前言:
爬取豆瓣top250其实是初学者用于练习和熟悉爬虫技能知识的简单实战项目,通过这个项目,可以让小白对爬虫有一个初步认识,因此,如果你已经接触过爬虫有些时间了,可以跳过该项目,选择更有挑战性的实战项目来提升技能。当然,如果你是小白,这个项目就再适合不过了。那么就让我们开始吧!
目录
一、实战
1.对豆瓣网网站进行Ajax分析
2.提取数据
二、python完整代码(两种方法)
bs4方法
正则式方法
一、实战
1.对豆瓣网网站进行Ajax分析
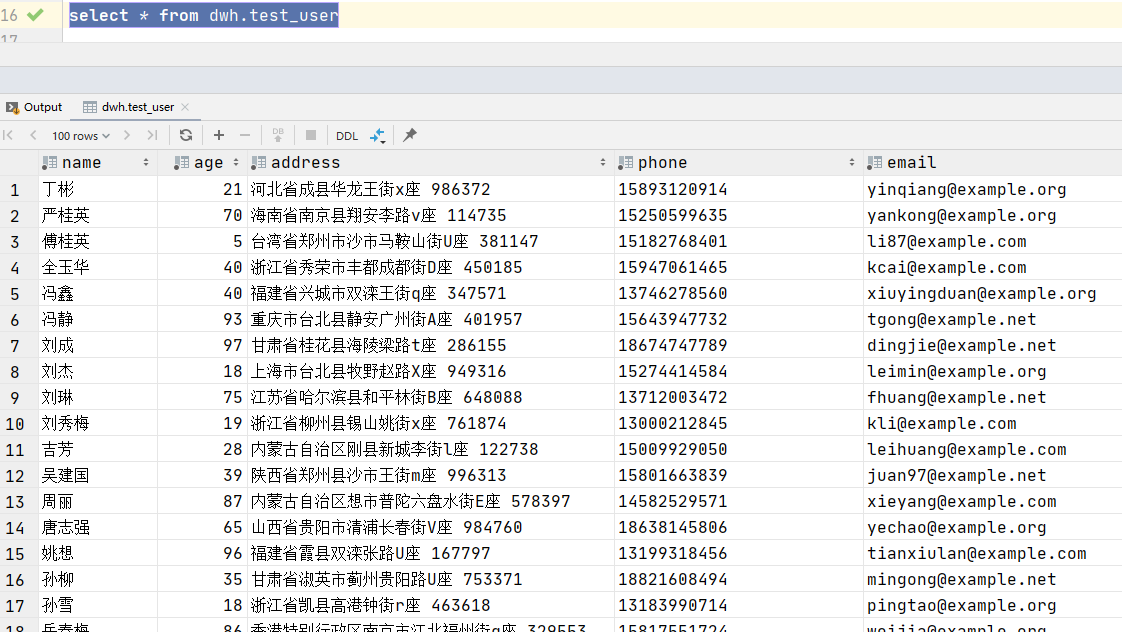
这里我用的是谷歌浏览器,对豆瓣电影top250网站进行检查,可以在网络部分看到该页数据的请求头信息。
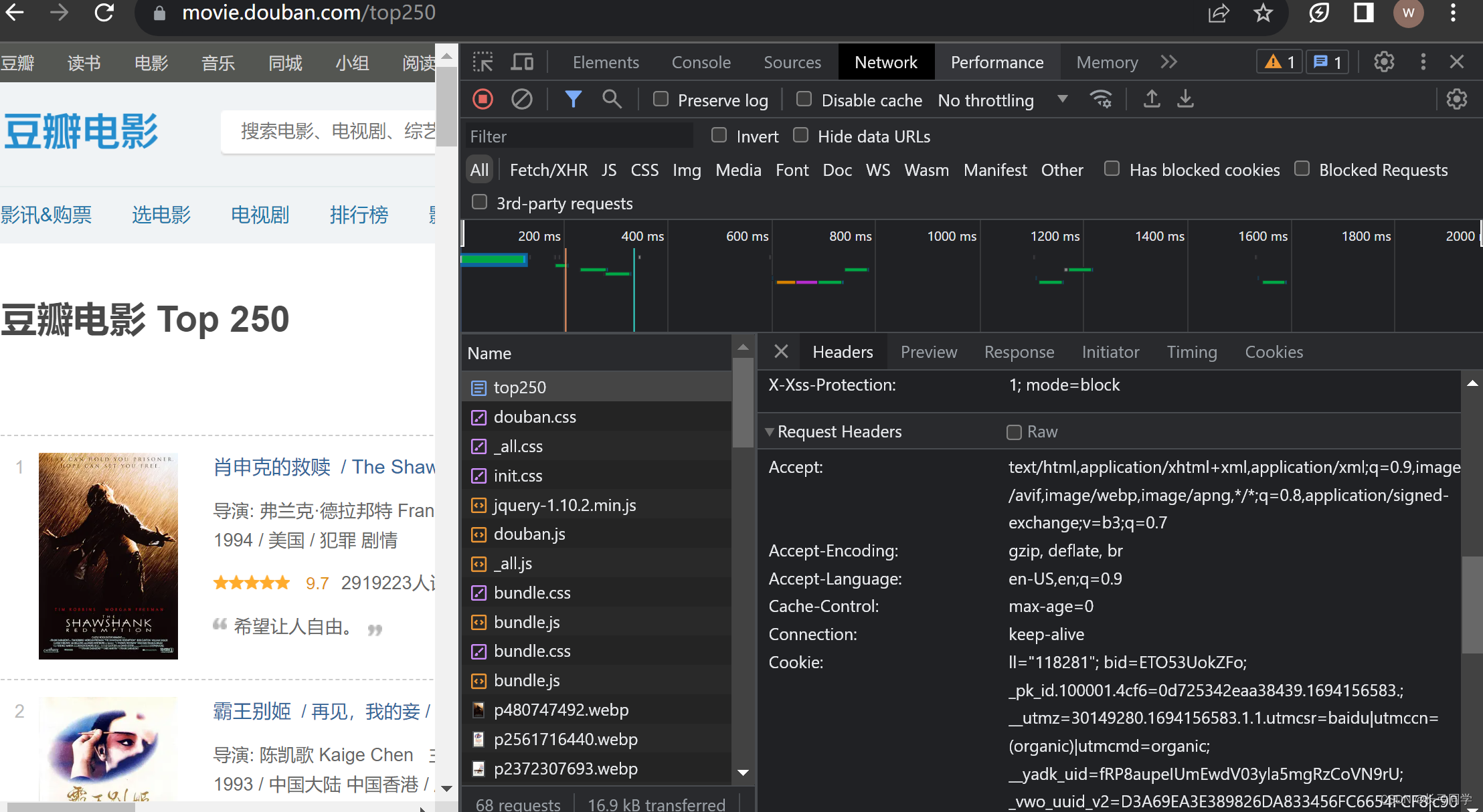
需要注意的是,我们要爬取的页面数据文件是top250这个文件,判断需要从哪个包中提取数据可以在响应里看到:
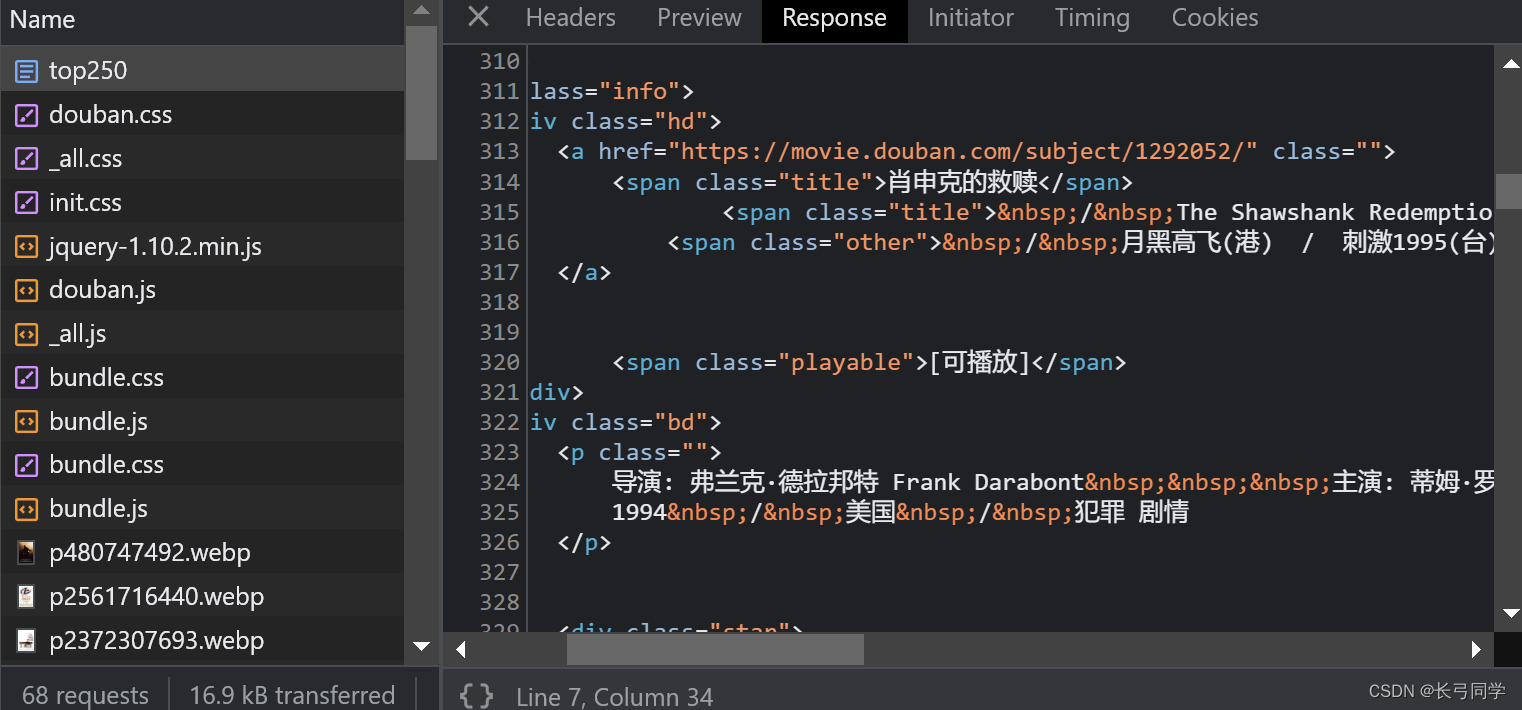
我们一开始可以试着给豆瓣发请求:
import requests
# 发请求测试
response = requests.get('https://movie.douban.com/top250')
print(response)得到响应结果如下:

状态码是418,意思是服务器拒绝了我们的请求。这是因为服务器没有识别到我们是用户端,所以为了保证网站数据的安全,将我们拒之门外。那么我们就需要对自己进行一些简单的伪装。
UA(user-agent)伪装,是我本次采用的伪装策略,也是最简单的伪装策略,有些网站的反爬机制比较复杂,则需要采用更加复杂的反反爬机制来进行伪装,不过,对于豆瓣来说,UA伪装就够用了。
那么我们现在给我们的请求带一个请求头,并且请求头中带一个User-agent信息,这个信息可以在检查页面的请求头信息(Headers)里找到,如下所示:
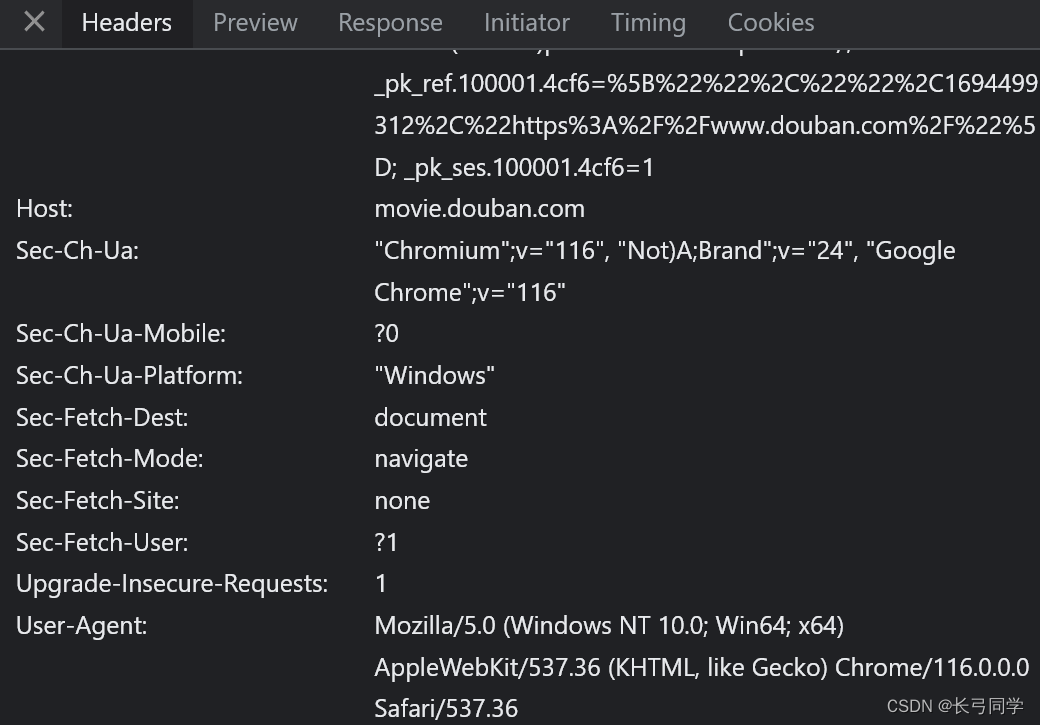
现在我们将它加入到我们的代码中:
import requests
# 发请求测试网站反爬机制
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}
response = requests.get('https://movie.douban.com/top250',headers=headers)
print(response)响应结果:
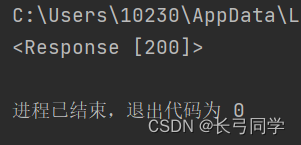
状态码为200,说明响应成功,这个时候我们已经爬到我们想要的数据了,打印出来看下:
print(response.text)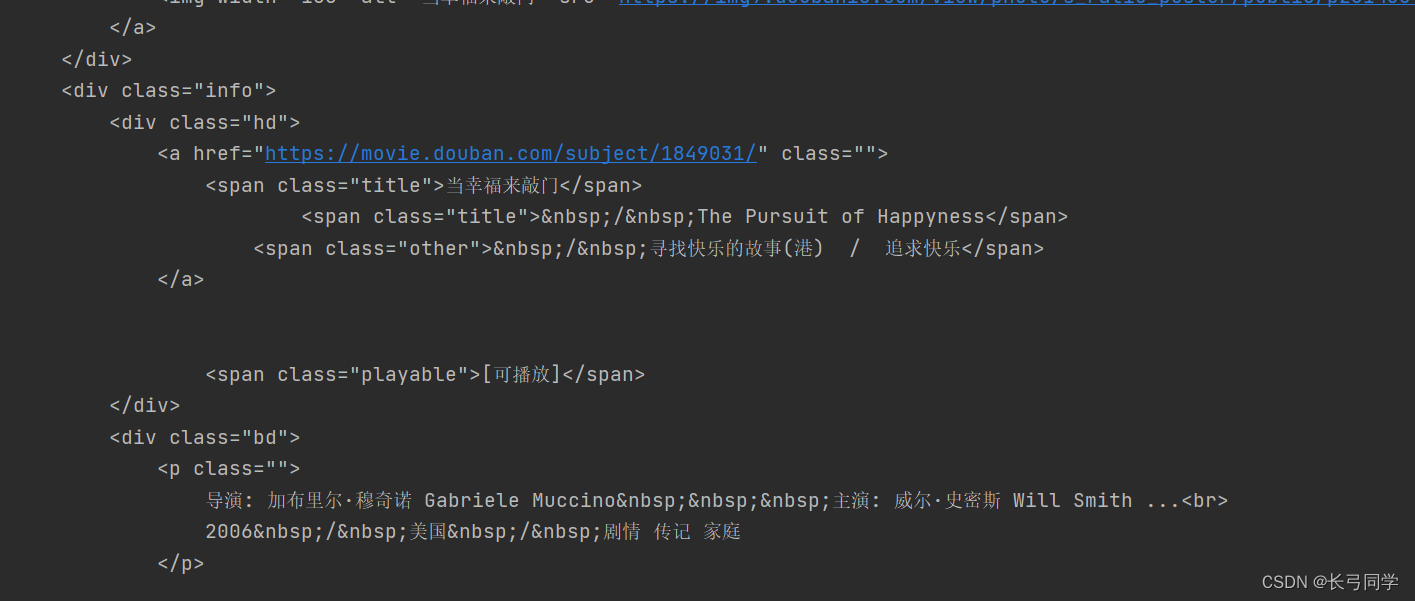
可以看到,我们已经得到了整个页面的html代码,那么下一步我们就需要从中提取我们需要的信息。
2.提取数据
这里我使用的方法是python正则式,所以我们需要先分析html代码的结构,这里需要一点前端知识,但是因为爬虫的前导知识是前端开发,因此默认大家都是能看懂的。
通过观察,我们可以发现电影标题包含在<span class="title"></span>这个类里,所以我们可以使用正则式将它匹配出来:
<span class="title">(.*?)</span>python代码:
import re
title = re.findall('<span class="title">(.*?)</span>', response.text,re.S)提取完之后我们需要对不干净的数据进行筛选,这一步可以省略,详见于完整代码。
其他信息也按照这个逻辑提取出来,这里我提取了题目、国籍、上映时间这三个数据,大家可以根据自己的需要去提取。
二、python完整代码(两种方法)
这里我提供两种方法,一种是用bs4对html代码进行解析(爬虫中用的比较多),另一种是python正则式。大家可以根据需要进行采用。
bs4方法
import requests
from bs4 import BeautifulSoup
import csv
'''爬取豆瓣电影top20'''
def top250_crawer(url,sum):
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}
response = requests.get(url,headers = headers)
soup = BeautifulSoup(response.text, 'html.parser')
# print(soup)
movie_items = soup.find_all('div', class_='item')
i = sum+1
for item in movie_items:
title = item.select_one('.title').text
# print(title)
rating = item.select_one('.rating_num').text
data = item.select('.bd p')[0].text.split('\n')
time = data[2].replace(' ','').split('/')[0]
country = data[2].replace(' ','').split('/')[1]
print(str(i)+'.'+title+','+country+','+time)
i +=1
url = 'https://movie.douban.com/top250'
sum =0
'遍历10页数据,250条结果'
for a in range(10):
if sum == 0 :
top250_crawer(url,sum)
sum +=25
else:
page = '?start='+str(sum)+'&filter='
new_url = url+page
top250_crawer(new_url,sum)
sum +=25
正则式方法
import requests
import re
'''爬取豆瓣电影top20'''
def top250_crawer(url, sum):
headers = {
'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/1'
}
response = requests.get(url, headers=headers)
print(response.text)
title = re.findall('<span class="title">(.*?)</span>', response.text,re.S)
new_title = []
for t in title:
if ' / ' not in t:
new_title.append(t)
data = re.findall('<br>(.*?)</p>', response.text, re.S)
time = []
country = []
for str1 in data:
str1 = str1.replace(' ', '')
str1 = str1.replace('\n', '')
time_data = str1.split(' / ')[0]
country_data = str1.split(' / ')[1]
time.append(time_data)
country.append(country_data)
print(len(new_title))
print(len(time))
print(len(country))
for j in range(len(country)):
sum += 1
print(str(sum)+'.' + new_title[j] + ',' + country[j] + ',' + time[j])
url = 'https://movie.douban.com/top250'
sum = 0
'遍历10页数据,250条结果'
for a in range(10):
if sum == 0:
top250_crawer(url, sum)
sum += 25
else:
page = '?start=' + str(sum) + '&filter='
new_url = url + page
top250_crawer(new_url, sum)
sum += 25
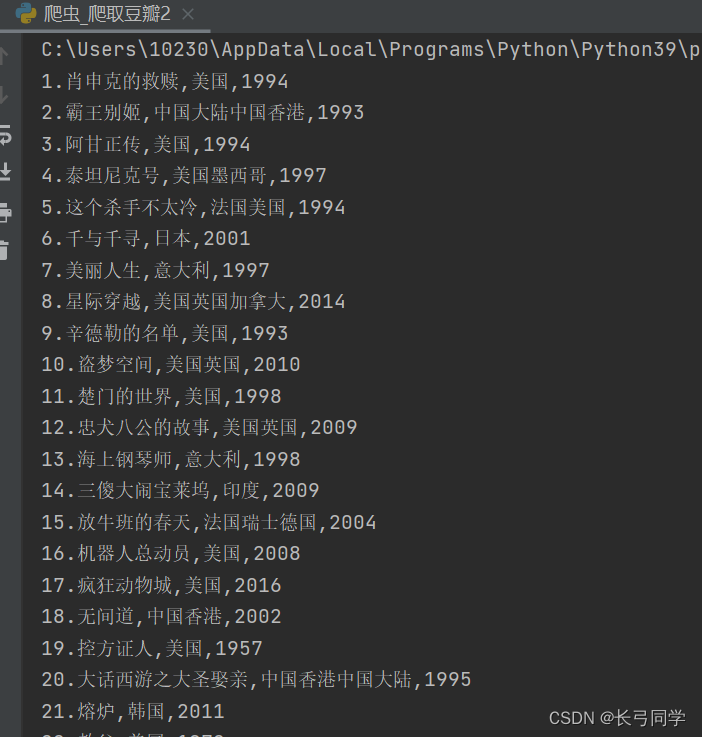
运行结果:



![[安洵杯 2019]easy_web md5强碰撞 preg_match绕过](https://img-blog.csdnimg.cn/59db3d4f83ec4843bec764454cd6f322.png)