文章目录
- 一、书籍推荐
- 二、完整代码
- 三、运行结果
一、书籍推荐
推荐本人书籍《Python网络爬虫入门到实战》 ,详细介绍见👉: 《Python网络爬虫入门到实战》 书籍介绍
二、完整代码
原理:抓取该链接中所有的图片格式。基于selenium来获取,自动下载到output文件夹中。
from selenium import webdriver
import requests as rq
import os
from bs4 import BeautifulSoup
import time
# Enter Path : chromedriver.exe
# Enter URL : http://www.netbian.com/meinv/index_2.htm
path = input("Enter Path : ")
url = input("Enter URL : ")
output = "output"
def get_url(path, url):
driver = webdriver.Chrome(executable_path=r"{}".format(path))
driver.get(url)
print("loading.....")
res = driver.execute_script("return document.documentElement.outerHTML")
return res
def get_img_links(res):
soup = BeautifulSoup(res, "lxml")
imglinks = soup.find_all("img", src=True)
return imglinks
def download_img(img_link, index):
try:
extensions = [".jpeg", ".jpg", ".png", ".gif"]
extension = ".jpg"
for exe in extensions:
if img_link.find(exe) > 0:
extension = exe
break
img_data = rq.get(img_link).content
with open(output + "\\" + str(index + 1) + extension, "wb+") as f:
f.write(img_data)
f.close()
except Exception:
pass
result = get_url(path, url)
time.sleep(60)
img_links = get_img_links(result)
if not os.path.isdir(output):
os.mkdir(output)
for index, img_link in enumerate(img_links):
img_link = img_link["src"]
print("Downloading...")
if img_link:
download_img(img_link, index)
print("Download Complete!!")
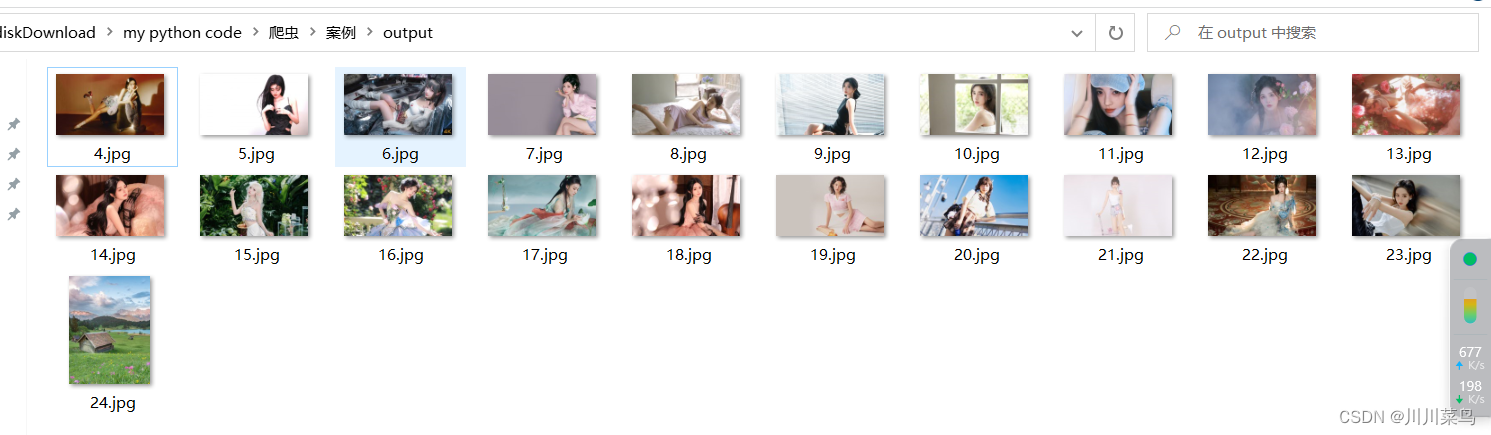
三、运行结果
如下所示: