文章目录
- 使用Dropout抑制过拟合
- 1. 环境准备
- 2. 导入数据集
- 3. 对所有数据的预测
- 3.1 数据集
- 3.2 构建神经网络
- 3.3 训练模型
- 3.4 分析模型
- 4. 对未见过数据的预测
- 4.1 划分数据集
- 4.2 构建神经网络
- 4.3 训练模型
- 4.4 分析模型
- 5. 使用Dropout抑制过拟合
- 5.1 构建神经网络
- 5.2 训练模型
- 5.3 分析模型
- 6. 正则化
- 6.1 神经网络太过复杂容易过拟合
- 6.2 太简单容易欠拟合
- 6.3 选取适当的神经网络
- 附:系列文章
使用Dropout抑制过拟合
Dropout是一种常用的神经网络正则化方法,主要用于防止过拟合。在深度学习中,由于网络层数过多,参数数量庞大,模型容易过拟合,并且在测试时产生较大的泛化误差。Dropout方法借鉴了集成学习中的Bagging思想,通过随机的方式,将一部分神经元的输出设置为0,从而减少过拟合的可能。
Dropout方法最早由Hinton等人提出,其基本思想是在训练时,以一定的概率随机地将网络中某些神经元的输出置为0。这种随机的行为可以被看作是一种对网络进行了部分剪枝,从而增加了网络的容忍性,使网络更加健壮,同时也避免了网络中某些特定的神经元对整个网络的过度依赖。
Dropout方法的具体实现如下:在每次训练过程中,以一定的概率p随机选择一部分神经元并将其置为0,被选择的神经元不参与后续的训练和反向传播。在测试时,为了保持模型的稳定性和一致性,一般不会采取随机化的方式,而是将每个神经元的权重乘以概率p,这里的p是在训练时选择的那个概率。
Dropout方法不仅可用于全连接网络,也可用于卷积神经网络和循环神经网络中,以减少过拟合现象。并且,它的实现简单,仅需要在模型训练时对每个神经元以概率p随机地进行挑选和保留,所以Dropout方法得到了广泛的应用和推广。
总之,Dropout方法可以在一定程度上提高模型的准确性和泛化能力,对于防止过拟合有着较好的效果。但是需要注意的是,Dropout方法会导致训练过程中每个mini-batch的梯度都不同,所以在使用Dropout方法时需要调整学习率,以保证模型的收敛速度和效果。
1. 环境准备
# 导入库
import keras
from keras import layers
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
Using TensorFlow backend.
2. 导入数据集
# 导入数据集
data = pd.read_csv('./dataset/credit-a.csv', header=None)
data
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 30.83 | 0.000 | 0 | 0 | 9 | 0 | 1.250 | 0 | 0 | 1 | 1 | 0 | 202 | 0.0 | -1 |
| 1 | 1 | 58.67 | 4.460 | 0 | 0 | 8 | 1 | 3.040 | 0 | 0 | 6 | 1 | 0 | 43 | 560.0 | -1 |
| 2 | 1 | 24.50 | 0.500 | 0 | 0 | 8 | 1 | 1.500 | 0 | 1 | 0 | 1 | 0 | 280 | 824.0 | -1 |
| 3 | 0 | 27.83 | 1.540 | 0 | 0 | 9 | 0 | 3.750 | 0 | 0 | 5 | 0 | 0 | 100 | 3.0 | -1 |
| 4 | 0 | 20.17 | 5.625 | 0 | 0 | 9 | 0 | 1.710 | 0 | 1 | 0 | 1 | 2 | 120 | 0.0 | -1 |
| 5 | 0 | 32.08 | 4.000 | 0 | 0 | 6 | 0 | 2.500 | 0 | 1 | 0 | 0 | 0 | 360 | 0.0 | -1 |
| 6 | 0 | 33.17 | 1.040 | 0 | 0 | 7 | 1 | 6.500 | 0 | 1 | 0 | 0 | 0 | 164 | 31285.0 | -1 |
| 7 | 1 | 22.92 | 11.585 | 0 | 0 | 2 | 0 | 0.040 | 0 | 1 | 0 | 1 | 0 | 80 | 1349.0 | -1 |
| 8 | 0 | 54.42 | 0.500 | 1 | 1 | 5 | 1 | 3.960 | 0 | 1 | 0 | 1 | 0 | 180 | 314.0 | -1 |
| 9 | 0 | 42.50 | 4.915 | 1 | 1 | 9 | 0 | 3.165 | 0 | 1 | 0 | 0 | 0 | 52 | 1442.0 | -1 |
| 10 | 0 | 22.08 | 0.830 | 0 | 0 | 0 | 1 | 2.165 | 1 | 1 | 0 | 0 | 0 | 128 | 0.0 | -1 |
| 11 | 0 | 29.92 | 1.835 | 0 | 0 | 0 | 1 | 4.335 | 0 | 1 | 0 | 1 | 0 | 260 | 200.0 | -1 |
| 12 | 1 | 38.25 | 6.000 | 0 | 0 | 5 | 0 | 1.000 | 0 | 1 | 0 | 0 | 0 | 0 | 0.0 | -1 |
| 13 | 0 | 48.08 | 6.040 | 0 | 0 | 5 | 0 | 0.040 | 1 | 1 | 0 | 1 | 0 | 0 | 2690.0 | -1 |
| 14 | 1 | 45.83 | 10.500 | 0 | 0 | 8 | 0 | 5.000 | 0 | 0 | 7 | 0 | 0 | 0 | 0.0 | -1 |
| 15 | 0 | 36.67 | 4.415 | 1 | 1 | 5 | 0 | 0.250 | 0 | 0 | 10 | 0 | 0 | 320 | 0.0 | -1 |
| 16 | 0 | 28.25 | 0.875 | 0 | 0 | 6 | 0 | 0.960 | 0 | 0 | 3 | 0 | 0 | 396 | 0.0 | -1 |
| 17 | 1 | 23.25 | 5.875 | 0 | 0 | 8 | 0 | 3.170 | 0 | 0 | 10 | 1 | 0 | 120 | 245.0 | -1 |
| 18 | 0 | 21.83 | 0.250 | 0 | 0 | 1 | 1 | 0.665 | 0 | 1 | 0 | 0 | 0 | 0 | 0.0 | -1 |
| 19 | 1 | 19.17 | 8.585 | 0 | 0 | 2 | 1 | 0.750 | 0 | 0 | 7 | 1 | 0 | 96 | 0.0 | -1 |
| 20 | 0 | 25.00 | 11.250 | 0 | 0 | 0 | 0 | 2.500 | 0 | 0 | 17 | 1 | 0 | 200 | 1208.0 | -1 |
| 21 | 0 | 23.25 | 1.000 | 0 | 0 | 0 | 0 | 0.835 | 0 | 1 | 0 | 1 | 2 | 300 | 0.0 | -1 |
| 22 | 1 | 47.75 | 8.000 | 0 | 0 | 0 | 0 | 7.875 | 0 | 0 | 6 | 0 | 0 | 0 | 1260.0 | -1 |
| 23 | 1 | 27.42 | 14.500 | 0 | 0 | 10 | 1 | 3.085 | 0 | 0 | 1 | 1 | 0 | 120 | 11.0 | -1 |
| 24 | 1 | 41.17 | 6.500 | 0 | 0 | 8 | 0 | 0.500 | 0 | 0 | 3 | 0 | 0 | 145 | 0.0 | -1 |
| 25 | 1 | 15.83 | 0.585 | 0 | 0 | 0 | 1 | 1.500 | 0 | 0 | 2 | 1 | 0 | 100 | 0.0 | -1 |
| 26 | 1 | 47.00 | 13.000 | 0 | 0 | 3 | 2 | 5.165 | 0 | 0 | 9 | 0 | 0 | 0 | 0.0 | -1 |
| 27 | 0 | 56.58 | 18.500 | 0 | 0 | 1 | 2 | 15.000 | 0 | 0 | 17 | 0 | 0 | 0 | 0.0 | -1 |
| 28 | 0 | 57.42 | 8.500 | 0 | 0 | 11 | 1 | 7.000 | 0 | 0 | 3 | 1 | 0 | 0 | 0.0 | -1 |
| 29 | 0 | 42.08 | 1.040 | 0 | 0 | 9 | 0 | 5.000 | 0 | 0 | 6 | 0 | 0 | 500 | 10000.0 | -1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 623 | 1 | 28.58 | 3.750 | 0 | 0 | 0 | 0 | 0.250 | 1 | 0 | 1 | 0 | 0 | 40 | 154.0 | 1 |
| 624 | 0 | 22.25 | 9.000 | 0 | 0 | 12 | 0 | 0.085 | 1 | 1 | 0 | 1 | 0 | 0 | 0.0 | 1 |
| 625 | 0 | 29.83 | 3.500 | 0 | 0 | 0 | 0 | 0.165 | 1 | 1 | 0 | 1 | 0 | 216 | 0.0 | 1 |
| 626 | 1 | 23.50 | 1.500 | 0 | 0 | 9 | 0 | 0.875 | 1 | 1 | 0 | 0 | 0 | 160 | 0.0 | 1 |
| 627 | 0 | 32.08 | 4.000 | 1 | 1 | 2 | 0 | 1.500 | 1 | 1 | 0 | 0 | 0 | 120 | 0.0 | 1 |
| 628 | 0 | 31.08 | 1.500 | 1 | 1 | 9 | 0 | 0.040 | 1 | 1 | 0 | 1 | 2 | 160 | 0.0 | 1 |
| 629 | 0 | 31.83 | 0.040 | 1 | 1 | 6 | 0 | 0.040 | 1 | 1 | 0 | 1 | 0 | 0 | 0.0 | 1 |
| 630 | 1 | 21.75 | 11.750 | 0 | 0 | 0 | 0 | 0.250 | 1 | 1 | 0 | 0 | 0 | 180 | 0.0 | 1 |
| 631 | 1 | 17.92 | 0.540 | 0 | 0 | 0 | 0 | 1.750 | 1 | 0 | 1 | 0 | 0 | 80 | 5.0 | 1 |
| 632 | 0 | 30.33 | 0.500 | 0 | 0 | 1 | 1 | 0.085 | 1 | 1 | 0 | 0 | 2 | 252 | 0.0 | 1 |
| 633 | 0 | 51.83 | 2.040 | 1 | 1 | 13 | 7 | 1.500 | 1 | 1 | 0 | 1 | 0 | 120 | 1.0 | 1 |
| 634 | 0 | 47.17 | 5.835 | 0 | 0 | 9 | 0 | 5.500 | 1 | 1 | 0 | 1 | 0 | 465 | 150.0 | 1 |
| 635 | 0 | 25.83 | 12.835 | 0 | 0 | 2 | 0 | 0.500 | 1 | 1 | 0 | 1 | 0 | 0 | 2.0 | 1 |
| 636 | 1 | 50.25 | 0.835 | 0 | 0 | 12 | 0 | 0.500 | 1 | 1 | 0 | 0 | 0 | 240 | 117.0 | 1 |
| 637 | 1 | 37.33 | 2.500 | 0 | 0 | 3 | 1 | 0.210 | 1 | 1 | 0 | 1 | 0 | 260 | 246.0 | 1 |
| 638 | 1 | 41.58 | 1.040 | 0 | 0 | 12 | 0 | 0.665 | 1 | 1 | 0 | 1 | 0 | 240 | 237.0 | 1 |
| 639 | 1 | 30.58 | 10.665 | 0 | 0 | 8 | 1 | 0.085 | 1 | 0 | 12 | 0 | 0 | 129 | 3.0 | 1 |
| 640 | 0 | 19.42 | 7.250 | 0 | 0 | 6 | 0 | 0.040 | 1 | 0 | 1 | 1 | 0 | 100 | 1.0 | 1 |
| 641 | 1 | 17.92 | 10.210 | 0 | 0 | 13 | 7 | 0.000 | 1 | 1 | 0 | 1 | 0 | 0 | 50.0 | 1 |
| 642 | 1 | 20.08 | 1.250 | 0 | 0 | 0 | 0 | 0.000 | 1 | 1 | 0 | 1 | 0 | 0 | 0.0 | 1 |
| 643 | 0 | 19.50 | 0.290 | 0 | 0 | 5 | 0 | 0.290 | 1 | 1 | 0 | 1 | 0 | 280 | 364.0 | 1 |
| 644 | 0 | 27.83 | 1.000 | 1 | 1 | 1 | 1 | 3.000 | 1 | 1 | 0 | 1 | 0 | 176 | 537.0 | 1 |
| 645 | 0 | 17.08 | 3.290 | 0 | 0 | 3 | 0 | 0.335 | 1 | 1 | 0 | 0 | 0 | 140 | 2.0 | 1 |
| 646 | 0 | 36.42 | 0.750 | 1 | 1 | 1 | 0 | 0.585 | 1 | 1 | 0 | 1 | 0 | 240 | 3.0 | 1 |
| 647 | 0 | 40.58 | 3.290 | 0 | 0 | 6 | 0 | 3.500 | 1 | 1 | 0 | 0 | 2 | 400 | 0.0 | 1 |
| 648 | 0 | 21.08 | 10.085 | 1 | 1 | 11 | 1 | 1.250 | 1 | 1 | 0 | 1 | 0 | 260 | 0.0 | 1 |
| 649 | 1 | 22.67 | 0.750 | 0 | 0 | 0 | 0 | 2.000 | 1 | 0 | 2 | 0 | 0 | 200 | 394.0 | 1 |
| 650 | 1 | 25.25 | 13.500 | 1 | 1 | 13 | 7 | 2.000 | 1 | 0 | 1 | 0 | 0 | 200 | 1.0 | 1 |
| 651 | 0 | 17.92 | 0.205 | 0 | 0 | 12 | 0 | 0.040 | 1 | 1 | 0 | 1 | 0 | 280 | 750.0 | 1 |
| 652 | 0 | 35.00 | 3.375 | 0 | 0 | 0 | 1 | 8.290 | 1 | 1 | 0 | 0 | 0 | 0 | 0.0 | 1 |
653 rows × 16 columns
data.iloc[:, -1].unique()
array([-1, 1])
3. 对所有数据的预测
3.1 数据集
x = data.iloc[:, :-1].values
y = data.iloc[:, -1].replace(-1, 0).values.reshape(-1, 1)
x.shape, y.shape
((653, 15), (653, 1))
3.2 构建神经网络
model = keras.Sequential()
model.add(layers.Dense(128, input_dim=15, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 128) 2048
_________________________________________________________________
dense_2 (Dense) (None, 128) 16512
_________________________________________________________________
dense_3 (Dense) (None, 128) 16512
_________________________________________________________________
dense_4 (Dense) (None, 1) 129
=================================================================
Total params: 35,201
Trainable params: 35,201
Non-trainable params: 0
_________________________________________________________________
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
WARNING:tensorflow:From /home/nlp/anaconda3/lib/python3.7/site-packages/tensorflow/python/ops/nn_impl.py:180: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
3.3 训练模型
history = model.fit(x, y, epochs=1000)
WARNING:tensorflow:From /home/nlp/anaconda3/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:422: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
Epoch 1/1000
653/653 [==============================] - 0s 434us/step - loss: 7.5273 - acc: 0.5988
Epoch 2/1000
653/653 [==============================] - 0s 92us/step - loss: 3.7401 - acc: 0.6187
Epoch 3/1000
653/653 [==============================] - 0s 75us/step - loss: 3.6464 - acc: 0.5712
Epoch 4/1000
653/653 [==============================] - 0s 56us/step - loss: 10.2291 - acc: 0.6631
Epoch 5/1000
653/653 [==============================] - 0s 63us/step - loss: 2.0400 - acc: 0.6233
Epoch 6/1000
653/653 [==============================] - 0s 120us/step - loss: 2.4279 - acc: 0.6217
Epoch 7/1000
653/653 [==============================] - 0s 105us/step - loss: 2.3289 - acc: 0.6325
Epoch 8/1000
653/653 [==============================] - 0s 159us/step - loss: 3.2521 - acc: 0.6294
Epoch 9/1000
653/653 [==============================] - 0s 89us/step - loss: 2.6005 - acc: 0.6294
Epoch 10/1000
653/653 [==============================] - 0s 118us/step - loss: 1.3997 - acc: 0.6738
……
Epoch 1000/1000
653/653 [==============================] - 0s 106us/step - loss: 0.2630 - acc: 0.9326
3.4 分析模型
history.history.keys()
dict_keys(['loss', 'acc'])
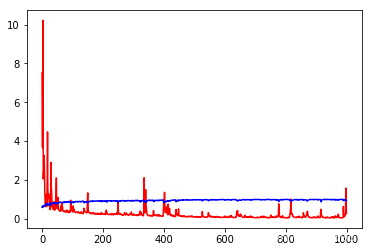
plt.plot(history.epoch, history.history.get('loss'), c='r')
plt.plot(history.epoch, history.history.get('acc'), c='b')
[<matplotlib.lines.Line2D at 0x7fd43c1597f0>]
4. 对未见过数据的预测
4.1 划分数据集
x_train = x[:int(len(x)*0.75)]
x_test = x[int(len(x)*0.75):]
y_train = y[:int(len(x)*0.75)]
y_test = y[int(len(x)*0.75):]
x_train.shape, x_test.shape, y_train.shape, y_test.shape
((489, 15), (164, 15), (489, 1), (164, 1))
4.2 构建神经网络
model = keras.Sequential()
model.add(layers.Dense(128, input_dim=15, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
#admam:利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率.
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
4.3 训练模型
history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))
Train on 489 samples, validate on 164 samples
Epoch 1/1000
489/489 [==============================] - 0s 487us/step - loss: 14.4564 - acc: 0.5951 - val_loss: 3.3778 - val_acc: 0.7256
Epoch 2/1000
489/489 [==============================] - 0s 110us/step - loss: 6.0909 - acc: 0.6012 - val_loss: 2.0924 - val_acc: 0.7195
Epoch 3/1000
489/489 [==============================] - 0s 195us/step - loss: 2.4527 - acc: 0.6074 - val_loss: 1.0763 - val_acc: 0.7378
Epoch 4/1000
489/489 [==============================] - 0s 183us/step - loss: 1.0751 - acc: 0.6585 - val_loss: 0.8990 - val_acc: 0.7134
Epoch 5/1000
489/489 [==============================] - 0s 155us/step - loss: 1.2669 - acc: 0.6503 - val_loss: 1.8094 - val_acc: 0.6585
Epoch 6/1000
489/489 [==============================] - 0s 202us/step - loss: 3.6742 - acc: 0.6892 - val_loss: 1.1836 - val_acc: 0.4573
Epoch 7/1000
489/489 [==============================] - 0s 166us/step - loss: 1.7544 - acc: 0.7301 - val_loss: 2.0060 - val_acc: 0.4573
Epoch 8/1000
489/489 [==============================] - 0s 185us/step - loss: 1.4768 - acc: 0.6605 - val_loss: 0.8917 - val_acc: 0.5427
Epoch 9/1000
489/489 [==============================] - 0s 163us/step - loss: 1.6829 - acc: 0.6667 - val_loss: 4.7695 - val_acc: 0.4573
Epoch 10/1000
489/489 [==============================] - 0s 157us/step - loss: 8.4323 - acc: 0.7239 - val_loss: 2.0879 - val_acc: 0.7439
……
Epoch 1000/1000
489/489 [==============================] - 0s 97us/step - loss: 0.0272 - acc: 0.9877 - val_loss: 2.2746 - val_acc: 0.8049
4.4 分析模型
history.history.keys()
dict_keys(['val_loss', 'val_acc', 'loss', 'acc'])
plt.plot(history.epoch, history.history.get('val_acc'), c='r', label='val_acc')
plt.plot(history.epoch, history.history.get('acc'), c='b', label='acc')
plt.legend()
<matplotlib.legend.Legend at 0x7fd417ff5978>
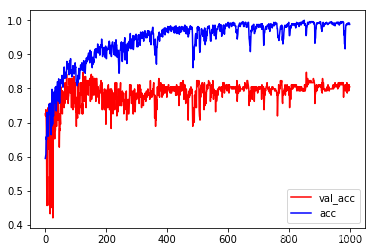
model.evaluate(x_train, y_train)
489/489 [==============================] - 0s 37us/step
[0.021263938083038197, 0.9897750616073608]
model.evaluate(x_test, y_test)
164/164 [==============================] - 0s 46us/step
[2.274633582976715, 0.8048780560493469]
过拟合:在训练数据正确率非常高, 在测试数据上比较低
5. 使用Dropout抑制过拟合
5.1 构建神经网络
model = keras.Sequential()
model.add(layers.Dense(128, input_dim=15, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) (None, 128) 2048
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_10 (Dense) (None, 128) 16512
_________________________________________________________________
dropout_2 (Dropout) (None, 128) 0
_________________________________________________________________
dense_11 (Dense) (None, 128) 16512
_________________________________________________________________
dropout_3 (Dropout) (None, 128) 0
_________________________________________________________________
dense_12 (Dense) (None, 1) 129
=================================================================
Total params: 35,201
Trainable params: 35,201
Non-trainable params: 0
________________________________________________________________
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
5.2 训练模型
history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))
Train on 489 samples, validate on 164 samples
Epoch 1/1000
489/489 [==============================] - 1s 1ms/step - loss: 41.6885 - acc: 0.5378 - val_loss: 9.9666 - val_acc: 0.6768
Epoch 2/1000
489/489 [==============================] - 0s 298us/step - loss: 53.1358 - acc: 0.5358 - val_loss: 11.0265 - val_acc: 0.6951
Epoch 3/1000
489/489 [==============================] - 0s 173us/step - loss: 36.9899 - acc: 0.5828 - val_loss: 11.6578 - val_acc: 0.6890
Epoch 4/1000
489/489 [==============================] - 0s 177us/step - loss: 43.3404 - acc: 0.5808 - val_loss: 7.5652 - val_acc: 0.6890
Epoch 5/1000
489/489 [==============================] - 0s 197us/step - loss: 23.3085 - acc: 0.6196 - val_loss: 7.9913 - val_acc: 0.6890
Epoch 6/1000
489/489 [==============================] - 0s 254us/step - loss: 24.1833 - acc: 0.6155 - val_loss: 5.5747 - val_acc: 0.7073
Epoch 7/1000
489/489 [==============================] - 0s 229us/step - loss: 19.7051 - acc: 0.5890 - val_loss: 5.5711 - val_acc: 0.7012
Epoch 8/1000
489/489 [==============================] - 0s 180us/step - loss: 22.1131 - acc: 0.5849 - val_loss: 7.0290 - val_acc: 0.6890
Epoch 9/1000
489/489 [==============================] - 0s 172us/step - loss: 23.2305 - acc: 0.6115 - val_loss: 4.2624 - val_acc: 0.6951
Epoch 10/1000
……
Epoch 1000/1000
489/489 [==============================] - 0s 137us/step - loss: 0.3524 - acc: 0.8200 - val_loss: 0.7290 - val_acc: 0.7012
5.3 分析模型
model.evaluate(x_train, y_train)
489/489 [==============================] - 0s 41us/step
[0.3090217998422728, 0.8548057079315186]
model.evaluate(x_test, y_test)
164/164 [==============================] - 0s 64us/step
[0.7289713301309725, 0.7012194991111755]
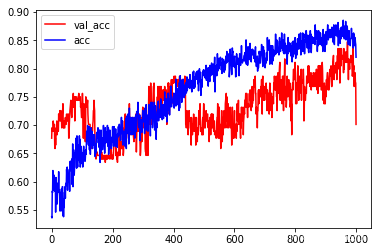
plt.plot(history.epoch, history.history.get('val_acc'), c='r', label='val_acc')
plt.plot(history.epoch, history.history.get('acc'), c='b', label='acc')
plt.legend()
<matplotlib.legend.Legend at 0x7fd4177c87b8>
6. 正则化
l1:loss = s*abs(w1 + w2 + …) + mse
l2:loss = s*(w12 + w22 + …) + mse
from keras import regularizers
6.1 神经网络太过复杂容易过拟合
#神经网络太过复杂容易过拟合
model = keras.Sequential()
model.add(layers.Dense(128, kernel_regularizer=regularizers.l2(0.001), input_dim=15, activation='relu'))
model.add(layers.Dense(128, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
model.add(layers.Dense(128, kernel_regularizer=regularizers.l2(0.001), activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))
Train on 489 samples, validate on 164 samples
Epoch 1/1000
489/489 [==============================] - 0s 752us/step - loss: 22.2560 - acc: 0.5910 - val_loss: 9.1111 - val_acc: 0.6524
Epoch 2/1000
489/489 [==============================] - 0s 137us/step - loss: 6.8963 - acc: 0.6217 - val_loss: 3.2886 - val_acc: 0.4573
Epoch 3/1000
489/489 [==============================] - 0s 161us/step - loss: 5.0407 - acc: 0.6830 - val_loss: 1.1973 - val_acc: 0.7256
Epoch 4/1000
489/489 [==============================] - 0s 218us/step - loss: 6.6088 - acc: 0.6421 - val_loss: 7.4651 - val_acc: 0.7012
Epoch 5/1000
489/489 [==============================] - 0s 233us/step - loss: 8.3945 - acc: 0.6973 - val_loss: 2.5579 - val_acc: 0.7317
Epoch 6/1000
489/489 [==============================] - 0s 192us/step - loss: 7.0204 - acc: 0.6196 - val_loss: 3.6758 - val_acc: 0.6829
Epoch 7/1000
489/489 [==============================] - 0s 152us/step - loss: 3.9961 - acc: 0.7382 - val_loss: 1.6183 - val_acc: 0.7317
Epoch 8/1000
489/489 [==============================] - 0s 94us/step - loss: 2.3441 - acc: 0.6237 - val_loss: 1.1523 - val_acc: 0.7256
Epoch 9/1000
489/489 [==============================] - 0s 114us/step - loss: 1.8178 - acc: 0.6442 - val_loss: 1.3449 - val_acc: 0.7073
Epoch 10/1000
489/489 [==============================] - 0s 157us/step - loss: 1.6122 - acc: 0.7117 - val_loss: 1.2869 - val_acc: 0.6646
……
Epoch 1000/1000
489/489 [==============================] - 0s 130us/step - loss: 0.1452 - acc: 0.9775 - val_loss: 1.0515 - val_acc: 0.7866
model.evaluate(x_train, y_train)
model.evaluate(x_train, y_train)
489/489 [==============================] - 0s 34us/step
[0.17742264538942426, 0.9611452221870422]
model.evaluate(x_test, y_test)
164/164 [==============================] - 0s 77us/step
[1.0514701096023, 0.7865853905677795]
6.2 太简单容易欠拟合
#太简单容易欠拟合
model = keras.Sequential()
model.add(layers.Dense(4, input_dim=15, activation='relu'))
model.add(layers.Dense(1, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))
Train on 489 samples, validate on 164 samples
Epoch 1/1000
489/489 [==============================] - 0s 502us/step - loss: 0.6932 - acc: 0.4765 - val_loss: 0.6931 - val_acc: 0.6341
Epoch 2/1000
489/489 [==============================] - 0s 91us/step - loss: 0.6931 - acc: 0.5174 - val_loss: 0.6930 - val_acc: 0.6341
Epoch 3/1000
489/489 [==============================] - 0s 107us/step - loss: 0.6931 - acc: 0.5174 - val_loss: 0.6924 - val_acc: 0.6341
Epoch 4/1000
489/489 [==============================] - 0s 91us/step - loss: 0.6930 - acc: 0.5174 - val_loss: 0.6916 - val_acc: 0.6341
Epoch 5/1000
489/489 [==============================] - 0s 101us/step - loss: 0.6930 - acc: 0.5174 - val_loss: 0.6914 - val_acc: 0.6341
Epoch 6/1000
489/489 [==============================] - 0s 113us/step - loss: 0.6930 - acc: 0.5174 - val_loss: 0.6914 - val_acc: 0.6341
Epoch 7/1000
489/489 [==============================] - 0s 147us/step - loss: 0.6929 - acc: 0.5174 - val_loss: 0.6908 - val_acc: 0.6341
Epoch 8/1000
489/489 [==============================] - 0s 166us/step - loss: 0.6929 - acc: 0.5174 - val_loss: 0.6905 - val_acc: 0.6341
Epoch 9/1000
489/489 [==============================] - 0s 162us/step - loss: 0.6929 - acc: 0.5174 - val_loss: 0.6904 - val_acc: 0.6341
Epoch 10/1000
489/489 [==============================] - 0s 129us/step - loss: 0.6928 - acc: 0.5174 - val_loss: 0.6901 - val_acc: 0.6341
……
Epoch 1000/1000
489/489 [==============================] - 0s 86us/step - loss: 0.6926 - acc: 0.5174 - val_loss: 0.6849 - val_acc: 0.6341
model.evaluate(x_train, y_train)
489/489 [==============================] - 0s 43us/step
[0.6925447341854587, 0.5173823833465576]
model.evaluate(x_test, y_test)
164/164 [==============================] - 0s 39us/step
[0.684889389247429, 0.6341463327407837]
6.3 选取适当的神经网络
# 选取适当的神经网络
model = keras.Sequential()
model.add(layers.Dense(4, input_dim=15, activation='relu'))
model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['acc']
)
history = model.fit(x_train, y_train, epochs=1000, validation_data=(x_test, y_test))
Train on 489 samples, validate on 164 samples
Epoch 1/1000
489/489 [==============================] - 0s 575us/step - loss: 40.1825 - acc: 0.5317 - val_loss: 17.6376 - val_acc: 0.6098
Epoch 2/1000
489/489 [==============================] - 0s 104us/step - loss: 30.0785 - acc: 0.5337 - val_loss: 12.6986 - val_acc: 0.6159
Epoch 3/1000
489/489 [==============================] - 0s 148us/step - loss: 20.0469 - acc: 0.5112 - val_loss: 8.3732 - val_acc: 0.5671
Epoch 4/1000
489/489 [==============================] - 0s 151us/step - loss: 12.5171 - acc: 0.4908 - val_loss: 3.8925 - val_acc: 0.5061
Epoch 5/1000
489/489 [==============================] - 0s 113us/step - loss: 4.4324 - acc: 0.4294 - val_loss: 0.9156 - val_acc: 0.4573
Epoch 6/1000
489/489 [==============================] - 0s 79us/step - loss: 1.0313 - acc: 0.5419 - val_loss: 0.9974 - val_acc: 0.4695
Epoch 7/1000
489/489 [==============================] - 0s 88us/step - loss: 1.0071 - acc: 0.5562 - val_loss: 0.8852 - val_acc: 0.5183
Epoch 8/1000
489/489 [==============================] - 0s 88us/step - loss: 0.9085 - acc: 0.5808 - val_loss: 0.7934 - val_acc: 0.5366
Epoch 9/1000
489/489 [==============================] - 0s 107us/step - loss: 0.8235 - acc: 0.5992 - val_loss: 0.7390 - val_acc: 0.5366
Epoch 10/1000
489/489 [==============================] - 0s 114us/step - loss: 0.7711 - acc: 0.5971 - val_loss: 0.7174 - val_acc: 0.5366
……
Epoch 1000/1000
489/489 [==============================] - 0s 141us/step - loss: 0.3095 - acc: 0.8732 - val_loss: 0.3971 - val_acc: 0.8537
model.evaluate(x_train, y_train)
489/489 [==============================] - 0s 68us/step
[0.30120014958464536, 0.8813905715942383]
model.evaluate(x_test, y_test)
164/164 [==============================] - 0s 45us/step
[0.39714593858253666, 0.8536585569381714]
附:系列文章
| 序号 | 文章目录 | 直达链接 |
|---|---|---|
| 1 | 波士顿房价预测 | https://want595.blog.csdn.net/article/details/132181950 |
| 2 | 鸢尾花数据集分析 | https://want595.blog.csdn.net/article/details/132182057 |
| 3 | 特征处理 | https://want595.blog.csdn.net/article/details/132182165 |
| 4 | 交叉验证 | https://want595.blog.csdn.net/article/details/132182238 |
| 5 | 构造神经网络示例 | https://want595.blog.csdn.net/article/details/132182341 |
| 6 | 使用TensorFlow完成线性回归 | https://want595.blog.csdn.net/article/details/132182417 |
| 7 | 使用TensorFlow完成逻辑回归 | https://want595.blog.csdn.net/article/details/132182496 |
| 8 | TensorBoard案例 | https://want595.blog.csdn.net/article/details/132182584 |
| 9 | 使用Keras完成线性回归 | https://want595.blog.csdn.net/article/details/132182723 |
| 10 | 使用Keras完成逻辑回归 | https://want595.blog.csdn.net/article/details/132182795 |
| 11 | 使用Keras预训练模型完成猫狗识别 | https://want595.blog.csdn.net/article/details/132243928 |
| 12 | 使用PyTorch训练模型 | https://want595.blog.csdn.net/article/details/132243989 |
| 13 | 使用Dropout抑制过拟合 | https://want595.blog.csdn.net/article/details/132244111 |
| 14 | 使用CNN完成MNIST手写体识别(TensorFlow) | https://want595.blog.csdn.net/article/details/132244499 |
| 15 | 使用CNN完成MNIST手写体识别(Keras) | https://want595.blog.csdn.net/article/details/132244552 |
| 16 | 使用CNN完成MNIST手写体识别(PyTorch) | https://want595.blog.csdn.net/article/details/132244641 |
| 17 | 使用GAN生成手写数字样本 | https://want595.blog.csdn.net/article/details/132244764 |
| 18 | 自然语言处理 | https://want595.blog.csdn.net/article/details/132276591 |




![[安洵杯 2019]easy_web md5强碰撞 preg_match绕过](https://img-blog.csdnimg.cn/59db3d4f83ec4843bec764454cd6f322.png)