01强化学习学习路线大纲
- 前言
- 强化学习脉络图
- 章节介绍
- Chapter 1:Basic Concepts
- Chapter 2:Bellman Equation
- Chapter 3:Bellman Optimality Equation
- Chapter 4:Value Iteration / Policy Iteration
- Chapter 5:Monte Carlo Learning
- Chapter 6:Stochastic Approximation
- Chapter 7:Temporal-Difference Learning
- Chapter 8:Value Function Approximation
- Chapter 9:Policy Gradient Methods
- Chapter 10:Actor-Critic Methods
前言
本文来自西湖大学赵世钰老师的B站视频。本文首先对要学习的内容做一个总结,没有基础的看不懂也很正常,可以先了解一下,后期学完各个章节之后再回头来看。
强化学习脉络图
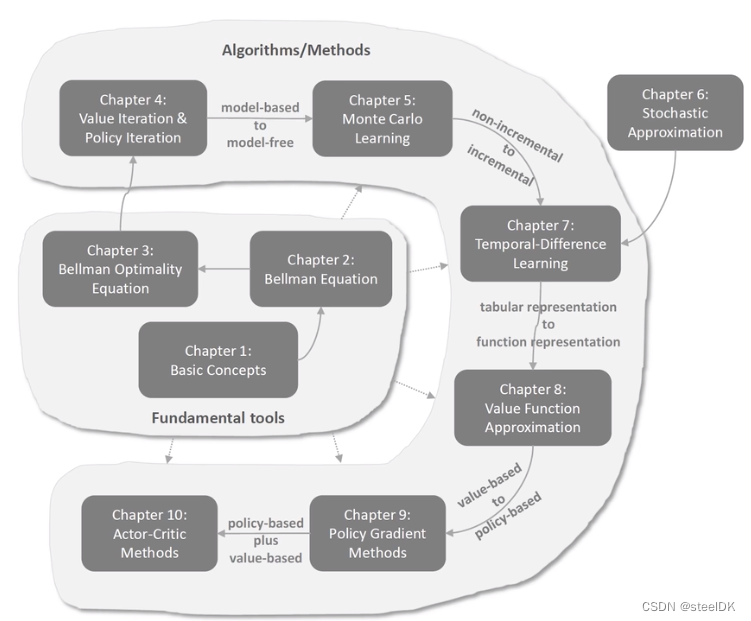
分成了两个板块,基本工具和算法方法。基本工具包括基本概念:贝尔曼公式、贝尔曼最优公式,算法和方法包括值迭代、策略迭代、蒙特卡洛方法、时序差分方法、基于value function approximation、policy Gradient Methonds、Actor-Critic Methods。
章节介绍
Chapter 1:Basic Concepts
基本概念:状态、动作、奖励、回报、episode、策略…。通过一个网格世界的例子,一个机器人找到目标区域的例子。之后会将这些概念放在Markov decision process(MDP)的框架下去介绍。
Chapter 2:Bellman Equation
第二章介绍贝尔曼公式。

这里要搞清一个概念(状态值)和一个工具(Bellman equation)以及它们之间的关系。状态值就是从一个状态出发,沿着一个策略所得到奖励汇报的一个平均值,状态值越高就越说明对应的策略越好,我评价了一个策略,得到了一个值,然后基于它的值再改进策略,就这样循环下去,最后就能得到一个最优的策略。
Chapter 3:Bellman Optimality Equation
贝尔曼最优公式实际上是贝尔曼公式的一个特殊情况,每一个贝尔曼公式都对应了一个策略,贝尔曼最优公式作为一个特殊的贝尔曼公式,对应最优策略,为什么要研究贝尔曼最优公式呢?就是因为它和最优策略有关系,这里就涉及到一个基础的问题,强化学习的终极目标是什么?强化学习的终极目标就是在求解最优策略。因此第三章非常重要。

最优策略的定义:沿着最优策略能够得到最大的状态值(重要)。最优策略很重要,那么如何分析它呢?需要用到一个工具,即贝尔曼最优公式。它写出来的形式其实是非常简洁的,是矩阵向量的形式。分析这个公式我们用到了不动点原理,不动点原理告诉了我们两个方面的性质,一个是判断最优的策略、最优的状态值到底存在不存在。最优的策略不一定是唯一的,但最优的状态值一定是唯一的。另一方面它能求解贝尔曼最优公式。
Chapter 4:Value Iteration / Policy Iteration
第一批能够求解最优策略的方法和算法是什么,包括值迭代、策略迭代和Truncated policy iteration。Truncated policy iteration是值迭代、策略迭代的统一化表达方式。这三个算法是迭代式算法,并且在每个迭代步骤当中有两个子步骤Policy update和value update,也就是说在当前时刻的策略不太好,此时进行估计该策略的值,进行策略评价,然后根据该策略的值来改进策略,改进之后再得到值,然后再改进如此反复迭代进行。Policy update和value update这两个步骤会不断地迭代,最后就能找到最优策略。

Chapter 5:Monte Carlo Learning
蒙特卡罗方法是最简单也是第一个不需要模型就能找到的最优策略的方法。没有模型实际上就是学习随机变量的期望,之前提到的state value、action value等都是随机变量的期望值,对x做随机采样,得到平均值,这个平均值就可有作为E(x)的一个很好的近似。总之,没模型要有数据,没数据的话要有模型,既没有模型也没有数据的话什么也学不了。
具体来说第五章介绍了三个算法,分别是MC Basic、MC Exploring Starts和MC ε-greedy。难度依次增加,MC Basic模型在实际中不能用,因为效率很低;
强化学习得学习是一环扣一环得,比如,这里要学会蒙特卡罗方法首先要学会Policy Iteration,要学Policy Iteration我们首先得知道value iteration,要学value iteration我们就得先知道Bellman optimality equation。
Chapter 6:Stochastic Approximation
本章学习随机近似理论。第一个问题是来估计一个随机变量的期望,我们想用这个例子来说明什么是non-incremental,什么是incremental。估计E(x)有两种方法,non-incremental的方法就是比如我有一万次采样,我要等所有的采样全部采到了,一次性求平均,就得到了E(x)的近似。incremental的思想是在最开始的时候对它有一个估计,这个估计可能不准,但是没关系,我们每得到一个采样就用这个采样来更新我们的估计,这样慢慢的我们的估计就会越来越准。
具体来说,第六章介绍了三个算法,如下:

总结:第六章的目的是为我们打基础。主要学习掌握增量式的算法的思想,以及SGD这个算法还有它的思想在后边都会有很广泛的应用。
Chapter 7:Temporal-Difference Learning
本章学习时序差分方法,时序差分是强化学习中非常经典的方法,具体介绍以下几种:

Chapter 8:Value Function Approximation
从第七章到第八章也存在一个比较大的鸿沟。从第七章到前边全都是基于表格形式的,比如说状态值Vπ(s),s是一个状态, 每一个状态都对应一个状态值,这些状态值存在一个表格或者向量当中,如果去访问或者修改的话都是非常容易的,但是如果状态非常多或者状态是连续的,那这种表格形式的效率就比较低下或者就不再适用了,这时我们就需要用函数的形式来进行代替,用V_(s,w),w是这个函数对应的参数,我们希望这个函数能和真实的Vπ(s)越接近越好。

总的来说,第八章我们引入了一个函数进来,而神经网络是函数非常好的表达方式,所以第八章神经网络首次进入到强化学习中。
Chapter 9:Policy Gradient Methods
从第八章到第九章也存在一个比较大的鸿沟,第八章之前全都是value-based方法,而第九章和第十章开始变成了policy-based方法。
value-based和policy-based方法的区别如下:
第八章有一个目标函数J(w),w是值函数的参数,我要更新值函数的参数使得这个值函数能够很好地近似或者估计出一个策略所对应的值,在这个基础上我再更新策略然后得到新的策略,然后在估计它的值,这样不断迭代。Policy gradient方法有些不一样,它是有一个目标函数J(θ),θ是策略的参数,这里我们也把策略从表格形式变成了函数的形式,所以我们是直接优化这个参数θ,即直接改变策略,慢慢的得到最优的策略。

Chapter 10:Actor-Critic Methods
Actor-Critic 方法实际上是把alue-based和policy-based方法相结合,更准确来说是把第八章和第九章中的内容结合在一起。