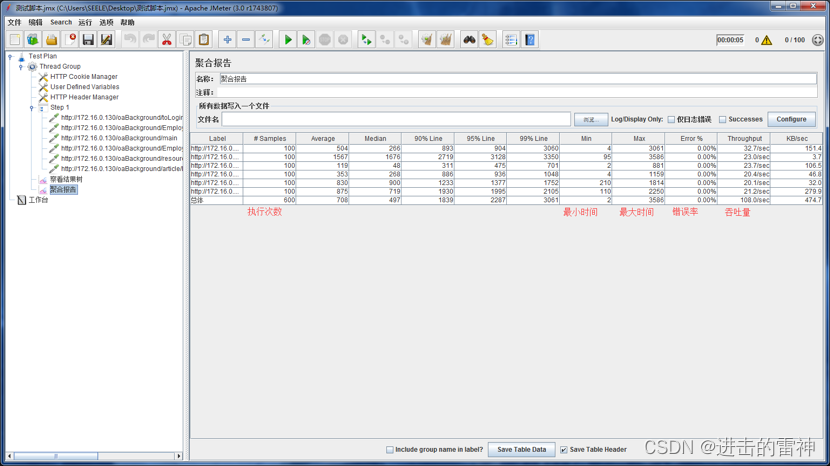
前言
很多人认为AlwaysOn在同步提交模式下数据是实时同步的,也就是说在主副本写入数据后可以在辅助副本立即查询到。因此期望实现一个彻底的读写分离策略,即所有的写语句在主副本上,所有的只读语句分离到辅助副本上。这是一个认知误区,本文通过原理和测试进行解释。
实现原理
从下图可以看到,在同步提交模式下,主副本产生的日志被同步并固化到辅助副本的日志文件后,主副本的事务就会提交。辅助副本再通过异步的REDO线程把日志转换为数据,因此数据在辅助节点是有滞后的。
要强调的是,这种实现原理是为了对主副本上的写入操作的性能影响最小化,并不会导致数据丢失。当主副本出现故障后,辅助副本切换成主副本时有一个数据库恢复阶段,用来把异步REDO线程没有处理完的日志转换成数据,完成后数据和原主副本是一致的。因此不会丢失数据,只是稍微增加了一点故障转移的时间。

测试
创建一个AlwaysOn可用性组,2个同步提交的副本,Node1为主副本,Node2为辅助副本。

在数据库db1中创建一张表。
SET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOCREATE TABLE [dbo].[tbl_always_on_test]([id] [int] IDENTITY(1,1) NOT NULL,[a] [nvarchar](50) NOT NULL,CONSTRAINT [PK_tbl_always_on_test] PRIMARY KEY CLUSTERED([id] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]) ON [PRIMARY]GO
写一个测试工具,首先建立到主副本数据库的连接,插入一行数据并获取新插入行的自增列的值,然后根据配置的等待时间进行线程等待,最后建立到辅助副本数据库的连接,查找新插入的这条数据是否已经存在,如存在成功数加1,不存在失败数加1。

配置等待时间为0,也就是在主副本插入完数据后立即到辅助副本去查询,可以看到成功的非常少,绝大多数都是查不到的。
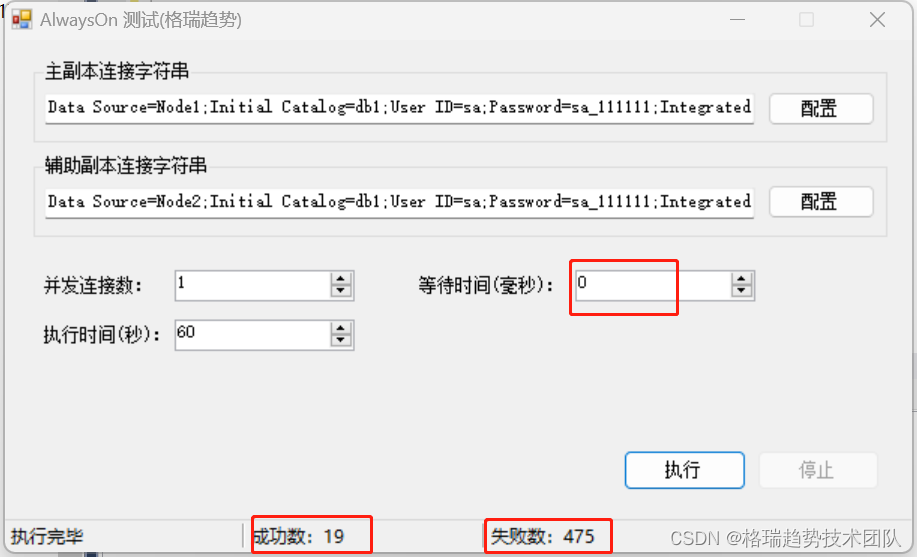
把等待时间增加到500毫秒,还有一半失败的。
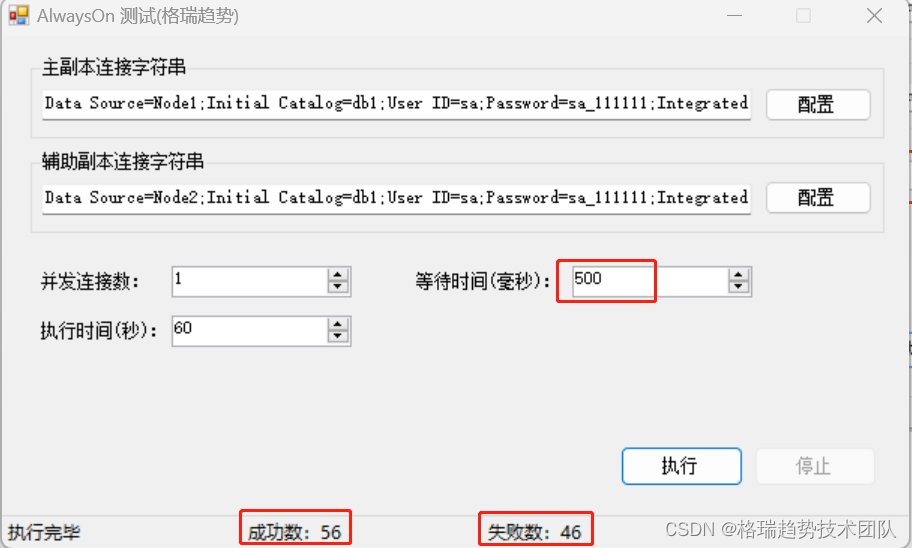
直到增加到1000毫秒,才会全部成功。
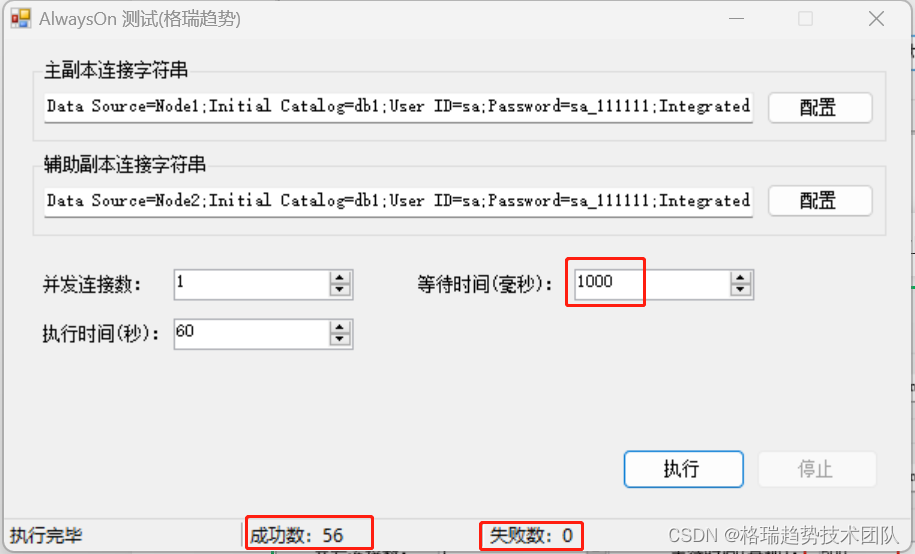
总结
通过原理和测试,我们理解到数据在辅助副本是有滞后的,而且滞后时间是不确定的,和硬件环境、日志大小、并发数等都有关系。同一个查询语句在主副本和辅助副本的查询结果可能是不同的,导致对数据实时性非常敏感的业务逻辑出现问题。因此很多人所期望的彻底的读写分离策略(写操作在主副本上,只读查询全部分离到辅助副本上)是不能实现的。我们不能制定简单粗暴的读写分离策略,只有对数据时效性不敏感的查询才能被分离。
再说一下我认为的读写分离, 我更愿意叫“报表分离”,在数据库中也遵循“二八定律”,即数量上占20%的SQL语句带来80%的性能问题,例如性能消耗、锁表导致阻塞等。这类语句大多数都是列表、统计、报表、数据抽取等查询语句,并且对数据时效性是不敏感的。因此把这20%的查询语句分离到辅助副本上, 即能从性能上分离走80%的压力,又能解决执行期间导致的阻塞,而且改造应用程序的成本很小。
通过链接“https://learn.microsoft.com/zh-cn/previous-versions/sql/sql-server-2012/ff877884(v=sql.110)”了解更多关于AlwaysOn的资料。
北京格瑞趋势科技有限公司是聚焦于数据服务的高新技术企业,成立于2008年,创始团队及核心技术人员来自微软和雅虎。微软数据平台金牌合作伙伴。通过产品+服务双轮驱动的业务模式,15年间累计服务4000+客户,覆盖互联网、市政、交通、电信、医疗、教育、电力、制造业等各个领域。