1. 背景说明
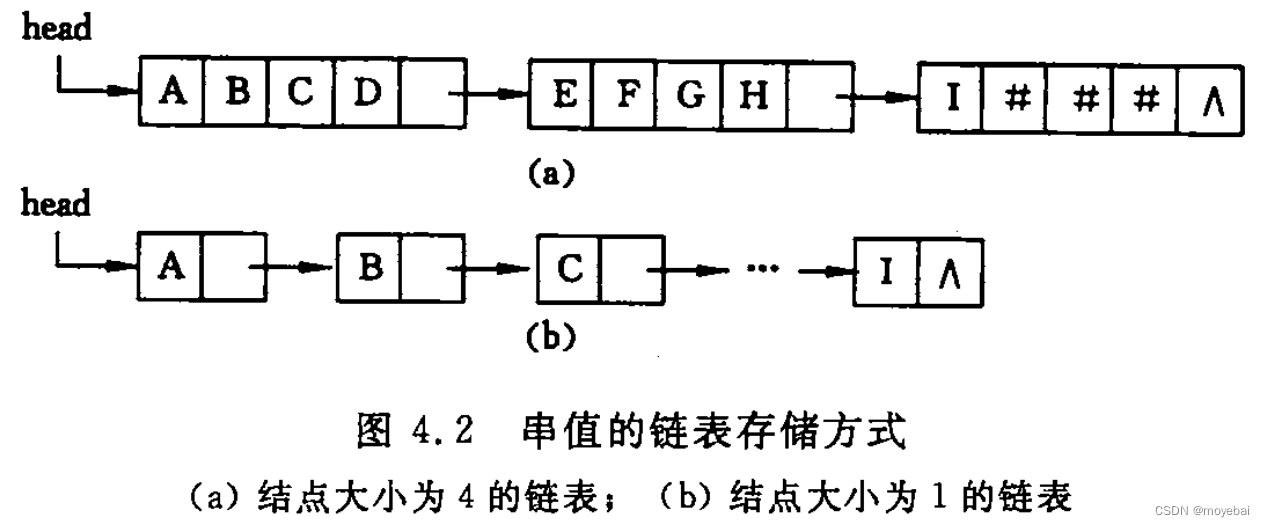
该实现和链表的实现极为相似,只是将链接的内存拆分为具体的大小的块。
2. 示例代码
1). status.h
/* DataStructure 预定义常量和类型头文件 */
#ifndef STATUS_H
#define STATUS_H
#define CHECK_NULL(pointer) if (!(pointer)) { \
printf("FuncName: %-15s Line: %-5d ErrorCode: %-3d\n", __func__, __LINE__, ERR_NULL_PTR); \
return NULL; \
}
#define CHECK_RET(ret) if (ret != RET_OK) { \
printf("FuncName: %-15s Line: %-5d ErrorCode: %-3d\n", __func__, __LINE__, ret); \
return ret; \
}
#define CHECK_VALUE(value, ERR_CODE) if (value) { \
printf("FuncName: %-15s Line: %-5d ErrorCode: %-3d\n", __func__, __LINE__, ERR_CODE); \
return ERR_CODE; \
}
#define CHECK_FALSE(value, ERR_CODE) if (!(value)) { \
printf("FuncName: %-15s Line: %-5d ErrorCode: %-3d\n", __func__, __LINE__, ERR_CODE); \
return FALSE; \
}
/* 函数结果状态码 */
#define TRUE 1 /* 返回值为真 */
#define FALSE 0 /* 返回值为假 */
#define RET_OK 0 /* 返回值正确 */
#define INFEASIABLE 2 /* 返回值未知 */
#define ERR_MEMORY 3 /* 访问内存错 */
#define ERR_NULL_PTR 4 /* 空指针错误 */
#define ERR_MEMORY_ALLOCATE 5 /* 内存分配错 */
#define ERR_NULL_STACK 6 /* 栈元素为空 */
#define ERR_PARA 7 /* 函数参数错 */
#define ERR_OPEN_FILE 8 /* 打开文件错 */
#define ERR_NULL_QUEUE 9 /* 队列为空错 */
#define ERR_FULL_QUEUE 10 /* 队列为满错 */
#define ERR_NOT_FOUND 11 /* 表项不存在 */
typedef int Status; /* Status 是函数的类型,其值是函数结果状态代码,如 RET_OK 等 */
typedef int Bollean; /* Boolean 是布尔类型,其值是 TRUE 或 FALSE */
#endif // !STATUS_H2) lString.h
/* 串的块链存储实现头文件 */
#ifndef LSTRING_H
#define LSTRING_H
#include "status.h"
#define CHUNK_SIZE 4
#define BLANK '#'
typedef struct Chunk {
char str[CHUNK_SIZE];
struct Chunk *next;
} Chunk;
typedef struct {
Chunk *head, *tail;
int curLen; /* 字符个数 */
} LString;
/* 初始化(产生空串)字符串 T */
Status InitString(LString *T);
/* 生成一个其值等于 chars 的串 T (要求 chars 中不包含填补空余的字符)
成功返回 OK,否则返回 ERROR */
Status StrAssign(const char *chars, LString *T);
/* 初始条件: 串 S 存在
操作结果: 由串 S 复制得串 T(连填补空余的字符一块拷贝) */
Status StrCopy(const LString *S, LString *T);
/* 初始条件:串 S 存在
操作结果:若 S 为空串,则返回 TRUE,否则返回 FALSE */
Bollean StrEmpty(const LString *S);
/* 若 S > T,则返回值 > 0;若 S = T,则返回值 = 0;若 S < T, 则返回值 < 0 */
int StrCompare(const LString *S, const LString *T);
/* 返回 S 的元素个数,称为串的长度 */
int StrLength(const LString *S);
/* 初始条件: 串 S 存在
操作结果: 将 S 清为空串 */
Status ClearString(LString *S);
/* 用 T 返回由 S1 和 S2 联接而成的新串 */
Status Concat(const LString *S1, const LString *S2, LString *T);
/* 用 Sub 返回串 S 的第 pos 个字符起长度为 len 的子串
其中, 1≤ pos ≤ StrLength(S) 且 0 ≤ len ≤ StrLength(S) - pos + 1 */
Status SubString(const LString *S, int pos, int len, LString *Sub);
/* T 为非空串。若主串 S 中第 pos 个字符之后存在与 T 相等的子串
则返回第一个这样的子串在 S 中的位置,否则返回 0 */
int Index(const LString *S, const LString *T, int pos);
/* 压缩串(清除块中不必要的填补空余的字符) */
Status Zip(LString *S);
/* 1 ≤ pos ≤ StrLength(S) + 1。在串 S 的第 pos 个字符之前插入串 T */
Status StrInsert(const LString *T, int pos, LString *S);
/* 从串 S 中删除第 pos 个字符起长度为 len 的子串 */
Status StrDelete(int pos, int len, LString *S);
/* 初始条件: 串 S, T 和 V 存在,T 是非空串(此函数与串的存储结构无关)
操作结果: 用 V 替换主串 S 中出现的所有与 T 相等的不重叠的子串 */
Status Replace(const LString *T, const LString *V, LString *S);
/* 输出字符串 T */
void StrPrint(const LString *T);
#endif // !LSTRING_H3) lString.c
/* 串的块链存储实现源文件 */
#include "lString.h"
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
/* 初始化(产生空串)字符串 T */
Status InitString(LString *T)
{
CHECK_VALUE(!T, ERR_NULL_PTR);
T->curLen = 0;
T->head = NULL;
T->tail = NULL;
return RET_OK;
}
/* 生成一个其值等于 chars 的串 T (要求 chars 中不包含填补空余的字符)
成功返回 OK,否则返回 ERROR */
Status StrAssign(const char *chars, LString *T)
{
CHECK_VALUE(!chars || !T, ERR_NULL_PTR);
int length = (int)strlen(chars);
CHECK_VALUE((length == 0) || strchr(chars, BLANK), ERR_PARA);
T->curLen = length;
int nodes = length / CHUNK_SIZE;
if (length % CHUNK_SIZE) {
nodes += 1;
}
Chunk *tail = NULL, *newNode = NULL;
for (int i = 0; i < nodes; ++i) {
newNode = (Chunk *)malloc(sizeof(Chunk));
CHECK_VALUE(!newNode, ERR_NULL_PTR);
if (i == 0) {
T->head = tail = newNode;
} else {
tail->next = newNode;
tail = newNode;
}
int j;
for (j = 0; (j < CHUNK_SIZE) && (*chars); ++j) {
*(tail->str + j) = *chars++;
}
if (!(*chars)) {
T->tail = tail;
tail->next = NULL;
while (j < CHUNK_SIZE) {
*(tail->str + j++) = BLANK;
}
}
}
return RET_OK;
}
/* 初始条件: 串 S 存在
操作结果: 由串 S 复制得串 T(连填补空余的字符一块拷贝) */
Status StrCopy(const LString *S, LString *T)
{
CHECK_VALUE(!S || !T, ERR_NULL_PTR);
Chunk *sHead = S->head, *newNode = NULL;
T->head = NULL;
while (sHead) {
newNode = (Chunk *)malloc(sizeof(Chunk));
CHECK_VALUE(!newNode, ERR_MEMORY_ALLOCATE);
newNode->next = NULL;
(void)memcpy_s(newNode, sizeof(Chunk), sHead, sizeof(Chunk));
if (T->head == NULL) {
T->head = T->tail = newNode;
} else {
T->tail->next = newNode;
T->tail = newNode;
}
sHead = sHead->next;
}
T->curLen = S->curLen;
return RET_OK;
}
/* 初始条件:串 S 存在
操作结果:若 S 为空串,则返回 TRUE,否则返回 FALSE */
Bollean StrEmpty(const LString *S)
{
CHECK_VALUE(!S, ERR_NULL_PTR);
return (S->curLen == 0) ? TRUE : FALSE;
}
static void GetNextCharPos(Chunk **node, int *order)
{
++(*order);
if (*order == CHUNK_SIZE) {
*node = (*node)->next;
*order = 0;
}
}
static void GetNextLegalCharPos(Chunk **node, int *order)
{
while (*((*node)->str + *order) == BLANK) {
GetNextCharPos(node, order);
}
}
/* 若 S > T,则返回值 > 0;若 S = T,则返回值 = 0;若 S < T, 则返回值 < 0 */
int StrCompare(const LString *S, const LString *T)
{
CHECK_VALUE(!S || !T, ERR_NULL_PTR);
Chunk *ps = S->head, *pt = T->head;
for (int i = 0, js = 0, jt = 0; (i < S->curLen) && (i < T->curLen); ++i) {
GetNextLegalCharPos(&ps, &js);
GetNextLegalCharPos(&pt, &jt);
if (*(ps->str + js) != *(pt->str + jt)) {
return *(ps->str + js) - *(pt->str + jt);
}
GetNextCharPos(&ps, &js);
GetNextCharPos(&pt, &jt);
}
return S->curLen - T->curLen;
}
/* 返回 S 的元素个数,称为串的长度 */
int StrLength(const LString *S)
{
CHECK_VALUE(!S, ERR_NULL_PTR);
return S->curLen;
}
/* 初始条件: 串 S 存在
操作结果: 将 S 清为空串 */
Status ClearString(LString *S)
{
CHECK_VALUE(!S, ERR_NULL_PTR);
Chunk *p = S->head, *q = NULL;
while (p) {
q = p->next;
free(p);
p = q;
}
S->head = S->tail = NULL;
S->curLen = 0;
return RET_OK;
}
/* 用 T 返回由 S1 和 S2 联接而成的新串 */
Status Concat(const LString *S1, const LString *S2, LString *T)
{
CHECK_VALUE(!S1 || !S2 || !T, ERR_NULL_PTR);
LString str1, str2;
InitString(&str1);
InitString(&str2);
StrCopy(S1, &str1);
StrCopy(S2, &str2);
T->head = str1.head;
str1.tail->next = str2.head;
T->tail = str2.tail;
T->curLen = str1.curLen + str2.curLen;
return RET_OK;
}
/* 用 Sub 返回串 S 的第 pos 个字符起长度为 len 的子串
其中, 1≤ pos ≤ StrLength(S) 且 0 ≤ len ≤ StrLength(S) - pos + 1 */
Status SubString(const LString *S, int pos, int len, LString *Sub)
{
CHECK_VALUE(!S || !Sub, ERR_NULL_PTR);
CHECK_VALUE((pos < 1) || (pos > S->curLen) || (len < 0) || (len > (S->curLen - pos + 1)), ERR_PARA);
int subLength = len / CHUNK_SIZE;
if (len % CHUNK_SIZE) {
subLength += 1;
}
Chunk *newNode = (Chunk *)malloc(sizeof(Chunk));
Sub->head = newNode;
Chunk *tail = Sub->head;
for (int i = 0; i < subLength - 1; ++i) {
newNode = (Chunk *)malloc(sizeof(Chunk));
tail->next = newNode;
tail = newNode;
}
tail->next = NULL;
Sub->tail = tail;
Sub->curLen = len;
int lastPos = len % CHUNK_SIZE;
if (lastPos) {
for (int i = lastPos; i < CHUNK_SIZE; ++i) {
*(newNode->str + i) = BLANK;
}
}
Chunk *subHead = Sub->head, *sHead = S->head;
int subPos = 0, count = 0;
Bollean isEnd = FALSE;
while (!isEnd) {
for (int i = 0; i < CHUNK_SIZE; ++i) {
if (*(sHead->str + i) == BLANK) {
continue;
}
++count;
if ((count >= pos) && (count <= pos + len - 1)) {
if (subPos == CHUNK_SIZE) {
subHead = subHead->next;
subPos = 0;
}
*(subHead->str + subPos) = *(sHead->str + i);
++subPos;
if (count == pos + len - 1) {
isEnd = TRUE;
break;
}
}
}
sHead = sHead->next;
}
return RET_OK;
}
/* T 为非空串。若主串 S 中第 pos 个字符之后存在与 T 相等的子串
则返回第一个这样的子串在 S 中的位置,否则返回 0 */
int Index(const LString *S, const LString *T, int pos)
{
CHECK_VALUE(!S || !T, ERR_NULL_PTR);
int maxRange = StrLength(S) - StrLength(T) + 1;
CHECK_VALUE((pos < 1) || (pos > maxRange), 0);
LString sub;
InitString(&sub);
while (pos <= maxRange) {
SubString(S, pos, StrLength(T), &sub);
if (StrCompare(T, &sub) == 0) {
return pos;
}
++pos;
}
return 0;
}
/* 压缩串(清除块中不必要的填补空余的字符) */
Status Zip(LString *S)
{
CHECK_VALUE(!S, ERR_NULL_PTR);
char *newStr = (char *)malloc(sizeof(char) * (unsigned int)(S->curLen + 1));
CHECK_VALUE(!newStr, ERR_NULL_PTR);
Chunk *sHead = S->head;
int count = 0;
while (sHead) {
for (int i = 0; i < CHUNK_SIZE; ++i) {
if (*(sHead->str + i) != BLANK) {
*(newStr + count) = *(sHead->str + i);
++count;
}
}
sHead = sHead->next;
}
*(newStr + count) = '\0';
ClearString(S);
StrAssign(newStr, S);
return RET_OK;
}
/* 1 ≤ pos ≤ StrLength(S) + 1。在串 S 的第 pos 个字符之前插入串 T */
Status StrInsert(const LString *T, int pos, LString *S)
{
CHECK_VALUE(!T || !S, ERR_MEMORY_ALLOCATE);
CHECK_VALUE((pos < 1) || (pos > StrLength(S) + 1), ERR_PARA);
LString t;
StrCopy(T, &t);
Zip(S);
int moveBlock = (pos - 1) / CHUNK_SIZE;
int insertPos = (pos - 1) % CHUNK_SIZE;
Chunk *sHead = S->head;
if (pos == 1) {
t.tail->next = S->head;
S->head = t.head;
} else if (insertPos == 0) {
for (int i = 0; i < moveBlock - 1; ++i) {
sHead = sHead->next;
}
Chunk *insertNext = sHead->next;
sHead->next = t.head;
t.tail->next = insertNext;
if (insertNext == NULL) {
S->tail = t.tail;
}
} else {
for (int i = 0; i < moveBlock; ++i) {
sHead = sHead->next;
}
Chunk *newBlock = (Chunk *)malloc(sizeof(Chunk));
CHECK_VALUE(!newBlock, ERR_NULL_PTR);
for (int i = 0; i < insertPos; ++i) {
*(newBlock->str + i) = BLANK;
}
for (int i = insertPos; i < CHUNK_SIZE; ++i) {
*(newBlock->str + i) = *(sHead->str + i);
*(sHead->str + i) = BLANK;
}
newBlock->next = sHead->next;
sHead->next = t.head;
t.tail->next = newBlock;
}
S->curLen += t.curLen;
Zip(S);
return RET_OK;
}
/* 从串 S 中删除第 pos 个字符起长度为 len 的子串 */
Status StrDelete(int pos, int len, LString *S)
{
CHECK_VALUE(!S, ERR_NULL_PTR);
CHECK_VALUE((pos < 1) || (pos > S->curLen - len + 1) || (len < 0), ERR_PARA);
int count = 0;
int currOrder = 0;
Chunk *sHead = S->head;
while (count < pos - 1) {
GetNextLegalCharPos(&sHead, &currOrder);
++count;
GetNextCharPos(&sHead, &currOrder);
}
++count;
if (*(sHead->str + currOrder) == BLANK) {
GetNextLegalCharPos(&sHead, &currOrder);
}
while (count < pos + len) {
GetNextLegalCharPos(&sHead, &currOrder);
*(sHead->str + currOrder) = BLANK;
++count;
GetNextCharPos(&sHead, &currOrder);
}
S->curLen -= len;
return RET_OK;
}
/* 初始条件: 串 S, T 和 V 存在,T 是非空串(此函数与串的存储结构无关)
操作结果: 用 V 替换主串 S 中出现的所有与 T 相等的不重叠的子串 */
Status Replace(const LString *T, const LString *V, LString *S)
{
CHECK_VALUE(!T || !V || !S, ERR_NULL_PTR);
CHECK_VALUE(StrEmpty(T), ERR_PARA);
int pos = 1;
do {
pos = Index(S, T, pos);
if (pos) {
StrDelete(pos, StrLength(T), S);
StrInsert(V, pos, S);
pos += StrLength(V);
}
} while (pos);
return RET_OK;
}
/* 输出字符串 T */
void StrPrint(const LString *T)
{
int count = 0;
Chunk *tHead = T->head;
while (count < T->curLen) {
for (int i = 0; i < CHUNK_SIZE; ++i) {
if (*(tHead->str + i) != BLANK) {
printf("%c", *(tHead->str + i));
++count;
}
}
tHead = tHead->next;
}
}4) main.c
/* 入口程序源文件 */
#include "lString.h"
#include <stdio.h>
void ShowStr(const LString *S, const char *stringName);
int main(void)
{
LString t1, t2, t3, t4;
InitString(&t1);
InitString(&t2);
InitString(&t3);
InitString(&t4);
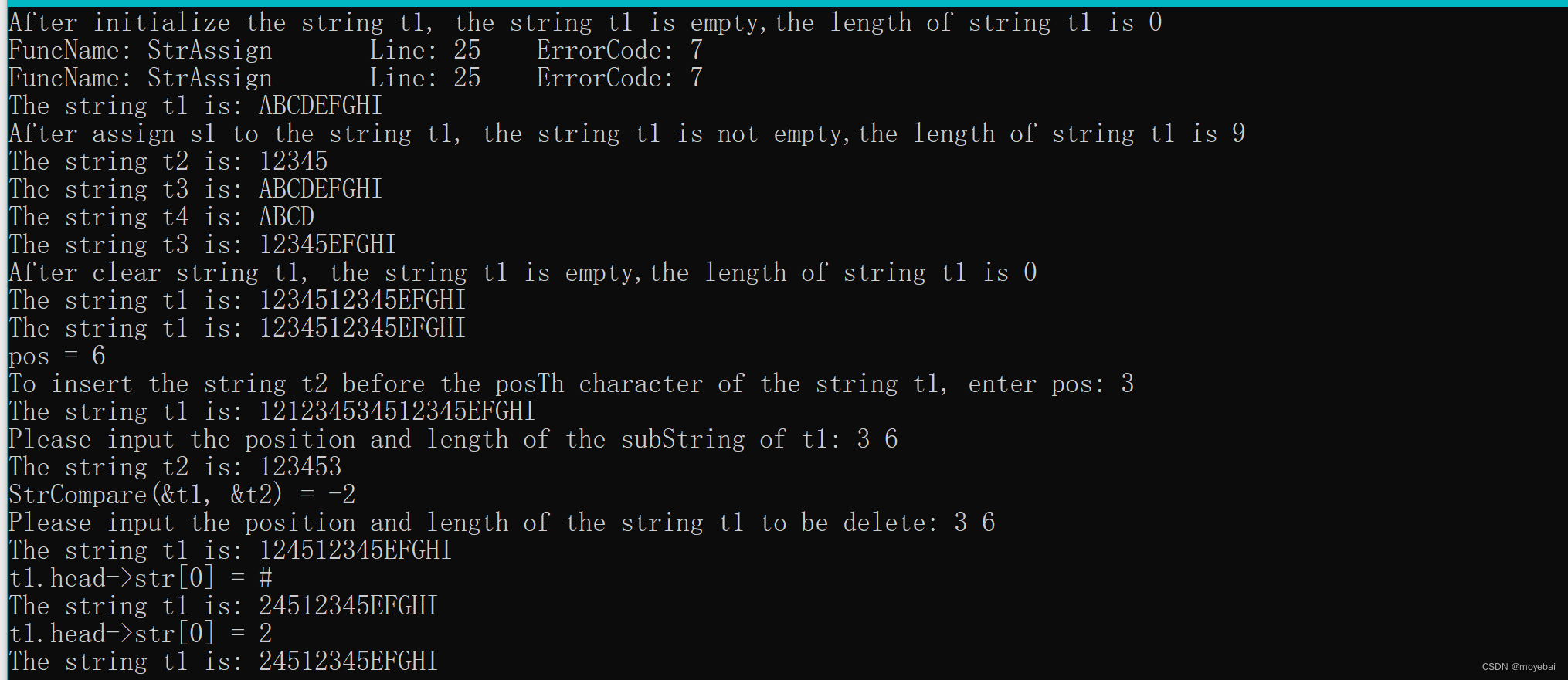
printf("After initialize the string t1, the string t1 is %s,"
"the length of string t1 is %d\n", (StrEmpty(&t1) == TRUE) ? "empty" : "not empty",
StrLength(&t1));
char *s1 = "ABCDEFGHI", *s2 = "12345", *s3 = "", *s4 = "asd#tr", *s5 = "ABCD";
Status ret = StrAssign(s3, &t1);
if (ret == RET_OK) {
ShowStr(&t1, "t1");
}
ret = StrAssign(s4, &t1);
if (ret == RET_OK) {
ShowStr(&t1, "t1");
}
ret = StrAssign(s1, &t1);
if (ret == RET_OK) {
ShowStr(&t1, "t1");
}
printf("After assign s1 to the string t1, the string t1 is %s,"
"the length of string t1 is %d\n", (StrEmpty(&t1) == TRUE) ? "empty" : "not empty",
StrLength(&t1));
ret = StrAssign(s2, &t2);
if (ret == RET_OK) {
ShowStr(&t2, "t2");
}
StrCopy(&t1, &t3);
ShowStr(&t3, "t3");
ret = StrAssign(s5, &t4);
if (ret == RET_OK) {
ShowStr(&t4, "t4");
}
Replace(&t4, &t2, &t3);
ShowStr(&t3, "t3");
ClearString(&t1);
printf("After clear string t1, the string t1 is %s,"
"the length of string t1 is %d\n", (StrEmpty(&t1) == TRUE) ? "empty" : "not empty",
StrLength(&t1));
Concat(&t2, &t3, &t1);
ShowStr(&t1, "t1");
Zip(&t1);
ShowStr(&t1, "t1");
int pos = Index(&t1, &t3, 1);
printf("pos = %d\n", pos);
printf("To insert the string t2 before the posTh character of the string t1, enter pos: ");
scanf_s("%d", &pos);
StrInsert(&t2, pos, &t1);
ShowStr(&t1, "t1");
int len;
printf("Please input the position and length of the subString of t1: ");
scanf_s("%d%d", &pos, &len);
ClearString(&t2);
SubString(&t1, pos, len, &t2);
ShowStr(&t2, "t2");
printf("StrCompare(&t1, &t2) = %d\n", StrCompare(&t1, &t2));
printf("Please input the position and length of the string t1 to be delete: ");
scanf_s("%d%d", &pos, &len);
StrDelete(pos, len, &t1);
ShowStr(&t1, "t1");
t1.head->str[0] = BLANK;
t1.curLen--;
printf("t1.head->str[0] = %c\n", t1.head->str[0]);
ShowStr(&t1, "t1");
Zip(&t1);
printf("t1.head->str[0] = %c\n", t1.head->str[0]);
ShowStr(&t1, "t1");
ClearString(&t1);
ClearString(&t2);
ClearString(&t3);
ClearString(&t4);
return 0;
}
void ShowStr(const LString *S, const char *stringName)
{
printf("The string %s is: ", stringName);
StrPrint(S);
printf("\n");
}3. 运行示例




![[PowerQuery] PowerAutoMate 刷新PowerBI 数据](https://img-blog.csdnimg.cn/0f070adf9dd342ad8ba1358fe4a4ad50.png)