文章目录
- 制作数据集的文本文件
- 读取文本文件
制作数据集的文本文件
import os
from os.path import join
import random
import config
args = config.args
class SplitDataset:
def __init__(self):
self.data_root_path = args.data_root_path
self.dataset_split_rate = args.dataset_split_rate
def split_dataset(self):
# image_file_list里面只保留有标签数据的
label_path = join(self.data_root_path, 'label')
image_path = join(self.data_root_path, 'image')
dataset_name_list = []
for image_name in os.listdir(image_path):
label_name = image_name.split(sep='.')[0]+"_GT.nii"
if label_name in os.listdir(label_path):
dataset_name_list.append(join(image_name))
# print(image_name_list)
# 将image_file_list分为训练、验证和测试集
numbers = len(dataset_name_list)
print('Total numbers of samples is :', numbers)
random.shuffle(dataset_name_list)
train_name_list = dataset_name_list[0:int(numbers * self.dataset_split_rate[0])]
val_name_list = dataset_name_list[
int(numbers * self.dataset_split_rate[0]):
int(numbers * (self.dataset_split_rate[0] + self.dataset_split_rate[1]))]
test_name_list = dataset_name_list[
int(numbers * (self.dataset_split_rate[0] + self.dataset_split_rate[1])):]
self.write_txt(train_name_list, "train_list.txt")
self.write_txt(val_name_list, "val_list.txt")
self.write_txt(test_name_list, "test_list.txt")
def write_txt(self, name_list, file_name):
root_path = join(args.root_path, 'TOF_MRA')
f = open(join(root_path, file_name), 'w')
for name in name_list:
image_path = join(args.data_root_path, 'image', name)
label_path = join(args.data_root_path, 'label', name.split(sep='.')[0]+'_GT.nii')
f.write(image_path + ' ' + label_path + "\n")
f.close()
if __name__ == '__main__':
dataset = SplitDataset().split_dataset()
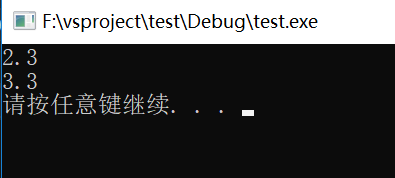
结果
读取文本文件
def load_file_name_list(file_path):
file_name_list = []
with open(file_path, 'r') as file_to_read:
while True:
lines = file_to_read.readline().strip() # 整行读取数据
if not lines:
break
pass
file_name_list.append(lines)
pass
return file_name_list