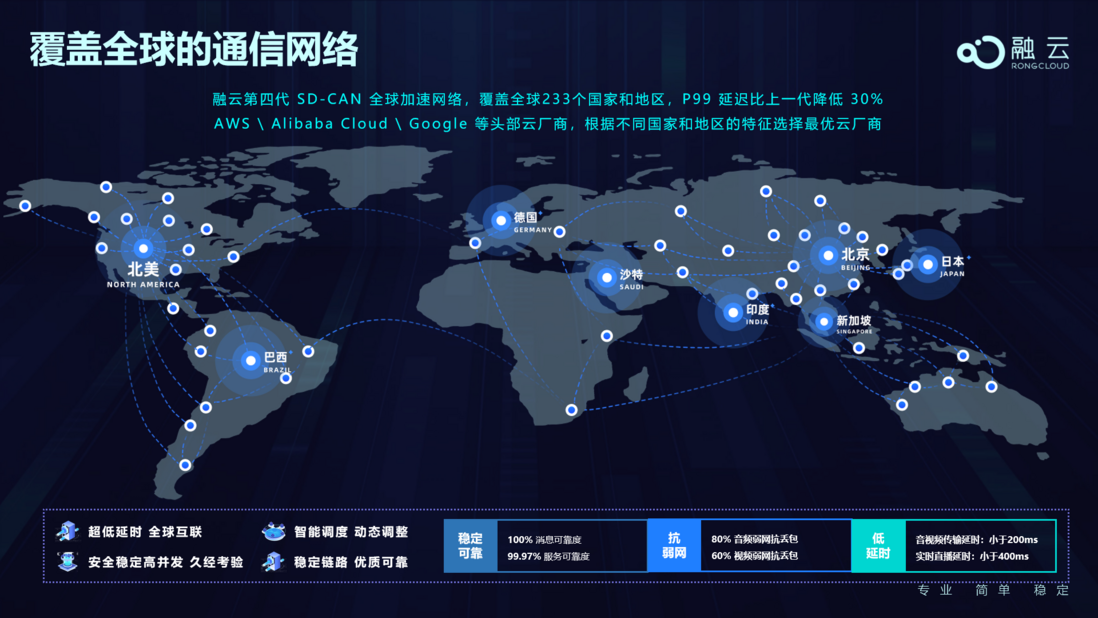
语言模型
从历史上来看, 自然语言处理的研究范式变化是从规则到统计, 从统计机器学习到基于神经网络的深度学习,这同时也是语言模型发展的历史。要了解语言模型的发展历史,首先我们需要认识什么是语言模型。语言模型的目标是建模自然语言的概率分布, 即确定语言中任意词序列的概率, 它提供了从概率统计角度 建模语言文字的独特视角。语言模型在自然语言处理中用广泛的应用, 在语音识别、语法纠错、机器翻译、语言生成等任务中均发挥着重要的作用。
自然语言处理的研究范式
简单来说,语言模型就是一串词序列的概率分布,语言模型的作用是为一个长度为 i 的文本确定一个概率分布P,表示这段文本存在的可能性,即:
语言模型的基本任务是在给定上下文 C = w1 , w2 , ..., wi-1 的情况下, 预测下一个词 wi 的条件概率 P (wi |C)。
问题在于,联合概率 P 的参数量十分巨大,如 i 代表句子的长度,N 代表单词的数量,那么词序列w1 , w2 , ..., wi 将具有以下的可能:N^i ,而这会带来巨大的模型参数量,以《牛津高阶英汉双解词典》为例子,其中收录了 185000 个单词,以每句平均长度15个单词,模型参数量将有: ,约为
。
与之相比, 宇宙中的原子数量大概在这个量级, 这实在是一个不可想象的天文数字, 以目前的计算手段无 法进行存储和运算。因此, 如何减少模型的参数量, 成为一个迫切需要解决的问题。其中的一种简化思路是,利用句子序列从左至右的生成过程来分解联合概率:
也就是说, 将词序列 的生成过程看成单词的逐个生成, 假设第 i 个单词的概率取决于前 i- 1 个单词。 需要指出的是, 这种将联合概率 P 转换为多个条件概率的乘积本身并未降低模型所需的参数量, 但是这种转换为接下来的简化提供了一种途径。
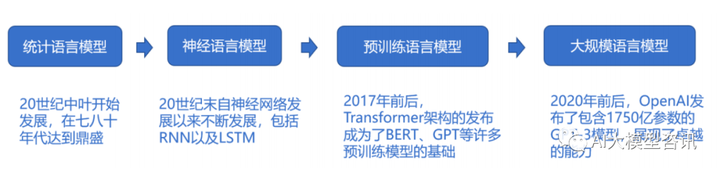
上面公式看到, 词 wi 出现的概率取决于它前面所有的词, 即使用链式法则, 即当前第 i 个词用哪一个, 完全取决于前 i- 1 个词, 我们在实际工作中会经常碰到文本长度较长情况, 的估算会非常困 难。因此, 为了实现对该数值的估算, 先后出现了 n-gram 统计语言模型, nnlm 前馈神经语言模型, 循环神经语 言模型,并最终形成当前大火的 Bert 预训练语言模型。
统计语言模型
统计语言模型语言模型, 是当前非规则自然语言处理的根基, 也是自然语言处理学科的精髓所在, 当我们在 判定一句话是否合适的时候, 可以通过计算概率的方式来判断该句子是否成立, 如果一个句子成立的概率很大, 那么这个句子是一个成立的句子概率就越大。1975 年,Frederick Jelinek 等人在论文《Continuous Speech Recognition by Statistical Methods》中提出并应用 n-gram 模型于语音识别任务, 也即所谓的元文法模型。根据上述假设, 词 的概率受前面 i- 1 个词的影响, 称为历史影响, 而估算这种概率最简单的方法是根据语料库, 计算词序列在语料库中出现的频次。
问题在于, 随着历史单词数量的增加, 这种建模方式所需的数据量会指数增长, 这就是维度灾难。此外, 当历史 单词序列越来越长,绝大多数的历史并不会在训练数据中出现,造成概率估计丢失。
为了解决上述问题,进一步假设任意单词的出现概率只和过去 n- 1 个词相关,即:
当 n 越大,历史信息也越完整,但是参数量也会增大。实际应用中, n 通常不大于 3
-
n=1 时,每个词的概率独立于历史,称为一元语法(Unigram)
-
n=2 时,词的概率只依赖前一个词,称为二元语法(Bigram)或一阶马尔可夫链
-
n=3 时,称为三元语法(Trigram)或者二阶马尔科夫链。
实际运用中, 由于语言具备无穷多可能性, 再庞大的训练语料也无法覆盖所有的 n 元语法, 而语料中的零 频次并不等于零概率, 因此还需要使用平滑技术来解决这一问题, 产生更合理的概率, 对所有可能出现的字符 串都分配一个非零概率值, 从而避免零概率问题。平滑是指为了产生更合理的概率, 对最大似然估计进行调整 的一类方法, 也称为数据平滑(Data Smoothing)。平滑处理的基本思想是提高低概率, 降低高概率, 使整体的概 率分布趋于均匀。
不过, 高阶 n 元语言模型面临严重的数据稀疏问题, 即存在一些明显的缺点:(1) 无法建模长度超过 n 的 上下文;(2) 依赖人工设计规则的平滑技术;(3) 当 n 增大时, 数据的稀疏性随之增大, 模型的参数量更是指 数级增加, 并且模型受到数据稀疏问题的影响, 其参数难以被准确的学习。此外, n 元文法中单词的离散表示也 忽略了单词之间的相似性。因此, 自神经网络发展以来, 神经语言模型逐渐成为新的研究热点, 所采用的技术 包括前馈神经网络、循环神经网络、长短期记忆循环神经网络语言模型等等。
PS:欢迎扫码关注微信公众号^-^.