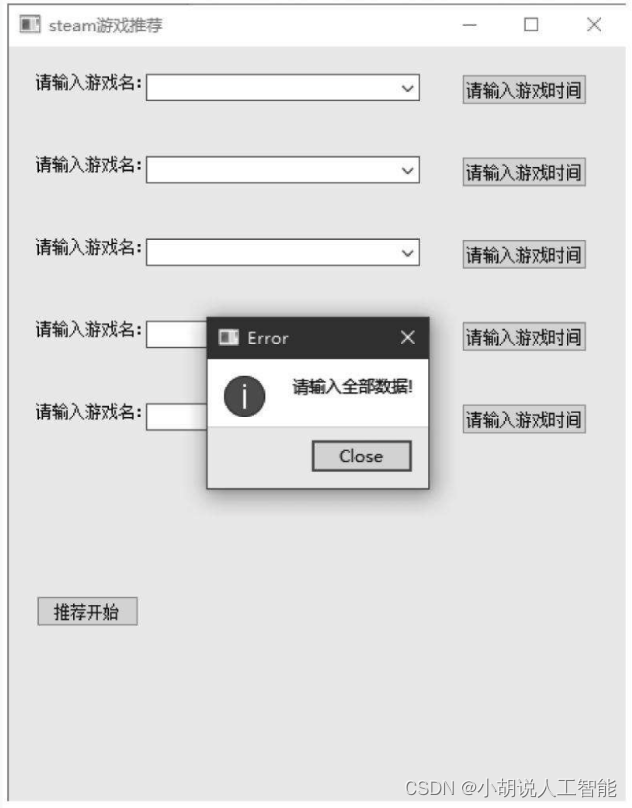
当所有数据被正确输入后,单击“推荐开始”按钮,弹出对话框,给出推荐的游戏,如图所示。

如果有数据未输入,则会弹出对话框,如图所示。
2)测试结果
测试结果如图所示。

相关其它博客
基于矩阵分解算法的智能Steam游戏AI推荐系统——深度学习算法应用(含python、ipynb工程源码)+数据集(一)
基于矩阵分解算法的智能Steam游戏AI推荐系统——深度学习算法应用(含python、ipynb工程源码)+数据集(二)
基于矩阵分解算法的智能Steam游戏AI推荐系统——深度学习算法应用(含python、ipynb工程源码)+数据集(三)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。