二、ArangoDB数据模型与索引
2.1 数据模型
ArangoDB的数据模型分为数据库(databse)、集合(collection)、文档(document),分别与RDBMS中的数据库、表、行对应。
数据类型包括:string、boolean、number、array、document/object
Collection:分为document collection、edge collection两种类型。其中documentcollection在Graph中又被称为vertex collection,edge collection只在Graph中使用。
Document: ArangoDB的document数据在展现层使用JSON格式,但物理存储时采用的是二进制的VelocyPack(一种高效紧凑的二进制序列化和存储格式)。document由一个主键(_key)、_id、_rev、0个或者多个属性组成,其中_key作为sharding的依据。Edgecollection中的文档要比documentcollection中的文档多两个特殊的属性(_from、_to)。
2.2 索引
ArangoDB中的索引类型分为:Primary、Edge、Hash、Skiplist、Persistent、Geo、Fulltext。ArangoDB会自动对文档中的_id、_key、_from、_to字段建立索引。
基本文档数据模型
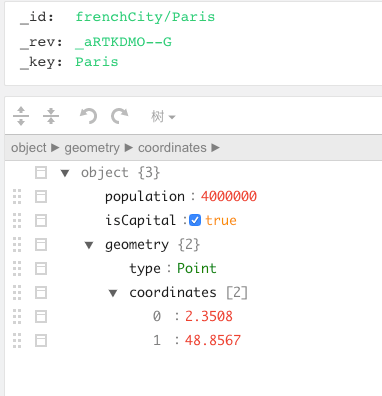
arangodb也有数据库(db), 表(collection)、记录(document)的概念,document上是有用户保存的,例如:
还额外有_id和_key,_rev
注:key可以自动生成也可以用户指定(不能存中文),而_id 等于表名加_key, _rev用的少。
图数据模型的存储结构
图模型的数据模型其实就是基于文档模型,只不过是节点放在document类型的表,和边信息放在edge类型的表。通过edge表里的_from 和_to字段指向的document类型表里的文档id来关联起的关系。 一切的处理是基于这两个表,就像mysql里的表一样,能支持想象不到的很多用处。 这两种表结构类似,唯一不同的是后者多了两个_from和_to字段用于指定起始和终点节点的_id 。
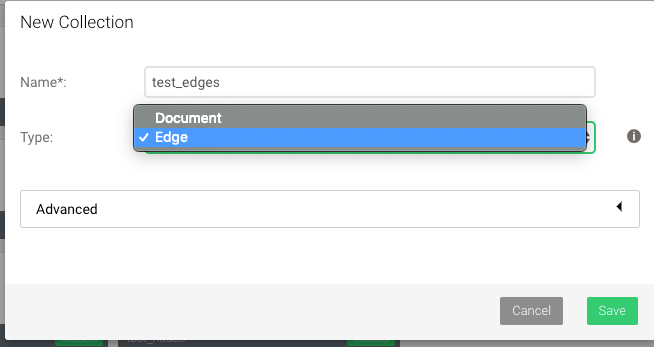
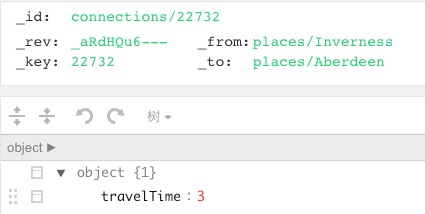
如何使用aql
(解释:在tablename表里面查询name都等于Alice并且age等1,2或是3的记录
let arr = [1,2,3]
for p in tablename
filter p.name == 'Alice'
filter contains(arr, p.age)
return p
(解释:在graph_large图里面查询起始点为nodes/id1,最长长度为3,最短长度为2的所有路径)
for v,e,p in 2..4
any
'nodes/id1'
graph 'graph_large'
return e




![web:[ACTF2020 新生赛]Include](https://img-blog.csdnimg.cn/823d78c0e209441b9e2eb0c0d27a7b70.png)