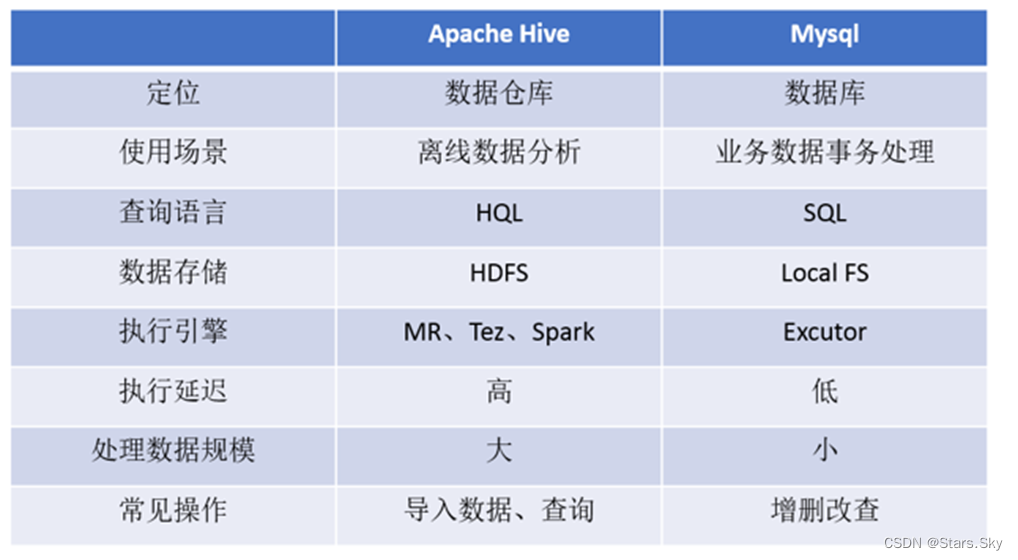
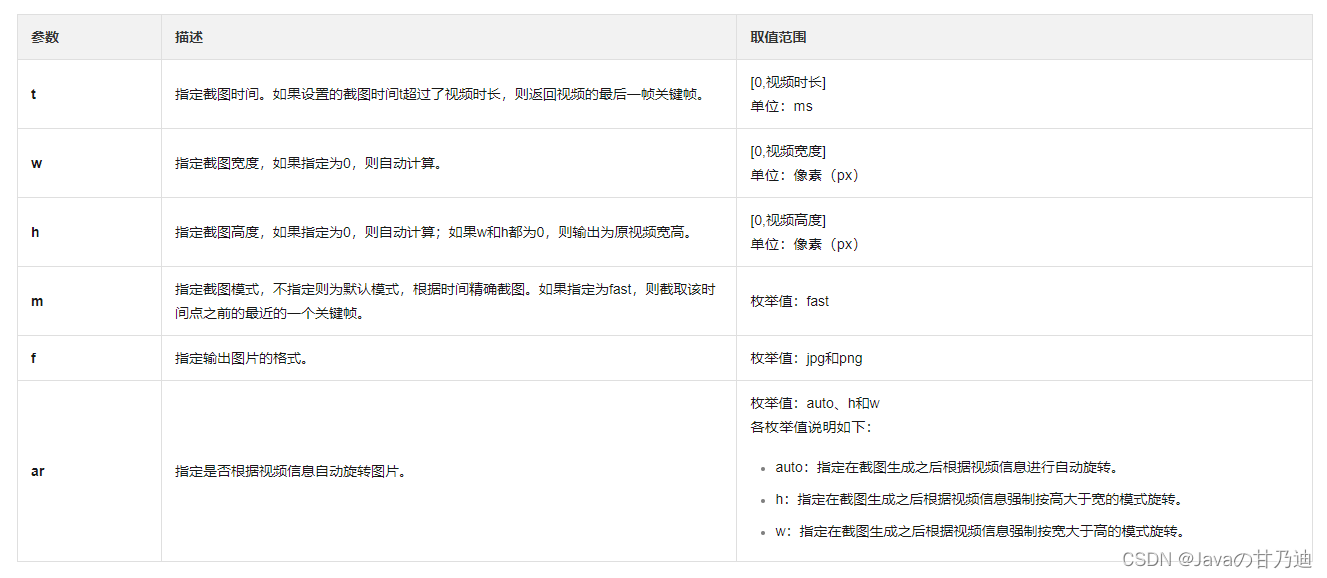
temperature
官方文档
temperature number or null Optional Defaults to 1
What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
We generally recommend altering this or top_p but not both.
温度采样参数取值介于 0 和 2 之间。较高的值(如 0.8)将使输出更加随机,而较低的值(如 0.2)将使其更加集中和确定性。
我们通常建议此参数或top_p参数不要同时更改。
效果
随机性大可以理解为多次询问的回答多样性、回答更有创意、回答更有可能没有事实依据。随机性小可以理解为多次询问更有可能遇到重复的回答、回答更接近事实(更接近训练数据)。
作用机制
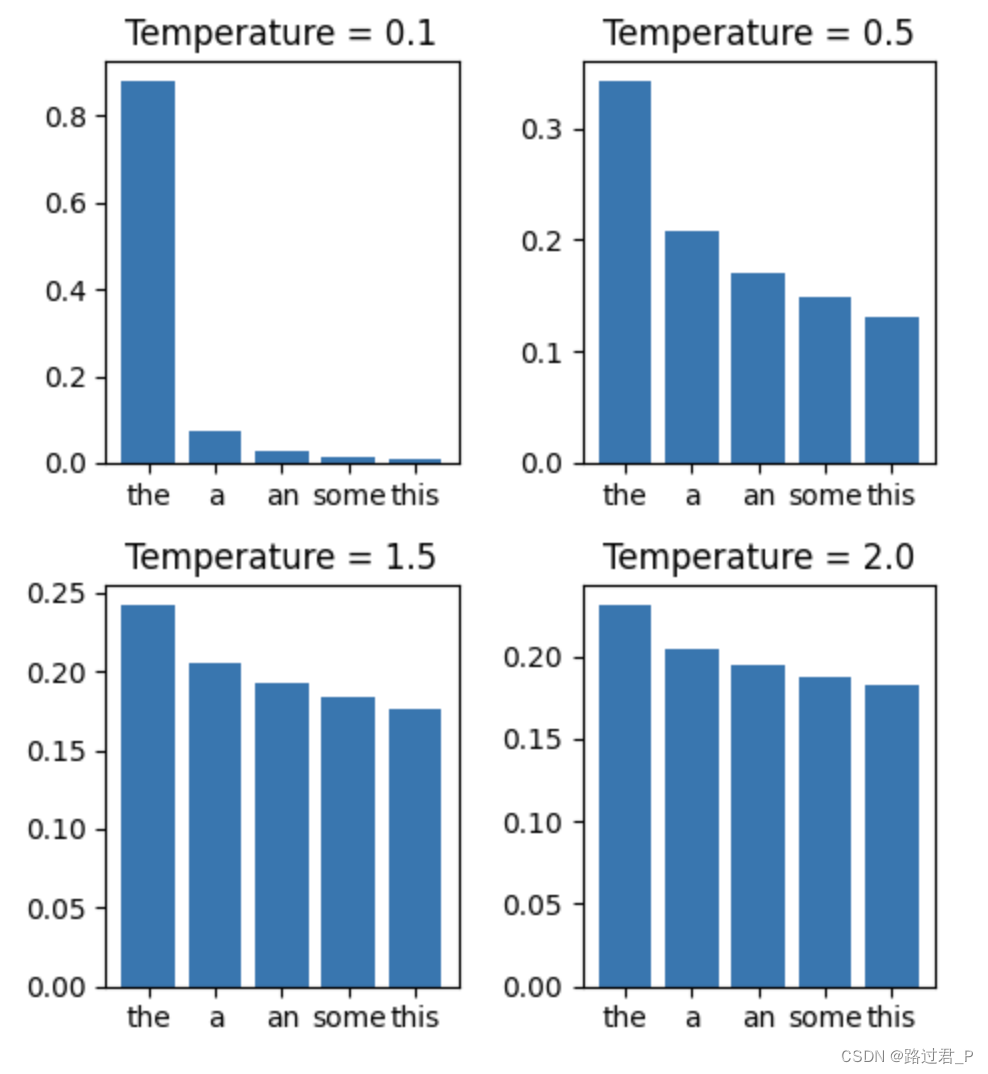
GPT 中的 temperature 参数调整模型输出的随机性。
下图显示不同温度值对单词出现在下一个位置的概率的影响:
top_p
官方文档
top_p number or null Optional Defaults to 1
An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered.
We generally recommend altering this or temperature but not both.
有一种替代温度采样的方法,叫做核采样,模型会考虑概率质量在top_p内的tokens的结果。所以0.1意味着只有概率质量在前10%的tokens会被考虑。
我们通常建议此参数或temperature参数不要同时更改。
作用机制
top_p 参数接受的是一个累积概率,top_p 的大小影响到候选 token 的数量。
模型使用以下逻辑选择部分单词加入备选集合
- 对所有单词按照概率从大到小进行排序
- 将备选集合中的概率逐个相加,当超过top_n时停止处理后面的单词
假设有这几个单词可供选择,
| 单词 | 概率 | 累计概率 |
|---|---|---|
| the | 0.5 | 0.5 |
| a | 0.25 | 0.75 |
| an | 0.15 | 0.9 |
| some | 0.08 | 0.98 |
| this | 0.02 | 1 |
假设设定 top_p = 0.7 ,则备选集合为(the,a)