PyTorch深度学习实战(17)——多任务学习
- 0. 前言
- 1. 多任务学习
- 1.1 多任务学习基本概念
- 1.2 多任务学习优势
- 2. 模型与数据集分析
- 2.1 模型分析
- 2.2 数据集介绍
- 3. 实现年龄估计和性别分类
- 小结
- 系列链接
0. 前言
多任务学习( Multi-Task Learning, MTL )是一种常见的机器学习方法,用于同时处理和学习多个相关任务。在传统的单任务学习中,通常需要为每个任务训练一个独立的模型,而多任务学习则通过共享模型的特征表示来同时学习多个任务。例如,根据我们在猫狗分类和关键点检测中所学习的,我们能够训练神经网络对给定图像中的人物年龄或性别进行单独的预测,但是,我们尚未考虑如何根据单个图像同时预测年龄和性别。根据同一图像进行多项预测在实际场景中非常重要,因为同一张照片可能被用于同时进行多项预测。在本节中,将介绍多任务学习的基本概念,并构建模型同时执行多个不同类型的任务,包括预测人物的性别和年龄。
1. 多任务学习
1.1 多任务学习基本概念
多任务学习能够同时处理和学习多个相关任务,将多个互相关联的任务联合训练,从而提高模型的泛化能力和效果,使用一个或多个输入用于预测几个不同输出。在多任务学习中,多个不同的任务使用同一网络模型,模型同时学习多个任务的知识,从而更好地利用训练数据进行训练。例如,在自动驾驶中,模型需要识别障碍物、规划路线、提供适量的油门/制动和转向等,通过考虑相同的输入集(来自多个传感器)实时完成这些任务。
1.2 多任务学习优势
多任务学习的优势在于任务之间的相互促进和共享知识。通过将任务之间的相关性和依赖关系引入到共享模型中,可以提高整体性能、泛化能力和数据效率:
- 提升性能:通过共享底层特征表示,模型可以从不同任务中学习到更通用的特征,可以通过共享知识来提高任务的性能
- 泛化能力增强:多任务学习可以通过在不同但相关的任务上进行联合训练,帮助模型学习到更广泛、更全局的特征,从而提高其泛化能力
- 数据效率提高:当我们面对数据稀缺的情况时,多任务学习可以通过共享模型来利用任务之间的数据共享,提高数据的有效利用率
- 鲁棒性增强:多任务学习可以通过在不同任务之间共享特征,提高模型的鲁棒性和抗干扰能力。当一个任务面临异常或缺失数据时,其他任务可以提供额外的信息帮助模型更好地应对
多任务学习的应用领域广泛,如自然语言处理、计算机视觉、语音识别等,通过多任务学习可以共享底层的语义表示,提高任务的整体效果。
2. 模型与数据集分析
2.1 模型分析
在本节中,我们将学习如何在单个前向传递中同时进行连续值预测和离散值(类别)预测。构建模型策略如下:
- 导入相关库
- 获取包含人物图像、性别和年龄信息的数据集
- 预处理数据并创建训练和测试数据集
- 构建模型:
- 特征提取层使用预训练VGG19模型
- 创建两个分支独立层,其中一层对应于年龄估计,另一层对应于性别分类
- 每个输出分支都有不同的损失函数,年龄是一个连续值(计算
mse或mae损失),而性别是一个分类值(计算交叉熵损失) - 对年龄估计损失和性别分类损失加权求
- 通过反向传播优化权重值来最小化整体损失
- 训练模型并预测新图像
2.2 数据集介绍
为了构建多分类模型,我们将使用 FairFace 数据集,FairFace 数据集是一个用于面部分析和人脸识别的多样性人脸数据集,由 FairFace 团队于 2019 年发布。FairFace 数据集的目标是提供一个包含多种族、性别和年龄的真实世界人脸图像集合,以便研究人员可以训练和评估面部识别算法在多样性群体中的表现。该数据集包含了 87,022 个标记的人脸图像,下载使用此数据集,提取码:cr6n。
3. 实现年龄估计和性别分类
接下来,使用 PyTorch 实现多任务学习模型。
(1) 导入相关库:
import torch
import numpy as np, cv2, pandas as pd, time
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, models
device = 'cuda' if torch.cuda.is_available() else 'cpu'
(2) 加载下载完成的数据集,查看数据结构:
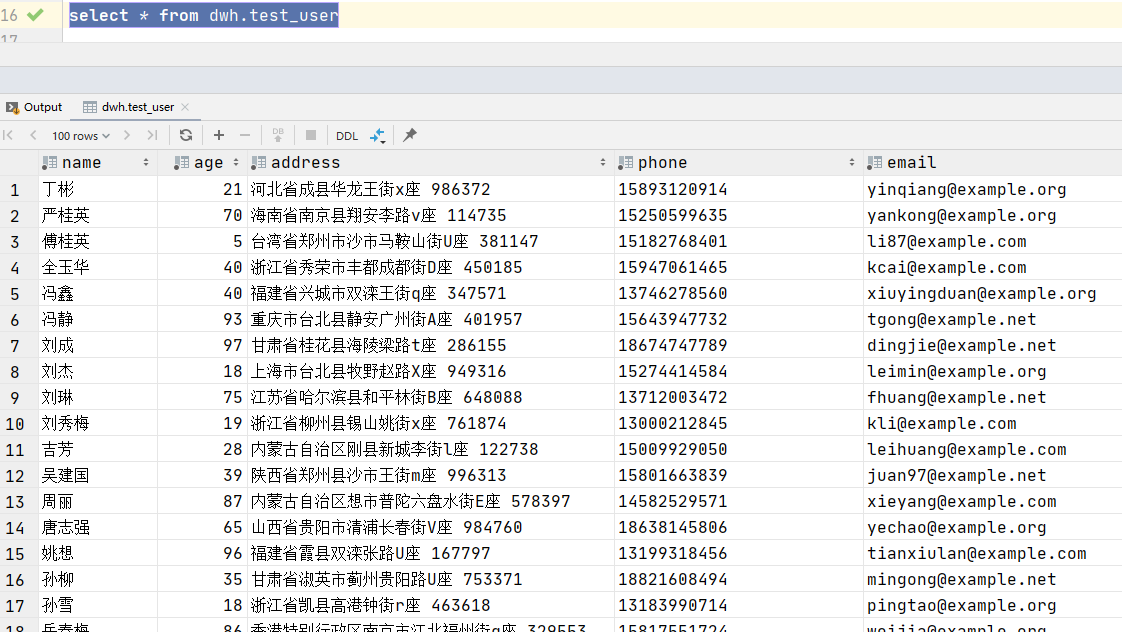
trn_df = pd.read_csv('fairface-labels-train.csv')
val_df = pd.read_csv('fairface-labels-val.csv')
print(trn_df.head())
输出结果如下所示:
file age gender race service_test
0 train/1.jpg 59 Male East Asian True
1 train/2.jpg 39 Female Indian False
2 train/3.jpg 11 Female Black False
3 train/4.jpg 26 Female Indian True
4 train/5.jpg 26 Female Indian True
(3) 构建 GenderAgeClass 类,以文件名作为输入并返回相应的图像、性别和年龄。其中,年龄需要缩放,因为这是一个连续的数字,缩放数据以避免梯度消失,然后在后处理期间重新进行还原。
在 __init__ 方法中以图像的文件路径作为输入:
IMAGE_SIZE = 224
class GenderAgeClass(Dataset):
def __init__(self, df, tfms=None):
self.df = df
self.normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
使用 __len__ 方法返回输入中图像数量:
def __len__(self):
return len(self.df)
定义 __getitem__ 方法,获取给定位置 ix 的图像信息:
def __getitem__(self, ix):
f = self.df.iloc[ix].squeeze()
file = f.file
gen = f.gender == 'Female'
age = f.age
im = cv2.imread(file)
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
return im, age, gen
编写图像预处理函数,包括调整图像大小、调整图像通道以及图像归一化:
def preprocess_image(self, im):
im = cv2.resize(im, (IMAGE_SIZE, IMAGE_SIZE))
im = torch.tensor(im).permute(2,0,1)
im = self.normalize(im/255.)
return im[None]
创建 collate_fn 方法,该方法用于对批数据执行以下预处理:
- 使用
process_image方法处理每个图像 - 缩放年龄(除以数据集中存在的最大年龄值——
80),令所有值都介于0和1之间 - 将性别转换为浮点值
- 将图像、年龄和性别转换为张量对象并返回
def collate_fn(self, batch):
'preprocess images, ages and genders'
ims, ages, genders = [], [], []
for im, age, gender in batch:
im = self.preprocess_image(im)
ims.append(im)
ages.append(float(int(age)/80))
genders.append(float(gender))
ages, genders = [torch.tensor(x).to(device).float() for x in [ages, genders]]
ims = torch.cat(ims).to(device)
return ims, ages, genders
(4) 定义训练和验证数据集以及数据加载器。
创建数据集:
trn = GenderAgeClass(trn_df)
val = GenderAgeClass(val_df)
构建数据加载器:
train_loader = DataLoader(trn, batch_size=32, shuffle=True, drop_last=True, collate_fn=trn.collate_fn)
test_loader = DataLoader(val, batch_size=32, collate_fn=val.collate_fn)
a,b,c, = next(iter(train_loader))
print(a.shape, b.shape, c.shape)
# torch.Size([32, 3, 224, 224]) torch.Size([32]) torch.Size([32])
(5) 定义模型、损失函数和优化器。
在函数 get_model() 中,加载预训练 VGG16 模型:
def get_model():
model = models.vgg16(pretrained = True)
冻结加载的模型(指定参数 param.requires_grad = False):
for param in model.parameters():
param.requires_grad = False
使用自定义网络层替换 avgpool 层:
model.avgpool = nn.Sequential(
nn.Conv2d(512,512, kernel_size=3),
nn.MaxPool2d(2),
nn.ReLU(),
nn.Flatten()
)
构建名为 ageGenderClassifier 的神经网络类,以创建包含两个输出分支的神经网络:
class ageGenderClassifier(nn.Module):
def __init__(self):
super(ageGenderClassifier, self).__init__()
定义中间层 intermediate:
self.intermediate = nn.Sequential(
nn.Linear(2048,512),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(512,128),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(128,64),
nn.ReLU(),
)
定义 age_classifier 和 gender_classifier:
self.age_classifier = nn.Sequential(
nn.Linear(64, 1),
nn.Sigmoid()
)
self.gender_classifier = nn.Sequential(
nn.Linear(64, 1),
nn.Sigmoid()
)
在以上代码中,年龄预测层 age_classifier 和性别预测层 gender_classifier 均使用 sigmoid 激活,因为年龄输出是一个介于 0 和 1 之间的值,且性别输出是 0 或 1。
定义前向传递方法 forward,使用网络层 age_classifier 和 gender_classifier:
def forward(self, x):
x = self.intermediate(x)
age = self.age_classifier(x)
gender = self.gender_classifier(x)
return gender, age
使用自定义网络替换 VGG16 预训练模型分类器模块:
model.classifier = ageGenderClassifier()
定义性别分类(二元交叉熵损失)和年龄预测( L1 损失)的损失函数。定义优化器并返回模型、损失函数和优化器:
gender_criterion = nn.BCELoss()
age_criterion = nn.L1Loss()
loss_functions = gender_criterion, age_criterion
optimizer = torch.optim.Adam(model.parameters(), lr= 1e-4)
return model.to(device), loss_functions, optimizer
调用 get_model() 函数初始化变量中的值:
model, loss_functions, optimizer = get_model()
(6) 定义函数在训练数据集上进行训练并在测试数据集上进行验证。train_batch 方法将图像、性别、年龄、模型、优化器和损失函数的实际值作为输入来计算总损失。
使用适当的输入参数定义 train_batch() 方法:
def train_batch(data, model, optimizer, criteria):
指定训练模型,将优化器重置为 zero_grad,并计算年龄和性别的预测值:
model.train()
ims, age, gender = data
optimizer.zero_grad()
pred_gender, pred_age = model(ims)
在计算年龄估计和性别分类对应的损失之前,获取用于年龄估计和性别分类的损失函数:
gender_criterion, age_criterion = criteria
gender_loss = gender_criterion(pred_gender.squeeze(), gender)
age_loss = age_criterion(pred_age.squeeze(), age)
通过将 gender_loss 和 age_loss 相加来计算整体损失,并通过优化模型的可训练权重执行反向传播以减少整体损失:
total_loss = gender_loss + age_loss
total_loss.backward()
optimizer.step()
return total_loss
validate_batch() 方法将图像、模型和损失函数以及年龄和性别的实际值作为输入,计算年龄和性别的预测值以及损失值。
使用所需的输入参数定义 vaidate_batch 函数:
def validate_batch(data, model, criteria):
指定模型处于评估阶段,因此不需要进行梯度计算:
model.eval()
ims, age, gender = data
with torch.no_grad():
pred_gender, pred_age = model(ims)
计算年龄和性别预测对应的损失值( gender_loss 和 age_loss)。压缩预测形状 (batch size, 1),以便将其整形为与目标值相同的形状( batch size):
gender_criterion, age_criterion = criteria
gender_loss = gender_criterion(pred_gender.squeeze(), gender)
age_loss = age_criterion(pred_age.squeeze(), age)
计算整体损失,最终预测的性别类别( pred_gender)、性别预测准确率和年龄估计误差:
total_loss = gender_loss + age_loss
pred_gender = (pred_gender > 0.5).squeeze()
gender_acc = (pred_gender == gender).float().sum()
age_mae = torch.abs(age - pred_age).float().sum()
return total_loss, gender_acc, age_mae
(7) 训练模型。
定义用于存储训练和测试损失值的列表,并指定训练 epoch 数:
model, criteria, optimizer = get_model()
val_gender_accuracies = []
val_age_maes = []
train_losses = []
val_losses = []
n_epochs = 10
best_test_loss = 1000
start = time.time()
在每个 epoch 开始时重新初始化训练和测试损失值:
for epoch in range(n_epochs):
epoch_train_loss, epoch_test_loss = 0, 0
val_age_mae, val_gender_acc, ctr = 0, 0, 0
_n = len(train_loader)
遍历训练数据加载器( train_loader )并训练模型:
for ix, data in enumerate(train_loader):
# if ix == 100: break
loss = train_batch(data, model, optimizer, criteria)
epoch_train_loss += loss.item()
遍历测试数据加载器并计算性别及年龄预测准确率:
for ix, data in enumerate(test_loader):
# if ix == 10: break
loss, gender_acc, age_mae = validate_batch(data, model, criteria)
epoch_test_loss += loss.item()
val_age_mae += age_mae
val_gender_acc += gender_acc
ctr += len(data[0])
计算年龄预测和性别分类的整体准确率:
val_age_mae /= ctr
val_gender_acc /= ctr
epoch_train_loss /= len(train_loader)
epoch_test_loss /= len(test_loader)
打印每个 epoch 结束时模型性能指标:
elapsed = time.time()-start
best_test_loss = min(best_test_loss, epoch_test_loss)
print('{}/{} ({:.2f}s - {:.2f}s remaining)'.format(epoch+1, n_epochs, time.time()-start, (n_epochs-epoch)*(elapsed/(epoch+1))))
info = f'''Epoch: {epoch+1:03d}\tTrain Loss: {epoch_train_loss:.3f}\tTest: {epoch_test_loss:.3f}\tBest Test Loss: {best_test_loss:.4f}'''
info += f'\nGender Accuracy: {val_gender_acc*100:.2f}%\tAge MAE: {val_age_mae:.2f}\n'
print(info)
存储每个 epoch 中测试数据集的年龄和性别预测准确率:
val_gender_accuracies.append(val_gender_acc)
val_age_maes.append(val_age_mae)
(8) 绘制年龄估计和性别预测训练过程中的准确率变化:
epochs = np.arange(1,len(val_gender_accuracies)+1)
fig,ax = plt.subplots(1,2,figsize=(10,5))
ax = ax.flat
ax[0].plot(epochs, val_gender_accuracies, 'bo')
ax[1].plot(epochs, val_age_maes, 'r')
ax[0].set_xlabel('Epochs')
ax[1].set_xlabel('Epochs')
ax[0].set_ylabel('Accuracy')
ax[1].set_ylabel('MAE')
ax[0].set_title('Validation Gender Accuracy')
ax[0].set_title('Validation Age Mean-Absolute-Error')
plt.show()

在年龄预测方面平均与真实年龄相差了 6 岁左右,在性别预测方面的准确率约为 84%。
(9) 随机选择测试图像,预测图中人物年龄和性别。
获取并加载图像,将其输入到 trn 对象中的 preprocess_image 方法中:
im = cv2.imread('4.jpeg')
im = trn.preprocess_image(im).to(device)
通过训练好的模型传递图像:
gender, age = model(im)
pred_gender = gender.to('cpu').detach().numpy()
pred_age = age.to('cpu').detach().numpy()
绘制图像并打印真实值和预测值:
im = cv2.imread('4.jpeg')
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
plt.imshow(im)
plt.show()
print('predicted gender:',np.where(pred_gender[0][0]<0.5,'Male','Female'), '; Predicted age', int(pred_age[0][0]*80))
# predicted gender: Female ; Predicted age 26
综上,可以看到,我们能够一次性同时预测年龄和性别。但是,需要注意,本节中构建的模型非常不稳定,年龄值会随着图像的光照条件有很大差异,可以通过使用数据增强观察模型性能改善情况。
小结
多任务学习可以同时处理和学习多个相关任务,在实践中,通过在多个任务上进行联合训练,模型可以学习到更通用的特征表示,从而改善每个任务的性能,这种共享知识的方式可以减少对大量任务特定数据的需求,使得训练更加高效,同时任务之间的相互促进和共享知识可以帮助模型更好地理解数据的内在结构和模式。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响
PyTorch深度学习实战(8)——批归一化
PyTorch深度学习实战(9)——学习率优化
PyTorch深度学习实战(10)——过拟合及其解决方法
PyTorch深度学习实战(11)——卷积神经网络
PyTorch深度学习实战(12)——数据增强
PyTorch深度学习实战(13)——可视化神经网络中间层输出
PyTorch深度学习实战(14)——类激活图
PyTorch深度学习实战(15)——迁移学习
PyTorch深度学习实战(16)——面部关键点检测




![[安洵杯 2019]easy_web md5强碰撞 preg_match绕过](https://img-blog.csdnimg.cn/59db3d4f83ec4843bec764454cd6f322.png)